Agentic AI 运营效率:借助 YugabyteDB Performance Advisor 实现更智能的可观测性
YugabyteDB Aeon 最近推出了 Performance Advisor,这是一款强大的新工具,将智能可观测性直接集成到您兼容 PostgreSQL 的分布式数据库中。在本文中,我们将深入探讨 YugabyteDB Performance Advisor 的新功能
Agentic AI 运营效率:借助 YugabyteDB Performance Advisor 实现更智能的可观测性
Kyle Hailey
2025 年 8 月 26 日
YugabyteDB Aeon 最近推出了 Performance Advisor,这是一款强大的新工具,将智能可观测性直接集成到您兼容 PostgreSQL 的分布式数据库中。在本文中,我们将深入探讨 YugabyteDB Performance Advisor 的新功能(目前处于技术预览阶段),并展示它如何帮助您的团队:
- 更快地优化数据库性能
-
- 让可观测性从被动变为主动
-
- 过滤告警噪音,更快地解决问题
-
- 将更多时间用于创新,而非缓解问题
更智能的洞察,而非更多的数据
传统的监控工具会用指标和告警轰炸您,往往让您在噪音中搜寻答案,而非直接找到问题。面临的挑战包括:
- 充满模糊指标的杂乱仪表板
-
- 过度活跃的告警系统,要么向您发送大量垃圾信息,要么错过关键问题
-
- 数据过载和误报导致告警疲劳
Performance Advisor 通过统一的集群负载图表改变了这一局面,使您能够轻松监控系统是处于空闲、繁忙还是瓶颈状态。负载按活动类型进行颜色编码,因此您可以一目了然地看到数据库是在高效利用 CPU、等待 I/O、被锁阻塞,还是面临其他资源限制。
- 数据过载和误报导致告警疲劳
该界面提供了负载图表的两种强大视图:
- 一种将负载与 top SQL queries 关联,帮助您将性能影响追溯到特定的工作负载。
-
- 另一种将负载与 detected anomalies 关联,提供基于真实系统行为的结构化、可操作的洞察。
Performance Advisor 持续扫描集群中的异常,揭示根本原因,并引导您进行深入、直观的下钻分析。这意味着它提供清晰、可视化的答案,而非猜测。
- 另一种将负载与 detected anomalies 关联,提供基于真实系统行为的结构化、可操作的洞察。
核心能力
Performance Advisor 通过自动关联整个 YugabyteDB 集群的性能数据,彻底改变了数据库可观测性。它使您能够快速识别问题,无论这些问题源于单个查询、节点级资源限制、数据库配置问题,还是应用层效率低下。
这种全面的方法确保性能问题不会被遗漏,无论它们起源于分布式数据库环境中的哪个位置。
两种全面视图
Performance Advisor 在 Performance Advisor 菜单下引入了两个直观的新视图:
- Anomalies – 提供跨多个层级的集群范围异常检测:
-
- SQL 层级:查询执行和优化问题
-
- Node 层级:基础设施和系统级问题
-
- Database 层级:数据库引擎和存储异常
-
- Application 层级:应用层性能问题
-
- Queries – 专注于 SQL 和 CQL 性能分析,展示对集群负载和延迟贡献最大的查询,并提供详细的执行指标和等待状态分解。
这种整体方法能够识别分布式数据库堆栈中任何位置的系统性问题、性能瓶颈和热点。
- Queries – 专注于 SQL 和 CQL 性能分析,展示对集群负载和延迟贡献最大的查询,并提供详细的执行指标和等待状态分解。
下图展示了 Perf Advisor 菜单下的两个新视图:Anomalies 和 Queries。
1. Anomalies
Anomalies 视图包含两个部分:
- Cluster Load Chart
-
- Detected Anomalies
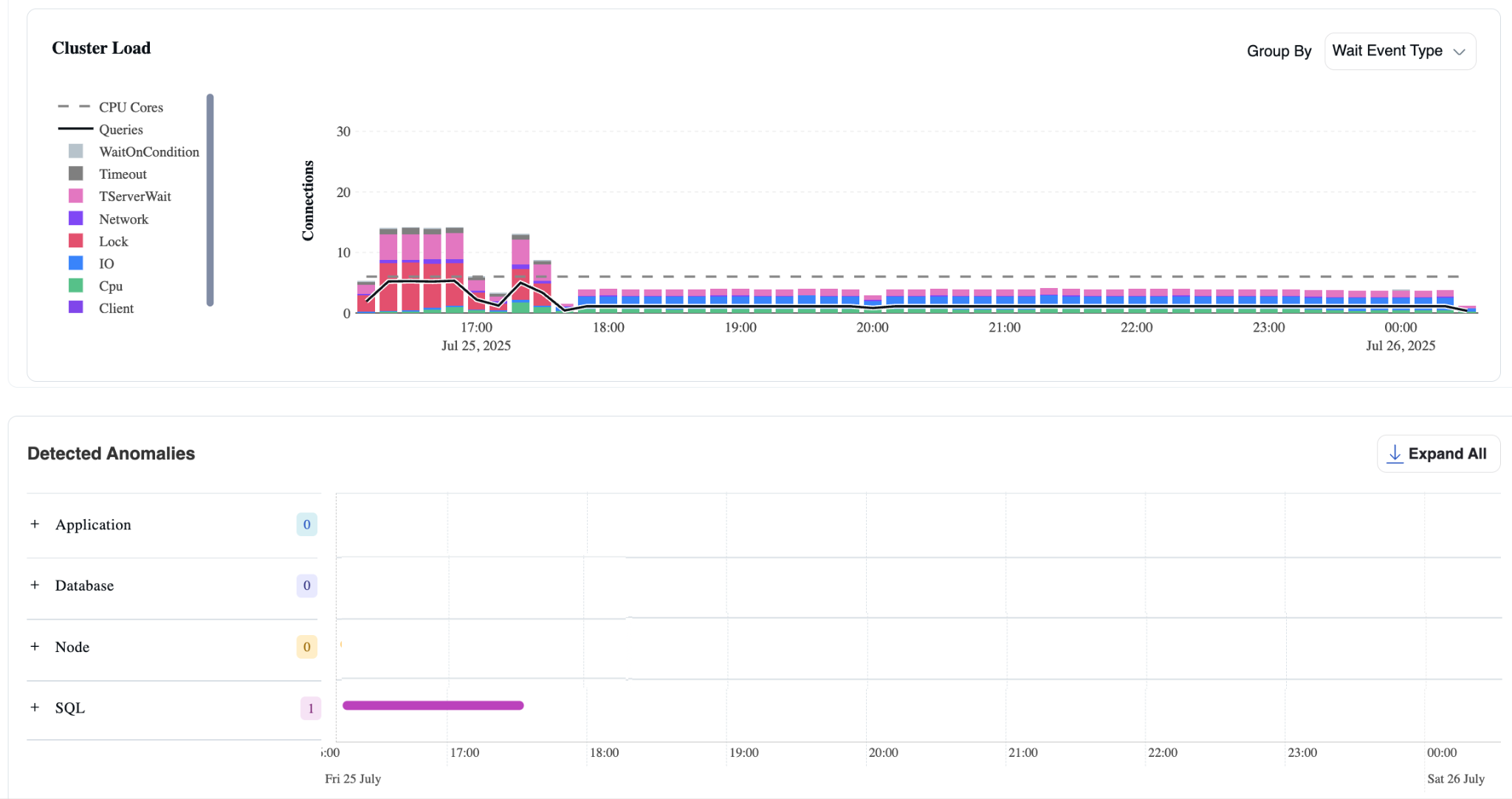
Cluster Load Chart
Cluster Load Chart 构建在 PostgreSQL 的 pg_stat_activity 表之上,该表为每个数据库连接维护一行数据。对于活跃连接,它会跟踪执行用户、正在运行的查询以及查询当前的等待状态(如 CPU、IO、Lock 或其他条件)。
查询通常处于"CPU"状态时表示它正在处理器上积极执行。否则,它可能在等待磁盘 I/O(例如从存储读取)、被另一个查询的锁阻塞,或在其他资源上停滞。这些被称为等待事件(wait events)。
为了增强对分布式性能的可见性,YugabyteDB 在 PostgreSQL 基础上扩展了针对其架构的额外等待事件。它还引入了一个新表:yb_active_session_history (ASH)。该表每秒对 pg_stat_activity 进行一次采样,并记录用户、查询文本和等待状态等关键信息。
Cluster Load Chart 使用此 ASH 数据来显示集群中所有节点的平均活跃会话数,按等待状态分组,为用户提供工作负载行为和系统健康状况的实时视图。
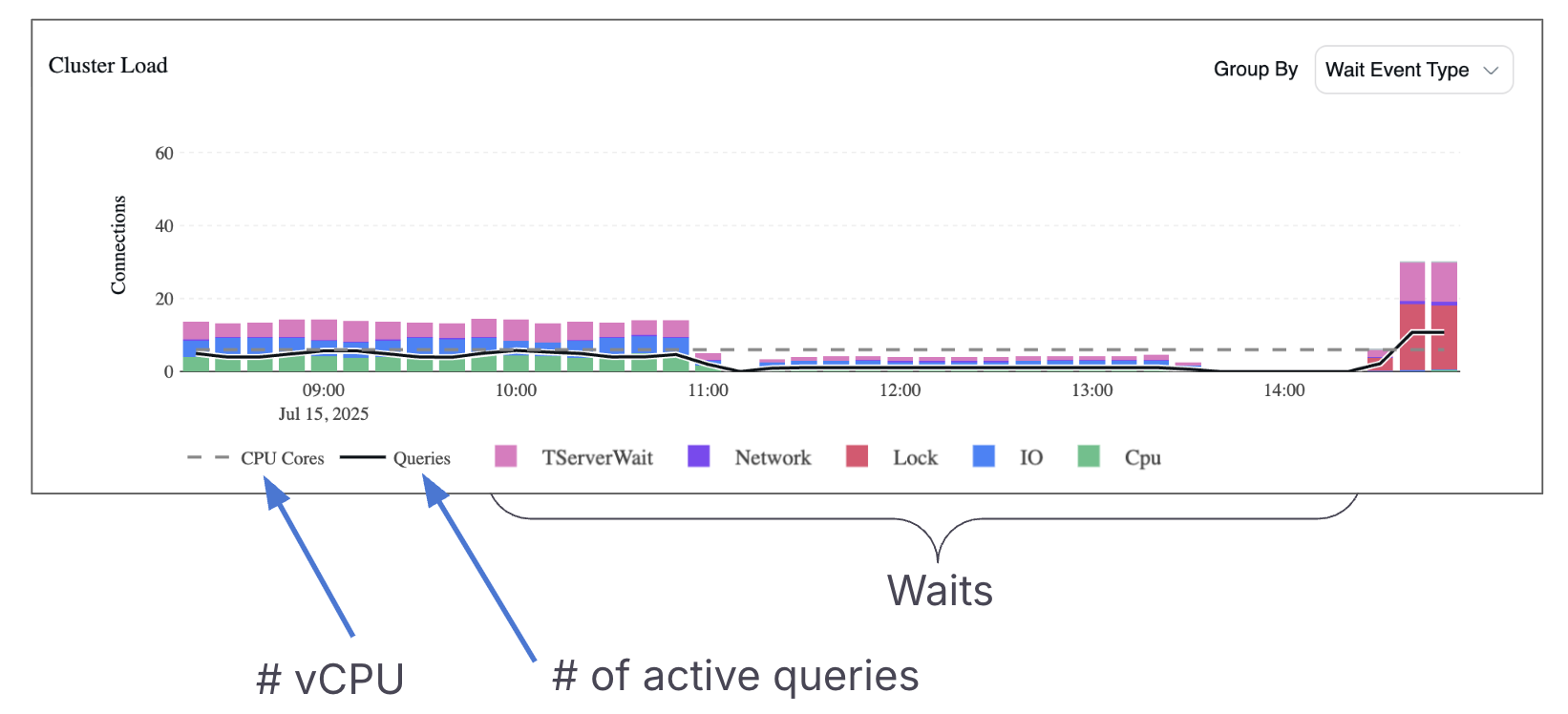
Cluster Load Chart 中每个条形的高度代表集群中活跃连接的总数。
每个段的颜色表示这些连接正在做什么,无论是处于 CPU 运行、等待 IO、被锁阻塞、经历网络延迟,还是处于其他状态。
YugabyteDB 架构中的一个关键细节是,每个查询通常由多个连接处理。初始连接会到达典型的 Postgres 进程。然后,查询被转发到本地 tserver(tablet server)上的一个线程。
本地 tserver 将查询转发到拥有相关数据的节点上的 tserver。如果查询触及分布在多个节点上的数据,可能会同时涉及多个 tserver,这意味着单个查询会跨越两个或更多活跃连接。
为了解释这一点,图表包含一条黑线,表示不同活跃查询的数量。通过将黑线与条形高度进行比较,您可以估算每个查询平均涉及多少个连接。
另一个重要的视觉指标是"CPU cores"线,它反映了集群中可用的 vCPU 总数。
这条线表示可以同时在 CPU 上活跃运行的最大查询数。如果受 CPU 限制的连接数超过 CPU 核心数,则意味着某些查询正在等待 CPU 时间,这表明存在潜在的资源竞争。
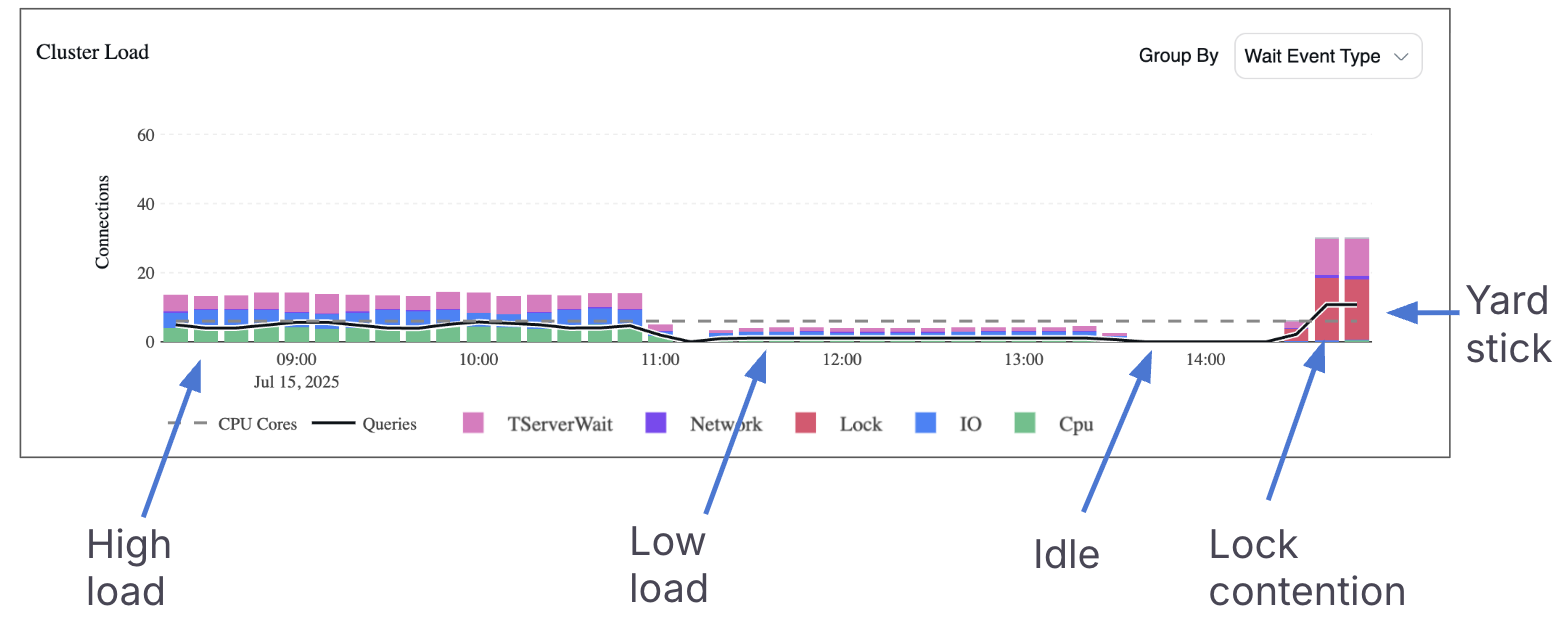
在上面的示例中,Cluster Load Chart 揭示了几个明显的工作负载模式:
- 左侧:活跃连接数超过 vCPU 数量的两倍,表明集群处于高负载状态。
-
- 中间部分:负载远低于 vCPU 线,表明集群有充足的余量来处理更多查询而不会导致性能下降。
-
- 中右侧:图表完全为空,这表明要么没有查询在运行,要么运行的查询完成得太快,没有留下可测量的痕迹。如果用户在此期间报告延迟缓慢,则问题可能出在数据库之外,例如应用层或网络。
-
- 最右侧:出现急剧峰值,且条形主要为红色,这代表锁竞争。这意味着许多查询在等待用户锁,导致工作负载执行明显变慢。
Detected Anomalies
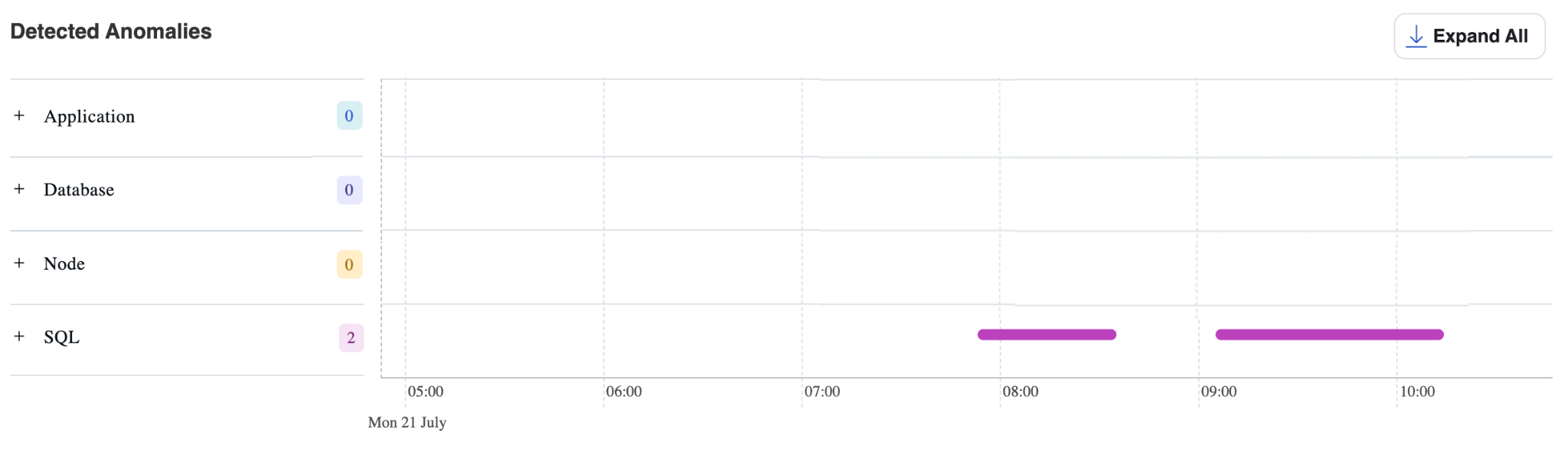
如集群负载图表所示,存在锁等待。当查询花费大量时间等待锁时,这些事件会显示在 Detected Anomalies 表中。
在上面的示例中,"SQL"部分显示一个洋红色条形,标记了检测到异常的时间窗口。左侧面板中的每个部分都可以展开,允许您探索涉及的具体查询并更详细地了解根本原因。

SQL 异常检测
SQL 部分监控三种类型的性能异常:
- Catalog Read Anomalies(目录读取异常)
-
- 检测阈值:查询花费超过 50% 的执行时间等待目录读取
-
- 根本原因:发生在检索查询执行所需的元数据时,例如表定义和模式信息
-
- 优化:可以通过实施适当的元数据缓存策略来消除此等待时间
-
- Lock Contention Anomalies(锁竞争异常)
-
- 检测阈值:查询花费超过 50% 的执行时间等待锁
-
- 影响:表明资源竞争会显著降低查询性能
-
- 示例:截图显示两个查询在此类别中经历了锁竞争等待
-
- SQL Latency Anomalies(SQL 延迟异常)
-
- 检测阈值:持续运行的查询,其延迟翻倍或超过基线性能
-
- 目的:识别随时间推移出现意外性能下降的查询
异常仪表板概览
Detected Anomalies 部分将结果组织为四个类别:
- Application – 应用层性能问题
-
- Database – 数据库引擎和存储异常
-
- Node – 基础设施和系统级问题
-
- SQL – 查询执行和优化问题
仪表板元素
- 异常计数:每个部分名称旁边的磁贴显示该类别中检测到的异常数量
-
- 时间线可视化:水平条形显示每个异常活跃的时间段
-
- 可展开部分:每个类别都可以展开,以查看该组中各个异常的详细信息
这种结构化方法使您能够快速识别和优先处理数据库堆栈不同层级的性能问题。
- 可展开部分:每个类别都可以展开,以查看该组中各个异常的详细信息
2. Queries
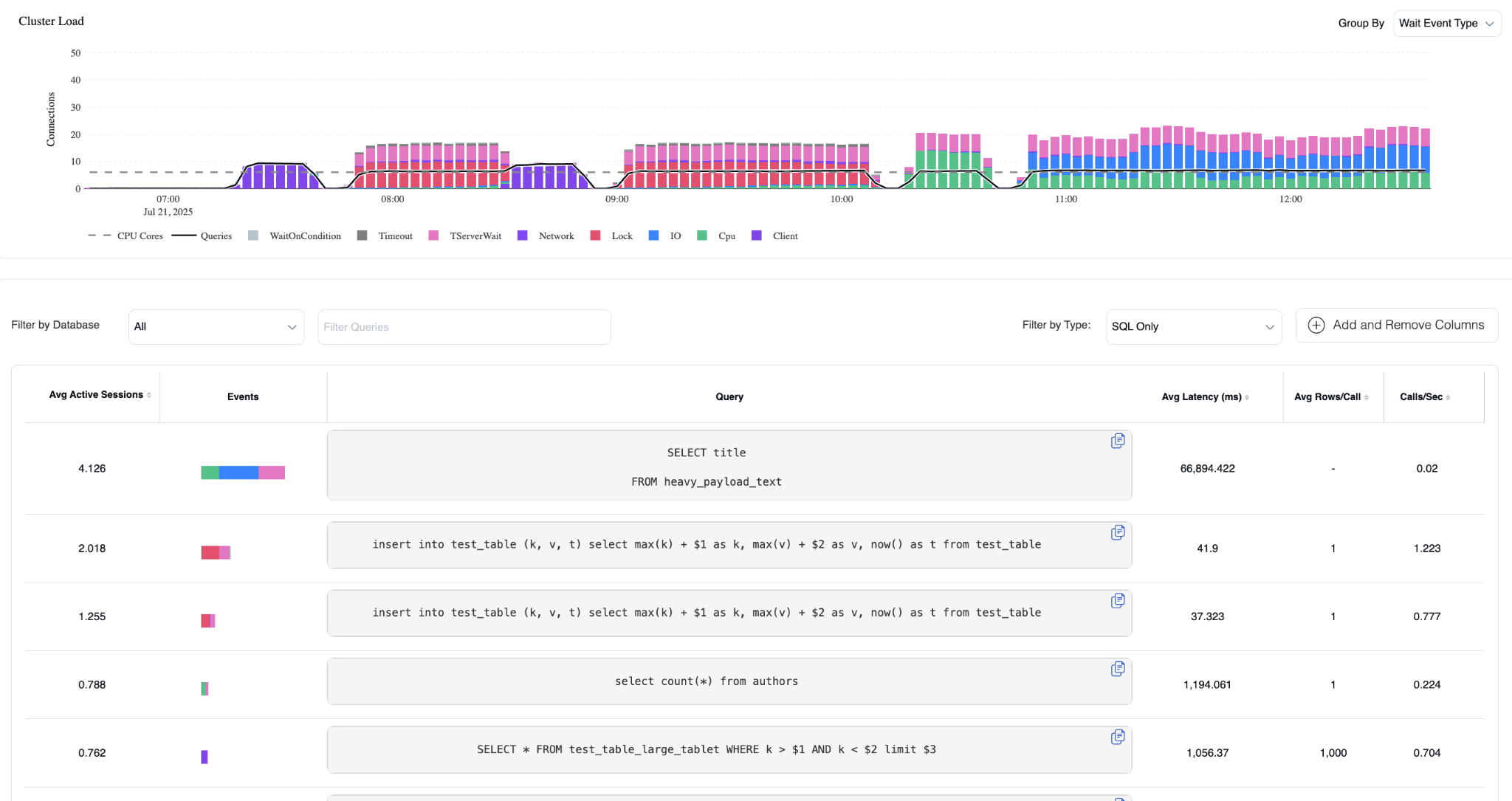
Queries 选项卡
Queries 视图提供详细的 SQL 级性能分析。它在顶部具有相同的集群负载图表,但增强了对驱动系统负载的具体查询的视图。
查询性能分析
在负载图表下方,SQL 语句按其相对集群性能的影响进行排名。这种优先级视图使您能够快速识别影响系统性能的最耗费资源的查询。
可视化负载分解
- 负载排名:查询按其对整体集群负载的贡献排序
-
- 等待状态可视化:每个 SQL 语句旁边的彩色条形显示该查询的特定等待状态
-
- 资源归属:例如,在当前视图中:
-
- 顶部查询几乎占用了所有 I/O(蓝色)
-
- 后续的 INSERT 语句主要负责锁竞争等待(红色)
下钻能力
每个查询条目都是交互式的,允许用户:
- 点击下钻详情:访问详细的 SQL 性能指标和分析
-
- 历史趋势:查看查询性能随时间的模式
-
- 细粒度监控:利用以一分钟间隔收集的 pg_stat_statements 数据进行精确的性能跟踪
数据收集框架
Performance Advisor 持续从 PostgreSQL 的 pg_stat_statements 扩展收集指标,提供:
- 实时洞察:逐分钟的性能数据收集
-
- 趋势分析:历史性能模式以识别性能下降或改进
-
- 全面覆盖:完全可见的查询执行统计信息和资源利用率
这种详细的查询级分析使数据库管理员能够快速识别、优先处理和解决 SQL 级的性能瓶颈。
- 全面覆盖:完全可见的查询执行统计信息和资源利用率
结论
Performance Advisor 代表了可观测性的一大飞跃,将嘈杂的指标转化为可操作的洞察。从实时负载图表到异常检测和查询级诊断,它使技术团队能够更快地解决性能问题,并将更多时间用于构建应用程序。
此功能目前作为技术预览版在运行 2024.2 或更高版本的 YugabyteDB Aeon 集群上提供。通过 YugabyteDB Anywhere (YBA) 的本地部署支持也即将推出。要为您的集群启用 Performance Advisor,请联系 YugabyteDB Support。
想了解如何构建稳健的 AI 应用程序吗?探索 latest YugabyteDB release 中引入的新的增强 AI 功能的优势。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)