MedSegDiff:基于扩散模型的医学图像分割
本文系统分析了两代基于扩散模型的医学图像分割方法:MedSegDiff和MedSegDiff-V2。MedSegDiff首次将去噪扩散概率模型(DPM)应用于医学图像分割,通过动态条件编码和FF-Parser模块解决了病灶边界模糊问题。MedSegDiff-V2则创新性地将Transformer与扩散模型结合,提出锚点条件和频谱空间Transformer架构,在20项任务中刷新性能记录,同时显著提
本文解读两篇使用扩散模型进行医学图像分割的论文,这两篇论文代表了医学图像分割在去噪扩散概率模型(DPM)领域的演进之路。MedSegDiff 作为首个将 DPM 应用于通用医学图像分割的开创性工作,通过动态条件编码和FF-Parser解决了病灶边界模糊和噪声干扰问题,在三项典型任务上打破了常规 CNN 和 Transformer 模型的性能瓶颈。而 MedSegDiff-V2 则在此基础上完成了架构跨越,成为首个将 Transformer 全局建模能力集成到扩散模型中的通用分割框架。它通过创新的锚点条件(U-SA)****频谱空间 Transformer(SS-Former),不仅在 20 项分割任务中刷新了 SOTA 记录,还显著提升了扩散模型的收敛速度和推理效率,解决了前代模型方差大、计算成本高的痛点。
本文对应的论文是:
1.Medsegdiff: Medical image segmentation with diffusion probabilistic model,Medical Imaging with Deep Learning, 2024
2.Medsegdiff-v2: Diffusion-based medical image segmentation with transformer,AAAI2025
向上一个概览图,然后对其对比分析,Medsegdiff-v2代码开源,本文会继续对其进行代码剖析,以方便理解。
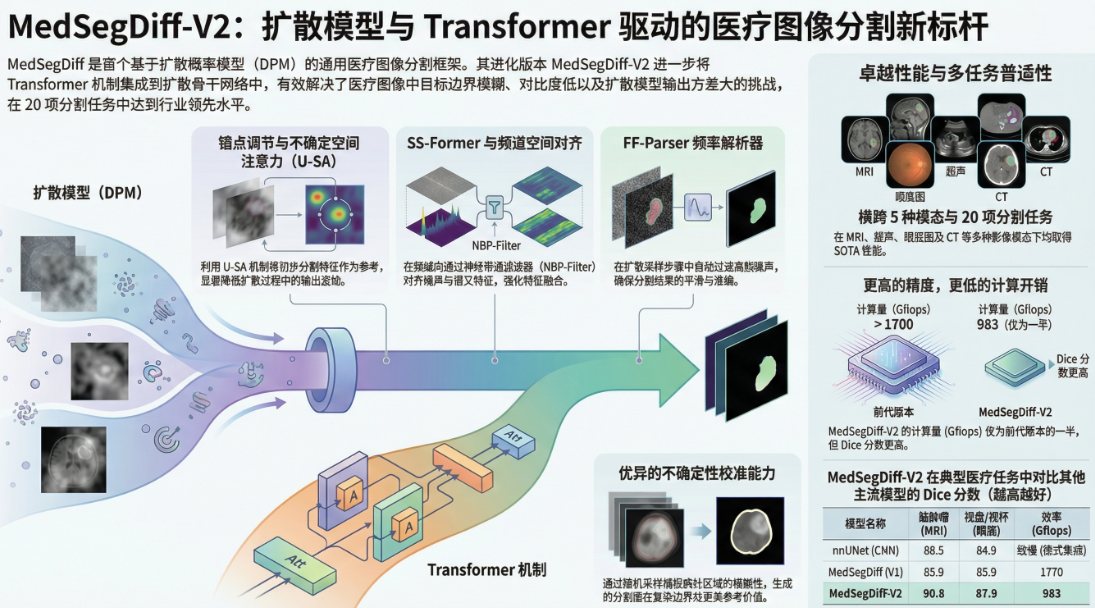
两个模型核心对比如下
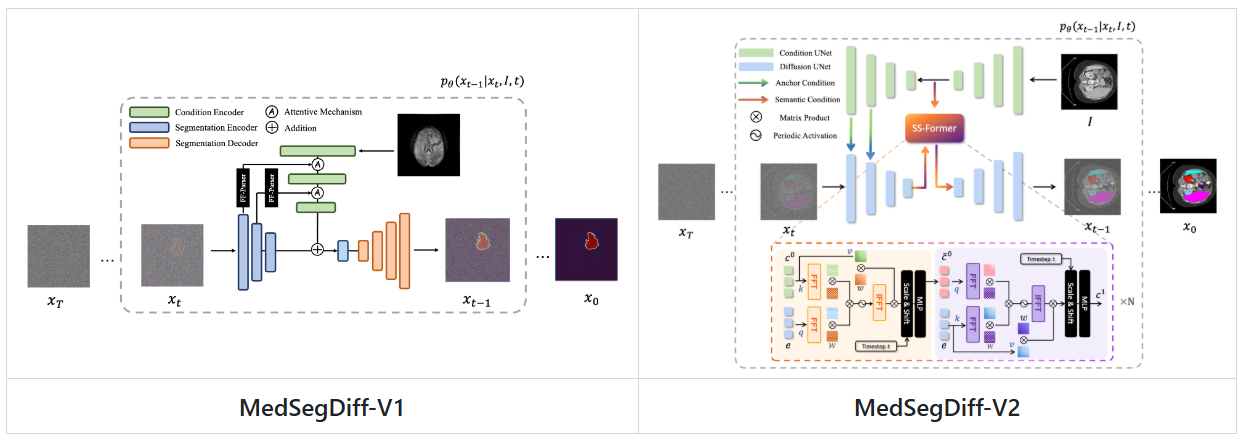
| 对比维度 | MedSegDiff (V1) | MedSegDiff-V2 |
|---|---|---|
| 模型定位 | 首个基于 DPM 的通用医学图像分割模型 | 首个结合 Transformer 的通用 DPM 分割模型 |
| 骨干架构 | 基于 ResUNet 的卷积神经网络结构 | 集成 ViT (Vision Transformer) 的增强架构 |
| 核心条件机制 | 动态条件编码 (Dy-Cond):每个步骤实现状态自适应的条件调节 | 双重条件:1. 锚点条件 (稳定方差);2. 语义条件 (跨域特征融合) |
| 关键技术模块 | FF-Parser:在傅里叶空间滤除分割图引入的高频噪声 | U-SA (不确定空间注意力) 与 SS-Former (包含神经网络带通滤波器 NBP-Filter) |
| 实验验证规模 | 3 项任务,3 种影像模态 (眼底、MRI、超声) | 20 项任务,5 种影像模态 (增加 CT、皮肤镜等) |
| 推理效率 | 较慢,通常需要 25 次采样集成才能稳定结果 | 显著提升,仅需 10 次采样集成即可收敛,计算量 (Gflops) 约减少一半 |
| 主要解决问题 | 应对病灶边界模糊及扩散模型中的高频噪声 | 解决 Transformer 在扩散过程中的高方差及语义/噪声特征间的域鸿沟 |
| 开源状态 | 未开源 | 已开源:GitHub 链接 |
一.第一篇:MedSegDiff —— 开启医学影像分割的“扩散”时代
1.研究背景与核心理念
传统的医学图像分割模型(如 CNN 或 Transformer)在处理边界模糊、对比度低的病变或器官时,往往难以将其与背景区分开。MedSegDiff 利用了生成模型强大的分布学习能力,将分割任务看作一个**从噪声中恢复分割标签(mask)**的过程。
2.MedSegDiff 的核心架构
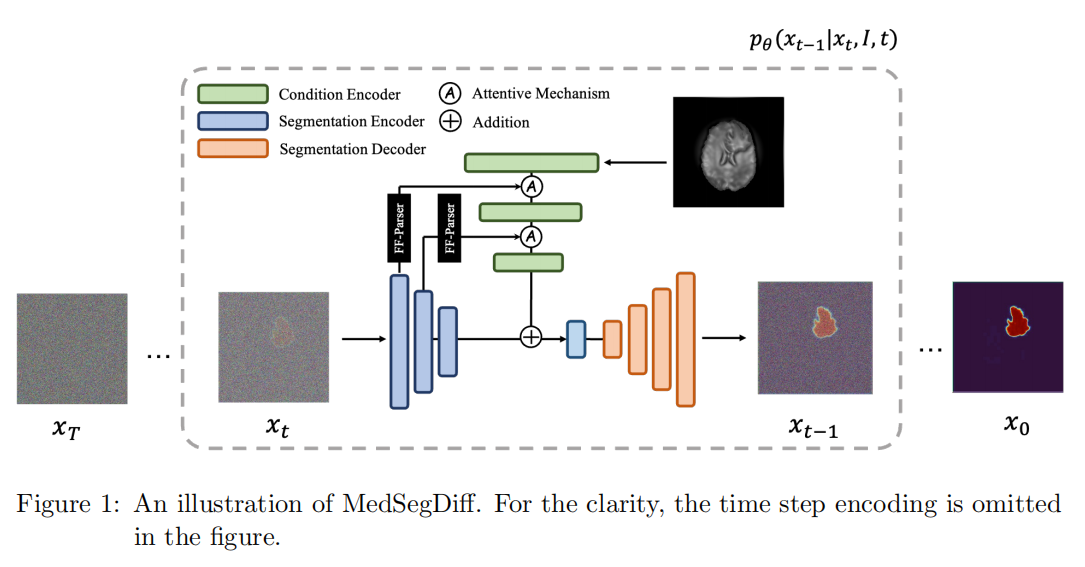
(1)核心流程:从噪声到分割图,图1展示了扩散模型的反向扩散(去噪)过程:
x T x_T xT到 x 0 x_0 x0:模型从一个完全的高斯噪声 x T x_T xT 开始,经过多个步长( t t t, t − 1 t-1 t−1,…)的迭代去噪,最终生成清晰的分割掩码(Mask) x 0 x_0 x0。
单步推理:虚线框内详细展示了模型在 t t t时刻如何从带有噪声的分割图 x t x_t xt预测出更清晰的 x t − 1 x_{t-1} xt−1
(2)三大核心组件(按颜色区分)
图1通过不同的颜色标注了模型的主要组成部分:
绿色(Condition Encoder):原始图像编码器。它负责提取原始医学图像(Raw Image I)的特征,作为分割的先验条件。
蓝色(Segmentation Encoder):分割图编码器。它负责提取当前步骤中带有噪声的分割图 x t x_t xt的特征。
橙色(Segmentation Decoder):分割解码器。它将融合后的特征解码,重建出更清晰的图像,从而预测下一步的状态。
3.关键技术创新
图1着重体现了该研究提出的两个核心模块,用于解决医学图像中病灶模糊的问题:
3.1 动态条件编码(Dynamic Conditional Encoding)
在医学影像(如 MRI 或超声)中,病变组织或器官通常与背景对比度低,边界非常模糊,传统的静态条件(即在整个去噪过程中只提供原始图像作为参考)难以提供足够的引导来进行精确校准。研究者观察到:原始图像含有准确的分割目标信息,但目标与背景难以区分。当前步骤的分割图 ( x t x_t xt) 虽然含有噪声且不完全准确,但它显著增强了目标区域的特征。 因此,将两者结合可以实现信息互补。与传统去噪扩散模型不同,动态条件编码为每一个采样步骤建立**状态自适应(State-adaptive)**的条件:
- 多尺度特征融合:该技术在特征层面将“当前步骤生成的分割图特征”与“原始图像编码特征”进行融合。
- 动态增强:通过在推理的每一个步长(step)中不断引入当前生成的掩码信息,模型能够动态地定位并校准分割结果,从而提高重建的准确性。
实现机制:注意力增强。动态条件编码通过一种**类注意力机制(Attentive-like mechanism)**来实现特征集成,其具体步骤如下: A ( m I k , m x k ) = ( L N ( m I k ) ⊗ L N ( m x k ) ) ⊗ m I k A(m_I^k,m_x^k)=(LN(m_I^k)\otimes LN(m_x^k))\otimes m_I^k A(mIk,mxk)=(LN(mIk)⊗LN(mxk))⊗mIk
- 层归一化(LN):首先对原始图像特征图( m I k m_I^k mIk)和当前分割图特征图( m x k m_x^k mxk)分别进行层归一化
- 生成亲和图(Affinity Map):将两者进行元素级相乘(⊗),得到一个反映区域关联度的亲和图
- 增强特征:将该亲和图再次与原始图像编码特征相乘,以增强模型对目标区域的注意力
3.2 FF-Parser(特征频率解析器)
在蓝色和绿色特征融合的路径上,可以看到 FF-Parser 模块。是 MedSegDiff 模型中用于清理特征、提升分割质量的关键模块。在扩散模型的推理过程中,当前步骤生成的分割图( x t x_t xt)本身是由高斯噪声逐步恢复而来的,因此不可避免地含有大量高频噪声成分。当“动态条件编码”将这些带有噪声的特征融合进原始图像特征时,会干扰模型对真实边界的判断。FF-Parser 的任务就是约束和消除这些与噪声相关的分量,具体步骤为:
空间转频域:首先通过 **2D 快速傅里叶变换(FFT)**将空间维度的特征图 m m m转换到频域,得到频谱图 M M M
参数化掩码调制:在频域中,模型会学习一个参数化的注意力图(Parameterized Attentive Map) A A A将这个学习到的掩码与频谱进 M M M行逐元素相乘( M ′ = A ⊗ M M^{\prime}=A\otimes M M′=A⊗M)
频域转空间:最后,通过 **逆快速傅里叶变换(iFFT)**将调整后的频谱 M ′ M^{\prime} M′转换回空间域,得到清理后的特征 m ′ m^{\prime} m′
与传统的空间注意力机制(关注“哪里”重要)不同,FF-Parser 属于全局频率调整。它可以根据训练过程,自动学习哪些频率成分是病灶的结构信息,哪些是需要抑制的噪声。它可以被视为数字图像处理中传统频率过滤器(如低通或高通滤波器)的可学习版本。
在 MedSegDiff 的 U-Net 架构中,FF-Parser 并不是随意放置的,而是被部署在每一条跳跃连接(Skip Connection)路径上,用于多尺度特征的整合。这意味着在从编码器到解码器的每一个特征传输层级,模型都会对融合特征进行一次“去噪扫描”。
第二篇 MedSegDiff-V2 —— Transformer 与扩散模型的强强联手
如果说第一代模型是打响了“第一枪”,那么 MedSegDiff-V2 就是一次全方位的“降维打击”。它不仅继承了扩散模型的优势,还首次完美融合了 Transformer 的全局建模能力。
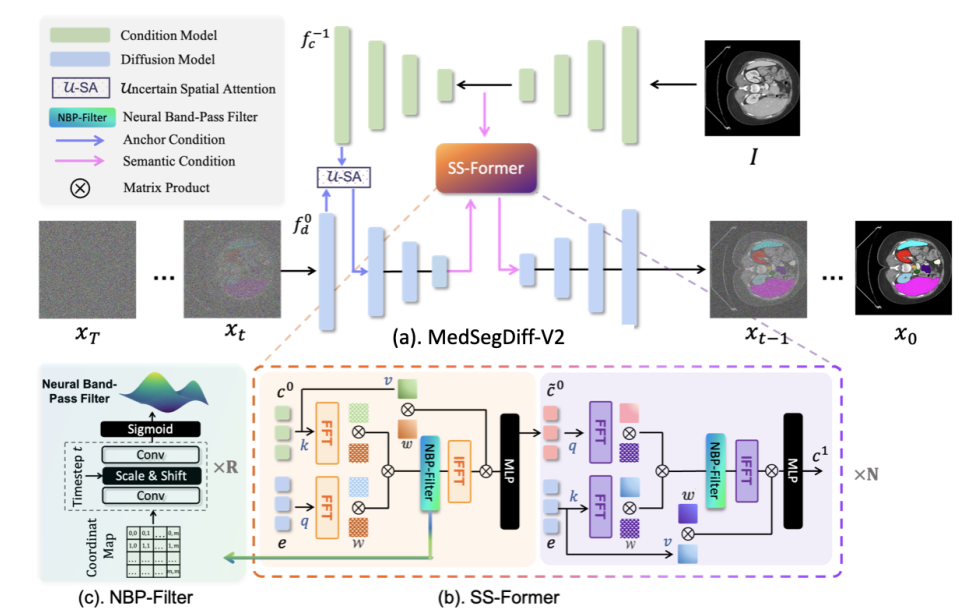
1.设计动机
MedSegDiff-V2 是首个将 Transformer 整合进扩散模型(Diffusion Model)框架的通用医学图像分割网络 。它旨在解决传统扩散模型(如基于 UNet 的 MedSegDiff)在医学图像分割中面临的两个痛点:
特征不匹配:Transformer 提取的深层语义特征与扩散模型处理噪声掩码(noisy mask)的特征域存在差异 。
方差过大:Transformer 的动态特性使其对输入方差较敏感,导致扩散过程难以收敛 。
2. 核心工作原理
U-SA 通过以下步骤将来自“条件模型”的分割特征集成到“扩散模型”的编码器中:
模拟不确定性:由于作为锚点的条件特征并不完全准确,U-SA 首先使用一个可学习的高斯核(learnable Gaussian kernel)对特征图进行平滑处理。这种做法承认了初始预测的不确定性,为扩散模型保留了进一步校准的空间,。
特征保留与增强:在平滑后的特征图与原始特征图之间执行 Max(最大值)操作,以确保在放松约束的同时,依然能保留最相关的分割信息。
空间注意力集成:最后,通过 1×1 卷积和 Sigmoid 激活函数,将处理后的锚点特征以空间注意力的方式叠加到扩散模型的特征层上
U-SA 扮演了一个“智能引导员”的角色,它既为 Transformer 提供了必要的方向指引(锚点),又通过模拟不确定性给予了模型足够的灵活性去修正和精细化分割边界
3.两种条件化方式
在 MedSegDiff-V2 研究论文中,作者确实提出了这两种创新的条件化(Conditioning)方式,旨在解决将 Transformer 集成到扩散模型(DPM)时遇到的特征不兼容和方差过大等挑战。
(1)锚点条件 (Anchor Condition)
锚点条件主要作用于扩散模型的**编码器(Encoder)**阶段,。
特征来源:它使用的是从“条件模型”(Condition Model,一个标准的 UNet)中提取并解码后的分割特征,。
核心机制——U-SA(不确定空间注意力):为了融合这些特征,研究者设计了 U-SA 模块,。该模块通过可学习的高斯核对特征进行平滑处理,通过增加“不确定性”来放宽约束,从而让扩散模型有更多的灵活性来进一步校准预测结果,。
主要作用:由于 Transformer 对输入方差非常敏感,锚点条件为其提供了一个粗略但静态的参考,。这有助于将预测限制在正确的范围内,从而显著降低扩散过程中的方差,解决模型难以收敛的问题,。
(2)语义条件 (Semantic Condition)
语义条件则作用于扩散模型的**嵌入层(Embedding)**部分,。
特征来源:它集成的是条件模型中的深层语义分割嵌入。
核心机制——SS-Former(频谱空间 Transformer):为了有效融合语义嵌入,研究者提出了 SS-Former。该模块在傅里叶频域中学习条件语义特征与扩散噪声特征之间的交互,。
关键组件——NBP-Filter(神经带通滤波器):SS-Former 内部包含一个时间步自适应的滤波器,它能根据当前的噪声水平(步数 t)自动对齐不同频率范围的特征,。
主要作用:它解决了原始图像的深层语义特征与带噪声掩码特征之间的域鸿沟(Domain Gap),。利用 Transformer 的全局和动态特性,语义条件能够提取出更强大的特征表示,从而提升分割的精度
这两种方式相辅相成:锚点条件通过 U-SA 模块在空间维度提供稳定性,减少采样时的随机偏差;而语义条件通过 SS-Former 在频域维度实现深度的特征对齐。这种双重调节机制使得 MedSegDiff-V2 在 20 项医学图像分割任务中均达到了领先(SOTA)。
简要小结
从 MedSegDiff 的动态校准,到 MedSegDiff-V2 的频域 Transformer,这一系列研究不仅证明了扩散模型是医学影像分割的新高地,更展示了如何通过跨领域技术(如傅里叶变换、Transformer)来克服生成式模型的固有缺陷。
MedSegDiff-V2核心代码解读
下面对MedSegDiff-V2三个核心组件的代码进行剖析:
1.核心网络定义文件:guided_diffusion/unet.py
这是整个项目最核心的文件,它实现了论文中提到的 MedSegDiff-V2 网络架构。由于该文件代码量较大(超过800行),我将重点聚焦于实现 MedSegDiff-V2 核心原理(SS-Former、频域处理、锚点融合)的代码段
(1)FFParser 类(SS-Former 的频域核心实现)
这是 V2 版本最创新的部分,负责在傅里叶空间处理特征。实现了 SS-Former 的物理基础,即通过 fft 和可学习权重在频域对齐语义。
class FFParser(nn.Module):
def __init__(self, dim, h=128, w=65):
super().__init__()
# 定义可学习的复数权重,用于在频域对特征进行过滤或增强
# 权重形状对应:通道数 x 频谱高度 x 频谱宽度 x 2(实部和虚部)
self.complex_weight = nn.Parameter(torch.randn(dim, h, w, 2, dtype=torch.float32) * 0.02)
self.w = w
self.h = h
def forward(self, x, spatial_size=None):
B, C, H, W = x.shape
assert H == W, "输入高度和宽度必须相等"
x = x.to(torch.float32)
# 执行二维实数快速傅里叶变换 (RFFT),将空间域图像转为频域
# norm='ortho' 表示正交归一化
x = torch.fft.rfft2(x, dim=(2, 3), norm='ortho')
# 将存储的实数参数转换为复数形式,以便进行复数运算
weight = torch.view_as_complex(self.complex_weight)
# 在频域进行逐元素乘法,这在物理意义上等同于空间域的卷积操作
x = x * weight
# 执行逆快速傅里叶变换 (IRFFT),将处理后的信号转回空间域
x = torch.fft.irfft2(x, s=(H, W), dim=(2, 3), norm='ortho')
x = x.reshape(B, C, H, W) # 恢复原始张量形状
return x
(2)UNetModel_newpreview 类(MedSegDiff-V2 模型主体)
此类实现了包含**锚点条件(Anchor Condition)**融合的扩散模型。实现了“双路”架构,通过 detach() 后的锚点特征来抑制扩散过程的方差。
class UNetModel_newpreview(nn.Module):
"""
集成了 Transformer 机制和锚点条件的完整扩散 UNet 模型
"""
def __init__(self, ...):
# ... 初始化参数 (层数、通道、注意力头等) ...
# 若开启 highway(高通)模式,初始化条件网络(Generic_UNet)
if high_way:
features = 32
self.hwm = Generic_UNet(self.in_channels - 1, features, 1, 5, anchor_out=True, upscale_logits=True)
def highway_forward(self, x, hs=None):
# 获取条件网络的输出,anch 即为论文中提到的锚点特征
return self.hwm(x, hs=None)
def forward(self, x, timesteps, y=None):
# ... 时间步嵌入处理 ...
h = x.type(self.dtype)
c = h[:,:-1,...] # 提取条件图像(原始医学图像)
# 核心 V2 逻辑:通过条件网络提取锚点和标定信息
anch, cal = self.highway_forward(c)
for ind, module in enumerate(self.input_blocks):
if len(emb.size()) > 2:
emb = emb.squeeze()
if ind == 0:
# 在扩散模型输入的第一层,直接将锚点特征融合进来
# 这里将 anch 的不同分辨率特征进行 concat 拼接,提供静态参考
h = module(h, emb)
h = h + th.cat((anch[0], anch[0], anch[1]), 1).detach()
else:
h = module(h, emb)
hs.append(h)
# ... 之后进入中间块(SS-Former)和解码器阶段 ...
return out, cal # cal 用于辅助计算锚点损失 L_anc
(3)Generic_UNet 类中的特征对齐(NBP-Filter 逻辑)
在条件网络中,如何将特征传递给扩散网络,涉及到频域对齐。作为 Condition Model,它通过多层级 ffparser 为扩散步提供受过滤的、干净的语义指导。
# 在 Generic_UNet 的 forward 中
if hs: # 如果存在从扩散模型传回的特征(用于跨网络交互)
h = hs.pop(0)
# a 块:执行通道投影对齐
h = self.conv_trans_blocks_a[d](h)
# 核心:调用 FFParser 在频域进行频谱过滤和对齐
h = self.ffparser[d](h)
# b 块:生成最终的空间权重图
ha = self.conv_trans_blocks_b[d](h)
# 全局池化生成通道权重
hb = th.mean(h, (2, 3))
hb = hb[:, :, None, None]
# 空间权重 * 通道权重,对当前层特征进行重校准
x = x * ha * hb
2. 训练逻辑文件:scripts/segmentation_train.py
该文件负责模型的训练流程,体现了论文中提到的损失函数优化。包含:
总损失函数 (Total Loss):在训练循环中,它整合了扩散模型的噪声预测损失( L n \mathcal{L}_n Ln)和监督条件网络的锚点损失( L a n c \mathcal{L}_{anc} Lanc,由 Dice 损失和交叉熵损失组成) 。
条件模型与扩散模型的联合训练:该脚本初始化了两个 UNet 结构(一个作为扩散主体,一个作为条件提取器),并确保它们在训练过程中能够协同工作 。
核心机制总结:
(1)输入端耦合:扩散模型在每一层(尤其是输入层)都会接收条件提取器生成的 anch(锚点)特征 。
(2)梯度解耦:源码中使用 .detach() 阻断了扩散步对条件网络的部分梯度影响,这解决了论文中提到的“Transformer 对方差敏感导致难以收敛”的问题 。
(3)多任务监督:通过 L a n c L_{anc} Lanc 强制要求条件网络即使在没有扩散噪声的情况下,也能独立理解图像语义,从而为扩散主体提供高质量的指导 。
在训练脚本 scripts/segmentation_train.py 中,系统会根据配置初始化扩散主体和条件提取器。
# 在 scripts/segmentation_train.py 的全局逻辑中
# 初始化扩散主体模型(Main Diffusion Model)
model, diffusion = create_model_and_diffusion(
**args_to_dict(args, model_and_diffusion_defaults().keys())
)
# 如果是在 V2 模式下,UNetModel_newpreview 会在其内部自动初始化条件提取器
# 源码见 guided_diffusion/unet.py 中的 UNetModel_newpreview.__init__
if high_way:
features = 32
# 初始化条件提取器(Condition Model),即 Generic_UNet
# anchor_out=True 表示该网络会输出用于扩散模型参考的“锚点”特征
self.hwm = Generic_UNet(self.in_channels - 1, features, 1, 5, anchor_out=True, upscale_logits=True)
在 guided_diffusion/unet.py 的 forward 函数中,展示了两个模型如何在每一个训练步(Step)中进行数据交换。
def forward(self, x, timesteps, y=None):
# x 包含了 [噪声掩码, 原始图像] 的拼接
h = x.type(self.dtype)
# 步骤 A:从输入中分离出原始医学图像(作为条件输入)
c = h[:, :-1, ...]
# 步骤 B:调用条件提取器(hwm),先行提取图像特征
# anch 是输出的锚点特征图列表,cal 是初步的分割预测(用于计算辅助损失)
anch, cal = self.highway_forward(c)
# 步骤 C:扩散主体开始处理
for ind, module in enumerate(self.input_blocks):
h = module(h, emb)
# 在输入层(ind == 0)将条件提取器的结果“注入”扩散主体
if ind == 0:
# 将锚点特征拼接到扩散主体的特征流中,实现“联合训练”
# .detach() 的作用是防止扩散过程的剧烈梯度直接冲击条件网络,保持其稳定性
h = h + th.cat((anch[0], anch[0], anch[1]), 1).detach()
hs.append(h)
# ... 后续扩散步骤 ...
return out, cal # 返回扩散预测结果和条件提取器的初始预测
在 scripts/segmentation_train.py 的训练循环中,通过总损失函数确保两个网络朝着同一个目标优化 。
# 伪代码逻辑,对应论文中的总损失公式 L_total = L_n + L_anc [cite: 120]
# 1. 计算扩散主体的噪声预测损失 (Standard Diffusion Loss)
loss_diffusion = mean_flat((target - model_output)**2)
# 2. 计算条件提取器的锚点损失 (Anchor Loss)
# 使用模型返回的 cal(条件提取器的输出)与真值(GT)对比 [cite: 144]
# 包含 Dice Loss 和 Cross Entropy Loss,确保条件提取器能提取到有效的语义信息
loss_anchor = dice_loss(cal, ground_truth) + 10 * ce_loss(cal, ground_truth)
# 3. 联合更新:将两部分损失相加进行反向传播 [cite: 120, 144]
total_loss = loss_diffusion + loss_anchor
total_loss.backward()
3.推理与集成采样文件:scripts/segmentation_sample.py
该文件实现了论文中提到的**隐式集成(Implicit Ensemble)**效果。包含
多样本生成:通过参数 --num_ensemble 控制对同一张图像进行多次扩散采样 。
效率体现:V2 版本的核心逻辑使得模型仅需约 5-10 次采样即可稳定,而在该脚本中你可以看到如何调用 STAPLE(STAPLE (Simultaneous Truth and Performance Level Estimation) ) 算法来融合这些样本,从而获得最终的高精度分割图 。它将扩散模型从一个“生成式随机模型”转化为一个“高可靠性的医疗诊断工具” 。虽然 STAPLE 算法通常由外部库(如 SimpleITK)提供,但在该项目的逻辑中,其调用流程如下:
(1)多样本收集:在推理阶段,程序会运行 num_ensemble 次(V2 建议为 5-10 次) 。
(2)算法原理:STAPLE 不仅仅是简单的“多数投票”(Majority Voting)。它会估计每个样本(即每一轮扩散采样)的灵敏度(Sensitivity)和特异性(Specificity) 。根据估计出的权重,对所有样本进行加权合并,从而剔除扩散过程中产生的随机噪声或异常边界。
在本论文的模型中:Transformer 结构虽然表达能力强,但容易产生较大的预测方差 。多次采样并使用 STAPLE 融合,可以有效地抵消这种不稳定性 。扩散模型生成的多个样本之间的差异,直接反映了医学图像中病灶边界的“不确定性” 。STAPLE 能够利用这些不确定性信息,生成一个平滑且稳健的最终边界 。论文指出,得益于 Anchor Condition(锚点条件) 和 SS-Former 的设计,MedSegDiff-V2 仅需 5-10 次采样后经 STAPLE 融合就能达到 SOTA 性能,这比 V1 版本的 25 次采样大幅缩短了时间 。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)