HuggingFace项目实战之编码&数据集&模型操作
本文介绍了使用Hugging Face库进行NLP任务预处理的关键步骤。主要内容包括:1)环境配置(安装transformers、datasets等库);2)文本编码工具的使用,详细讲解AutoTokenizer的加载、保存及编码参数(input_ids、token_type_ids、attention_mask);3)数据集操作,展示如何加载和保存ChnSentiCorp中文情感分析数据集。重点
目录:
一、环境准备
#pip install transformers
#pip install datasets
#pip install huggingface_hub
import transformers
import datasets
import huggingface_hub
transformers.__version__, datasets.__version__, huggingface_hub.__version__
二、词编码工具
from transformers import AutoTokenizer
#在线加载一个tokenizer
tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-chinese')
tokenizer

#保存到本地
tokenizer.save_pretrained('tokenizer/google-bert/bert-base-chinese')

#从本地文件加载
tokenizer = AutoTokenizer.from_pretrained(
'tokenizer/google-bert/bert-base-chinese')
tokenizer

#简单编码
data = tokenizer.encode('你好,你好吗?')
data

#解码
tokenizer.decode(data, skip_special_tokens=False)
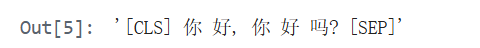
#常规编码
data = tokenizer('你好,你好吗?')
data

#参数解释
data = tokenizer(
#句子的前半部分
text=['第一个句子', '第二个句子'],
#句子的后半部分,单句子编码时不用传递
text_pair=['第三个句子', '第四个更长一点的句子'],
#是否要添加特殊符号
add_special_tokens=True,
#是否补长到统一长度,一般定义为True或者'max_length'
#定义为True时,编码的长度取决于最长的句子
#定义为max_length时,编码的长度就等于max_length
padding=True,
#句子长度超过max_length时是否裁剪,一般定义为True
truncation=True,
#定义最大编码长度
max_length=20,
#编码数据的格式,一般定义为'pt','np','tf'默认是list
return_tensors='np',
)
data

#批量解码
tokenizer.batch_decode(data.input_ids, skip_special_tokens=False)

#编码结果
data.input_ids
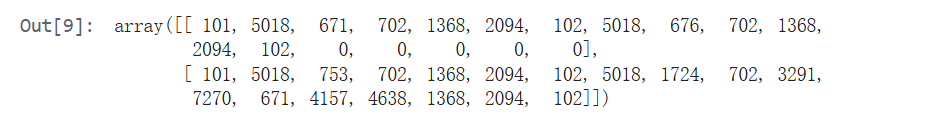
#标记每个句子中前后两段的位置,第二句的位置是1,其他是0
data.token_type_ids

#标记哪些位置是pad
data.attention_mask
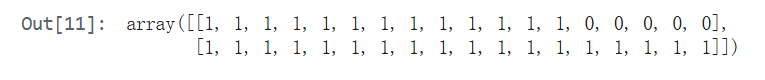
总结理解:
此处代码是自然语言处理(NLP)中的文本编码过程(使用 Hugging Face transformers
库),将人类可理解的中文句子转换为模型可计算的数字矩阵。这一步是所有 NLP
任务(包括文本填空)的前置必要步骤,因为计算机无法直接理解文字,只能处理数字。
1. input_ids:文本的数字表示(核心输入)
data.input_ids # 输出示例:array([[101, 5018, 671, 702, ..., 0, 0]])
作用:
将句子中的每个词/字转换为词典中的唯一编号(token id)。
- 关键符号:
- 101:[CLS](句子起始标记)
- 102:[SEP](句子分隔标记,如分隔两个句子)
- 0:[PAD](填充标记,用于统一句子长度)
举例:
句子 “[CLS] 第一个句子 [SEP] 第三个句子 [SEP]” 会被编码为 [101, 词1编号, 词2编号, 102, …, 102, 0, 0]
在填空任务中的用途:
模型通过这些数字编号查找预训练好的词向量,进而理解句子语义。
2. token_type_ids:标记句子边界(区分多个句子)
data.token_type_ids
# 输出示例:array([[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, ...]])
作用:
用 0 和 1 区分一个序列中的不同句子(仅对“句子对”任务有用,如问答、句子匹配)。
规则:
- 0:表示属于第一个句子的 token
- 1:表示属于第二个句子的 token
举例(对应图片中 Out 的句子):
“[CLS] 第一个句子 [SEP] 第三个句子 [SEP]”
[CLS] 第一个句子 [SEP] → 标记为 0
第三个句子 [SEP] → 标记为 1
在填空任务中的用途:
如果填空任务涉及“句子对”(如“根据上文补全下文”),模型需要用此区分两个句子的边界;单句填空任务中此参数可忽略。
3. attention_mask:标记有效 token(忽略填充位)
data.attention_mask
# 输出示例:array([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, ...]])
作用:用 1 和 0 标记哪些 token 是有效文本(需关注),哪些是填充([PAD],需忽略)。
规则:
- 1:表示该位置是有效文本 token(模型需要处理)
- 0:表示该位置是填充 token([PAD],模型应忽略)
为什么需要?
由于模型输入要求固定长度(如 max_length=20),短句子会用 [PAD] 填充到指定长度。attention_mask 告诉模型:“不要关注这些填充位,它们没有实际语义”。
在填空任务中的用途:
确保模型在预测 [MASK] 位置时,不会被无意义的填充 token 干扰。
4. 问题扩展
1、为什么 token_type_ids 通常只标记第二段为1?

模型本身有限制,只适用于处理句子对或者两段的句子。
2、多段文本如何处理?
使用用特殊符号分隔+单段处理(推荐):
原理:
- 将所有段落拼接为 单段文本,用特殊符号(如 [SEP] 或自定义 [PARAGRAPH])分隔
- token_type_ids 全程标记为 0,让模型通过分隔符自主学习段落边界
# 输入:[CLS] 段1 [SEP] 段2 [SEP] 段3 [SEP] 段4 [SEP]
token_type_ids = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] # 全0标记
优势:
- 无需修改 token_type_ids,兼容BERT等模型设计
- 模型可通过 [SEP] 符号学习段落边界(预训练时已接触过类似结构)
- 适合多轮对话(如将历史对话拼接为单段,用 [SEP] 分隔每轮对话)
三、数据集基本操作
from datasets import load_dataset
#可用的数据集:https://huggingface.co/datasets
#在线加载一个数据集
dataset = load_dataset(path='lansinuote/ChnSentiCorp', name=None, split=None)
dataset, dataset['train'][0]

#保存到本地
dataset.save_to_disk('dataset/lansinuote/ChnSentiCorp')

from datasets import load_from_disk
#从本地加载
dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#遍历每一条数据并进行处理
def f(data):
#新增字段
data['new_column'] = data['text'][:5]
#删除字段
del data['label']
#修改字段
data['text'] = 'prefix_' + data['text']
return data
dataset = dataset.map(f)
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#过滤数据集
f = lambda x: x['label'] == 1
dataset = dataset.filter(f)
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#map和filter时可以使用批量处理,同时使用多线程并行处理
#在某些环境下使用多线程会卡住,出现这种情况时请切换到单线程,num_proc=1
def f(data):
data['new_column'] = [i[:5] for i in data['text']]
return data
dataset = dataset.map(f, batched=True, batch_size=5, num_proc=2)
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#删除字段
dataset = dataset.remove_columns(['label'])
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#重命名字段
dataset = dataset.rename_columns({'text': 'new_text', 'label': 'new_label'})
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#设置字段的数据类型,可选的有np,pt,tf
dataset.set_format('pt', columns=['label'], output_all_columns=True)
dataset, dataset['train'][0]

from datasets import concatenate_datasets
dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#合并多个数据集
dataset = concatenate_datasets(list(dataset.values()))
dataset, dataset[0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#切分一个数据集为训练集和测试机,可以指定比例,也可以直接指定数量
dataset = dataset['train'].train_test_split(test_size=0.1, train_size=8640)
dataset, dataset['train'][0]

dataset = load_from_disk('dataset/lansinuote/ChnSentiCorp')
#取数据集中的某些数据
dataset = dataset['train'].select([5, 15, 20, 50])
dataset, dataset[0]

四、加载本地数据集
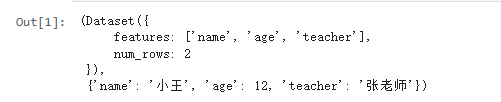
from datasets import Dataset
#从一个字典创建数据集
dataset = {'name': ['小王', '小李'], 'age': [12, 16], 'teacher': ['张老师', '马老师']}
dataset = Dataset.from_dict(dataset)
dataset, dataset[0]
#使用一个函数生成数据集
def f():
yield {'name': '小王', 'age': 12, 'teacher': '张老师'}
yield {'name': '小李', 'age': 16, 'teacher': '马老师'}
dataset = Dataset.from_generator(f)
dataset, dataset[0]

from datasets import load_dataset
#保存一个数据集为csv格式
dataset.to_csv('dataset/sample.csv')
#从csv文件创建数据集
dataset = load_dataset('csv', data_files='dataset/sample.csv', split='train')
dataset, dataset[0]

from datasets import load_dataset
#保存一个数据集为json格式
dataset.to_json('dataset/sample.json')
#从json文件创建数据集
dataset = load_dataset('json', data_files='dataset/sample.json', split='train')
dataset, dataset[0]

五、创建模型
import torch
from transformers import BertConfig, BertModel
#使用配置文件创建一个bert模型
config = BertConfig(vocab_size=15000, num_hidden_layers=4)
model = BertModel(config)
#使用该模型进行试算,输入数据是4句话,每句话125个词
input = {
'input_ids': torch.randint(100, 10000, [4, 125]),
'attention_mask': torch.ones(4, 125).long()
}
with torch.no_grad():
out = model(**input)
#计算结果是把这4句话向量化了
#可以基于这些向量做各种下游任务
config, out.last_hidden_state.shape

from transformers import GPT2Config, GPT2Model
#使用配置文件创建一个gpt2模型
config = GPT2Config(vocab_size=15000, n_layer=4)
model = GPT2Model(config)
#执行试算
with torch.no_grad():
out = model(**input)
config, out.last_hidden_state.shape

from transformers import BertConfig, BertForSequenceClassification
#直接创建一个语句分类模型
config = BertConfig(vocab_size=15000, num_hidden_layers=4, num_labels=3)
model = BertForSequenceClassification(config)
#执行试算,参数中包括labels,可以直接计算loss
input_with_labels = {
'input_ids': torch.randint(100, 10000, [4, 125]),
'attention_mask': torch.ones(4, 125).long(),
'labels': torch.ones(4).long()
}
with torch.no_grad():
out = model(**input_with_labels)
config, out.loss, out.logits.shape

from transformers import AutoModel
#可用的模型:https://huggingface.co/models
#在线加载一个预训练模型
model = AutoModel.from_pretrained('google-bert/bert-base-chinese')
#执行试算
with torch.no_grad():
out = model(**input)
out.last_hidden_state.shape
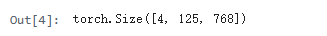
#保存一个模型到本地磁盘
model.save_pretrained('model/google-bert/bert-base-chinese')
#从本地磁盘加载模型
model = AutoModel.from_pretrained('model/google-bert/bert-base-chinese')

项目地址:
https://github.com/lansinuote/Simple_HuggingFace
HuggingFace国内官网:
https://hf-mirror.com/

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)