Flink 反压机制深度解析:原理、排查与调优
前言
在 Flink 流处理作业中,反压(Backpressure)是一个非常重要的概念。当下游算子处理速度跟不上上游算子的数据发送速度时,就会产生反压。如果不能正确处理反压问题,轻则导致作业延迟增加,重则导致 OOM 或作业失败。
本文将从反压的底层原理出发,详细介绍 Flink 的反压机制演进、监控排查方法以及调优策略。
一、反压原理
1.1 什么是反压
反压是流式计算系统中的一种自我保护机制。当数据流中某个节点处理速度低于上游发送速度时,会导致数据积压。反压机制能够将这种"压力"向上游传递,使整个数据流的处理速度趋于平衡,避免因数据积压导致的内存溢出。
反压传播方向:数据记录在作业中从 Source 流向 Sink(下游方向),而反压则沿相反方向传播(上游方向)。以简单的 Source -> Sink 作业为例,如果 Source 出现反压警告,说明 Sink 消费数据的速度比 Source 生产数据的速度慢,Sink 正在对上游算子 Source 施加反压。
1.2 为什么要关注反压
反压是机器或算子过载的指标,关注反压的原因包括:
- 影响端到端延迟:反压导致记录在队列中等待更长时间才能被处理
- 影响 Checkpoint:对齐的 Checkpoint 在反压时耗时更长,非对齐的 Checkpoint 会变得更大
- 资源优化:通过解决反压可以降低作业运行成本
注意:反压并不总是需要处理。从定义上讲,没有反压意味着集群至少有轻微的资源闲置。如果要最大化资源利用率,可能无法完全避免反压,这在批处理中尤为明显。
1.3 TCP 自带反压的局限性
Flink 早期版本(1.5 之前)依赖 TCP 的流量控制来实现反压。
工作原理:
在 TaskManager 之间通过 TCP 连接传输数据时,每个 Subtask 都有自己的 Buffer Pool:

当下游 Buffer Pool 满时,TCP 接收端停止读取数据,导致 TCP 滑动窗口变为 0,从而阻塞上游发送。
二、网络流控与反压机制
2.1 为什么需要网络流控

如上图所示,Producer 发送速率 2MB/s,Consumer 处理速率 1MB/s,存在 1MB/s 的速度差。
5 秒后 Receive Buffer 会积压 5MB 数据,这时会面临两种情况:
- 有界 Buffer:新数据被丢弃
- 无界 Buffer:Buffer 持续扩张,最终导致 Consumer 内存耗尽(OOM)
解决方案演进:
|
方案 |
说明 |
问题 |
|
静态限速 |
在 Producer 端设置固定速率限制 |
无法预估 Consumer 承受能力,且 Consumer 能力会动态变化 |
|
动态反压 |
Consumer 实时反馈处理能力给 Producer |
Flink 采用的方案 |
2.2 Flink 网络传输架构
在理解反压机制前,需要先了解 Flink 的网络传输架构。

关键点:发送端和接收端各有三层 Buffer,Flink 1.5 之前依赖 TCP 流控实现反压。
2.3 TCP 流控机制(滑动窗口)
TCP 通过滑动窗口机制实现流量控制,接收端通过 Window Size 告知发送端还能接收多少数据。
示例:滑动窗口流控过程
初始状态:发送端速率 3 packet/s,接收端速率 1 packet/s,接收窗口大小 5

2.4 Flink TCP-based 反压机制(1.5 之前)
Flink 1.5 之前,依赖 TCP 滑动窗口实现反压。反压传播分为两个阶段:
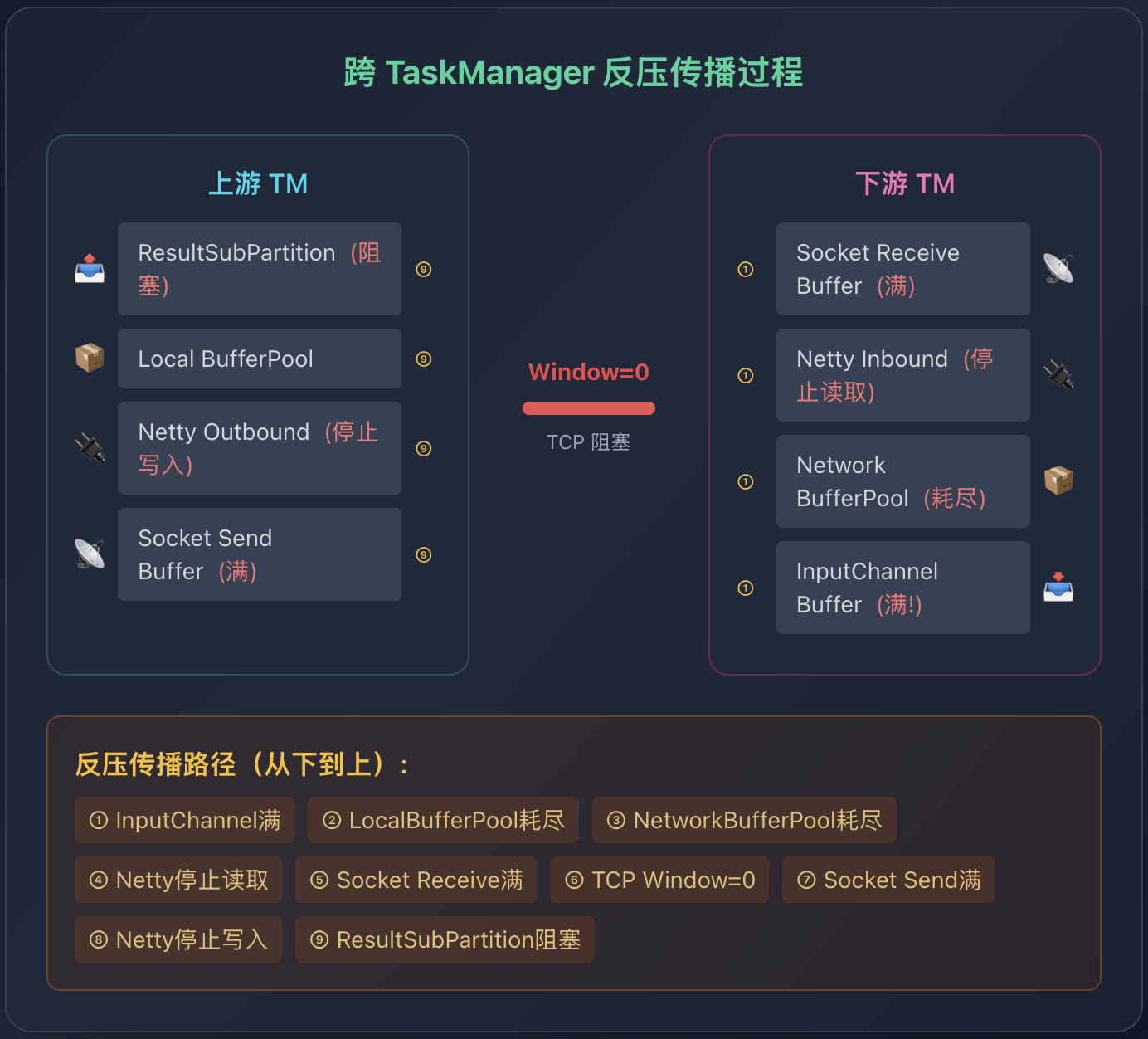
阶段一:跨 TaskManager 反压传播
当下游处理速度跟不上时,反压从 InputGate 传播到上游 ResultPartition。
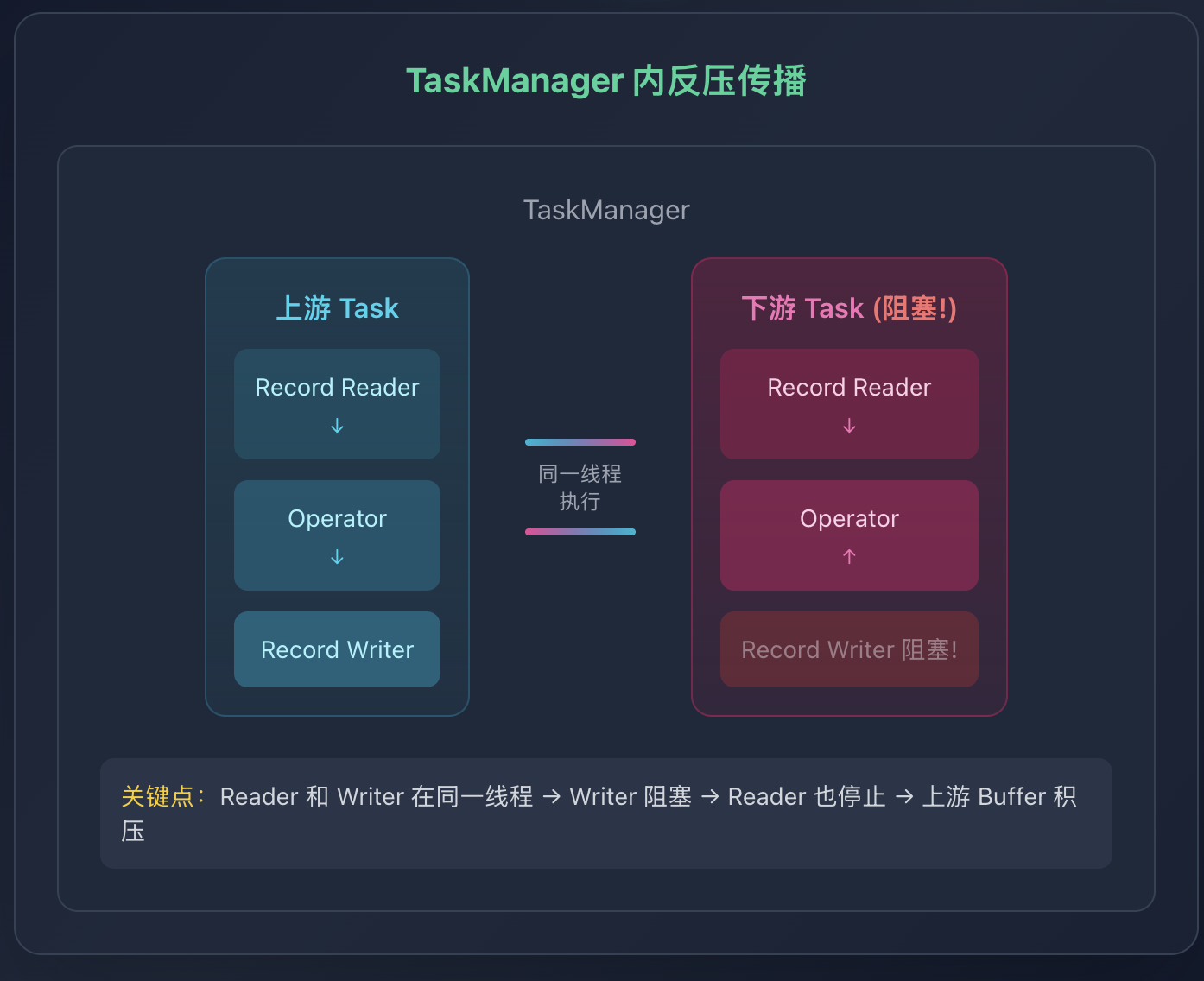
阶段二:TaskManager 内反压传播
当 ResultSubPartition 被阻塞后,反压在 TaskManager 内部继续向上传播。
TCP-based 反压的弊端

2.5 Credit-based 反压机制(1.5+)
Flink 1.5 引入 Credit-based 流控,在应用层实现类似 TCP 的流控机制,解决上述问题。
核心思想
Credit 机制 ≈ 应用层的 TCP Window 机制
- Backlog:发送端告知接收端"我有多少数据要发"
- Credit:接收端告知发送端"我能接收多少数据"

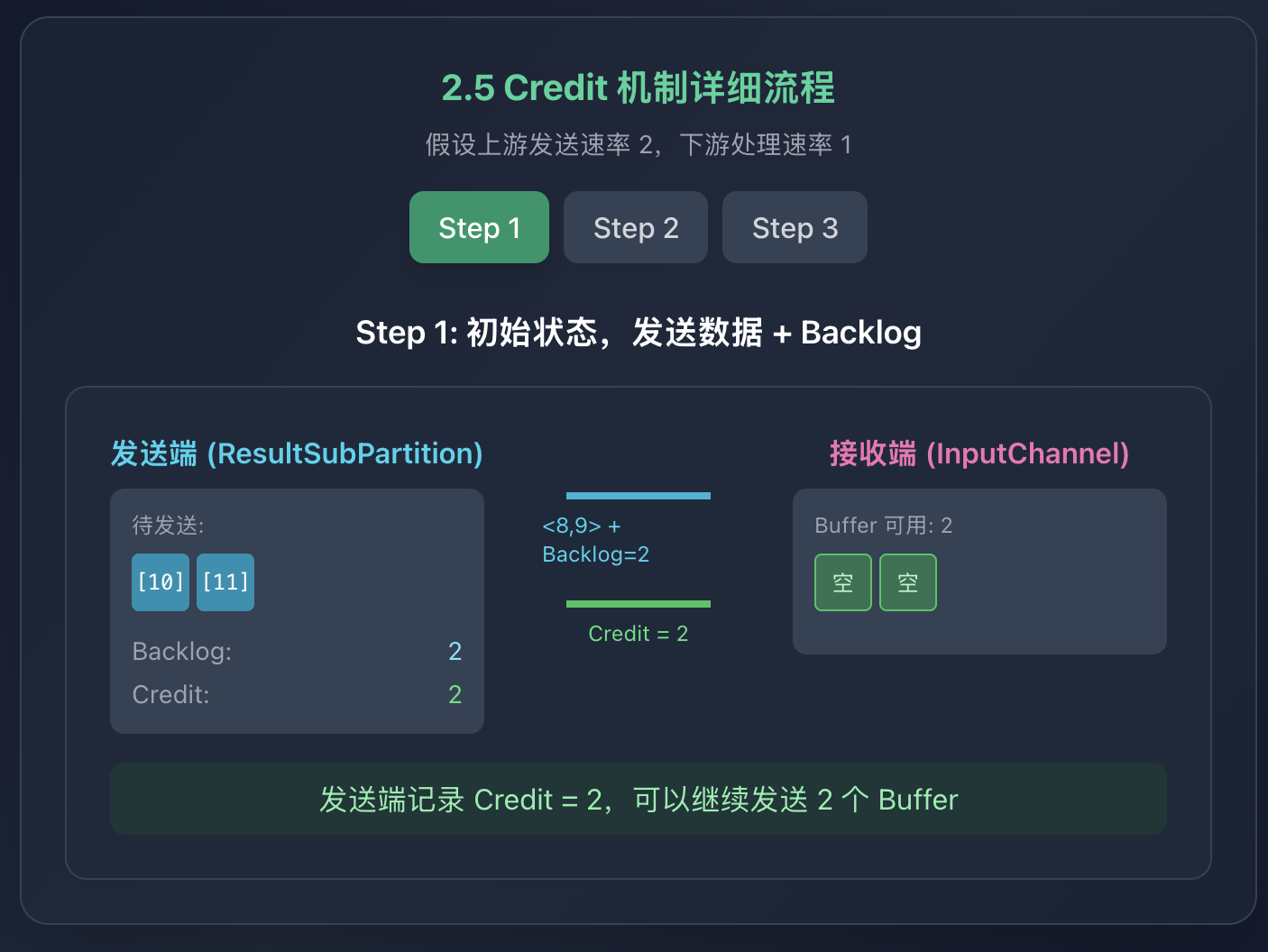
Credit 机制详细流程示例
假设上游发送速率 2,下游处理速率 1:
Credit 机制的优势

2.6 Exclusive Buffer 与 Floating Buffer
为什么需要两种 Buffer?

2.7 反压判定机制
在底层,反压是基于输出缓冲区的可用性来判断的:
- 如果一个 Task 没有可用的输出缓冲区,则该 Task 被认为处于反压状态
- 空闲状态则是根据是否有可用的输入数据来判断
三、反压监控与排查
3.1 核心指标(Flink 1.13+)
每个 Subtask 暴露三个核心时间指标:
|
指标 |
说明 |
|
|
每秒处于反压状态的时间(毫秒) |
|
|
每秒处于空闲状态的时间(毫秒) |
|
|
每秒处于忙碌状态的时间(毫秒) |
重要特性:
- 三个指标之和约等于 1000ms(类似于 CPU 使用率指标)
- 指标值是过去几秒的平均值
- 涵盖 Subtask 线程中的所有活动:算子、函数、定时器、Checkpoint、序列化/反序列化、网络栈等
注意事项:
- 使用旧版
SourceFunction接口的 Source 算子,busyTimeMsPerSecond会显示NaN/N/A - 这些指标无法感知在独立线程中发生的操作
3.2 Web UI 颜色指示
Flink Web UI 通过颜色直观展示 Task 状态:
|
颜色 |
状态 |
说明 |
|
🔵 蓝色 |
空闲 |
Task 处于空闲状态 |
|
🔴 红色 |
忙碌 |
Task 正在全力处理数据 |
|
⚫ 黑色 |
反压 |
Task 被下游反压 |
|
混合色 |
中间状态 |
三种状态的组合 |
快速定位方法:
- 找到黑色(反压)的 Task
- 在该 Task 下游找到最红(最忙碌)的 Task
- 这个最忙碌的 Task 很可能就是反压的源头(瓶颈)
3.3 反压采样机制
JobManager 通过定期采样来监控反压状态:

反压等级判定:
|
等级 |
比例范围 |
说明 |
|
OK |
0 ≤ ratio ≤ 0.10 |
正常,无反压 |
|
LOW |
0.10 < ratio ≤ 0.50 |
轻微反压,需关注 |
|
HIGH |
0.50 < ratio ≤ 1.00 |
严重反压,需处理 |
ratio = 处于反压状态的采样次数 / 总采样次数
3.4 反压参数配置
# flink-conf.yaml
# 反压结果刷新间隔,过期后重新采样(默认 60000ms = 1分钟)
web.backpressure.refresh-interval: 60000
# 每次采样的样本数(默认 100)
web.backpressure.num-samples: 100
# 采样间隔时间(默认 50ms)
web.backpressure.delay-between-samples: 503.5 排查步骤详解
3.5.1 通过 Web UI 查看
步骤一:查看 Job Graph 整体状态
- 打开 Flink Web UI → 进入 Job 详情页
- 观察各 Task 的颜色:
-
- 黑色 Task → 正在被反压
- 红色 Task(位于黑色 Task 下游)→ 可能是瓶颈
步骤二:查看 Subtask 详情
- 点击具体的 Task
- 进入 BackPressure 标签页
- 查看各 Subtask 的 Busy / Backpressured / Idle 比例
Flink 1.17.2 新增:从 Subtask BackPressure 标签页跳转时支持自动搜索 Subtask 堆栈。
3.5.2 通过 Metrics 监控
关键指标:
# Subtask 级别时间指标
backPressuredTimeMsPerSecond
busyTimeMsPerSecond
idleTimeMsPerSecond
# 缓冲区使用率指标
outPoolUsage # 输出缓冲池使用率
inPoolUsage # 输入缓冲池使用率(= floatingBuffersUsage + exclusiveBuffersUsage)
floatingBuffersUsage # 浮动缓冲区使用率
exclusiveBuffersUsage # 独占缓冲区使用率
# 吞吐量指标
numRecordsOutPerSecond
numRecordsInPerSecond3.5.3 定位反压源头
核心思路:找到第一个出现反压的节点,然后检查其下游。
判断标准:
|
场景 |
指标特征 |
结论 |
|
当前节点是瓶颈 |
Busy 高,Backpressured 低,下游 Idle 高 |
该节点处理能力不足 |
|
下游反压传导 |
Backpressured 高 |
继续向下游排查 |
|
网络瓶颈 |
下游输入缓冲空,上游输出缓冲满 |
网络带宽不足 |
定位示例:
A (backpressured 93%) -> B (backpressured 85%) -> C (backpressured 11%) -> D (backpressured 0%)在这个例子中,最接近 Sink 且反压值高的是 B,真正的慢算子是其下游的 C。
3.5.4 使用 Flame Graph 分析
Web UI 集成了 Flame Graph:
- 进入 Job 详情页
- 点击需要分析的 Task
- 进入 Flame Graph 标签页
- 分析热点函数调用
Flame Graph 可以帮助定位代码中的性能瓶颈,特别适用于 CPU 密集型问题的分析。
四、反压调优策略
4.1 处理反压的三种方式
应对反压有三种主要策略,可以单独或组合使用:
- 消除反压源:优化 Flink 作业、调整配置或扩容
- 减少 in-flight 数据量:使用 Buffer Debloating 或手动调整缓冲区配置
- 启用非对齐 Checkpoint:避免 Checkpoint 被反压阻塞
4.2 Buffer Debloating(缓冲区自动调节)
Flink 1.14 引入的自动控制 in-flight 数据量的功能,在 Flink 1.17 中更加成熟。
# 启用 Buffer Debloating
taskmanager.network.memory.buffer-debloat.enabled: true
# 目标缓冲时间(默认 1000ms)
taskmanager.network.memory.buffer-debloat.target: 1000ms
# 吞吐量计算的时间窗口
taskmanager.network.memory.buffer-debloat.period: 200ms适用场景:
- 配合对齐 Checkpoint 使用效果最明显
- 配合非对齐 Checkpoint 使用可减小 Checkpoint 大小和恢复时间
4.3 非对齐 Checkpoint(Flink 1.17 生产可用)
在 Flink 1.17 中,非对齐 Checkpoint 已经可以在生产环境使用,解决了之前版本写入大量小文件的问题。
# 启用非对齐 Checkpoint
execution.checkpointing.unaligned.enabled: true
# 对齐超时后切换为非对齐(可选)
execution.checkpointing.aligned-checkpoint-timeout: 30s优势:
- Checkpoint 时间与吞吐量解耦,不再嵌入数据流
- 在反压场景下 Checkpoint 完成率大幅提升
注意事项:
- 非对齐 Checkpoint 会增加状态存储的 I/O 开销
- 如果状态存储 I/O 是瓶颈,则不建议使用
- 恢复时 Flink 会在恢复 in-flight 数据后才生成 Watermark
4.4 网络缓冲区配置(Flink 1.17 更新)
# 网络缓冲区内存占比
taskmanager.memory.network.fraction: 0.1
# 网络缓冲区最小值
taskmanager.memory.network.min: 64mb
# 网络缓冲区最大值(Flink 1.17 默认值改为 Long.MAX_VALUE)
taskmanager.memory.network.max: 1gb
# 单个 Buffer 大小(默认 32KB)
taskmanager.memory.segment-size: 32kb
# 每个 Channel 的 Exclusive Buffer 数量(默认 2)
taskmanager.network.memory.buffers-per-channel: 2
# Floating Buffer 数量(默认 8)
taskmanager.network.memory.floating-buffers-per-gate: 8
# Overdraft Buffer 数量(默认 5)
taskmanager.network.memory.max-overdraft-buffers-per-gate: 5
# Required Buffers 阈值(Flink 1.17 新增,用于减少 buffer 不足导致的失败)
taskmanager.network.memory.read-buffer.required-per-gate.max: 1000Flink 1.17 变化说明:
taskmanager.memory.network.max默认值从 1GB 改为 Long.MAX_VALUE,减少用户手动调整配置的需求- 新增
taskmanager.network.memory.read-buffer.required-per-gate.max参数,批处理默认会减少所需缓冲区数量
4.5 资源层面
4.5.1 增加并行度
// 全局并行度
env.setParallelism(16);
// 算子级别并行度
dataStream
.keyBy(...)
.process(new MyProcessFunction())
.setParallelism(32); // 单独设置4.5.2 增加 TaskManager 资源
# flink-conf.yaml
taskmanager.memory.process.size: 4096m
taskmanager.numberOfTaskSlots: 4
taskmanager.cpu.cores: 4建议:保持平均负载在 70% 以下,为负载峰值预留空间。
4.6 算子层面
4.6.1 优化数据倾斜
// 方案1:预聚合 + 二次聚合(加盐打散)
dataStream
.map(record -> new Tuple2<>(record.getKey() + "_" + random.nextInt(10), record))
.keyBy(t -> t.f0)
.reduce(...) // 预聚合
.map(t -> new Tuple2<>(t.f0.split("_")[0], t.f1))
.keyBy(t -> t.f0)
.reduce(...); // 最终聚合
// 方案2:使用 Rebalance
dataStream
.rebalance() // 强制轮询分发
.map(...);4.6.2 使用异步 IO
对于涉及外部系统访问的场景,使用 AsyncIO 避免阻塞:
AsyncDataStream.unorderedWait(
inputStream,
new AsyncDatabaseRequest(),
1000, // 超时时间
TimeUnit.MILLISECONDS,
100 // 最大并发请求数
);4.6.3 启用 MiniBatch 聚合
// 启用 MiniBatch(Table API / SQL)
tableConfig.set("table.exec.mini-batch.enabled", "true");
tableConfig.set("table.exec.mini-batch.allow-latency", "5s");
tableConfig.set("table.exec.mini-batch.size", "5000");4.6.4 减少算子中的日志输出
生产环境中减少日志输出,或考虑将调试信息输出到单独的数据流。
4.7 状态后端优化
# 使用 HashMapStateBackend 替代 RocksDB(适用于小状态)
state.backend: hashmap
# RocksDB 优化配置
state.backend.rocksdb.localdir: /ssd/flink/rocksdb
state.backend.incremental: true
state.backend.local-recovery: true4.8 Checkpoint 优化
# 增大 Checkpoint 间隔
execution.checkpointing.interval: 180000
# 设置最小间隔
execution.checkpointing.min-pause: 60000
# 启用增量 Checkpoint(RocksDB)
state.backend.incremental: true
# 启用本地恢复
state.backend.local-recovery: trueFlink 1.17 Checkpoint 改进:
- 通用增量 Checkpoint (GIC) 提升了 Checkpoint 速度和稳定性
- 支持通过 REST API 手动触发 Checkpoint 并指定类型
五、常见反压原因与解决方案
|
原因 |
现象 |
解决方案 |
|
数据倾斜 |
部分 Subtask 繁忙,其他空闲 |
加盐打散、Rebalance |
|
外部系统慢 |
涉及 IO 的算子反压 |
使用 AsyncIO |
|
CPU 密集计算 |
Busy 指标高 |
增加并行度、优化算法 |
|
序列化开销 |
网络传输算子反压 |
使用高效序列化器(Kryo、Avro) |
|
GC 问题 |
周期性反压 |
调整内存配置、优化 GC |
|
Checkpoint 阻塞 |
Checkpoint 期间反压 |
启用非对齐 Checkpoint、Buffer Debloating |
|
网络瓶颈 |
所有算子都反压 |
增加网络带宽、Buffer 配置 |
|
大记录序列化 |
单条记录处理慢 |
增加 Overdraft Buffer |
六、最佳实践总结
- 监控先行:建立完善的 Metrics 监控体系,关注 busy/backpressured/idle 三个核心指标
- 找准源头:通过 Web UI 颜色和指标定位第一个产生反压的节点及其下游瓶颈
- 使用 Flame Graph:对瓶颈算子进行代码级别的性能分析
- 启用 Buffer Debloating:自动控制 in-flight 数据量,改善 Checkpoint 性能
- 考虑非对齐 Checkpoint:在 Flink 1.17 中已生产可用,适合严重反压场景
- 避免数据倾斜:数据倾斜是导致反压的常见原因
- 合理设置并行度:保持平均负载在 70% 以下
七、Flink 1.17 相关更新汇总
|
特性 |
说明 |
|
非对齐 Checkpoint 生产可用 |
解决了之前写入大量小文件的问题 |
|
通用增量 Checkpoint (GIC) |
提升 Checkpoint 速度和稳定性 |
|
REST API 触发 Checkpoint |
支持运行时手动触发指定类型的 Checkpoint |
|
Network Max 默认值调整 |
默认改为 Long.MAX_VALUE |
|
Required Buffers 阈值 |
减少因 Buffer 不足导致的失败 |
|
Subtask 堆栈自动搜索 |
BackPressure 标签页跳转时自动搜索(1.17.2) |
参考资料
- Apache Flink 1.17 官方文档 - Monitoring Back Pressure
- Apache Flink 1.17 官方文档 - Checkpointing Under Backpressure
- Apache Flink 1.17 官方文档 - Network Memory Tuning
- How to identify the source of backpressure - Flink Blog
- Announcing the Release of Apache Flink 1.17
- Apache Flink 1.17 Release Notes
更新时间:2025-01-05

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)