【技术】容器-harbor项目列表加载过慢与 ChartMuseum 优化实践
1. 问题背景
在生产环境中使用 Harbor 2.4 版本(后端存储使用 S3 对象存储)时,用户反馈项目列表页面(Projects)加载极其缓慢,通常需要等待 30s 左右才会显示结果,且频繁出现请求超时或报错。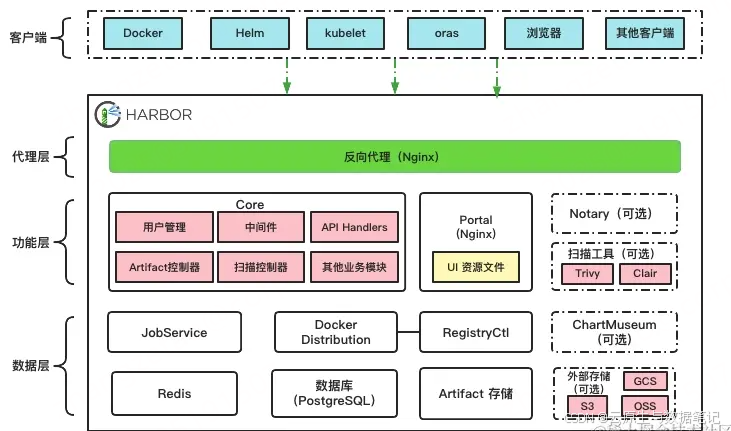
环境信息
- Harbor 版本:2.4.x
- 存储后端:S3 对象存储 (xstore)
- 缓存机制:Redis
- 涉及组件:harbor-core, harbor-chartmuseum
2. 异常现象与日志分析
2.1 日志表现
通过查看 harbor-core 的日志,发现了大量的 context deadline exceeded 报错:
[ERROR] failed to filter charts: get content failed: send request GET /creator-xxx/index.yaml failed: Get "http://harbor-chartmuseum/creator-xxx/index.yaml": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
[ERROR] get chart count of project 344610 failed: get content failed: send request GET /mlops-zygl/index.yaml failed: Get "http://harbor-chartmuseum/mlops-xxx/index.yaml": context deadline exceeded
2.2 现象总结
- 同步阻塞:Harbor 在加载项目列表页时,会同步调用 ChartMuseum 接口获取每个项目的 Chart 数量(Chart Count)。
- 硬超时:Harbor Core 对内部组件的请求设置了约 20s-30s 的超时阈值。
- 级联失败:只要项目列表中包含一个“巨型项目”(Chart 版本极多),整个 API 请求就会卡死,导致前端界面转圈或报错。
3. 核心根因分析 (RCA)
经过深入分析,发现问题的根源在于 Helm Chart 索引文件(index.yaml)的体积爆炸。
3.1 ChartMuseum 的机制
ChartMuseum 负责管理 Helm Chart。为了兼容 Helm 客户端,它必须为每个项目维护一个 index.yaml 索引文件。该文件包含了该项目下所有 Chart 的所有历史版本。
3.2 性能瓶颈点
- S3 扫描开销:当缓存失效或项目变动时,ChartMuseum 需要扫描 S3 桶中的所有
.tgz文件。如果一个项目下有数千个版本,S3 的ListObjects操作耗时会显著增加。 - 文件体积与带宽:一个拥有几千个版本的项目,其
index.yaml体积可能达到 20MB - 50MB。 - CPU 解析瓶颈 (Unmarshal):Harbor Core 在收到
index.yaml后,必须使用 Go 的yaml.Unmarshal将其加载到内存并解析。解析数 MB 的 YAML 是一个极度消耗 CPU 且缓慢的过程。
结论: 当版本过多时,下载 + 解析庞大的 index.yaml 的总耗时超过了 Harbor 的内部超时限制。
4. 解决方案:引入 INDEX_LIMIT
为了快速恢复业务性能,我们在 ChartMuseum 的配置中引入了 INDEX_LIMIT 参数。
4.1 参数原理
INDEX_LIMIT 是 ChartMuseum 服务端的一个限流/截断参数。
- 设置值:
INDEX_LIMIT: "500" - 逻辑:ChartMuseum 在生成并返回
index.yaml给客户端(Harbor Core)之前,会强制截断条目,只保留每个 Chart 最新的 500 个版本。
4.2 为什么有效?
- 体积骤减:
index.yaml从几十 MB 缩小到了几百 KB。 - 解析飞快:Harbor Core 几乎可以毫秒级完成解析并统计出 Chart 数量。
- 网络无压力:减少了 S3 与容器间、容器与容器间的网络流量。
5. 实施与配置
在 Harbor 的 docker-compose.yml 或 chartserver 环境变量配置中添加:
data:
INDEX_LIMIT: "500" # 限制索引条目数为 500
CACHE: redis # 配合 Redis 缓存效果更佳
CACHE_REDIS_ADDR: ...
关键操作建议:
修改参数后,必须执行 docker-compose down && docker-compose up -d 重启,重建harbor-chartmuseum 的服务即可,以确保新的截断策略立即生效。
6. 影响与风险评估
6.1 积极影响
- 项目列表加载速度从 30s 降至 < 1s。
- 系统整体 CPU 和内存占用大幅下降,稳定性显著提升。
6.2 负面影响(副作用)
- 版本不可见性:超过 500 个限制之外的旧版本 Chart 将不再出现在索引文件中。
- Helm 客户端影响:用户如果尝试安装极其古老的版本(在 500 名开外),
helm install会提示version not found。 - 注意:S3 上的物理数据不会丢失,这仅仅是一个“展示层”的限制。
7. 长期建议与架构演进
INDEX_LIMIT 是一个优秀的“灭火器”,但为了彻底解决性能问题,建议采取以下策略:
-
建立清理机制:通过 CI/CD 或脚本,定期清理 S3 上不必要的历史 Chart 版本。建议保留版本数控制在 100 以内。
-
迁移至 OCI 模式(推荐)
:
- 从 Harbor 2.x 开始,支持 Helm Chart 以 OCI 镜像格式 存储。
- 优点:直接使用
helm push到镜像仓库,数据直接存入数据库,不依赖index.yaml。查询性能是数据库级的(毫秒),彻底解决 ChartMuseum 的架构瓶颈。
-
监控预警:针对 ChartMuseum 的请求响应耗时建立监控,提前发现“巨型项目”。
总结:在 Harbor 与 Helm 结合的重度使用场景下,合理的版本保留策略(Retention Policy)与关键性能参数(INDEX_LIMIT)是保障私有仓库高可用的核心要素。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)