Zookeeper及kafka
一、spring cloud
Spring Cloud Alibaba
https://github.com/alibaba/spring-cloud-alibaba
https://github.com/alibaba/spring-cloud-alibaba/wiki
https://gitee.com/mirrors/Spring-Cloud-Alibaba/
二、zookeeper
ZooKeeper 是一个分布式服务框架,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:命名服务、状态同步、配置中心、集群管理等。
官方文档:https://zookeeper.apache.org/doc/
主要是 kafka 依赖 zookeeper
(一)ZooKeeper 安装
下载地址:https://archive.apache.org/dist/zookeeper/
版本: stable 和 current ,生产建议使用stable版本
基本配置:
tickTime=2000 #"滴答时间",用于配置Zookeeper中最小的时间单元长度,单位毫秒,是其它时间配置的基础
initLimit=10 #初始化时间,包含启动和数据同步,其值是tickTime的倍数
syncLimit=5 #正常工作,心跳监测的时间间隔,其值是tickTime的倍数
dataDir=/tmp/zookeeper #配置Zookeeper服务存储数据快照的目录,可以自动创建,可以修改为 dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs #指定日志路径,默认与 dataDir 一致,事务日志对性能影响非常大,强烈建议事务日志目录和数据目录分开,如果后续修改路径,需要先删除中dataDir中旧的事务日志,否则可能无法启动,此目录可以自动创建
clientPort=2181 #配置当前Zookeeper服务对外暴露的端口,用户客户端和服务端建立连接会话
preAllocSize: #为事务日志预先开辟磁盘空间。默认是64M,意味着每个事务日志初始大小64M。如果ZooKeeper产生快照频率较大,可以考虑减小这个参数,因为每次快照后都会切换到新的事务日志,即使前面的64M没有写满。
snapCount: #该配置项指定ZooKeeper在将内存数据库保存为快照之前,需要先写多少次事务日志,即,每写几次事务日志就快照一次。默认值为100000。为了防止所有的ZooKeeper服务器节点同时生成快照(一般情况下,所有集群的实例的配置文件是完全相同的),当某节点的先写事务数量在(snapCount/2+1,snapCount)范围内时挑选一个随机值做为该节点拍快照的时机。
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能#通过prometheus监控的相关配置,需要stop再start,restart可能会失败
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#提供prometheus监控功能
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
1.安装JAVA环境
apt update && apt -y install openjdk-21-jdk2.部署 ZooKeeper
把二进制包放进来解压
root@ubuntu10:~ tar xf apache-zookeeper-3.9.3-bin.tar.gz -C /usr/local/
root@ubuntu10:~ cd /usr/local/
root@ubuntu10:/usr/local ln -s apache-zookeeper-3.9.3-bin/ zookeeper
修改配置文件,先复制一个 zoo.cfg 出来
root@ubuntu10:/usr/local/zookeeper/conf cp zoo_sample.cfg zoo.cfg
root@ubuntu10:/usr/local/zookeeper vim conf/zoo.cfg
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
……
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
启动文件是:zkServer.sh
3.service文件
root@ubuntu10:/usr/local/zookeeper vim /lib/systemd/system/zookeeper.service
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target
root@ubuntu10:/usr/local/zookeeper systemctl daemon-reload
root@ubuntu10:/usr/local/zookeeper systemctl enable --now zookeeper.service
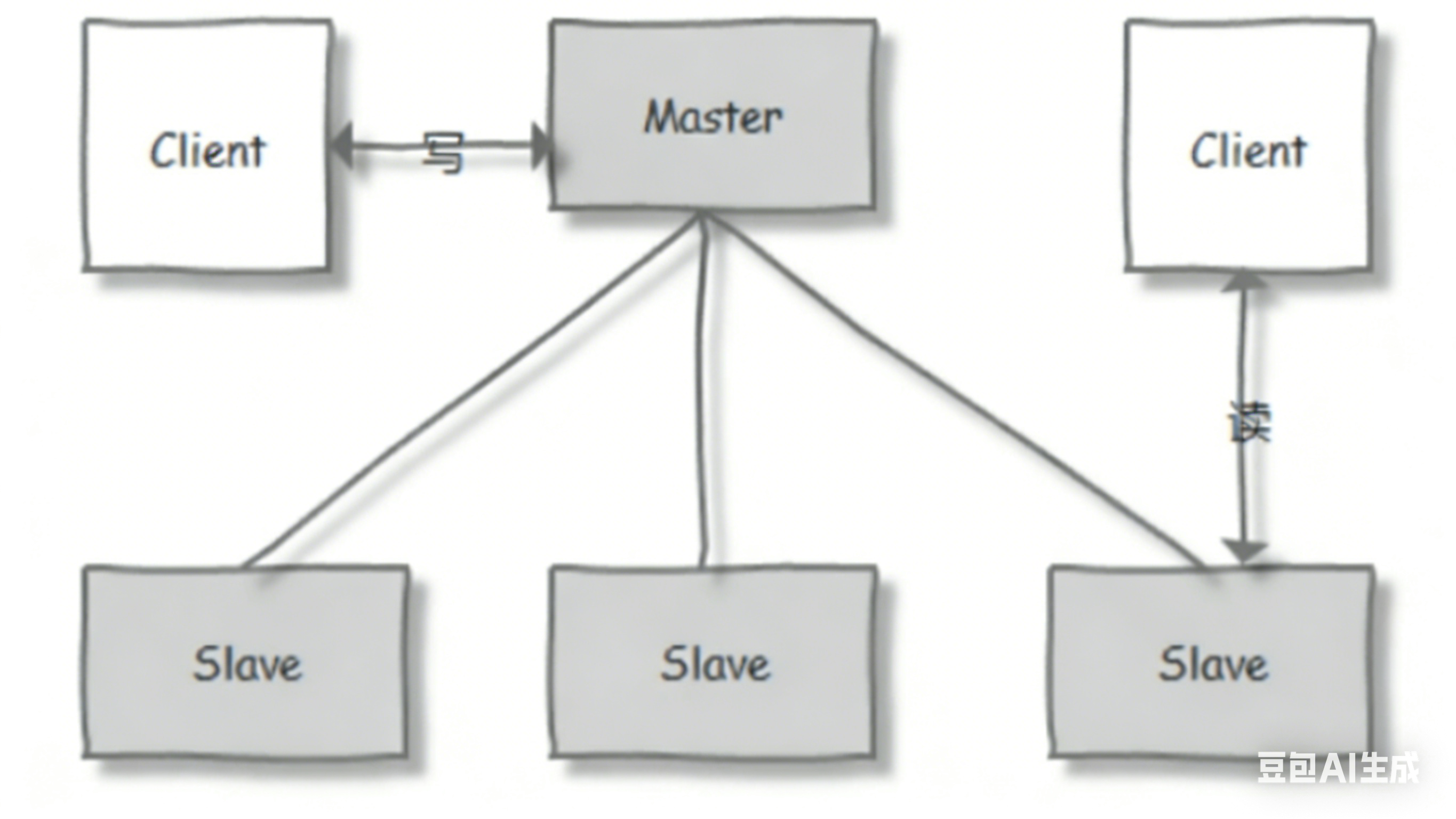
(二)zookeeper集群
需要奇数个结点
1.环境准备
准备三台主机10.0.0.10/10.0.0.11/10.0.0.12
安装java:apt update && apt -y install openjdk-21-jdk,把安装包放到三台主机上
在每台主机上分别执行以下命令
tar xf apache-zookeeper-3.9.3-bin.tar.gz -C /usr/local/
ln -s /usr/local/apache-zookeeper-3.9.3-bin/ /usr/local/zookeeper
cd /usr/local/zookeeper
root@ubuntu11:/usr/local/zookeeper ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.md
root@ubuntu11:/usr/local/zookeeper cp conf/zoo_sample.cfg conf/zoo.cfg
2.准备配置文件
每个主机的配置文件都如下去配置
root@ubuntu10:/usr/local/zookeeper/conf vim /usr/local/zookeeper/conf/zoo.cfg
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
server.1=10.0.0.10:2888:3888
server.2=10.0.0.11:2888:3888
server.3=10.0.0.12:2888:3888
……
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpHost=0.0.0.0
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
3.在各个节点生成ID文件
注意: 各个myid文件的内容要和zoo.cfg文件相匹配
[root@ubuntu10 ~]mkdir /usr/local/zookeeper/data; echo 1 > /usr/local/zookeeper/data/myid
[root@ubuntu11 ~]mkdir /usr/local/zookeeper/data; echo 2 > /usr/local/zookeeper/data/myid
[root@ubuntu12 ~]mkdir /usr/local/zookeeper/data; echo 3 > /usr/local/zookeeper/data/myid4.启动
注意:在所有三个节点快速启动服务,否则会造成集群失败
/usr/local/zookeeper/bin/zkServer.sh startroot@ubuntu12:/usr/local/zookeeper# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
root@ubuntu11:/usr/local/zookeeper# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
root@ubuntu10:/usr/local/zookeeper# /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
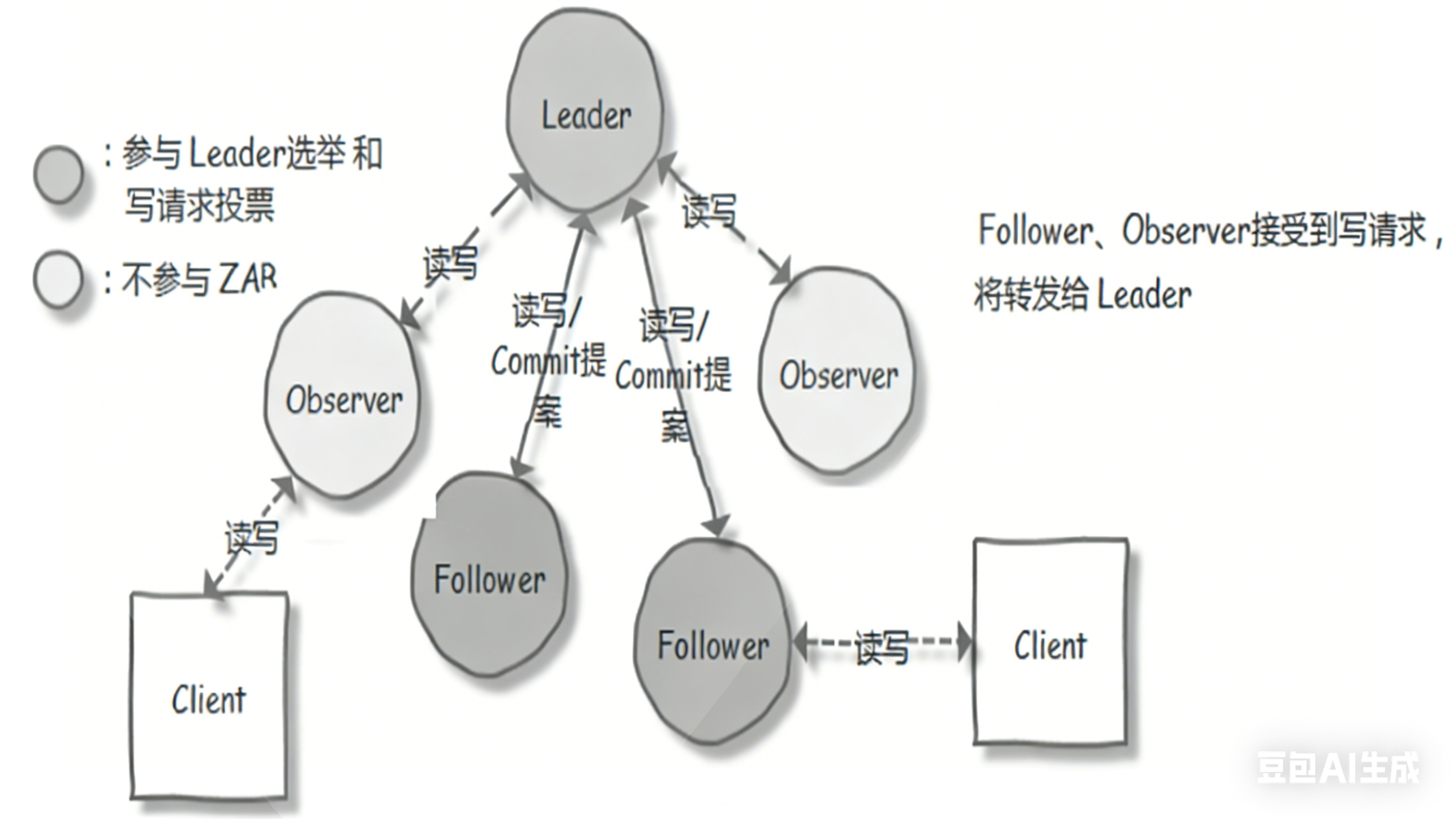
如果挂了主节点会从从节点中选举一个出来;需要半数以上可用这个集群才能正常运行
三、Kafka
目前主流的消息队列软件有 Kafka、RabbitMQ、ActiveMQ、RocketMQ等,还有相对小众的消息队列软件如ZeroMQ、Apache Qpid 等。
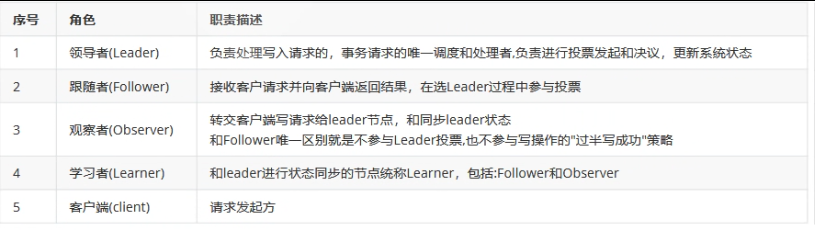
一、核心角色
-
Producer:消息生产者,负责向 Kafka 发送数据
-
Consumer:消息消费者,从 Kafka 拉取数据消费
-
Consumer Group:消费者组,组内消费者负载均衡消费,保证消息不重复处理
-
Broker:Kafka 服务节点,负责存储和管理消息
-
Topic:消息分类主题,是消息的逻辑容器
-
Partition:主题分区,Topic 的物理分片,提升并发读写能力
-
Leader/Follower:分区主从副本,Leader 处理读写,Follower 同步数据,保障高可用
二、核心流程
-
生产流程:Producer 将消息按规则发送到对应 Topic 的 Partition
-
存储流程:消息写入 Partition 主副本,Follower 异步同步数据
-
消费流程:Consumer 从 Partition 拉取消息,记录消费偏移量(Offset)
-
高可用:Leader 宕机时,Follower 自动选举为新 Leader,服务不中断
(一)Kafka 部署
kafka下载链接
http://kafka.apache.org/downloads
kafka版本格式
kafka<5cala版本>_<kafka版本,
#示例:
kafka_2.13-2.7.0.tgz
kafka_2.12-3.9.0.tgzkafka4.0之后的就不依赖zookeeper了
1.旧版基于 zookeeper 部署 kafka单机
注意主机名解析,默认主机名称反向解析IP进行访问
root@ubuntu10:~ hostname
ubuntu10
root@ubuntu10:~ cat /etc/hosts
……
ff02::2 ip6-allrouters
10.0.0.10 ubuntu10
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
root@ubuntu10:~ tar xf kafka_2.13-3.9.1.tgz -C /usr/local/
root@ubuntu10:~ cd /usr/local/
root@ubuntu10:/usr/local ln -s kafka_2.13-3.9.1/ kafka
root@ubuntu10:/usr/local cd kafka ; ls
bin config libs LICENSE licenses NOTICE site-docs
修改zookeeper配置文件
root@ubuntu10:/usr/local/kafka vim config/zookeeper.properties
dataDir=/data/zookeeper #自定义一个数据目录,之前的电脑重启就没了
启动zookeeper
root@ubuntu10:/usr/local/kafka bin/zookeeper-server-start.sh config/zookeeper.properties
修改kafka配置文件
root@ubuntu10:/usr/local/kafka vim config/server.properties
……
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/data/kafka-logs #修改数据存放地址
……启动kafka
root@ubuntu10:/usr/local/kafka bin/kafka-server-start.sh config/server.properties
2. 4.0之后的kafka
#修改数据日录
vim config/server.properties #新版路径不一样
log.dirs=/data/kraft-combined-logs其他都差不多不用配置zookeeper了
(二)基于 zookeeper 模式的集群
1.环境准备
准备10.0.0.11/10.0.0.12/10.0.013主机
注意:每个kafka节点的主机名称解析需要提前准备,否则会导致失败
修改每个kafka节点的主机名
11主机:hostnamectl hostname node1
12主机:hostnamectl hostname node2
13主机:hostnamectl hostname node3
在所有kafka节点上实现主机名称解析
cat /etc/hosts
……
10.0.0.11 node1
10.0.0.12 node2
10.0.0.13 node3
每个主机都安装 JAVA
apt update && apt -y install openjdk-21-jre2.使用kafka自带的zookeeper,需要修改配置文件
所有节点都要更改zookeeper配置文件
root@ubuntu11:/usr/local/kafka vim config/zookeeper.properties
#必须添加时间相关配置
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
#保留下面内容
clientPort=2181
maxClientCnxns=0
admin.enableServer=false
#添加下面集群配置
dataDir=/usr/local/kafka/data/
server.1=10.0.0.11:2888:3888
server.2=10.0.0.12:2888:3888
server.3=10.0.0.13:2888:3888修改各个节点的MyID
mkdir /usr/local/kafka/data #没有就创建
分别在对应的主机上创建myid
echo 1 > /usr/local/kafka/data/myid
echo 2 > /usr/local/kafka/data/myid
echo 3 > /usr/local/kafka/data/myid在所有节点上启动zookeeper
3. 各节点部署 Kafka
每个节点修改配置文件
root@node1:/usr/local/kafka# vim config/server.properties
……
############################# Server Basics###############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复,此行必须修改
broker.id=0
……
############################# Socket ServerSettings ######################
# 用自己的主机IP地址,kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.11:9092
……
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/usr/local/kafka/data
……
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=10.0.0.11:2181,10.0.0.12:2181,10.0.0.13:2181
……启动kafka
#前台启动
[root@node1 ~] /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
#后台启动
[root@node1 ~] /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
(三) Kafka 读写数据
参考文档
http://kafka.apache.org/quickstart
常见命令
kafka-topics.sh #消息的管理命令
kafka-console-producer.sh #生产者的模拟命令
kafka-console-consumer.sh #消费者的模拟命令
1.创建 Topic
创建topic名为 liao,partitions(分区)为3,replication(每个分区的副本数/每个分区的分区因子)为 2
root@node1:/usr/local/kafka/bin /usr/local/kafka/bin/kafka-topics.sh --create --topic liao --bootstrap-server 10.0.0.11:9092 --partitions 3 --replication-f-factor 2
查看分区状态
root@node1:/usr/local/kafka/bin /usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server 10.0.0.11:9092 --topic liao
Topic: liao TopicId: 1ukQJRmtRGuk-T8TBfbDpg PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: liao Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1 Elr: N/A LastKnownElr: N/A
Topic: liao Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0 Elr: N/A LastKnownElr: N/A
Topic: liao Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2 Elr: N/A LastKnownElr: N/A
2.消息积压
通过Kafka提供的工具查看格式:
#发现当前消费的offset和最后一条的offset差距很大,说明有大量的数据积压
kafka-consumer-groups.sh-bootstrap-server{kafka连接地址}--describe--group{消费组}-a1I-groups
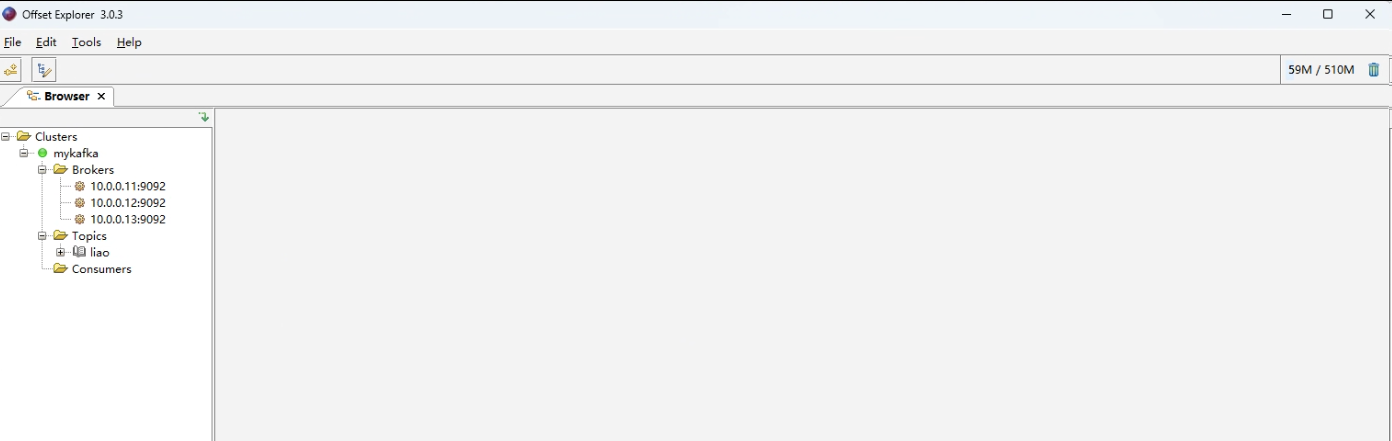
(四)Kafka 工具
图形工具 Offset Explorer
官网:https://www.kafkatool.com/
配置主机ip就可以看到下面内容


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)