【CVPR26-俞思悦-西交利物浦大学】TALENT:面向指代表达图像分割的目标感知高效微调方法
文章:TALENT: Target-aware Efficient Tuning for Referring Image Segmentation
代码:https://github.com/Kimsure/TALENT
单位:西交利物浦大学、利物浦大学、中国石油大学(华东)、北京科技大学、北京交通大学
一、问题背景
1. 任务定义
RIS需要建立文本描述 ↔ 视觉区域的一对一精确匹配,对类别、属性、空间关系的细粒度对齐要求极高,是视觉-语言理解中极具挑战的任务。
2. 现有方法痛点
-
全参数微调(PFT):效果好但计算开销巨大,模型扩展能力差。
-
参数高效微调(PET):仅训练少量参数,轻量化高效,但无法区分同类别不同实例,出现非目标激活(NTA)。
-
量化问题:论文提出NTA-IoU指标,专门衡量模型错误分割到同类别非目标区域的比例,分数越高代表NTA问题越严重。
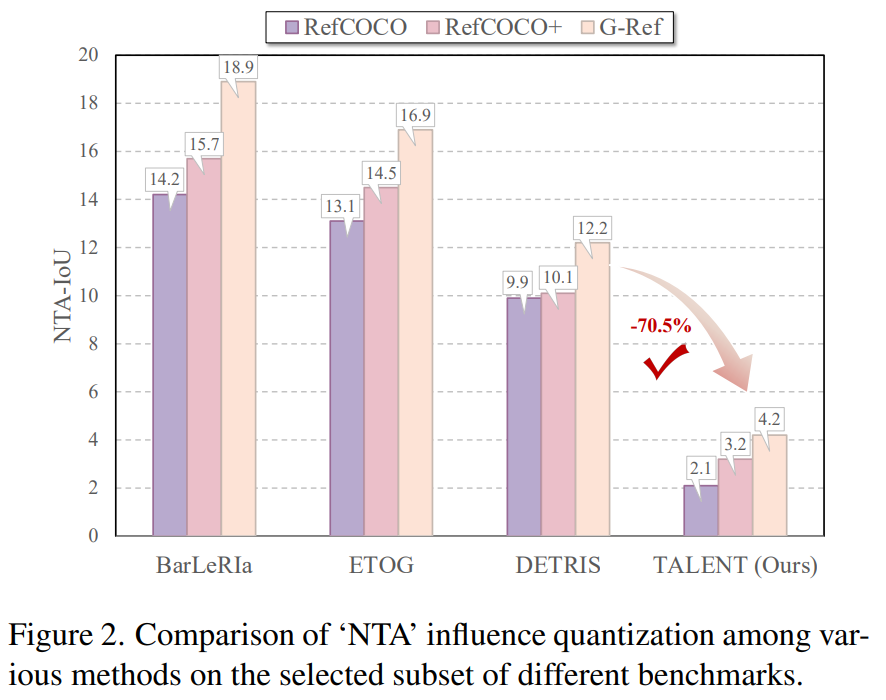
3. 核心矛盾
现有PET模型只关注语义类别,忽略文本描述的实例级细节(如“准备击球的棒球手”而非任意棒球手),最终分割到显著但错误的物体。
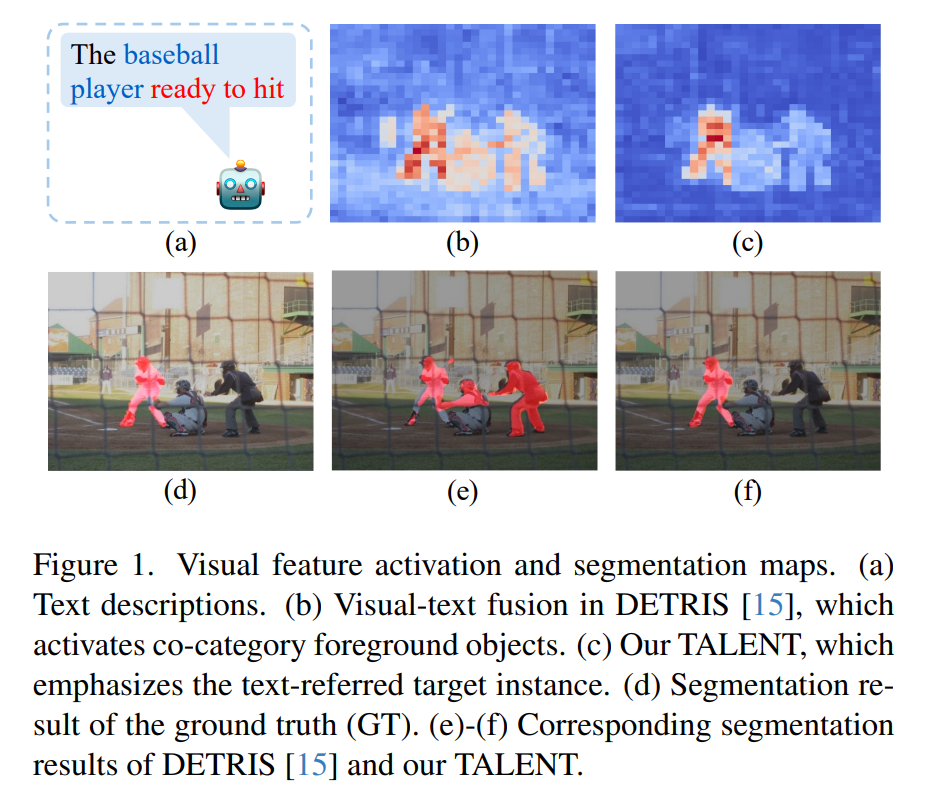
二、方法创新(核心详解)
TALENT整体架构基于冻结DINOv2-Reg视觉编码器+冻结CLIP文本编码器,仅训练少量新增模块,实现目标感知的高效微调。
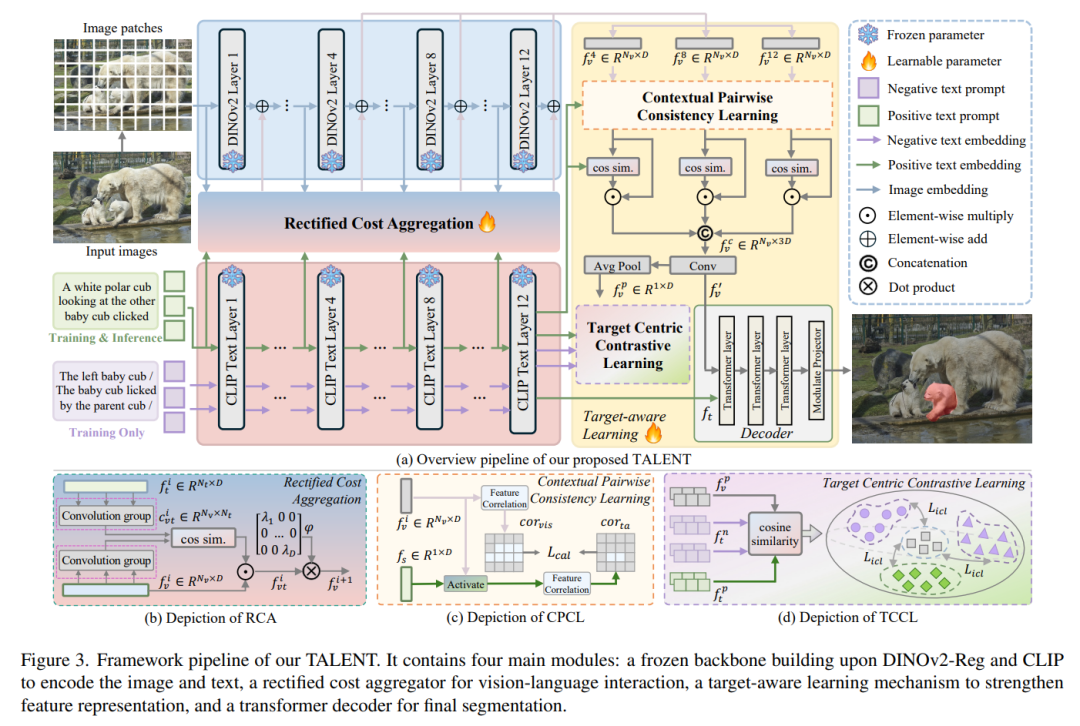
1. 总设计思路
-
用修正成本聚合器(RCA) 做高效视觉-文本特征融合。
-
用目标感知学习机制(TLM) 双重校准特征,抑制NTA。
-
Transformer解码器输出最终分割掩码。
2. 核心模块1:修正成本聚合器(RCA)
解决问题:传统跨模态融合易产生无关交互,无法精准聚焦文本指向区域。创新点:
-
构建向量化成本体(cost volume),建模视觉-文本匹配关系。
-
使用ReLU过滤负向匹配响应,只保留文本相关的正向对齐。
-
引入可学习对角矩阵做残差缩放,最小化对冻结主干的干扰。作用:把文本信息注入视觉特征,让模型初步“看懂”文本指向的区域。
3. 核心模块2:目标感知学习机制(TLM)
TLM包含两个互补学习目标,协同解决NTA:
(1)上下文成对一致性学习(CPCL)
-
利用CLIP句子级全局文本特征,构建文本增强的特征亲和图。
-
强制视觉特征的相关性与文本引导的相关性对齐。
-
学习上下文感知的语义关联,粗定位目标区域。效果:让特征关注文本描述的整体语境,而非单纯类别。
(2)目标中心对比学习(TCCL)
-
构造正/负文本对:正样本是目标描述,负样本是同图其他物体描述。
-
用对比损失拉近视觉特征与正文本、推远与负文本。
-
强化实例级细粒度区分能力。效果:精准锁定唯一目标实例,彻底区分同类别不同物体。
4. 总损失函数
总损失由三部分构成:
-
文本到像素判别损失(主损失)
-
CPCL成对一致性损失
-
TCCL对比损失 三者联合优化,实现粗定位+细粒度区分,全面抑制NTA。
三、实验结果
实验在RefCOCO / RefCOCO+ / G-Ref三大标准数据集开展,使用oIoU、mIoU、Precision@X评估。
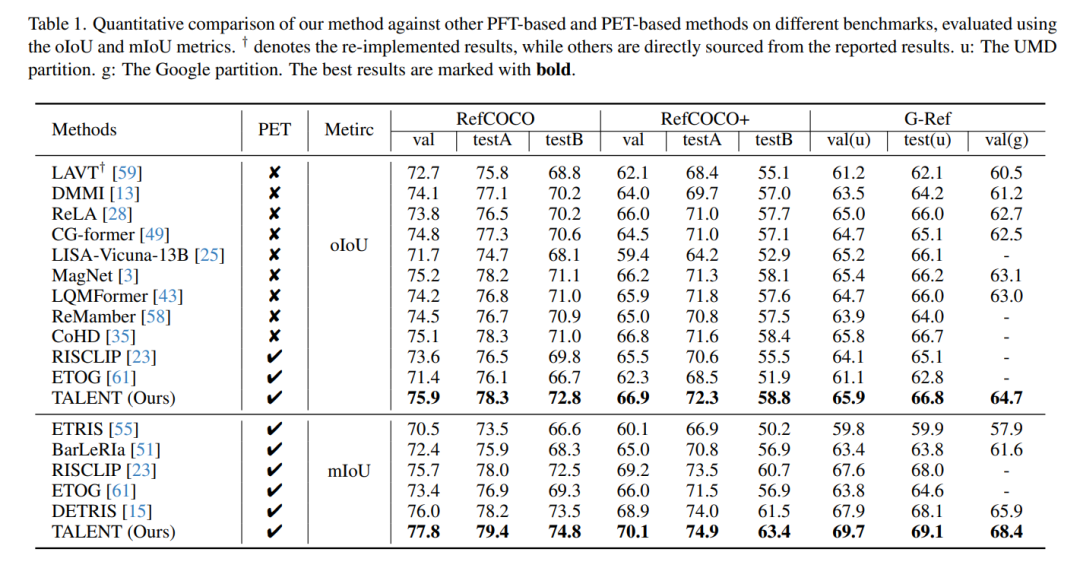
1. 定量SOTA
-
超越所有PET方法:在RefCOCO上mIoU达**77.8%**,超DETRIS 1.8%。
-
超越全参数微调(PFT)方法:优于ReMamber、CoHD等。
-
超越大模型方案:比LISA-Vicuna-13B高3.6%~4.7% oIoU。
-
G-Ref val集mIoU提升**2.5%,Precision@0.9提升12.6%**。
2. NTA抑制效果
NTA-IoU从基线9.9%降至**2.1%,下降幅度超78%**,证明非目标激活被极大缓解。
3. 参数量效率
总可训练参数仅22.77M,远低于传统方案,在轻量化PET模型中性能第一。
4. 可视化结果
-
对比方法:激活同类别所有显著物体。
-
TALENT:只激活文本描述的唯一目标,分割掩码与GT高度吻合。
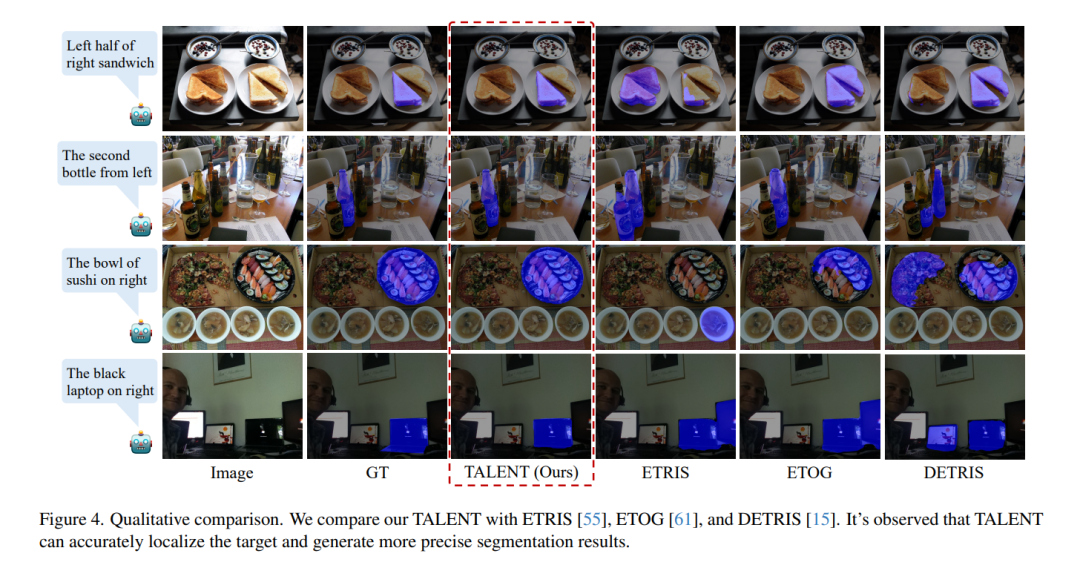
四、优势与局限
1. 核心优势
-
首次定义并量化NTA问题,为PET-RIS提供新评测维度。
-
RCA+TLM双模块设计,精准解决同类别实例混淆。
-
高效轻量化:冻结主干、仅训少量参数,训练成本极低。
-
泛化性强:TLM可兼容cross-attention等其他跨模态结构。
-
SOTA性能:在所有主流数据集全面领先。
2. 局限
-
依赖冻结的DINOv2-Reg与CLIP,对主干有一定选型约束。
-
在极端复杂背景、小目标、遮挡严重场景仍有少量误差。
-
暂未适配实时推理部署,侧重精度与训练效率。
五、一句话总结
TALENT针对PET-RIS中普遍存在的非目标激活(NTA)痛点,提出修正成本聚合器+目标感知双学习机制,在极低参数量下实现精准文本-目标实例对齐,全面刷新参考图像分割SOTA,为轻量化视觉-语言分割提供了全新解决方案。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)