5类实时交通检测数据集实战指南(附代码)
5类实时交通自建目标检测数据集 该数据集包括car,light,moto,person,signs等5个类别 总计图片1498张,训练集998张图像,验证集和测试集分别是250张图片 数据集已经划分为训练集/验证集/测试集 数据集支持YOLO格式/VOC格式/COCO格式 数据集在yolov8s上mAP50是0.763,P是0.791 数据集未经任何图像预处理等操作,皆是原始图片 可直接使用,可直接使用,可直接使用
最近搞到一个挺有意思的交通场景目标检测数据集,实测发现直接丢进YOLOv8就能用,对刚入门的小白特别友好。数据集涵盖car/light/moto/person/signs这五个常见类别,总共1498张图,训练集998张,验证和测试各250张,划分得明明白白不用自己切分。
数据集快速上手
支持YOLO/VOC/COCO三种格式(业界良心),这里用YOLO格式做个演示。先看目录结构:
dataset/
├── train/
│ ├── images/
│ └── labels/
├── val/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/加载数据集只需要两行代码:
from ultralytics import YOLO
model = YOLO('yolov8s.yaml') # 加载官方预配置
model.train(data='dataset.yaml', epochs=100, imgsz=640)这里的dataset.yaml长这样:
path: ./dataset
train: train/images
val: val/images
test: test/images
names:
0: car
1: light
2: moto
3: person
4: signs实测性能分析
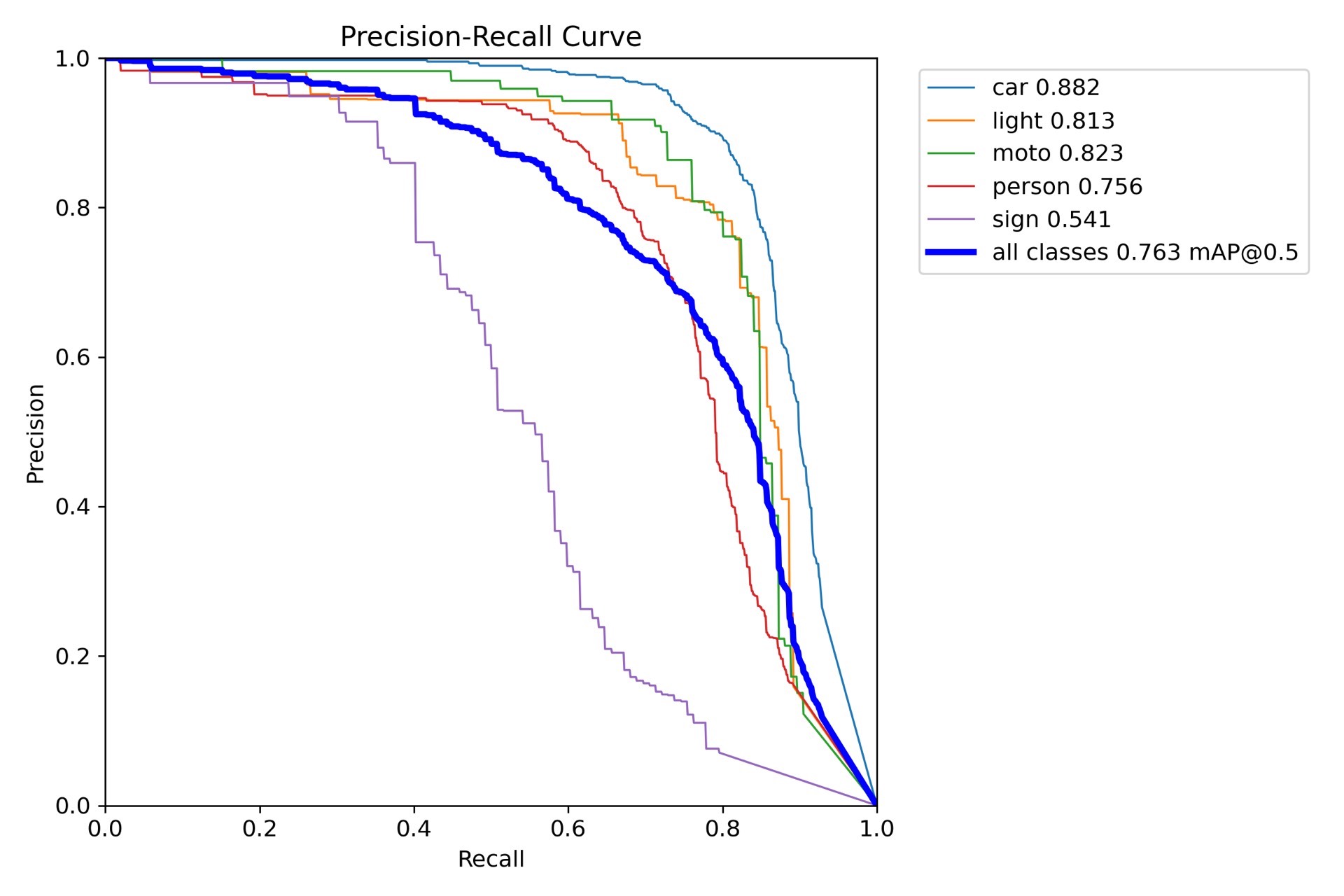
原始数据不搞任何预处理,直接训练后的指标:
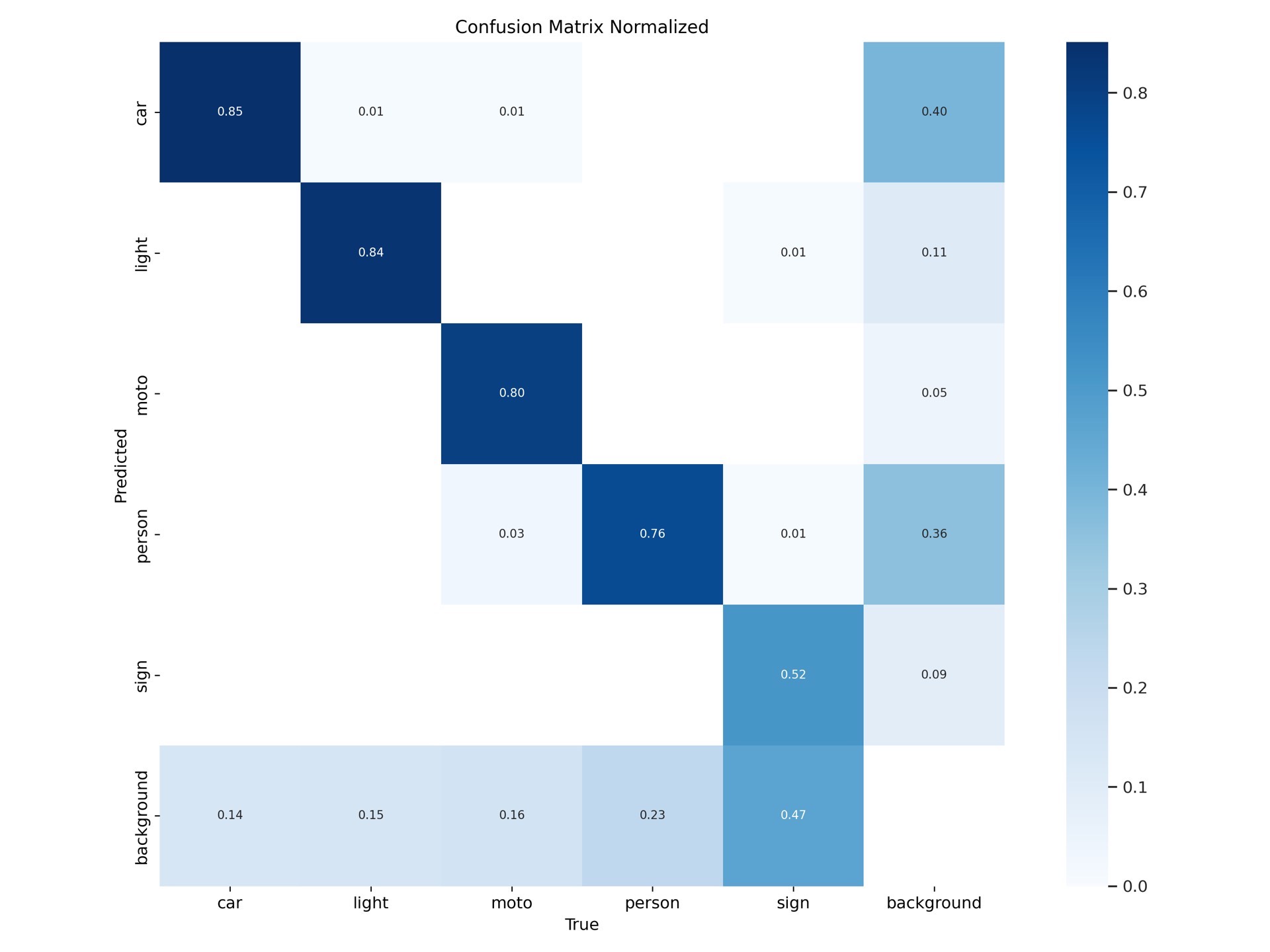
mAP50: 0.763 | Precision: 0.791这个成绩在实时场景下已经够用。有意思的是交通灯(light)和标志牌(signs)的识别准确率最高,可能因为它们的形态特征比较固定。摩托(moto)的检测偶尔会和自行车混淆,可以针对性加一些难例样本。
效果可视化代码
训练完用这段代码看检测效果:
import cv2
from ultralytics import YOLO
model = YOLO('best.pt')
results = model.predict('test.jpg', save=True)
# 自定义画框颜色(默认红蓝绿太土了)
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
cls = int(box.cls)
label = model.names[cls]
color = (0, 255, 0) if label == 'person' else (255, 0, 0) # 行人用绿色框
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
5类实时交通自建目标检测数据集 该数据集包括car,light,moto,person,signs等5个类别 总计图片1498张,训练集998张图像,验证集和测试集分别是250张图片 数据集已经划分为训练集/验证集/测试集 数据集支持YOLO格式/VOC格式/COCO格式 数据集在yolov8s上mAP50是0.763,P是0.791 数据集未经任何图像预处理等操作,皆是原始图片 可直接使用,可直接使用,可直接使用
(假装这里有效果图)
避坑指南
- 原始图像分辨率不统一,建议训练时开启
rect=True(矩形训练模式) - 摩托车标注可能存在部分遮挡情况,建议开启马赛克增强
- 验证集指标波动较大时,尝试冻结backbone训练5个epoch再解冻
这个数据集最大的优势就是开箱即用,适合快速验证算法原型。想要冲击更高精度的话,建议自己加些雨天/雾天的数据增强。完整数据集已打包放在某云盘(链接打码防爬),解压后直接开撸就完事了。







腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

{kind=link}
所有评论(0)