100万的并发,如何设计一个商品搜索系统?
今天我们来看一道比较有深度的面试题:百万并发下,商品搜索系统,你如何设计呢?我们每次提到关键词搜索,大家很容易就想到但是,显然商品数据量超10亿条,搜索不能用like。可以使用Elasticsearch ,但是我们是做系统设计,肯定不能直接回答面试官,说,用Elasticsearch呀,而是按照系统设计的思想(),说一整个链路。我们在使用mysql做查询的时候,会遇到深分页的问题,比如回表十万次我
今天我们来看一道比较有深度的面试题:百万并发下,商品搜索系统,你如何设计呢?
假设场景:某电商平台大促期间,需支撑每秒100万次的商品搜索请求,要求响应时间≤200ms,同时应对商品数据量超10亿条。假设给你来做系统设计,怎么做呢?
如果是我来回答面试官这道题的话,我会按照这些思路来跟面试官阐述:
- 为什么不能用MySQL的llike?
- 总体架构设计
- 核心关键设计
1.为什么不能用mysql的like?
我们每次提到关键词搜索,大家很容易就想到数据库的like,比如:
SELECT * FROM products WHERE title LIKE '%智能手机%' LIMIT 10;
但是,显然商品数据量超10亿条,搜索不能用like。
LIKE '%keyword%'无法利用索引,触发全表扫描。10亿数据时单次查询可能耗时数秒。- 不支持分词搜索(如"手机壳"无法拆分为"手机"和"壳"单独匹配)
- 分库分表后跨库LIKE查询复杂度指数级上升
可以使用Elasticsearch ,但是我们是做系统设计,肯定不能直接回答面试官,说,用Elasticsearch呀,而是按照系统设计的思想(高可用 + 可扩展),说一整个链路。

2. 总体架构设计
- 用户层(前端 + CDN)
- 接入层(Nginx )
- 服务层(Search Gateway )
- 检索层(搜索引擎,如 Elasticsearch)
- 数据层(商品数据服务 / DB / 缓存)

2.1 用户层(前端 + CDN)
- 请求分发:通过CDN加速静态资源(图片/JS/CSS)
- 浏览器缓存:利用LocalStorage缓存高频搜索关键词
- 请求合并:合并相似搜索请求(如防抖机制)
// 前端防抖示例(减少无效请求)
let searchTimer;
function handleSearch(keyword) {
clearTimeout(searchTimer);
searchTimer = setTimeout(() => {
fetch(`/api/search?q=${encodeURIComponent(keyword)}`);
}, 300); // 300ms防抖
}
2.2 接入层(Nginx)
- 流量管控:限流、熔断、鉴权
- 负载均衡:轮询/一致性哈希分发请求
- 协议转换:HTTP/2 → HTTP/1.1内部通信
Nginx 关键配置
# 限流配置(每秒1000请求/ip)
limit_req_zone $binary_remote_addr zone=search_limit:10m rate=1000r/s;
location /api/search {
limit_req zone=search_limit burst=200;
proxy_pass http://search_cluster;
# 缓存热门请求结果(5秒)
proxy_cache search_cache;
proxy_cache_valid 200 5s;
}
2.3 服务层(Search Gateway)
- 业务逻辑:请求参数校验、结果格式化
- 多级缓存:本地缓存 → Redis → Elasticsearch
- 降级策略:超时返回兜底数据
// 搜索网关伪代码
public class SearchGateway {
@Cacheable(value = "localCache", key = "#keyword")
public List<Product> search(String keyword) {
// 1. 检查Redis缓存
String redisKey = "search:" + keyword.hashCode();
List<Product> cached = redis.get(redisKey);
if (cached != null) return cached;
// 2. 查询Elasticsearch
List<Product> result = elasticsearch.search(buildQuery(keyword));
// 3. 异步写入缓存
executor.submit(() -> {
redis.setex(redisKey, 30, result); // 缓存30秒
});
return result;
}
}
2.4 检索层(Elasticsearch)
- 索引构建:商品标题/类目/属性倒排索引
- 分布式查询:分片并行计算
- 相关性排序:BM25算法优化
索引设计demo:
PUT /products
{
"settings": {
"number_of_shards": 40,
"number_of_replicas": 1,
"refresh_interval": "30s" // 降低写入实时性要求
},
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "ik_max_word" },
"price": { "type": "double" },
"sales": { "type": "integer" }
}
}
}
2.5 数据层(DB + 缓存)
- 持久化存储:MySQL分库分表
- 数据同步:Binlog → Canal → Elasticsearch
- 冷热分离:Redis缓存热数据,HBase存历史数据
分库分表demo
-- 按商品ID分64个库,每个库分256表
CREATE TABLE products_%02d.t_product_%03d (
id BIGINT PRIMARY KEY,
title VARCHAR(255),
price DECIMAL(10,2)
) ENGINE=InnoDB;
-- 分片路由算法:hash(product_id) % 64 → 分库
-- hash(product_id) / 64 % 256 → 分表
3. 核心关键设计
3.1 分片与容量设计(水平扩展)
- 使用 Elasticsearch,每个索引进行合理分片(Sharding)
- 每个分片大小控制在 20-50 GB,避免 OOM 和延迟增加
- 按业务维度(如商品类目、国家)分索引或路由分片
- 分片副本(Replica)数设置,提升可用性
3.2 深度分页性能优化
我们在使用mysql做查询的时候,会遇到深分页的问题,比如回表十万次

我们可以用标签记录法,来解决深分页问题。
其实Elasticsearch 也存在深分页的问题,当用户翻页到几百页时,ES 会做全量扫描,性能陡降。
- 避免传统 from + size 深分页
- Search After(推荐):基于上一页最后一个 sort_value 做游标分页。(类似标签记录法思想)
- Scroll API:适用于数据导出,不推荐用户查询
- 或业务限制分页范围(如最多展示 100 页)
3.3 避免缓存穿透设计
跟大家一起复习一下,什么是缓存穿透?
指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
在百万并发商品搜索系统时,我们要避免这个问题,可以用布隆过滤器,简单流程图如下:
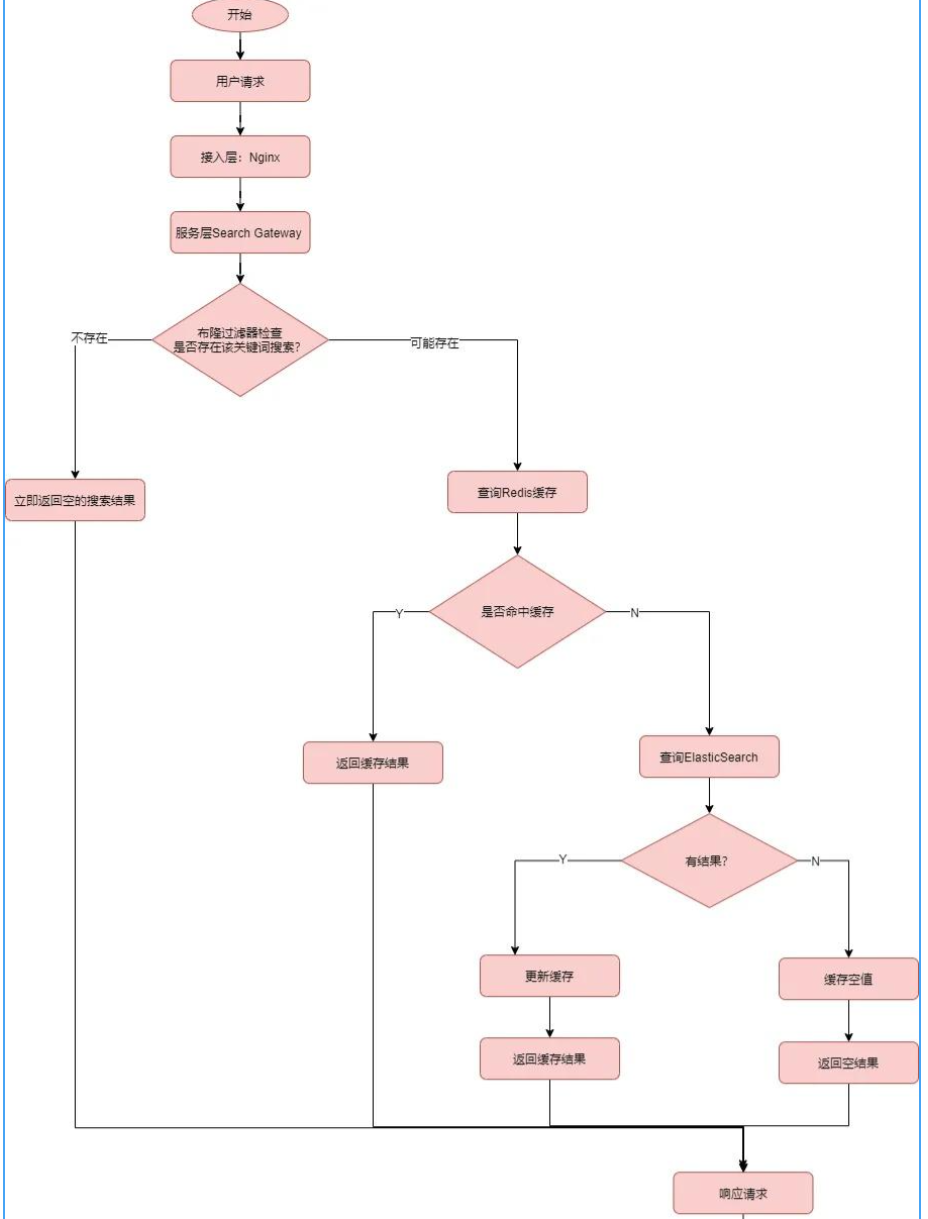
核心业务逻辑(代码简单demo):
@Service
public class SearchService {
// 布隆过滤器(存储所有有效关键词)
@Autowired
private BloomFilter<String> searchBloomFilter;
// Redis缓存操作
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public SearchResult search(String keyword) {
// Step 1: 布隆过滤器校验
if (!searchBloomFilter.mightContain(normalizeKeyword(keyword))) {
return SearchResult.EMPTY;
}
// Step 2: 查询缓存
String cacheKey = "search:" + keyword.hashCode();
SearchResult cached = (SearchResult) redisTemplate.opsForValue().get(cacheKey);
if (cached != null) return cached;
// Step 3: 查询Elasticsearch
SearchResult result = elasticsearchClient.search(buildQuery(keyword));
// Step 4: 更新缓存
if (result.isEmpty()) {
redisTemplate.opsForValue().set(cacheKey, SearchResult.EMPTY, 30, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(cacheKey, result, 5, TimeUnit.MINUTES);
}
return result;
}
// 关键词标准化处理(如去空格、转小写)
private String normalizeKeyword(String keyword) {
return keyword.trim().toLowerCase();
}
}
这里有个点可能要注意一下哈,布隆过滤器需要初始化一下:
// 初始化所有有效关键词到布隆过滤器
@PostConstruct
public void initBloomFilter() {
List<String> allKeywords = productDao.getAllSearchKeywords(); // 获取所有商品标题/标签
allKeywords.stream()
.map(this::normalizeKeyword)
.forEach(searchBloomFilter::put);
}
// 动态更新(新增商品时)
public void addProduct(Product product) {
// ... 其他业务逻辑
searchBloomFilter.put(normalizeKeyword(product.getTitle()));
product.getTags().forEach(tag ->
searchBloomFilter.put(normalizeKeyword(tag))
);
}3.4 GC调优
既然是百万并发的系统设计,少不了GC调优。
尽量降低 Full GC 频率:
- 使用 G1 或 ZGC
- 调大堆内存(视机器资源)
- 避免频繁创建临时对象,使用对象池(如 Query 对象)
在上线前,我们要进行压力测试,然后调出最优最优JVM参数。JVM 最优参数配置不是一成不变的,根据实际压测,得到的。
压力测试可以用loadrunner或者jemeter,进行高并发模拟测试。
JVM 参数配置demo:
# elasticsearch/jvm.options
# 基础配置
-Xms31g
-Xmx31g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
# G1调优参数
-XX:InitiatingHeapOccupancyPercent=35
-XX:G1ReservePercent=25
-XX:G1HeapRegionSize=4m
# 内存锁防止Swap
-XX:+AlwaysPreTouch
-XX:+DisableExplicitGC
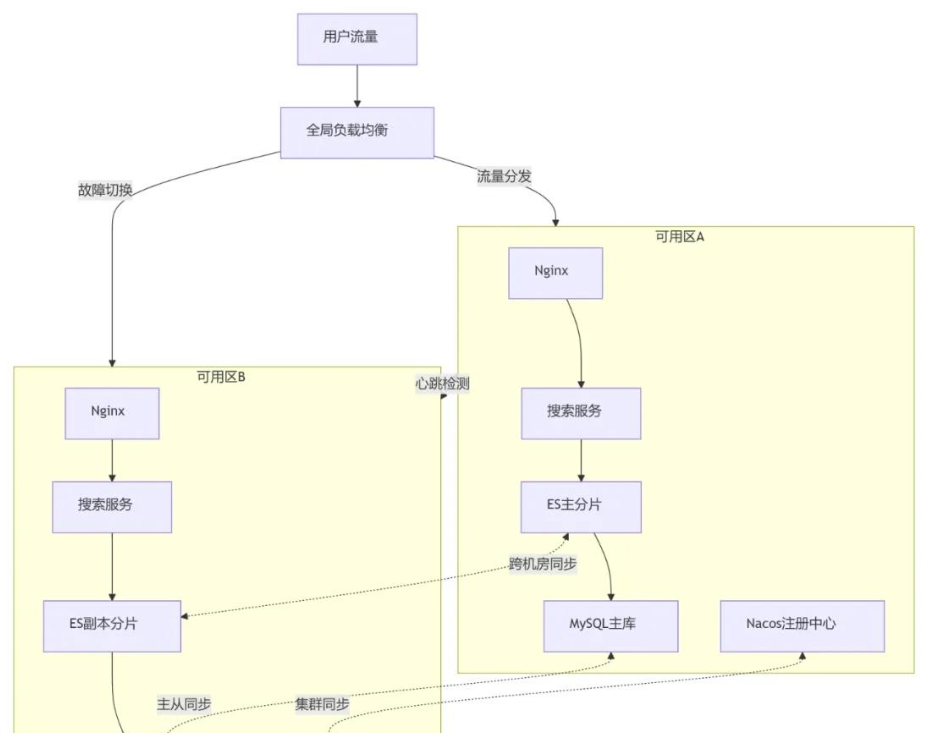
3.5 灾备与高可用设计
高并发系统,少不了容灾和高可用的设计要点,可以采取以下几种方式:
- 多 AZ 部署(分布在不同机房 / 可用区)
- Elasticsearch 设置跨机房副本(replica + shard allocation awareness)
- 服务注册中心(如 Nacos)与服务熔断、降级策略配合
- 主从切换、故障自动转移(Failover)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)