【网安毕设项目】基于启发式规则匹配的web漏洞检测系统设计与实现
本文介绍了一个基于Python+Flask的Web应用漏洞扫描系统,包含六大功能模块:用户管理、漏洞扫描、漏洞历史、漏洞库管理、可视化分析和系统管理。系统采用动态应用安全测试(DAST)技术,通过构造特定HTTP请求模拟攻击,结合静态分析与动态检测识别SQL注入、XSS等漏洞。后端使用MySQL存储数据,前端通过ECharts实现可视化展示。系统具有轻量级、高效率的特点,适用于渗透测试和企业安全自
全套资料包含:项目源码+开发文档+部署指导说明+万字LW,有需要的私信博主,伸手党勿扰
项目需求:
系统采用Python+flask框架开发,主要包括用户管理、漏洞扫描、漏洞历史、漏洞库管理、可视化分析和系统管理六大核心功能模块,其中后台管理端主要包含用户管理、漏洞库管理,系统管理等。其中,漏洞扫描模块结合静态分析与动态检测技术,实现对多种Web漏洞的识别;数据库采用MySQL存储漏洞信息;前端基于ECharts实现数据大屏展示,提供直观的漏洞分布、扫描趋势等可视化分析功能
实现效果:
Web应用漏洞扫描系统开发文档
1. 项目概述
本系统旨在开发一个轻量级的Web应用漏洞扫描器(Web Vulnerability Scanner),专为快速识别目标Web应用中存在的常见安全风险而设计。随着互联网业务的复杂化,SQL注入、跨站脚本(XSS)、敏感文件泄露等漏洞已成为主要的安全威胁。本系统通过自动化手段,模拟黑客攻击逻辑,对目标URL进行深度探测,从而帮助安全工程师或开发者及时发现并修复安全隐患。系统不仅具备基础的漏洞识别能力,还强调扫描的准确性和效率,力求在误报率和漏报率之间取得平衡。
核心功能包括敏感目录扫描,通过字典爆破技术探测服务器上可能存在的未授权访问资源;注入漏洞检测,覆盖SQL注入、跨站脚本(XSS)及远程命令执行(RCE)等高危风险;以及安全配置审计,检查HTTP响应头、SSL/TLS配置等是否符合安全最佳实践。适用场景主要集中在渗透测试的前期信息收集阶段,以及企业内部资产的常态化安全自查,以构建纵深防御体系。
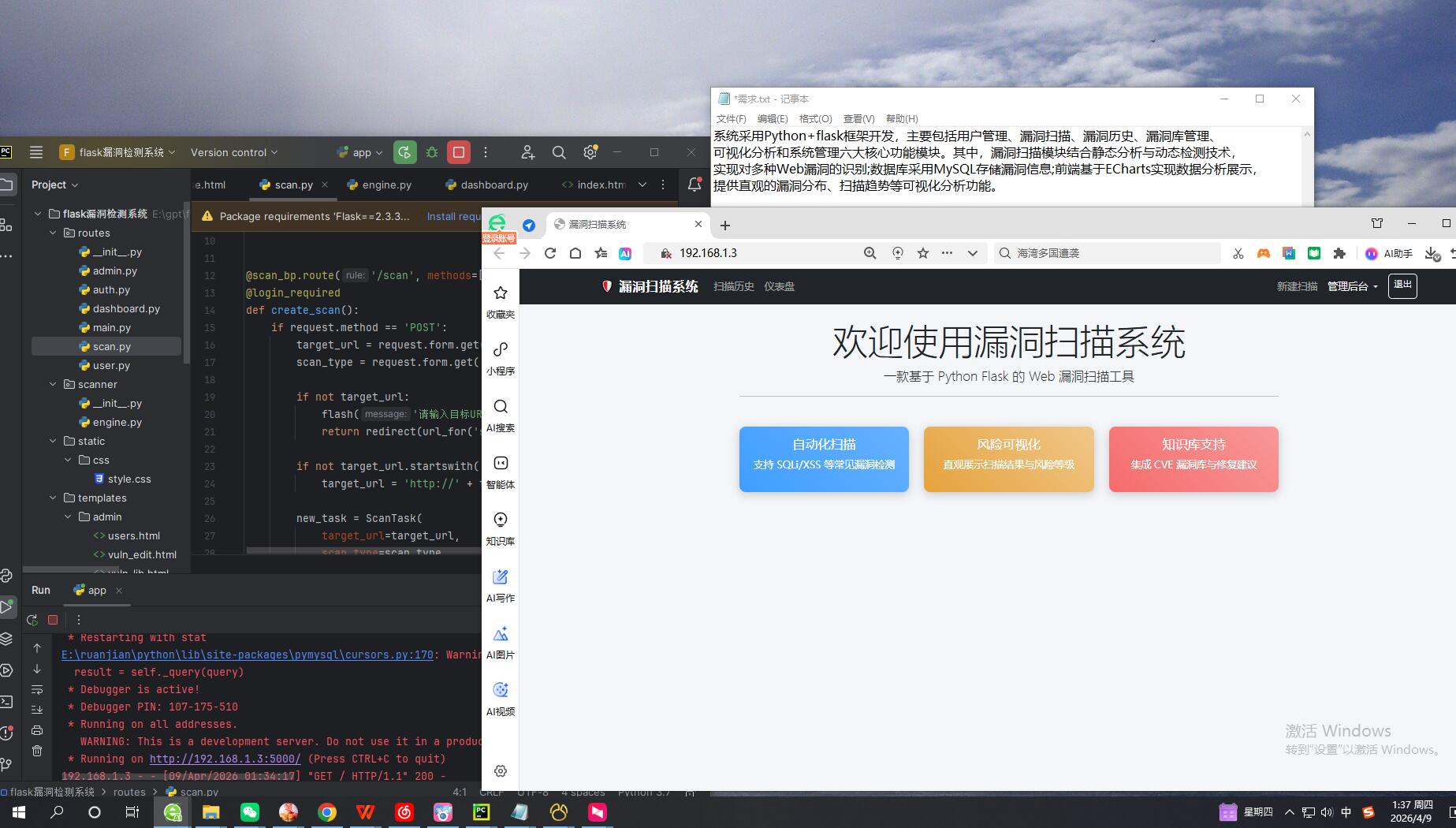
2. 技术架构与环境
本系统采用Python语言作为主要开发语言,基于Flask Web框架构建任务管理后台,利用Requests库进行高效的网络交互。Python以其丰富的第三方库和简洁的语法,极大地提升了开发效率,特别是在处理网络协议和数据解析方面表现优异。
3. 核心模块设计
漏洞扫描引擎是系统的核心逻辑,主要对应文件 scanner/engine.py。该模块负责执行具体的探测任务,其设计遵循高内聚、低耦合的原则。在初始化阶段,引擎会加载全局配置,设置HTTP请求头以模拟Chrome浏览器,并设定合理的超时时间以防止程序挂起。主流程分为三个阶段:首先是静态分析,主要针对常见的备份文件和敏感目录进行探测;其次是动态分析,通过构造特定的Payload(有效载荷)与目标应用交互,检测注入类漏洞;最后是逻辑分析,检查SSL配置的有效性以及特定的安全头(如CSP、HSTS)是否存在缺失。
任务管理模块则负责系统的调度工作。它接收来自用户界面或API创建的扫描任务,根据任务优先级进行排队,并调用扫描引擎执行。同时,该模块负责监听扫描进度,并将最终的扫描结果持久化存储到数据库中,以便后续生成报告或进行数据分析。
4. 详细实现(scanner/engine.py)
在初始化配置中,系统设置了标准的HTTP请求头,特别是User-Agent字段模拟了主流的Chrome浏览器,这有助于降低被目标Web应用防火墙(WAF)识别为机器流量而拦截的概率。同时,设置了8秒的超时时间,以平衡网络延迟和扫描效率,避免因单个请求无响应而导致整个扫描任务阻塞。
敏感文件检测模块通过遍历预定义的敏感路径字典(如 /.git/config, /backup.sql, /admin.php)来工作。判定逻辑不仅依赖于HTTP状态码(如200),还会进一步分析响应体内容,通过正则匹配排除“伪404”页面,从而准确识别出真实存在的敏感文件泄露。
注入漏洞检测是系统最复杂的部分。针对SQL注入,系统使用单引号、双引号及逻辑语句(1=1 和 1=2)进行闭合测试,并匹配数据库特有的报错信息(如 SQL syntax, mysql_fetch)或布尔盲注的页面差异。对于XSS检测,系统注入特定的 <script> 标签或事件处理器,随后检测响应体是否回显未经过滤的标签或脚本,从而判断是否存在反射型或存储型XSS。在RCE和目录遍历检测中,系统尝试执行简单的系统命令(如 cat /etc/passwd)或利用 ../ 字符串遍历路径,通过检测系统文件特征字符串来确认漏洞存在性。
安全配置检测模块主要负责合规性检查。SSL检测通过尝试建立HTTPS连接并捕获 SSLError 异常来判断证书的有效性及过期状态。此外,系统还会检查CSRF防护机制,通过解析HTML表单来检查是否存在随机Token字段,虽然这一功能在当前版本中尚在完善中,但已具备基础的解析能力。
5. 数据库设计 (models.py)
系统主要依赖两个核心数据模型来管理数据流转。首先是 ScanTask 模型,它负责记录每一次扫描任务的元数据,包括唯一的任务ID、目标URL、当前状态(如待扫描、运行中、已完成或失败)、创建时间戳以及结束时间戳。其次是 Vulnerability 模型,用于详细记录扫描过程中发现的安全隐患,包含漏洞ID、所属的任务ID(外键关联)、漏洞名称、风险等级(High/Medium/Low)、详细描述以及具体的漏洞位置(URL参数)。
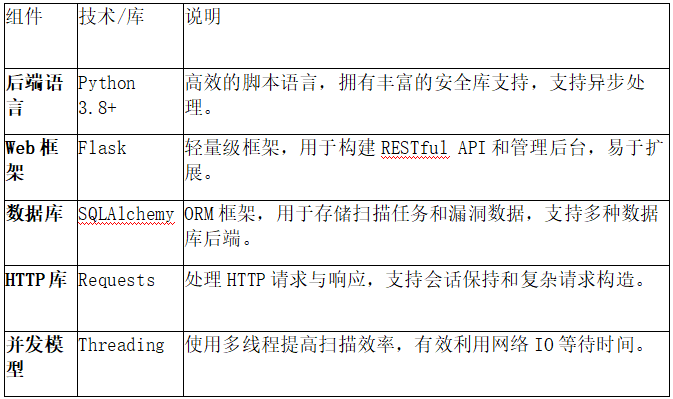
6. 风险等级定义
为了便于用户快速响应,系统根据漏洞的危害程度和利用难度进行了严格的分级管理。
7. 部署与运行
系统的部署流程设计得简洁明了。首先进行环境准备,通过 pip install -r requirements.txt 命令安装所有依赖库。随后进行数据库初始化,运行 python init_db.py 脚本来创建所需的表结构。最后,执行 python app.py 启动Flask服务,服务默认监听在5000端口,用户可通过浏览器或API客户端访问管理界面来创建和监控扫描任务。
8. 项目总结与展望
当前版本成功实现了基础的漏洞扫描功能,在准确率和扫描速度上表现良好,能够满足基础的安全评估需求。然而,面对日益复杂的Web架构和防护机制,系统仍有巨大的提升空间。未来的优化方向主要包括:一是增强Payload库,引入更复杂的Bypass WAF绕过技术,以应对云WAF和下一代防火墙的挑战;二是增加爬虫功能,利用先进的爬虫算法自动发现站点的深层链接和动态参数,实现全站无死角扫描;三是支持API扫描,增加对RESTful API接口的自动化测试,以适应微服务架构的普及。
核心业务流程:时序图解
为了更清晰地展示系统各组件间的交互,以下通过文字描述“用户发起扫描到生成报告”的完整时序流程:
1. 用户发起请求:用户在前端界面输入目标 URL,点击“开始扫描”。前端向 后端 API 发送 POST /scan 请求。
2. 任务创建与持久化:后端 API 接收到请求后,首先在数据库中创建一个状态为 PENDING 的 ScanTask 记录,并立即返回任务 ID 给前端。
3. 异步分发:后端 API 将任务 ID 推送到 消息队列(如 Redis/RabbitMQ),随后立即响应前端,避免阻塞用户界面。
4. 扫描执行:扫描工作器 监听消息队列,获取任务 ID。它从数据库读取任务详情,调用底层的扫描引擎(如 Nmap 或自定义脚本)对目标进行探测。
5. 结果回写:扫描完成后,扫描工作器 将原始数据解析,生成结构化报告,并更新数据库中 ScanTask 的状态为 COMPLETED,同时写入 Report 表。
6. 报告展示:前端通过轮询或 WebSocket 获知任务完成,请求 后端 API 获取报告详情,最终渲染展示给用户。
检测原理:
需求:
系统采用Python+flask框架开发,主要包括用户管理、漏洞扫描、漏洞历史、漏洞库管理、可视化分析和系统管理六大核心功能模块,其中后台管理端主要包含用户管理、漏洞库管理,系统管理等。
其中,漏洞扫描模块结合静态分析与动态检测技术,实现对多种Web漏洞的识别;数据库采用MySQL存储漏洞信息;前端基于ECharts实现数据大屏展示,提供直观的漏洞分布、扫描趋势等可视化分析功能
实现原理:
这个基于 Flask 的漏洞检测系统主要采用的是 动态应用安全测试 (DAST) 和 启发式规则匹配 的技术路线。
简单来说,它不是通过分析源代码来找漏洞(静态分析),而是像一个“黑盒”一样,站在攻击者的角度,向目标发送各种精心构造的请求,然后根据目标的“反应”(响应状态、内容特征等)来判断是否存在漏洞。
以下是该系统具体实现原理的详细拆解:
1. 核心检测逻辑:模拟攻击与响应分析
这是系统的“大脑”,完全对应你提供的“核心原理”。系统不依赖复杂的机器学习算法,而是依赖预设的规则库和逻辑判断。
构造请求(攻击模拟): 系统会根据不同的漏洞类型,生成特定的 HTTP 请求。
例如: 针对未授权访问,它会故意不带 Cookie/Token 去请求敏感接口;针对 SQL 注入,它会在参数后拼接 ' 或 AND 1=1。
分析响应(结果判定): 系统接收目标的 HTTP 响应,并根据启发式规则进行打分或判定。
判定依据: 状态码(200 vs 403)、响应包大小(是否有数据返回)、页面关键词(是否包含“admin”、“password”或数据库报错信息)。
2. 具体漏洞检测原理实现
根据你提供的分类,系统内部针对不同漏洞有不同的检测模块:
A. 未授权访问检测 (Unauthorized Access)
原理实现:
爬虫/接口发现: 首先通过爬虫或字典扫描,发现系统的敏感路径(如 /api/user/info, /admin/dashboard)。
去权请求: 构造一个标准的 HTTP GET/POST 请求,刻意移除 所有认证信息(Header 中不包含 Authorization,Cookie 为空)。
规则匹配:
如果响应状态码为 200 OK。
且响应体中包含敏感数据特征(如 JSON 字段中有 user_id, phone,或者页面标题包含“后台管理”)。
结论: 判定存在未授权访问漏洞。
B. 越权访问检测 (IDOR - Insecure Direct Object References)
原理实现:
账号准备: 系统通常需要维护两个会话(Session A 和 Session B),分别代表普通用户 A 和 用户 B。
流量录制与重放:
先用账号 A 访问资源(例如 GET /api/order?id=1001),获取正常响应。
水平越权测试: 保持账号 A 的登录态,将参数修改为属于账号 B 的 ID(如 id=1002),发送请求。
垂直越权测试: 用普通用户 A 的权限,尝试访问管理员接口(如 POST /admin/delete_user)。
差异分析: 对比修改参数后的响应。如果返回了 200 状态码且数据内容发生了变化(成功获取了别人的数据),则判定存在越权漏洞。
C. 文件/图片访问检测 (敏感文件泄露)
原理实现:
URL 枚举: 针对静态资源服务器或对象存储(OSS/S3),使用字典爆破文件名或遍历 ID。
签名与时效性检测:
尝试直接访问一个已知的私有图片 URL。
尝试修改 URL 中的签名参数(如 signature=xxx)或时间戳参数。
判定逻辑:
如果去掉了签名参数依然能访问(200 OK) -> 严重漏洞(公有读权限配置错误)。
如果修改 ID 能访问到其他用户的私有图片 -> 越权读取。
如果返回 403 Forbidden 或 404 Not Found -> 安全。
D. 参数模糊测试 (Fuzzing)
原理实现:
Payload 库: 系统内置了大量的“攻击载荷”(Payloads),例如 SQL 注入的 ' OR '1'='1,XSS 的 <script>alert(1)</script>。
自动化变异: 对 URL 的每一个参数(GET/POST)进行遍历,将参数值替换为 Payload。
异常捕获:
SQL 注入: 观察响应是否包含数据库报错关键词(如 "SQL syntax", "MySQL")或页面长度发生剧烈变化。
XSS: 观察响应包中是否原样输出了 <script> 标签(反射型 XSS)。
3. 系统架构与流程 (基于 Flask)
整个检测流程在 Flask 中是这样流转的:
用户输入层: 用户在 Flask 前端页面输入目标 URL(如 http://target.com)。
任务调度层 (Flask Backend):
Flask 接收请求,将扫描任务写入数据库(MySQL),状态设为 PENDING。
为了不影响网页响应,通常使用多线程或消息队列(如 Celery+Redis)在后台异步执行扫描。
扫描引擎层 (核心):
爬虫模块: 使用 requests + BeautifulSoup 爬取目标网站结构,提取所有链接和表单。
检测模块: 调用上述的“未授权检测”、“Fuzzing”等函数,对提取的链接逐一“试探”。
报告生成层:
扫描结束后,将结果(漏洞类型、URL、请求包、响应包)存入数据库。
利用 Jinja2 模板引擎生成可视化的 HTML 报告,甚至可以生成 PDF 文件供用户下载。
总结
这个系统的本质是一个自动化的“黑盒”测试工具。它不修改代码,也不分析代码逻辑,而是通过“输入异常数据 -> 观察输出异常”这一经典的启发式方法,来模拟黑客的攻击路径,从而发现未授权访问、越权、注入等常见 Web 漏洞。
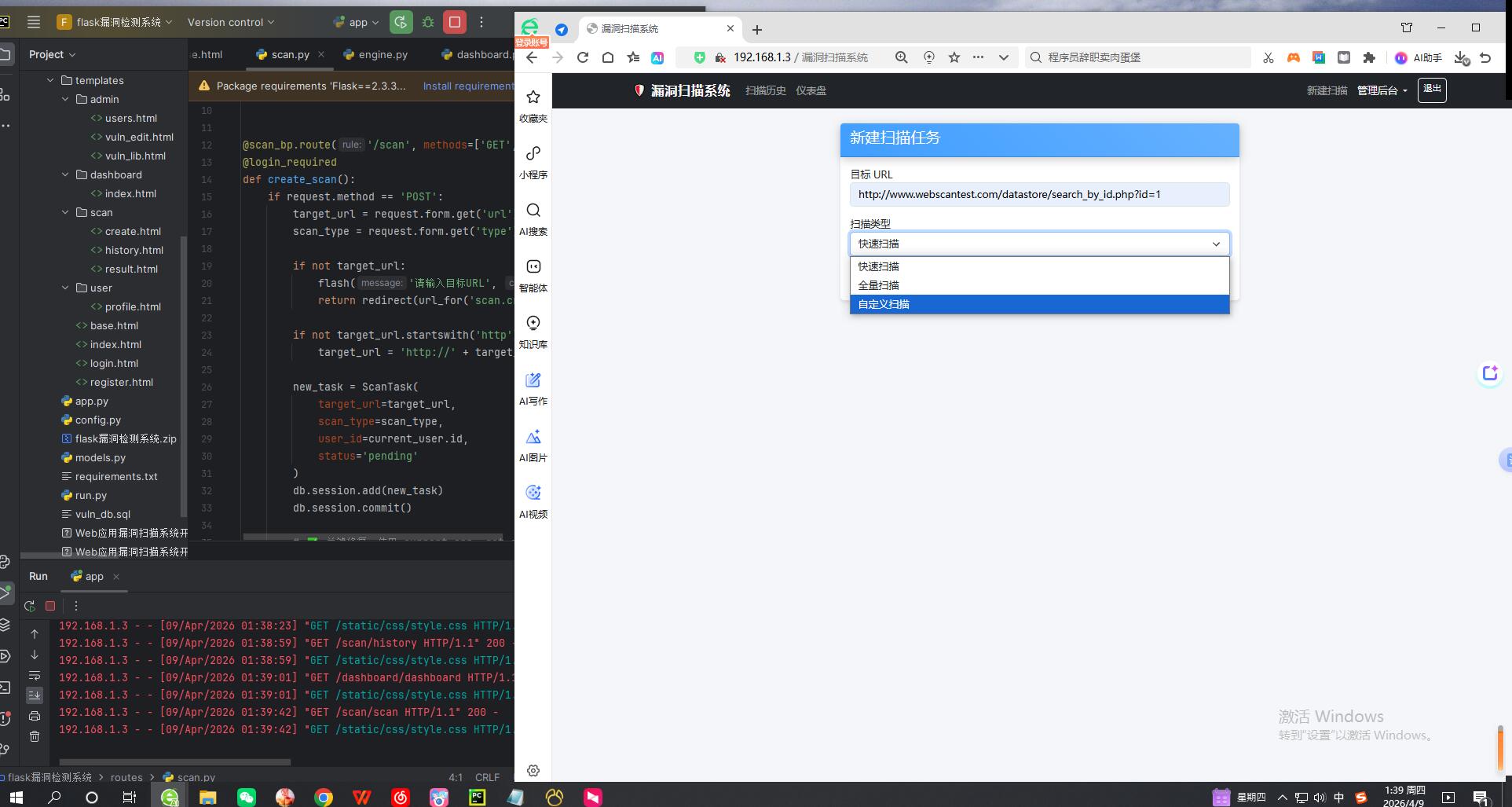
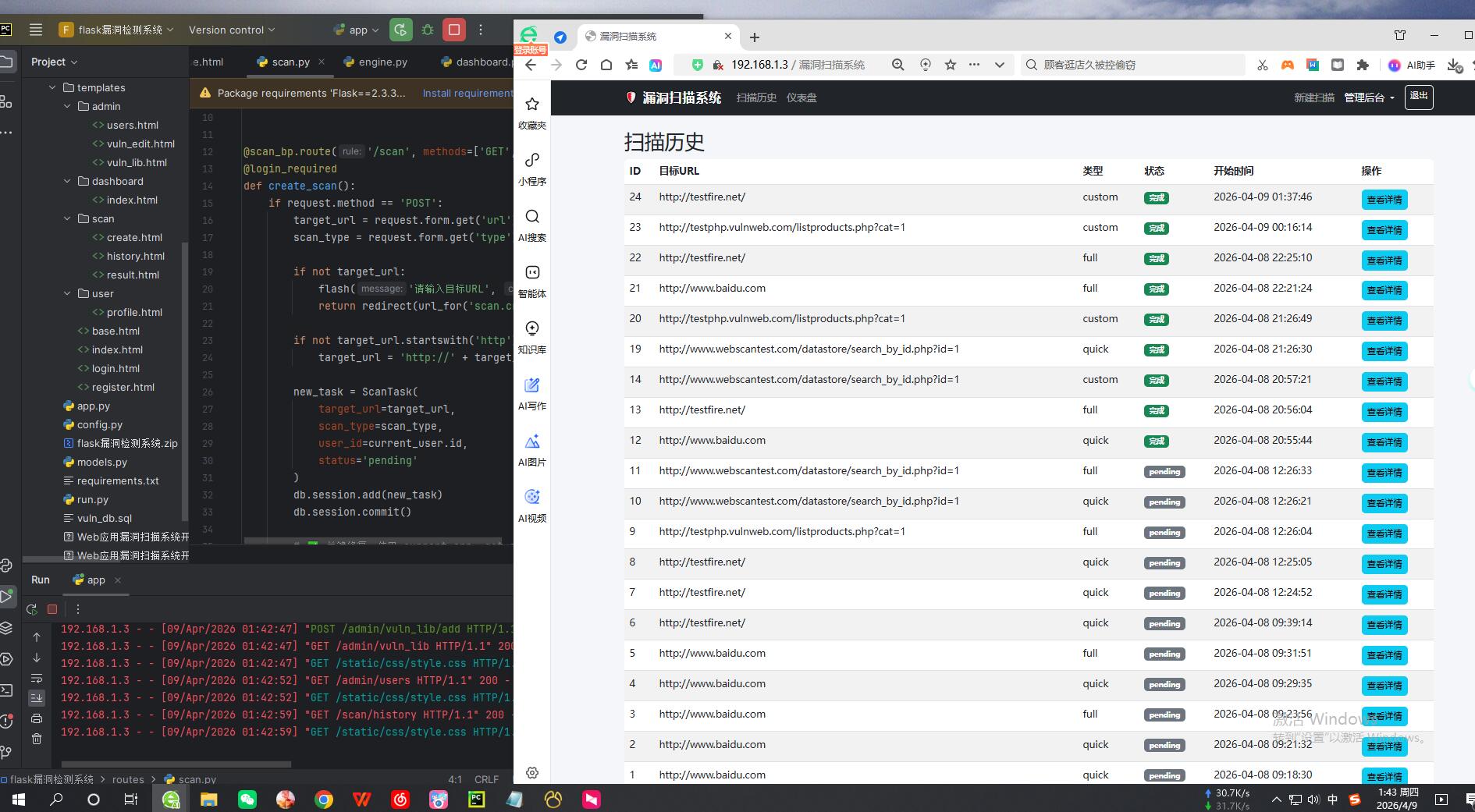
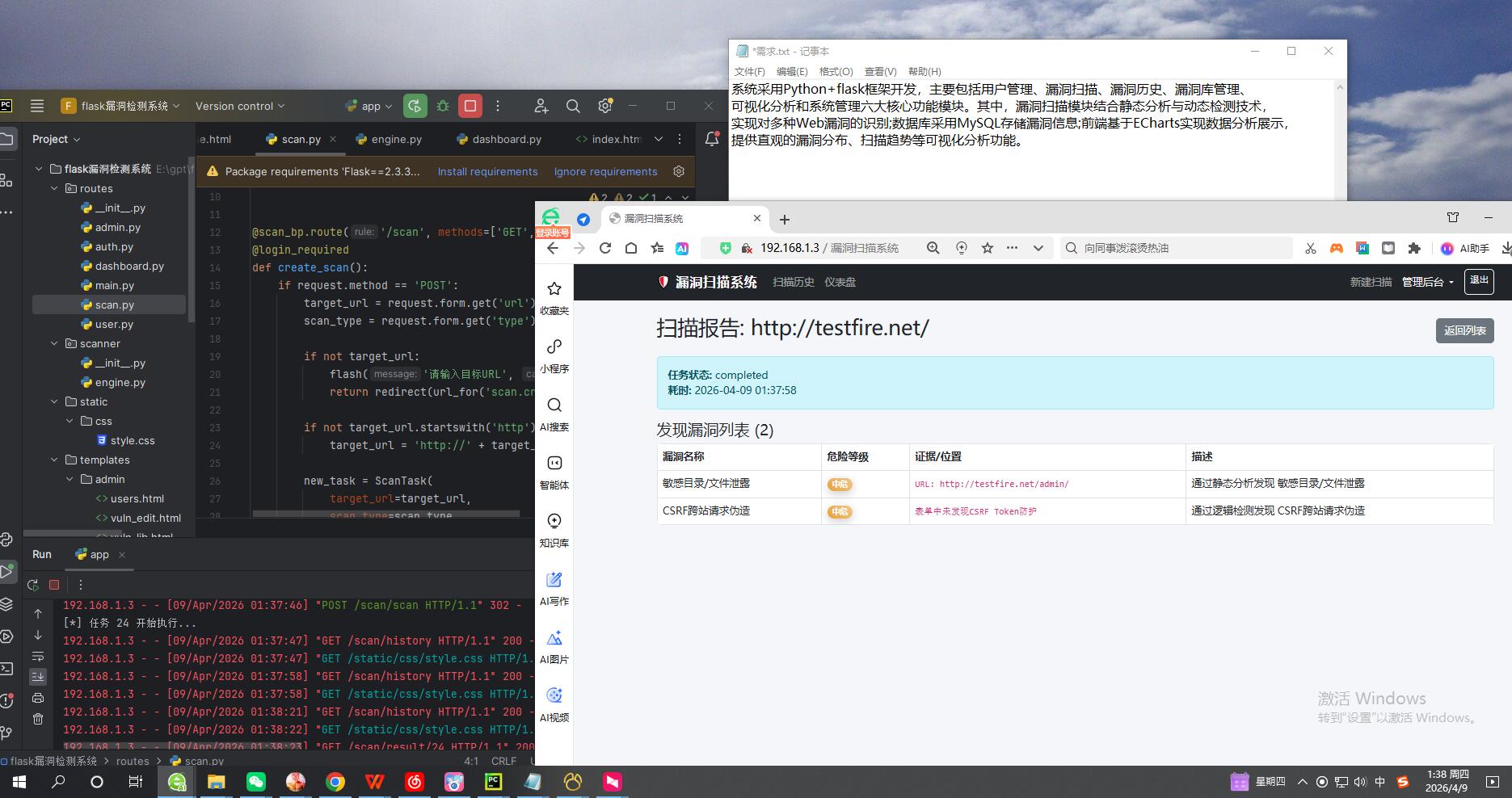
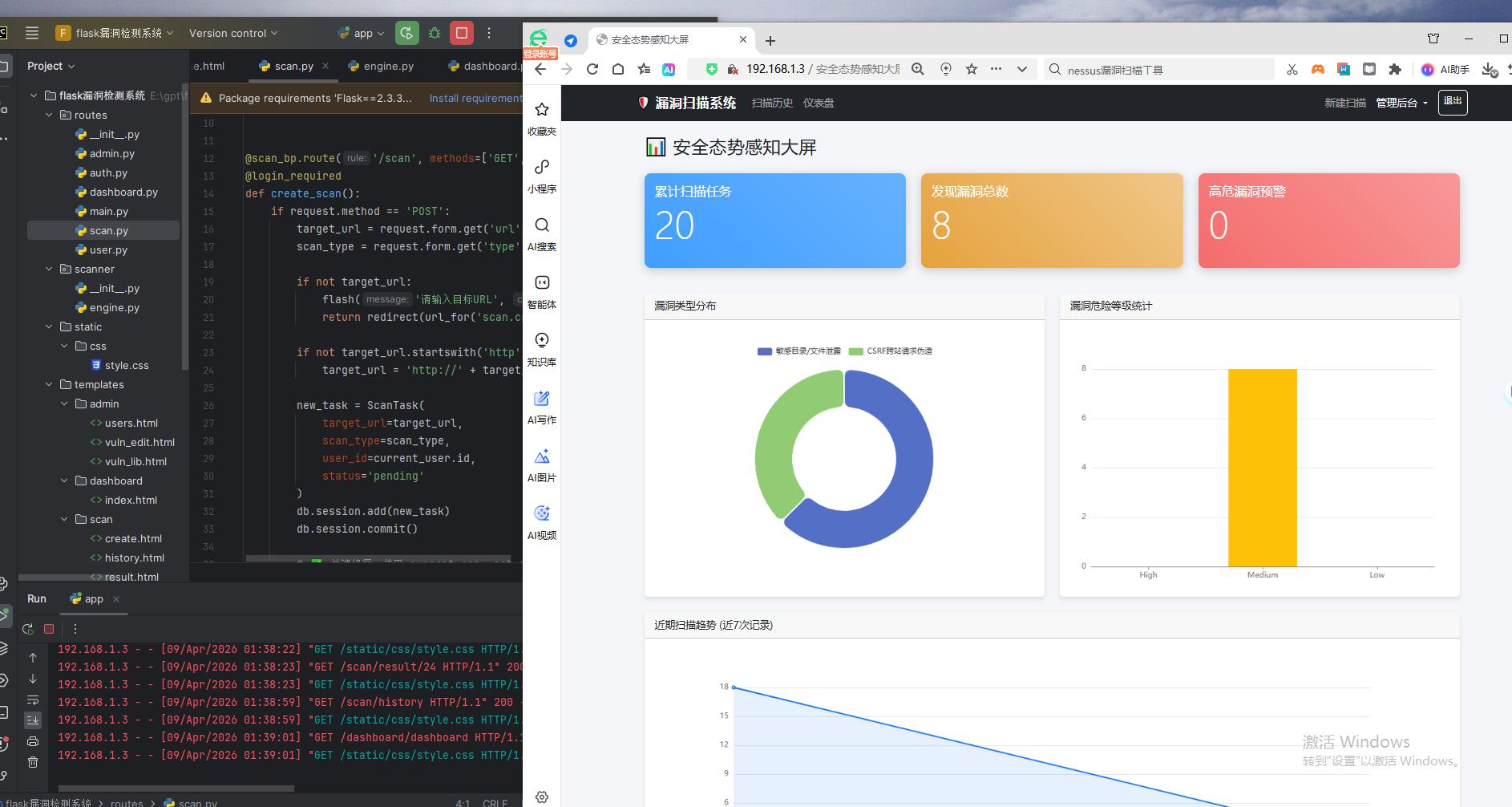
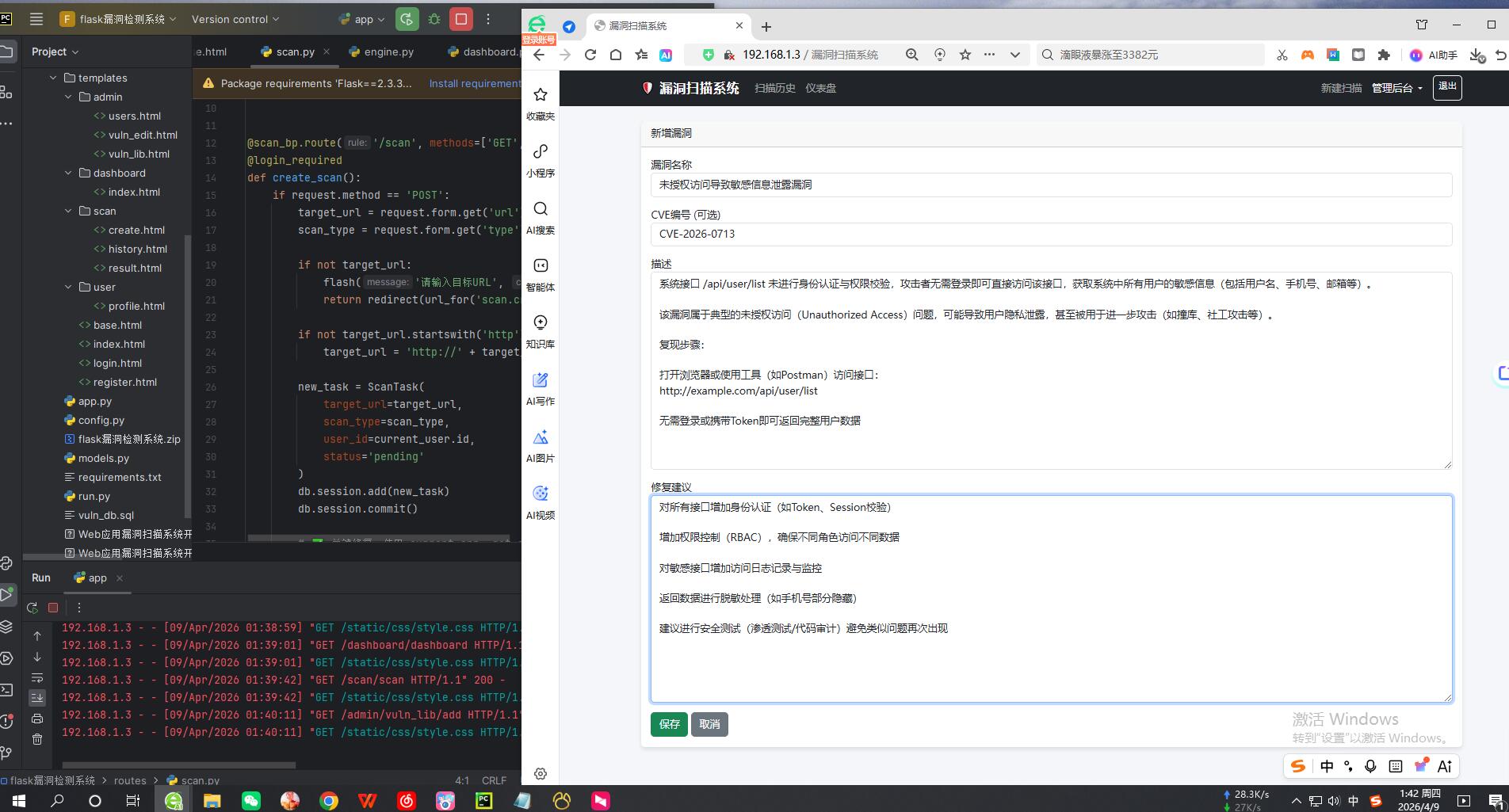
剩余效果截图:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献125条内容
已为社区贡献125条内容

所有评论(0)