“SINE——首个解决基于上下文视觉学习的分割任务中歧义性问题的简单图像分割框架”【学习笔记】
近年来,人们已经探索出了一些通用的分割模型,这些模型可以在一个统一的上下文学习框架内有效地处理各种图像分割任务。上下文分割中的任务歧义性,因为并非所有的上下文分割实例都能准确地传达任务信息。为了解决这个问题,本文提出了SINE(aSIN-contextExamples):一个利用上下文样例的简单图像分割框架。主要方法是利用了一个Transformer编码器-解码器结构,其中编码器提供高质量的图像表
论文来自NeurIPS 2024:
[2410.04842] A Simple Image Segmentation Framework via In-Context Examples https://arxiv.org/abs/2410.04842
https://arxiv.org/abs/2410.04842
1 Abstract
近年来,人们已经探索出了一些通用的分割模型,这些模型可以在一个统一的上下文学习框架内有效地处理各种图像分割任务。
然而,这些方法仍然存在一个局限性:上下文分割中的任务歧义性,因为并非所有的上下文分割实例都能准确地传达任务信息。
为了解决这个问题,本文提出了SINE(a Simple image Segmentation framework utilizing IN-context Examples):一个利用上下文样例的简单图像分割框架。
主要方法是利用了一个Transformer编码器-解码器结构,其中编码器提供高质量的图像表示,解码器被设计为产生多个特定于任务的输出掩码,以有效地消除任务歧义。(说白了就是在出现任务歧义性n选1的时候,把n种任务都做一遍,当然本文的n是3:相同对象分割、语义分割、实例分割)
具体来说,本文引入了上下文交互模块来补充上下文信息,并在目标图像和上下文样本之间产生相关性,引入了一个使用固定匹配和匈牙利算法的匹配Transformer来消除不同任务之间的差异。
此外,本文还进一步完善了现有的上下文图像分割评价体系,对不同分割任务的实验表明了该方法的有效性。
代码链接:http:// https://github.com/aim-uofa/SINE。
2 Introduction
图像分割涉及在像素级定位和组织概念。不同的概念定义,如前景,类别和对象实例,导致不同类型的分割任务,例如:语义分割,实例分割,全景分割,前景分割,交互式分割。
尽管如此,大多数现有的分割方法都是针对某些任务定制的,无法应用于其他任务。
最近,一些工作探索了能够通过上下文学习解决多样化和无限制分割任务的通用分割模型。
比如,Painter 使用掩码图像建模执行上下文训练,并可以根据上下文视觉提示实现各种任务。SegGPT 专注于视觉分割,并引入了上下文分割,它通过将目标图像和注释的参考图像作为输入来统一多个分割任务。
然而,这些模型在上下文分割中仍然存在任务歧义:
上下文分割模型需要理解上下文示例传达的任务和内容信息,并在目标图像上分割相关概念。
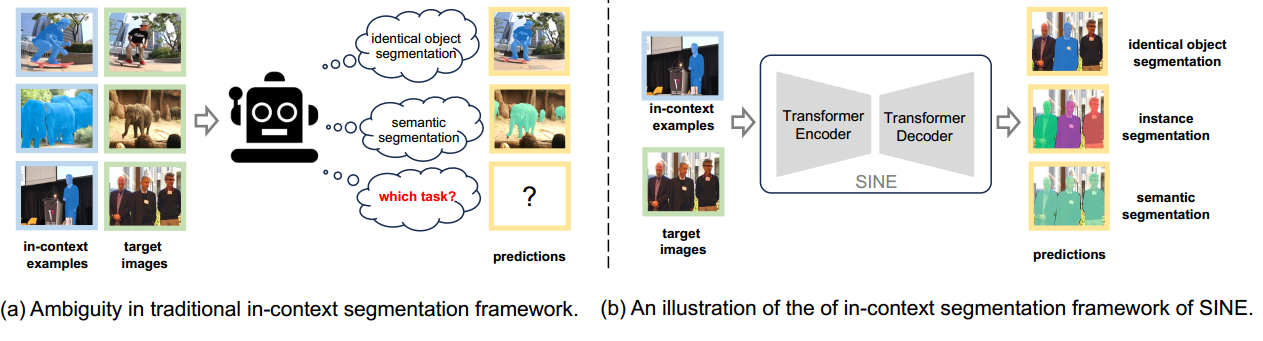
然而,并不是所有的上下文示例都能准确地传达任务信息。
例如图1(a)所示,当示例和目标图中都只有滑板少年,模型能很清楚的分割出相同的目标——滑板少年;当示例和目标图种都只有大象,虽然示例图和目标图种都只有大象,但是模型以及能知道需要分割的是大象这个语义信息;但是,当需要分割特定个体时,包括“他”和其他人的目标图像时,模型就分不清应该做什么分割任务,到底时应该仅限于单独个体“他”的相同对象分割,还是包括不同人的实例分割,还是专注于所有人的语义分割?
这就是本文所提到的任务歧义性,也叫任务模糊性——task ambiguity:
在上下文分割任务中,目标图像的像素是否需要被分割取决于它们与上下文示例的相似性。上下文中的歧义示例会使传统的上下文分割模型难以清楚地定义不同任务之间的边界,从而导致不期望的输出。
SINE的提出就是为了解决这个问题。从SAM(通过生成不同粒度的多个掩码解决点模糊)中汲取灵感,SINE预测多个输出掩码,包括:相同的对象,实例到整体语义。至此,SINE将现有的分割任务与各种粒度统一起来,旨在实现更广泛的任务泛化。
SINE利用Transformer编码器-解码器结构:encoder包含一个frozen的预训练图像编码器用来提供高质量的图像表示,以及一个上下文交互模块,以补充上下文信息并学习目标和参考图像特征之间的相关性。decoder部分,本文提出了一种新型的匹配Transformer(M-Former)用于高效的多任务解码。M-Former由双路Transformer实现。一条路径用于图像特征和对象查询之间的信息交互,另一条路径用于增强语义原型以实现精确匹配。此外,采用固定匹配和匈牙利算法消除不同任务之间的差异。
与SegGPT相比,SINE以更少的可训练参数实现了令人印象深刻的性能。实验的定性结果表明,SINE可以有效地解决在上下文分割的任务歧义的问题,而SegGPT只输出语义分割结果。SINE在现有的上下文图像分割基准上实现了最先进或具有竞争力的性能,包括few-shot语义分割,视频对象分割。
此外,本文进一步将few-shot实例分割引入到当前的上下文图像分割评价体系中,以促进对这些模型的整体评估。同时,SINE为上下文分割模型提供了一个基线结果,促进了该领域的发展。
SINE主要贡献如下:
①第一个调查的任务歧义性的上下文分割,并提出了一个简单而有效的框架来解决这个问题。
②提出匹配Transformer,以低训练成本释放冻结的预训练图像模型在各种分割任务中的潜力。
③综合结果表明,SINE可以解决广泛的分割任务,包括few-shot语义分割,few-shot实例分割,视频对象分割。
3 Preliminary
本节中,首先制定了上下文分割的问题设置。然后,文章回顾了一下以前的上下文分割模型SegGPT。
3.1 Problem Formulation
上下文内分割旨在识别给定上下文内示例内的特定任务和对象,包括参考图像X_r及其注释Y_r 并分割目标图像X_t中的感兴趣对象。mi_r表示第i个参考掩码,ci_r表示其类别标签,N表示参考掩码的数量。感兴趣的对象与上下文中的示例相关,该上下文中的示例可以是用于视频对象分割的相同对象,或者是用于实例分割和语义分割的相同语义概念的所有对象。
SINE主要集中在三个语义粒度的任务歧义,即:相同的对象(ID),实例和语义。相同对象分割可以看作是更细粒度的实例分割,而实例分割可以通过合并属于同一类别的实例掩码转化为语义分割。
3.2 A Revisit of SegGPT
SegGPT 引入了上下文分割,它将图像和掩模注释合并到RGB图像中,以传达要执行的特定任务并同时识别要分割的对象。SegGPT将拼接的参考图像和目标图像作为输入,并采用掩码图像建模算法和平滑损失θ来训练Vision-Transformer编码器。在推理过程中,SegGPT可以通过上下文示例分割所有内容,包括参考图像及其注释图像。给定一个目标图像,它将与参考图像缝合并输入SegGPT以获得相应的上下文预测。尽管SegGPT在各种细分任务中取得了巨大成功,但它面临两个挑战:(1)在许多情况下,上下文中的示例可能无法准确地传达任务信息。比如,当上下文内的示例仅由单个对象及其注释组成时,缺少附加的任务相关信息可能导致不正确的输出。(2)SegGPT利用单个Transformer编码器结构进行特征提取和特定于任务的解码。这将在上下文分割过程中引入复杂性,并导致次优解决方案。
受SAM的启发,该模型通过同时输出多个不同粒度的掩码来解决点歧义,SINE单独关注上下文示例的各种内容,并赋予模型为不同任务预测多个输出掩码的能力。此外,本文架构解开了SegGPT中的Transformer编码器的功能,并部署了一个Transformer编码器和解码器,分别执行特征提取和任务解码。
4 Method
我们提出了SINE,一个利用上下文样例的简单图像分割框架。SINE可以有效地解决上下文分割中的任务模糊性问题,通过将特定任务从上下文示例中分离出来,并理解提示的语义概念,以从相同对象、实例到语义的不同级别的任务粒度输出结果。我们在下面的小节中详细介绍我们的方法。
4.1 Overview
SINE框架的概述如图2所示:基于经典的Transformer结构构建,以及一些针对上下文分割任务的有效设计,包括frozen的预训练图像编码器、上下文交互模块和轻量级匹配解码器(M-Former)。
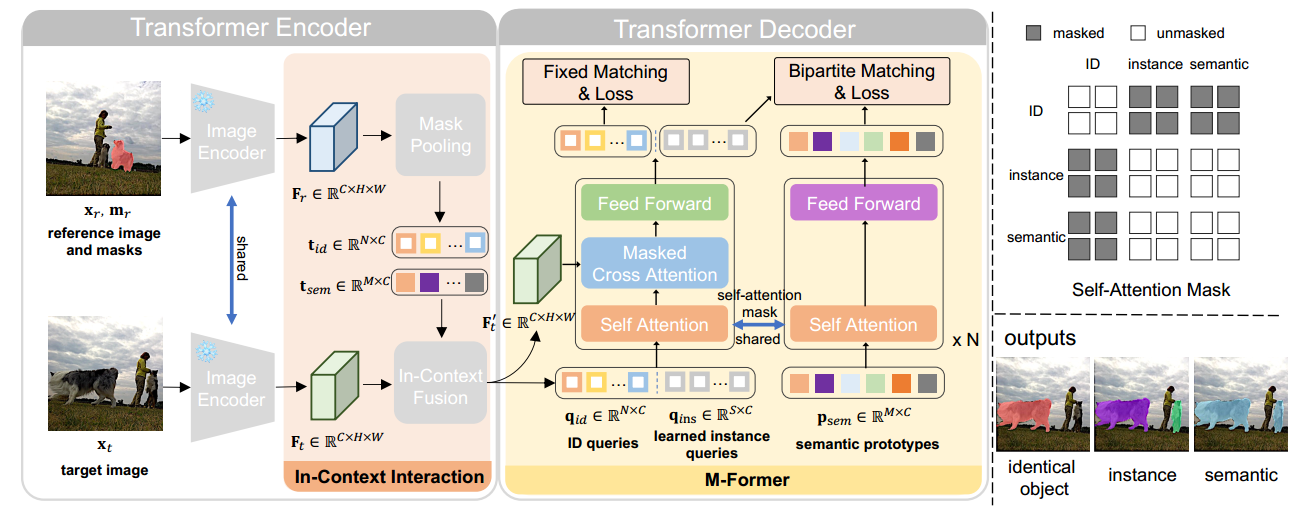
SINE使用冻结的预训练图像编码器对x_r和x_t进行编码,得到参考特征F_r 和目标特征F_t 。
受NLP 中上下文学习的启发,为了使SINE能够掌握参考图像和目标图像之间共存的上下文相关性构建了一个上下文交互模块——专门用于捕获F_r和F_t之间语义相关性的组件,并输出增强的目标特征F ′ t 、ID查询qid 、语义原型psem 。
SINE被构建为基于查询的分割模型,遵循DETR和Mask2Former的方案:采用ID查询qid来识别和定位目标图像中的对象,这些对象在参考图像中具有相同的对应物。
此外,应用可学习的实例查询qins 来识别和定位目标图像中与参考图像共享相同语义标签的对象。M-Fomer解码器被用来更新这些查询和原型。然后,采用预测前馈网络分别预测ID和实例输出。
4.2 In-Context Interaction
上下文交互的目的是补充上下文信息,并在参考和目标图像特征之间产生相关性。
如图3所示,首先通过为每个掩码分配不同的ID标签,将掩码m_r转换为ID掩码m_id ,再通过合并具有相同类别标签的掩码,将m_r转换为语义掩码m_sem;最后,使用这些掩码再参考特征F_r上做池化操作,以获得t_id和t_sem。
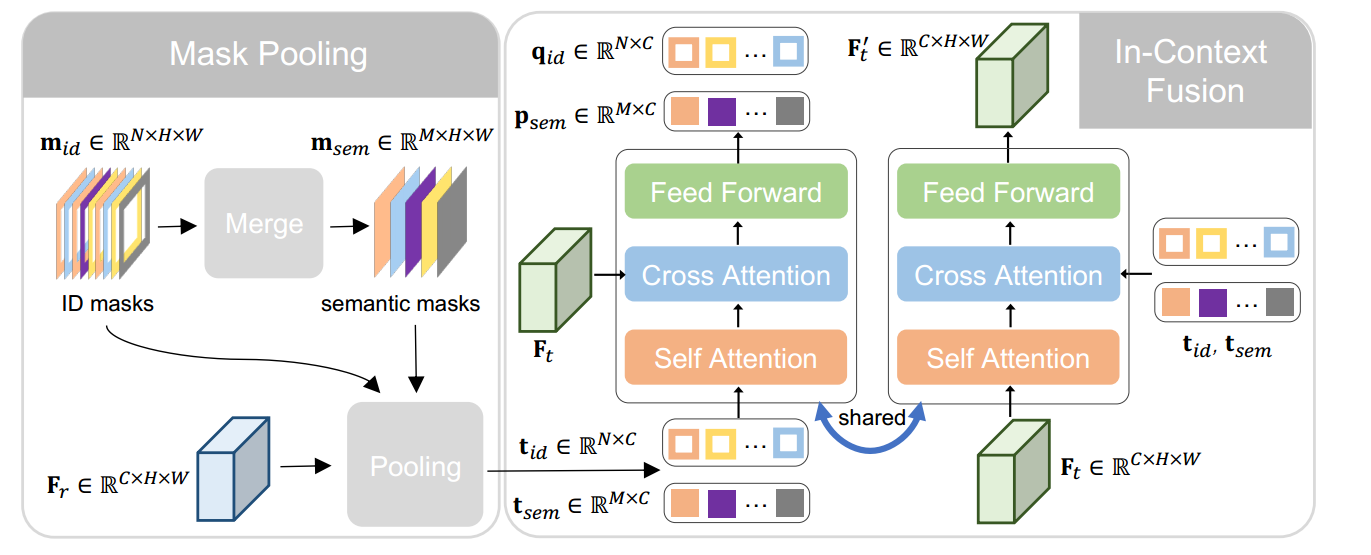
该模块旨在补充引用和目标之间的上下文信息。ID和语义标记通过掩码池提取。
增强的目标特征、ID查询和语义原型由上下文融合模块输出。
我们引入了一个上下文融合模块来实现参考和目标特征之间的上下文相关性。该模块的过程可以总结如下:
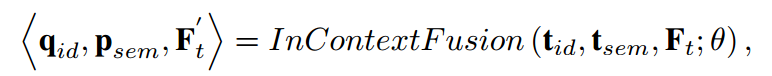
其中θ是上下文融合的参数。该模块是一个Transformer块,包括自注意力、交叉注意力和前馈网络。自注意力层是共享的,将标记(t_id和t_sem)和目标特征(F_t)融合,在交叉注意中作为彼此的键和值,得到增强的目标特征F ′ t、ID查询q_id和语义原型p_sem。
4.3 Matching Transformer
M-Former旨在将增强的目标特征解码为不同的任务输出,从相同的对象,实例到语义,并为上下文分割提供全面而高效的性能。因此,除了ID查询q_id和语义原型p_sem,还将一组可学习的实例查询q_ins用于预测实例。
为了有效地进行上下文分割和消除任务歧义,M-Former的设计需要考虑一下几点:(1)语义原型需要为实例查询分配语义信息;(2)避免粗粒度语义原型污染细粒度ID查询;(3)查询与目标特征交互。
在上述分析的启发下,M-Former由共享自注意层的双路径Transformer解码器实现。
第一条路径用于F ′ t和查询(q_id和q_ins)的交互,以从目标图像中提取与上下文示例相关的特征。这条路径由一系列自注意力、掩蔽交叉注意力和前馈网络组成。
第二条路径用于增强语义原型p_sem,以实现更准确的匹配。
这两条路径采用共享的自注意层,为了将语义从p_sem分配到q_ins。同时,为了避免语义原型污染细粒度的ID查询,我们在共享的自注意层中应用自注意掩码,如图2右上角所示。
M-Former的过程可以总结如下:
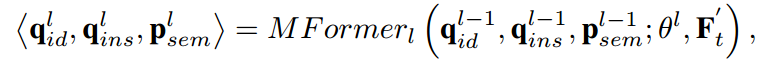
其中,l表示M-Former的层数,θ_l是第l个M-Former块的参数。然后,采用预测前馈网络分别预测ID和实例输出。
对于实例分割,我们使用更新后的语义原型p_sem作为分类器,并让y_ins表示S实例预测的集合,其基础真值由y表示。我们使用匈牙利损失来学习SINE。具体来说,我们计算匹配问题的预测y样本i_ins和GT值y_j之间的分配成本,即,−pi(c j)+ Lmask(mj),其中(cj,mj)是地面实况对象的类和掩码,cj可能为空。pi(cj)是第i个实例查询的类cj的概率,m^i_ins表示其预测掩码。L_mask是一个二进制掩码损失和骰子损失。匈牙利的损失是:
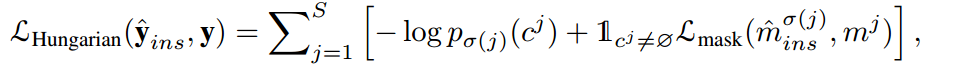
其中σ(j)表示二分匹配的结果索引。为了赋予SINE预测相同对象的能力,我们使用图像中同一实例的不同裁剪视图作为参考-目标图像对。令N_id表示N_ID预测的集合。由于参考ID和目标ID之间的关系是固定的,并且可以准确确定,因此我们在预测和地面实况之间执行固定匹配。损失可以写成:
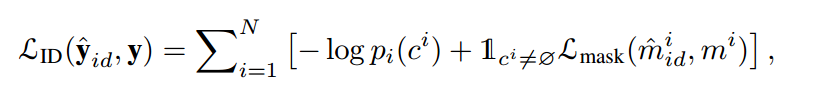
中(c i,mi)是基础真值类和掩码,c i ∈ {1,mi},ci= 1表示对象同时出现在参考图像和目标图像两者中。
总损失为 L_Total= L_Hungarian + L_ID。一旦训练完成,SINE的全部功能在推理过程中得到释放。SINE可以解决上下文示例中的模糊性,并为不同的分割任务输出预测。
5 Experiments
训练数据:实验使用一组不同的分割数据集来训练我们的模型,包括语义分割、实例分割和全景分割。具体来说,使用三个视觉感知数据集:ADE 20 K 是一个流行的语义分割数据集,为150个类别提供语义标签。对于全景分割,150个类别可以分为100个“事物”和50个“东西”类别。它有25K张图像,其中20K用于训练,2K用于验证,3K用于测试。COCO 是一个广泛使用的数据集,支持对象检测,实例分割和全景分割。它包含80个“事物”和53个“东西”类别,118K训练和5K验证图像。Objects365 是一个大规模的高质量目标检测数据集。它包含365个类别,638K图像和10M边界框。我们通过使用Segment Anything Model 扩展Objects365的实例分割注释。同时,将不同的数据注释转换为实例分割的形式,用于统一的混合数据训练。
训练细节:模型部署了具有304 M参数的冻结DINOv 2(ViT-L)作为图像编码器,并使用仅19 M的可训练参数训练SINE。In-Context Fusion有一个块,M-Former有六个块。SINE的模型大小与SegGPT(307 M)相当。SINE的可训练参数较少,导致更有效的训练。
使用64个批量大小训练SINE大约50 K步。使用Adam 优化器并采用β1 = 0.9,β2 = 0.999用于优化。用线性学习率调度器,基本学习率为1 e −4,预热为100步。权重衰减设置为0.05。对于数据增强,使用随机水平翻转和大尺度抖动(LSJ)增强,随机尺度从0.1到2.0采样,然后固定大小裁剪到896×896。(更多实现细节详见附录B)
5.1 Qualitative Results
定向结果证明了SINE框架可以有效地解决上下文示例中的模糊性。如图4(a)所示,很难理解应该通过带有特定个体注释的参考图像执行哪些任务。SegGPT只输出语义分割结果。相比之下,SINE输出多个输出以避免任务歧义。我们进一步可视化SINE在少镜头语义分割,少镜头实例分割,SINE展示了其在不同任务中提供高度准确预测的能力,同时在任务定义中保持出色的灵活性。

图4 -SINE的定性结果。(a)SegGPT和SINE在解决上下文分割中的歧义方面的比较。(B)few-shot语义分割。(c)few-shot实例分割。(d)视频对象分割。
5.2 Few-shot Semantic Segmentation
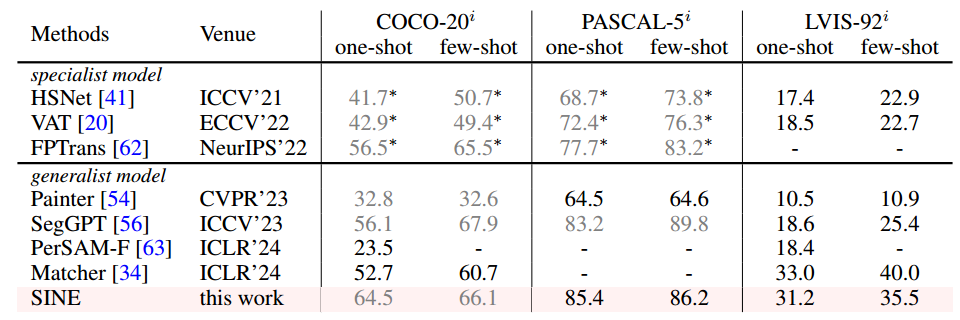
数据集:本文在两个设置中重新审视few-shot语义分割任务:域内(COCO-20 i [43])和域外(PASCAL-5i [50],LVIS-92 i [34]),基于数据集是否在训练期间被看到。COCO-20 i将COCO的80个类划分为四个交叉验证折叠,每个折叠具有20个测试类和60个训练类。类似地,PASCAL-5i构建于PASCAL之上,包含4个交叉验证折叠,LVIS-92 i是基于LVIS [16]的模型跨数据集泛化评估的更具挑战性的基准,包含10个折叠,每个折叠包含92个类,我们根据[41,56,34]的评估方案在这些数据集上全面验证了SINE的few-shot语义分割性能。
结果:如表1所示,将SINE与各种专家和通用分割模型进行了比较。对于COCO-20 i和PASCAL-5 i,由于SINE是用COCO的所有数据训练的,因此与在域内类别上训练的专家模型的性能(标记为)进行公平比较。虽然SINE和SegGPT是在COCO数据集上训练的,SINE在COCO-20 i上使用更简单的上下文学习框架,在单次性能方面取得了显著优势。此外,在PASCAL数据集上没有特定的训练,SINE在单次性能方面取得了更好的性能,在PASCAL-5i上使用较少的单次性能与SegGPT相当。在更具挑战性的数据集LVIS-92 i上,SINE的性能优于Painter,SegGPT和PerSAM-F,表现出优越的上级泛化能力和通用性。与Matcher相比,SINE在LVIS-92 i上的性能略弱,后者受益于在大规模分割数据集上预训练的SAM [25]。SINE独立地实现了有竞争力的结果,而不依赖于广泛的分割数据。
本文中提到请注意的一点:SINE的目的是为研究团体提供见解,以建立一个简单的基线,用于上下文分割,而不是SOTA。
尽管已经在12个不同的分割数据集上进行了培训[56],SegGPT应用于LVIS-92 i时表现有限。这表明需要开发更有效的以数据为中心的学习方法,专门针对上下文分割。SINE是第一个探索使用Objects 365和自动掩码注释的学习方法。SINE的高效设计使得在上下文分割的基础上进行Objects 365的训练成为可能。这使得SINE仅使用19 M训练参数,使得训练预算远小于Matcher中的SegGPT(304 M)或SAM(600 M)。
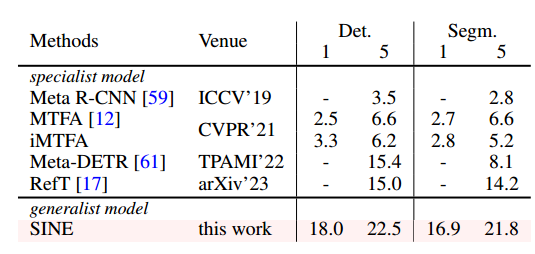
5.3 Few-shot Instance Segmentation
数据集:与few-shot语义分割一样,评估了两种设置下few-shot实例分割的SINE性能:COCO-NOVEL [23]上的域内和COCO 2 VOC [9]设置上的域外。COCO-NOVEL包括20个与VOC相交的类和5 k个测试图像。评估了该数据集上的1-shot和5-shot实例分割性能。为了评估COCO2VOC数据集的跨数据集泛化能力,使用COCO的参考样本对VOC测试集进行测试,并报告了两个数据集使用不同随机种子生成的10组不同参考图像的平均结果。
结果:表2显示了few-shot目标检测和实例分割的结果。SINE在1-shot和5-shot设置下都大幅优于专家方法。对于表3中的COCO2VOC结果,SINE显示出比专家模型更好的泛化能力。
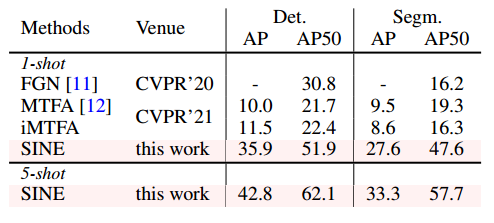
同样的请注意:本实验的目的并不是证明SINE与专业分割模型相比实现了更好的少镜头实例分割性能。
现有的上下文分割模型,如SegGPT,不适合进行实例分割。SegGPT需要使用滑动窗口遍历所有网格来预测对象,后处理复杂且效率低下。SINE是第一个本文提出了一种基于SINE的上下文分割模型,该模型能够解决小镜头实例分割问题,希望SINE能够成为上下文分割模型的一个基线,以促进该领域的发展。
5.4 Video Object Segmentation
数据集对于视频对象分割(VOS),本文实验专注于半监督设置,其中提供第一帧的对象掩码,模型负责分割所有后续帧中的对象。本文在三个验证数据集上评估SINE,包括DAVIS 2017 [46],DAVIS 2016 [45],和YouTube-VOS 2018 [58],使用J评分和F评分来评估性能。
细节:为了有效地在VOS任务上执行SINE,为每个对象引入了一组内存库,以保持中间预测。根据分类和掩码得分来确定将哪一帧保留在内存中。考虑到对象更有可能与相邻帧中的对象相似,对得分应用基于时间的衰减比率,逐渐降低其值。此外,将参考图像和掩模存储在存储器中以解决对象消失和再现的情况。
结果:表4比较了SINE和不同方法之间在是否有视频数据训练的VOS性能。在没有视频数据的情况下,SINE与DAVIS 2017上使用视频数据训练的模型相比具有竞争力的性能。此外,SINE在YouTube-VOS 2018上优于最近的通用分割方法,如Painter,SEEM,DINOv和PerSAM-F。这些结果表明,SINE具有解决视频任务的潜力。
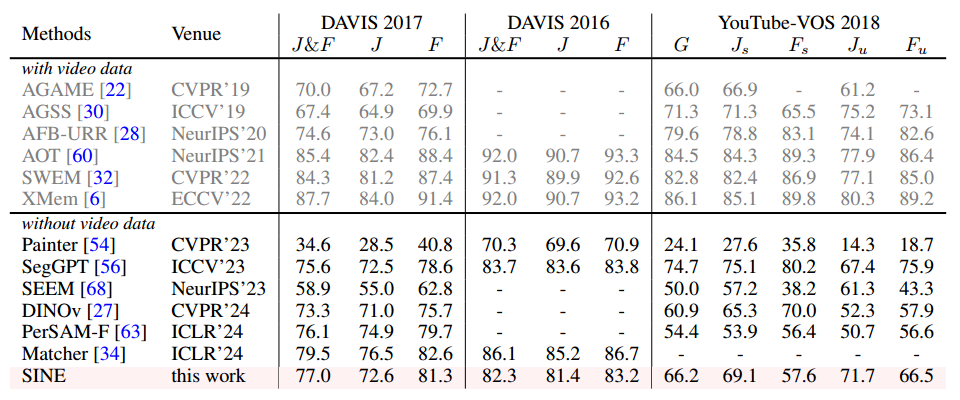
灰色表示模型是在包含视频数据的目标数据集上训练的。G是YouTube-VOS 2018中“可见”和“不可见”类的平均得分。
5.5 Transfer Learning Experiments
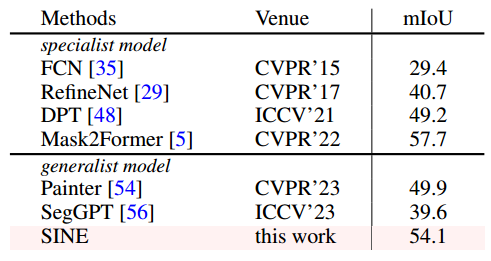
此部分研究了SINE在转移到常见分割任务时的性能,例如ADE 20K语义分割和COCO全景分割。与传统的预训练方法不同,例如MAE [18],需要微调下游任务的所有模型参数。本文验证了SINE方法可以通过参数有效微调(PEFT)方法有效地转移到这些任务[38]。具体来说,在冻结图像编码器上部署流行的PEFT方法LoRA [21],并固定原始参数以测试SINE的Transfer能力。选择rank= 32作为默认设置,为特定的分割任务训练语义原型和LoRA参数。
语义分割:根据表5,SINE在ADE 20K语义分割基准测试中实现了54.1%的mIoU,优于其他上下文分割模型,如SegGPT,它使用相关的数据集注释训练特定于文本的提示。此外,仅使用少数可训练参数,SINE实现了更好或与专业分割模型相当的性能。值得注意的是,与Mask2Former [5]不同,SINE不使用多尺度特征以获得更好的性能。
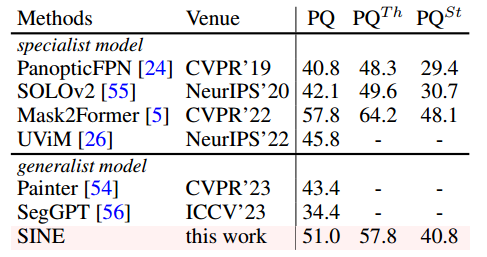
全景分割:表6显示,SINE在COCO全景分割任务上也显著优于其他通才分割模型,表明所提出的方法可以使学习的Transformer解码器有效地应用于更复杂的全景分割。通过固定总体模型参数并仅添加少量LoRA参数,SINE实现了与最佳专家分割模型的竞争性能。Mask2Former(掩模2成型器)。
5.6 Ablation Study
如表7所示,在LVIS-92 i上进行了少量语义分割的消融实验,COCO-NOVEL数据集用于少量实例分割,DAVIS 2017用于视频对象分割,ADE 20 K用于语义分割任务,以彻底验证所提出的组件的有效性以及使用不同数据集进行训练的影响。除非另有说明,只有fold 0和seed 0用于对少镜头语义/实例分割的消融。
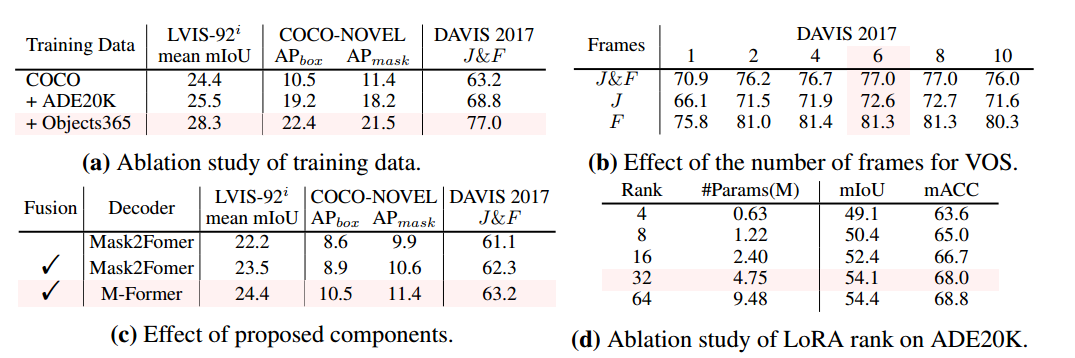
不同训练数据的影响:在不同的数据源上训练SINE(表7a),验证了包含更多样化的语义分割数据(如ADE 20K)有助于改进模型。此外,首次证明添加额外的检测数据(如Object365)可以大大增强模型的上下文分割能力。
拟议组件的消融研究:表7c显示了拟议组件的影响,所有实验仅使用COCO作为训练数据。拟议的上下文融合模块导致平均mIoU的改善,AP和J&F。当使用M-Former时,在所有评价指标中观察到进一步的增强。这证明了所提出的组件在提高模型的性能为各种分割任务的有效性。
改变帧数:表7b显示,随着帧数从1增加到6,整体分割质量逐渐提高。总体而言,使用中等帧数(如6或8)可在DAVIS 2017数据集上实现最佳VOS性能。
改变LoRA等级:表7d展示了LoRA等级对Transfer性能的影响。当LoRA为32时,SINE在可训练参数较少的情况下达到了可接受的性能。进一步将秩增加到64只会带来边际改善。考虑到性能和可训练参数数量之间的权衡,选择秩32作为默认设置。
6 Discussion and Conclusion
本文首次提出了上下文分割中存在的任务模糊性问题,并提出了SINE模型,该算法能够同时预测多个任务模板,利用其高效的设计,利用较少的可训练参数表现出较强的分割能力,本文希望SINE算法能够促进上下文分割的发展。
limitations和更多讨论详见原文附录部分。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)