学术文献阅读平台开发(一):PDF文献解析实现
本文介绍了面向学术场景的文献解析平台的PDF解析模块实现过程。该模块通过MinerU开源工具实现复杂PDF文档的解析与内容抽取,能够处理多模态PDF文件中的文本、图片、表格和公式等元素。开发过程中采用FastAPI后端架构,实现了PDF上传、任务状态管理和结果获取等功能接口。技术难点包括双栏排版处理、图片表格识别、公式转换和章节结构恢复等。最终解决方案整合了MinerU的解析引擎,通过异步任务处理
摘要
本系列博客用于介绍正在搭建的一个面向学术场景的文献解析平台,我们将实现包括pdf文献解析,文献搜索,文献追踪,文献深度,深度理解问答在内的11+个功能模块。本篇博客是用于介绍本平台的第一个功能模块PDF文献解析功能的实现。该模块在实现过程中经历多次技术尝试,包括使用了pypdf包,maker开源库等,最后效果均不理想,最后尝试了一个Mineru的开源库进行实现。
一、PDF的原理
PDF实际上本质并非是文档,word、网页的排版都是流式排版。文字会自动换行适应屏幕,文档里存放的是段落标题列表等等语义结构,但是PDF是固定布局,每一页都是写死的,不会自适应电脑,同时文档里几乎不存在语义,只存在什么地方画什么矢量图,也就是说PDF的本质实际上存储的并不是文字而是一条一条的绘画指令。没有任何的表格、段落、标题,所有的显示的实际上都是靠坐标进行绘画的一张画布,因此解析PDF实际上就是解析这一系列的绘图指令。它具备矢量特性,在放大后永远清晰不失真。
总结来说PDF实际上是画出来的一个页面,而不是写出来的文档,这也是PDF难以解析的本质所在
二、PDF解析功能的痛点
1.开始时我们以为PDF解析仅仅是把文字读取出来,但是实际做下来之后我们发现,PDF的解析是一个相当困难的功能,要进行学术PDF的解析难点远远不只是文本的智能提取:
具体包括但不限于:
1.同一页中存在双栏排版,简单的PDF解析容易顺序混乱,甚至是出现前言不搭后语
2.图片与正文交错:在学术文献中有大量的图片,而PDF中的图片解析并且解析后在正确位置显示也是一件相当困难的事
3.表格不是规则的文本:正如我们之前在PDF原理所说,PDF实际上是画出来的一个画布,没有语义结构,因此解析报表格也是困难所在
4.公式的识别与渲染:我们即使相当调用视觉模型或其他的一些PDF解析进行文字提取,想以此来提取PDF中的文字,但也会出现学术文献场景下的数学公式的正确显示问题,往往提取出来的公式显示的就是一团latex代码,并非我们人眼识别的数学公式
5.章节层级的恢复问题:这也是因为PDF实际上不具备语义结构,因此原本的标题段落在解析之后,如何正确识别出来也是一大难点所在
6.阅读顺序必须正确:不会出现段落间的文本顺序错误
三、Mineru
3.1Mineru是什么?
MinerU 是上海人工智能实验室 OpenDataLab 团队研发的开源智能数据提取工具,核心聚焦于复杂 PDF 文档的高效解析与内容抽取工作。这款工具能够把搭载图片、公式、表格等多元元素的多模态 PDF 文件,转换为更易开展数据分析工作的 Markdown 格式,同时还支持从网页、电子书等载体中提取文本内容。该工具配备了高精度的 PDF 模型解析工具链,可适配多种输入模型,具备自动识别文档乱码的能力,在转换环节能完整留存原文档的结构框架,还可将公式精准转化为 LaTex 格式。MinerU 的应用场景广泛,覆盖学术科研、财务统计、法律文书等诸多领域,既支持 CPU 运行也兼容 GPU 加速,适配 Windows、Linux、Mac 三大主流操作系统,整体运行性能表现出众。
总体来说Mineru=视觉语言模型 + 专业 PDF 理解模型,huggingface上已开源他的参数权重
这是其官网的地址:MinerU-免费全能的文档解析神器
3.2为何选择Mineru
我们最开始也尝试过其他的PDF接续工具+大模型的模式来进行解析,但是发现最后的效果都不是很好,存在大量的乱码,表格位置混乱,图片不能显示,文本丢失等大量的问题。
经过我们团队队员的调研以及查询PDF解析的主流技术,我们发现,Mineru非常适配于我们的学术平台:
1.Mineru对学术PDF的适配能力强
2.不仅仅只是提取文本,还可以处理图片、表格、公式理解等复杂的元素
3.输出格式有较多格式,包括markdown、JSON、中间结果文件
4.开源,包括其相关模型的权重均开源,适合我们用于平台的解析层实现
3.3Mineru功能
1.复杂PDF文档高效解析与内容抽取
2.多模态PDF(图片、公式、表格)可转markdown
3.网页、电子书等载体文本提取
4.高解读PDF解析,适配多种输入模型
5.自动识别文档乱码
6.完整保留源文档结构框架
7.公式精准转换为latex格式
8.支持CPU运行与GPU加速
四、PDF解析模块的最终实现过程
我们的项目实现过程中使用的是AI+人工修改的方式,让根据我们的需求搭建出我们需要的功能模块,然后再对其中的问题进行再修改,使用的模型是chatgpt-5.3-codex,并且不再记录我们之前的失败技术,仅记录最后使用Mineru成功的过程
4.1给AI的prompt
你是一位后端专家,现在我需要搭建一个学术阅读平台,目前的进度是需要完成我们架构中的解析层,请你帮我完成这个功能模块的实现,实现过程请你采用软件工程的实现范式,模块化编程,记录你写好的api接口(包括如何调用,参数,接口作用)以方便我们进行人工代码审核与修改及后的功能与之后的代码实现。同时实现功能过程中不要使用其他PDF解析技术,指定你使用Mineru这个开源库来进行实现,Mineru需要使用的模型的相关权重已在huggingface上进开源,你可以直接下载。https://github.com/opendat该网址是Mineru在github上的地址。同时请你记住,在开发过程中对于不知道的问题请不要擅自修改,对于有疑问的地方请你直接向我提问,不得凭空捏造,如出现技术困难无法实现之处,请你不得擅自修改技术选型,开发语言python,现在请你开始完成
4.2ai开发工程中的问题
约20min后ai帮助我们完成了第一版的实现,但是经过我的测试,第一版功能并没有实现,存在大量的报错,且无法实现解析功能,如下图所示:
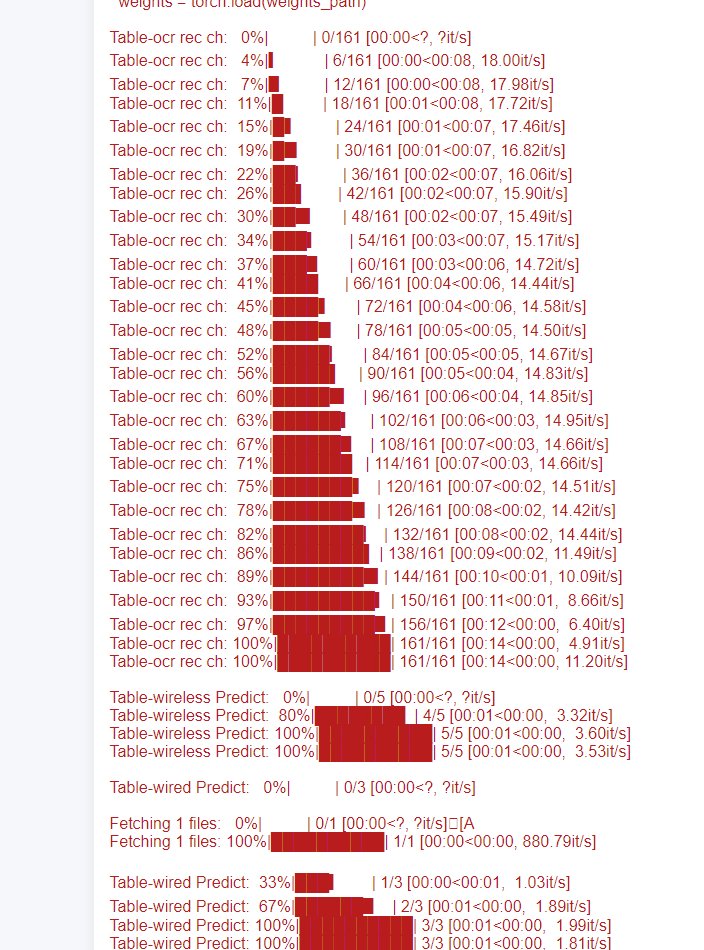
之后我们详细追踪了报错日志,发现是问题在于该功能有复杂的依赖链,ai有大量的依赖库未安装,包括如下的依赖:
fastapi==0.116.1
uvicorn==0.35.0
python-multipart==0.0.20
httpx==0.28.1
mineru==3.0.9
--extra-index-url https://download.pytorch.org/whl/cpu
torch==2.5.1+cpu
torchvision==0.20.1+cpu
transformers==4.52.4
tokenizers==0.21.4
huggingface-hub==0.34.4
numpy==2.2.6
opencv-python==4.13.0.92
shapely==2.1.2
albumentations==2.0.8
omegaconf==2.3.0
ftfy==6.3.1
pyclipper==1.4.0
这些依赖是github上给出,以及部分我们环境所需的依赖,使用pip install +依赖项 完成所有的依赖安装后,第一版功能成功跑通
4.3效果展示:
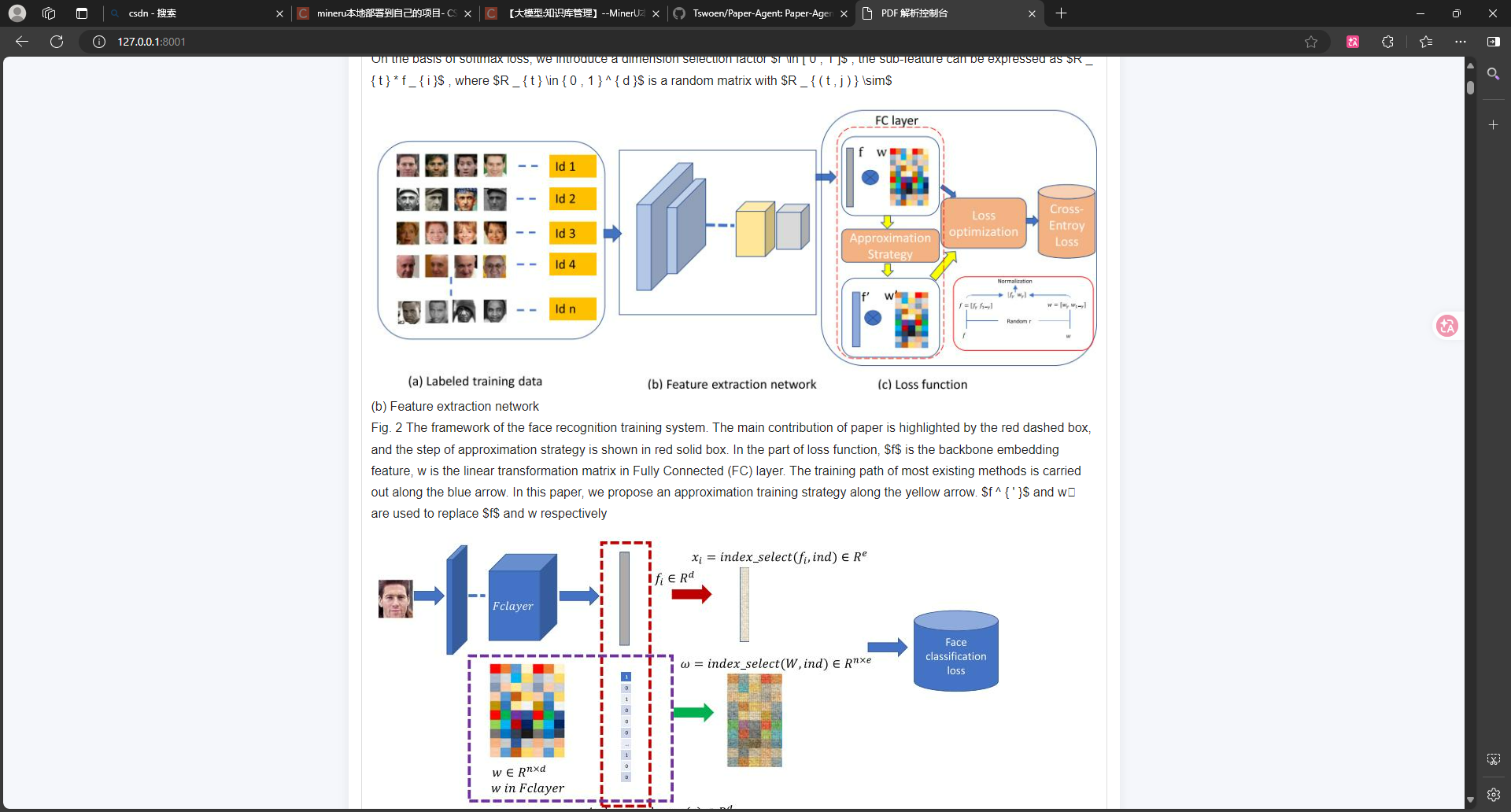
此时我们的文献可以看到几乎已经正确显示,但是扔存在如顶部所示的部分letex公式显示问题。经过我的查询,发现可以使用前端渲染来解决这个问题,因此我们又重新向ai说了:当前功能存在letex公式无法正确渲染问题,问题出在前段渲染,请你考虑使用渲染清除这些噪声点。并经过几轮的反复调试,最终消除了噪声点,对于我们传入的文献几乎都可以完美的显示出来
五.PDF解析模块实现的原理与数据流
5.1功能涉及技术
1.后端架构本次使用FastAPI,用于提供上传,任务状态,结果获取,资源访问接口
2.任务化解析:上传后生成一个task_id,后台线程执行Mineru,状态写入task.json
3.MinerU集成:后端会执行Mineru。把输入出写进任务目录并回收md/json
4.资源可视化 :静态资源路由 + Markdown 图片链接重写提供 /api/v1/tasks/{task_id}/assets/... 并把 Markdown 里的相对路径改为可访问 URL
5.2模块职责划分
1.MinerU(解析引擎)负责
-文档理解流水线:版面分析、OCR、公式识别、表格识别、阅读顺序重建
-生成解析产物:Markdown、JSON、图片资源与中间文件
2.我们的后端(FastAPI)负责
- 提供上传接口与任务接口:创建任务、查询状态、获取结果
- 以 CLI 方式调用 MinerU,控制输入/输出目录
- 统一整理结果文件(写 result.md/result.json )
- 提供图片等资源的可访问接口,并对 Markdown 图片链接做重写
3.我们的前端负责
- 上传 PDF、轮询任务状态
- Markdown 渲染(marked)
- 公式渲染(MathJax)与少量噪声清洗
- 展示图片/表格(通过后端 assets 路由加载)
5.3整体流程(数据流)
用户(浏览器)→ 我们的前端页面:选择 PDF,点击上传
前端 → 我们的后端(FastAPI):上传 PDF 文件(multipart/form-data)
后端 → 文件系统:保存 PDF 到任务目录 data/parsed/<task_id>/xxx.pdf ,写入 task.json 后端 → 后台线程:启动解析线程(异步执行)
后台线程 → MinerU(CLI):传入输入 PDF 路径、输出目录,执行解析命令
MinerU → 文件系统:在输出目录写 Markdown/JSON/图片等产物
后台线程 → 文件系统:把“最终结果”落成 result.md/result.json ,并更新 task.json 为 succeeded/failed
前端 ⇄ 后端:轮询任务状态;成功后请求结果与资源
后端 → 前端:返回 Markdown/JSON(结果 API)+ 图片资源(assets API)
前端:把 Markdown 渲染成 HTML,MathJax 渲染公式,图片通过 assets URL 加载
上传阶段实现方案
前端通过POST请求发送PDF文件到/api/v1/tasks接口,使用multipart/form-data格式上传,字段名为file。后端接收文件后生成唯一task_id,创建任务目录结构。
data/parsed/<task_id>/
├── <filename>.pdf
└── task.json
后端立即返回JSON响应包含任务基础信息:
{
"task_id": "uuidv4",
"status": "pending",
"output_dir": "/data/parsed/<task_id>"
}
解析阶段技术细节
后台线程通过TaskService._run_task启动处理流程,更新任务状态为running。调用MinerU解析时使用预定义命令模板:
MINERU_COMMAND_TEMPLATE = (
'py -3.10 -c "from mineru.cli.client import main; main()" '
'-p "{input_path}" -o "{output_dir}" -b pipeline'
)
执行命令前需验证Python环境与MinerU模块是否可用。输出目录设置为data/parsed/<task_id>/mineru_output保持隔离
结果标准化处理
解析完成后,后端从MinerU输出目录提取有效结果进行标准化:
- 合并多个.md文件为单个
result.md - 转换中间JSON为统一结构的
result.json - 移动图片资源到标准位置
- 执行Markdown链接重写
前端交互流程
轮询接口返回完整任务状态对象
{
"status": "succeeded",
"created_at": "ISO8601",
"updated_at": "ISO8601",
"error": null
}
总结来说就是:“前端上传 PDF 到后端 → 后端创建 task_id 并保存文件 → 后台线程调用 MinerU CLI 解析 → MinerU 在任务目录产出 Markdown/JSON/图片 → 后端统一整理成 result.md/result.json 并更新任务状态 → 前端轮询状态成功后拉取结果 → 前端渲染 Markdown+MathJax,图片通过后端 assets 接口按需加载。”
六、开发总结
最后的感受是PDF解析功能是一个相当复杂的功能,如果不依赖开源库,单单以我们学生的理解以及编码能力,是无法完成如此复杂功能的实现的,该功能的实现更多的依赖了开源库与chatgpt的编程能力,帮助我们省下了很多的编码时间
现在的编码确实已经进入了ai'编码时代,但是根据我在开发过程中的感受来看,ai现在编码还是倾向于需要人类提出需求,设计好架构,功能耦合,ai写出的功能能在第一次完成百分之80+正确,但是最后百分之20的调试往往需要更多的时间精力以及人工干涉排错等等,需要对技术选型需要足够的了解,当出现问题时才知道如何解决,如何采取其他技术去解决,如果仅交由ai全处理,往往最后的功能会偏离预想
最后经过检查,ai写的接口文档全部正确,可以供我们进行后续功能的拓展与开发,之后我们将基于Langgraph框架,来实现多agent编排的其余功能搭建与实现

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)