山东大学软件学院创新实训(四)
本文介绍了智能诊疗系统的阶段四开发进展,重点解决了医生端工作台的体验优化和智能辅助功能实现。在业务层面,修复了医生头像同步问题,通过统一数据源和审批流程确保档案一致性;在技术层面,采用FastAPI+Vue3架构,构建了基于OpenAI兼容API的诊疗智能辅助系统,支持本地轻量化模型(Ollama+千问3B)和云端通道双模式。系统实现了电子病历智能填充、处方辅助等功能,并通过权限控制确保数据安全。
关键词
智能诊疗;数据权限;FastAPI;Vue3;电子病历;处方;接诊统计;医生端架构;诊疗智能辅助(P3);Ollama;OpenAI 兼容 API
前言
阶段三里,我们把医生端“接诊工作台—电子病历—处方—患者档案—接诊统计”这条主链跑顺,并在权限、导出、处方隔离与前端可读性上收了一圈。阶段四则聚焦两件可交付、可复盘的事:一是把阶段一~三里容易遗留的一致性/体验问题再收口(典型如头像在多入口不同步);二是在不改动核心业务表结构的前提下,为项目落一个可联调、可配置的 P3 诊疗智能辅助雏形——后端统一走 OpenAI 兼容 /v1/chat/completions,前端在接诊工作台预留入口,本地优先接 Ollama + 轻量化千问,云端通道预留合规网关。
下文按“问题—根因—改法—配置与踩坑"的结构记录,便于同组交接与后续接患者端/异步任务。
目录(仅供提示)
- 背景与阶段四目标
- Bug 修复:医生主页头像与「医生档案」不同步
- 体验与流程:档案变更审批信息可读性
- P3 开端:诊疗智能辅助(架构与接口约定)
- 本地轻量化模型:Ollama、目录迁移与机型选择
- 前后端联调要点(超时、生成长度、偏慢提示)
- 结语与下阶段排期
1. 背景与阶段四目标
业务上:医生在”我的医生主页“修改展示照等信息,经审批或管理端维护后,医生档案列表/弹窗应读到同一套 photo_url;顶栏若走 sys_user.avatar,也需同源或显式同步,避免”主页新、档案旧“。
工程上:在阶段三权限与页面形态稳定后,补 DAO 写入正确性、审批 payload 键名兼容、前端相对路径头像展示 等细节;并启动 P3:以最小闭环验证”工作台一键调模型 → 回填临床辅助文本“是否可行,而非一上来上大模型工程化全家桶。
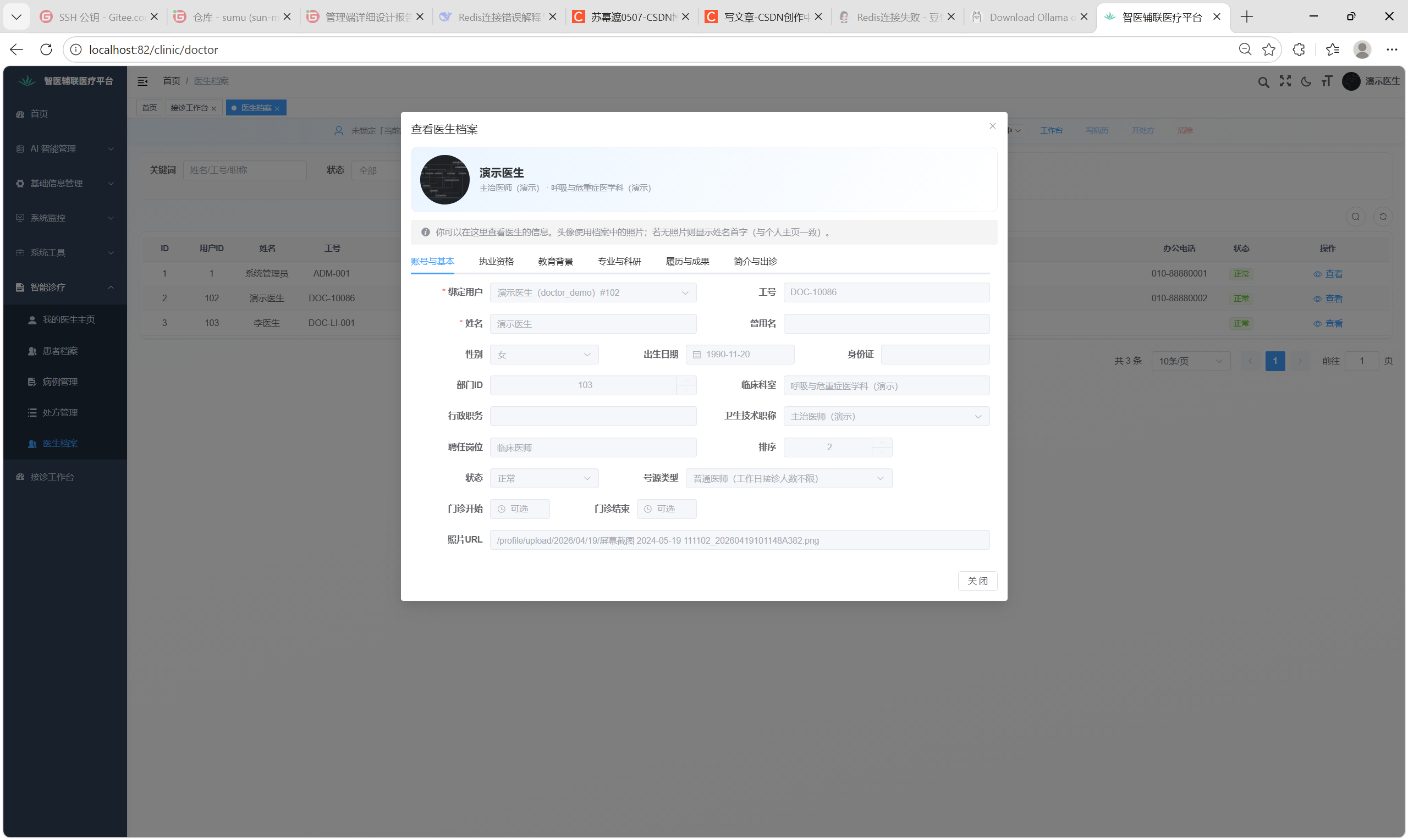
2. Bug 修复:医生主页头像与「医生档案」不同步
现象:医生在个人主页更换头像(或展示照)后,医生档案等处仍显示旧图,或一侧能显示、一侧裂图。
根因归纳:
- 后端
med_clinic_doctor更新语句不符合 SQLAlchemy 2 用法,photo_url等字段未可靠落库,档案列表/详情仍读旧值。 - 审批合并时,
payload_json若仅存驼峰键(如photoUrl),旧过滤逻辑只认蛇形字段,导致合并不含photo_url。 - 前端:我的主页对相对路径头像会拼
VITE_APP_BASE_API,医生档案弹窗若直接绑原始photoUrl,相对路径会打到错误站点,表现为「未更新」或裂图。
实现效果如下:
改法摘要:
1.DAO:按 doctor_profile_id 执行 update(...).where(...).values(**合法列),只写表内列。
2.服务层:更新 photo_url 时同步 sys_user.avatar(注意字段长度,必要时截断),保证顶栏与档案策略一致。
3.变更审批:用 Pydantic 校验申请体,兼容驼峰/蛇形写入合并。
4.前端档案页:头像展示与我的主页同一套「外链 / 拼 baseApi」规则;审批抽屉用中文标签 + 展开详情替代裸 JSON,降低误操作。
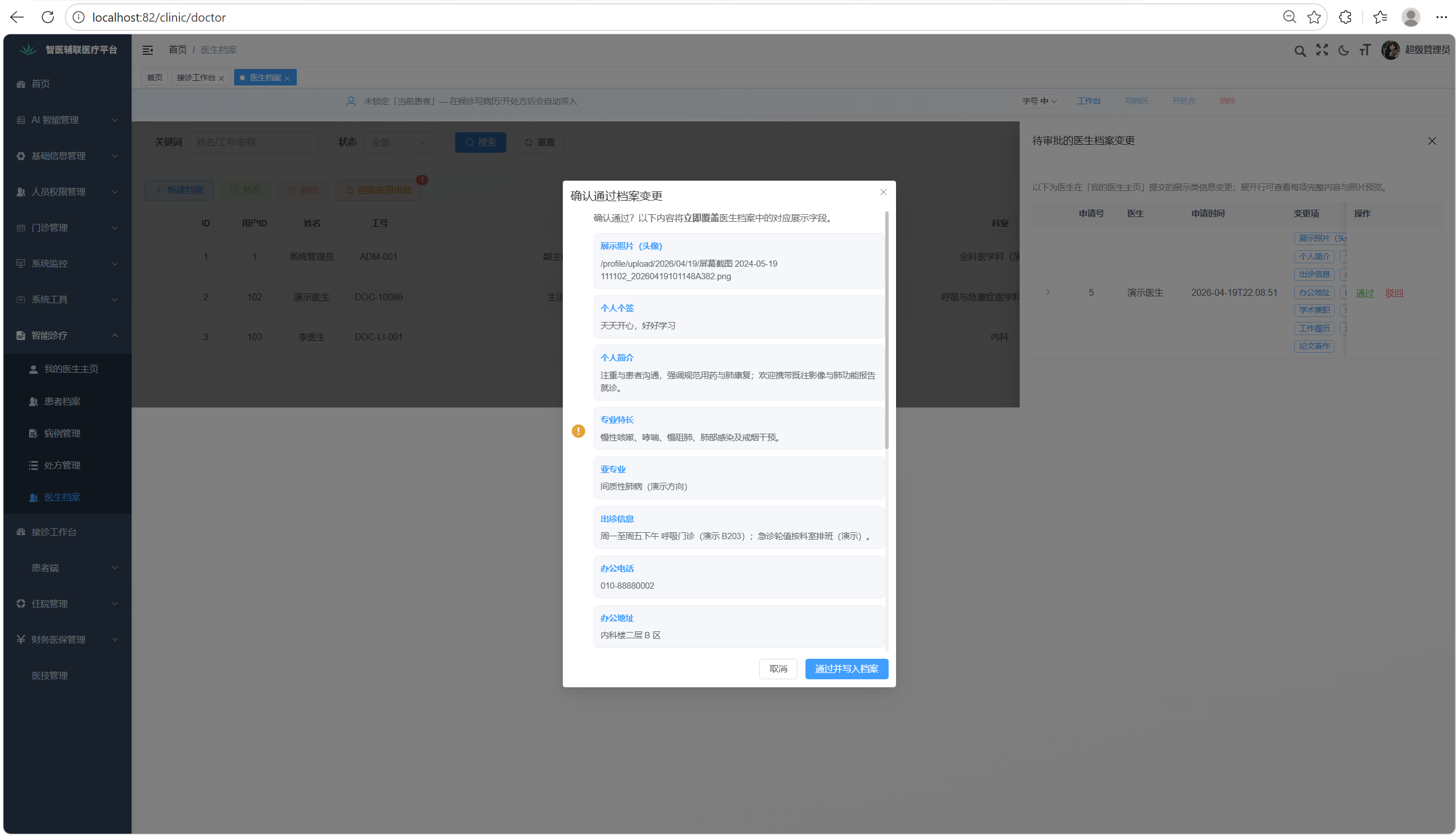
3. 体验与流程:档案变更审批信息可读性
在管理端待审批的医生档案变更中,将摘要改为变更项标签,展开区用 Descriptions + 照片预览,通过前确认框展示结构化变更说明,避免管理员看不清批什么。
4. P3 开端:诊疗智能辅助(架构与接口约定)
定位:与电子病历/处方并列在工作台周边,不侵入核心业务表;先做到 HTTP 同步调用 + 可配置网关。
后端(FastAPI):
a.GET /clinic/llm/status:返回本地/云端/智能体通道是否已配置(不落密钥)。
b.POST /clinic/llm/assist:请求体含 mode(local / cloud / agent)、task、userInput、context;下游统一请求 OpenAI 兼容 POST {base}/v1/chat/completions。
任务划分(与产品分工对齐):
a.本地轻量:标准病历模板、常规病史摘要、基础用药参考、固定话术填充。
b.云端深度(需合规 API):病历润色、全量病史整合、复杂病例提示、用药禁忌关注点等(仍仅辅助,非处方结论)。
权限:与接诊工作台医生身份衔接(如
clinic:workbench:list或单独clinic:llm:assist,可按菜单 SQL 授权)。前端:接诊工作台 P3 卡片 → 抽屉:选通道与任务、填写上下文与医生输入、展示结果;结果区可带
max_tokens、耗时 便于调参。
5. 本地轻量化模型:Ollama、目录迁移与机型选择
过程如下:
- 安装 Ollama,确认
http://127.0.0.1:11434可用。 - C 盘空间紧张时:设置用户环境变量
OLLAMA_MODELS指向 E:/F: 大容量目录,重启 Ollama 后再pull,新模型落在目标盘;旧C:\Users\xxx\.ollama\models在验证新路径可用后再删。 ollama pull与ollama run自测:pull 成功 ≠ run 成功;若 14B 反复llama runner terminated,多为显存/内存或驱动问题,改用qwen2.5:3b/7b先打通链路。- 项目
.env.dev:CLINIC_LLM_LOCAL_BASE_URL=http://127.0.0.1:11434/v1CLINIC_LLM_LOCAL_MODEL与ollama list名称严格一致(如qwen2.5:3b)。
- 重启后端,在工作台智能辅助里点「调用模型」做联调。
显卡(如 RTX 4070):安装最新 NVIDIA 驱动;nvidia-smi 在推理时观察显存占用,一般 Ollama 在 Windows 上会走 GPU,无需在业务代码里写死 CUDA 逻辑。
6. 前后端联调要点(超时、生成长度、偏慢提示)
前端 axios 默认 10s:本地 7B/3B 首次推理常超时,需对 /clinic/llm/assist 单独加大 timeout(如 180s)。
后端:为请求增加 max_tokens 上限、按任务设不同 cap,并限制 temperature、输入截断长度,在不牺牲可用性的前提下缩短 wall time。
「偏慢」提示:用可配置的 软阈值(如本地 20s) 与真实推理时间对比;超过阈值时提示 max_tokens、缩短输入、换更小模型或后续异步,而不是用 300ms 类不切实际 SLA 误报。
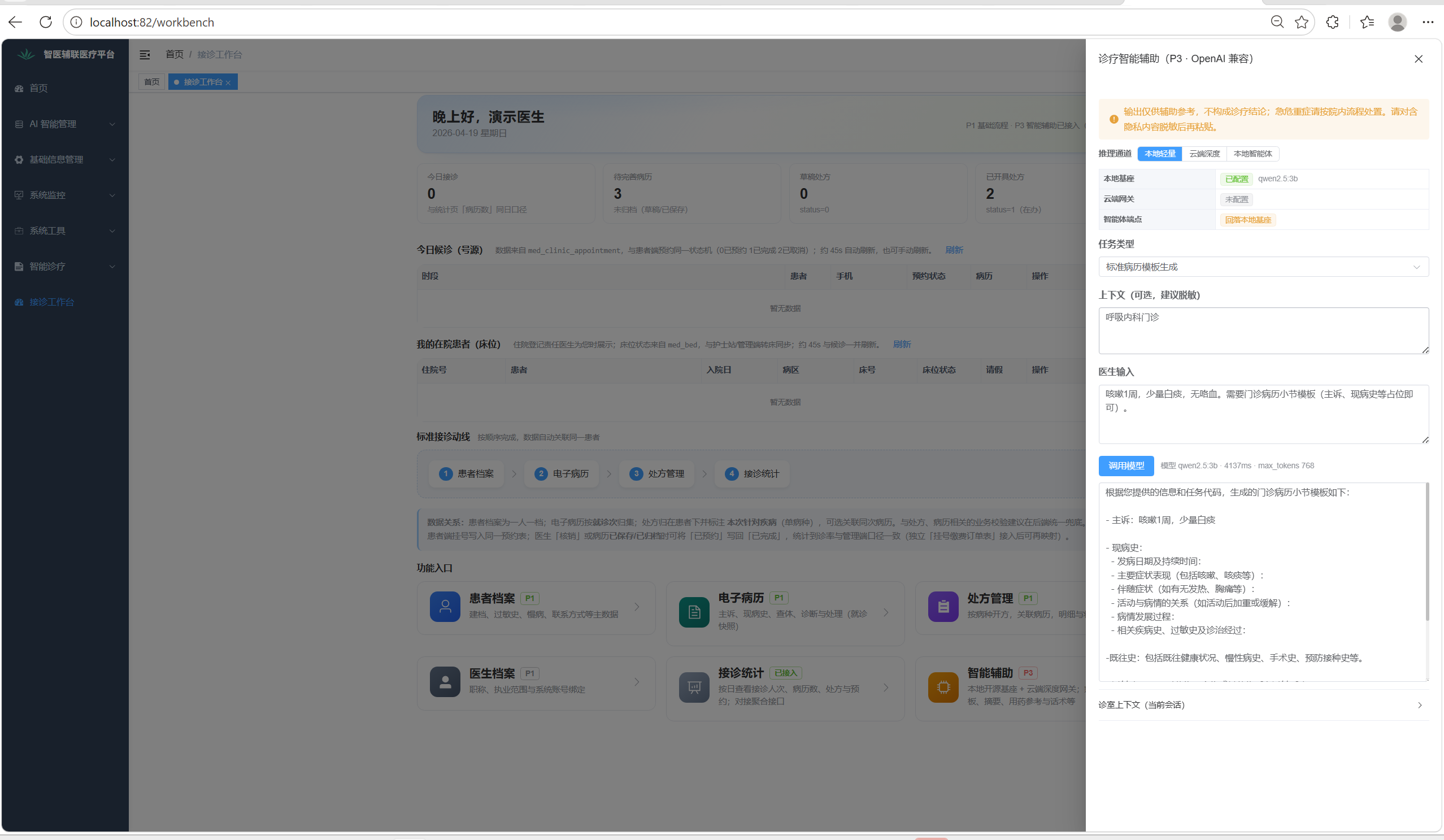
大致实现效果如下:
(键入内容
本地轻量 → 标准病历模板 mr_template_std
上下文:呼吸内科门诊
医生输入:
咳嗽1周,少量白痰,无咯血。需要门诊病历小节模板(主诉、现病史等占位即可)。)
7. 结语与下阶段排期
阶段四在业务上补齐了头像与档案、审批展示等一致性;在架构上把 P3 诊疗智能辅助以 OpenAI 兼容 + 双通道 的形式落到可运行状态,并在本机用 Ollama + 千问 3B 完成轻量化验证。
下一阶段可排:异步任务与结果回写病历侧栏、审计与脱敏流水、患者端联调、以及云端合规网关对接与密钥托管;若集群多进程,实时通知可再演进到消息中间件。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)