在ubuntu部署EFK测试功能使用
官网下载 elasticsearch 链接
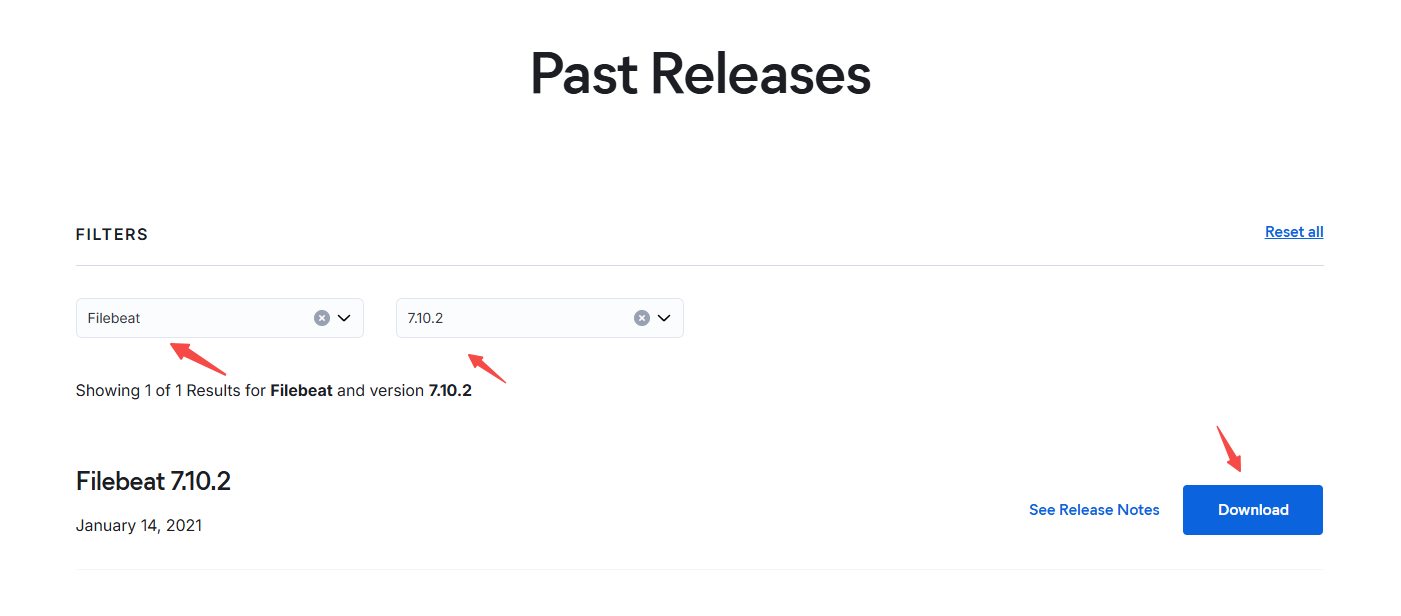
https://www.elastic.co/downloads/past-releases?product=elasticsearch
官网搜索 elasticsearch 下载指定 版本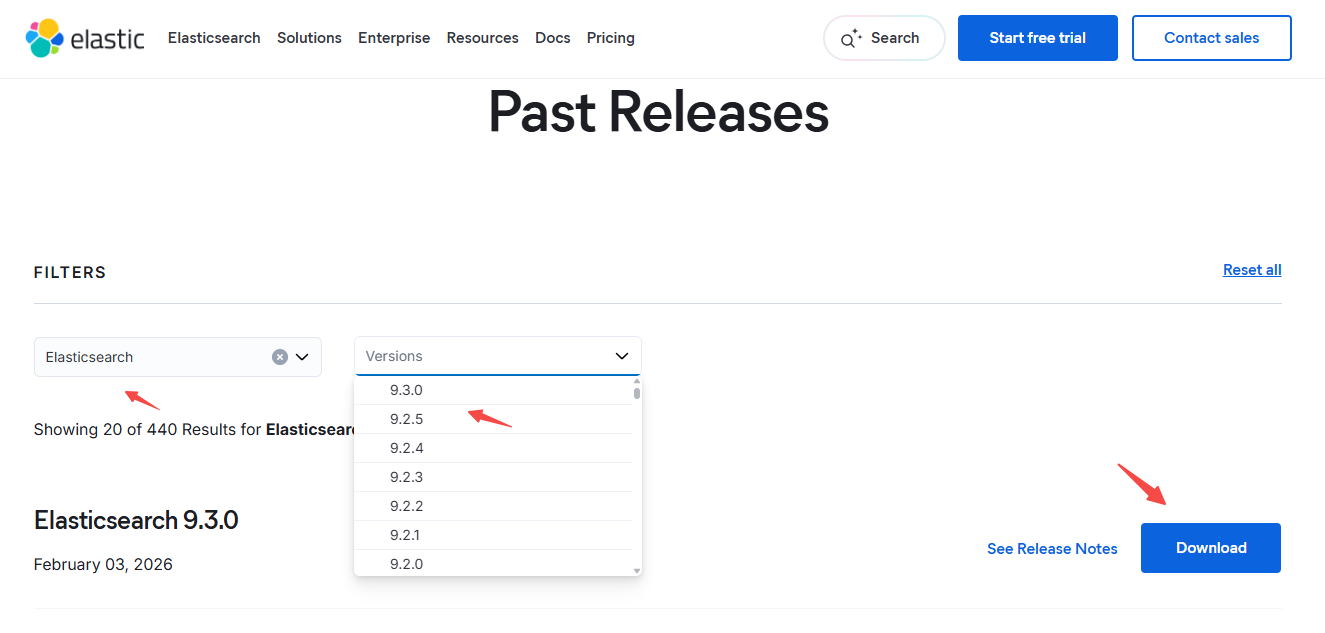
下载直接解压使用
右键复制下载链接

下载 elasticsearch
mkdir -p /opt/efk
cd /opt/efk
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.2-linux-x86_64.tar.gz
tar xvf elasticsearch-7.10.2-linux-x86_64.tar.gz
mv elasticsearch-7.10.2 elasticsearch
添加 elasticsearch 用户
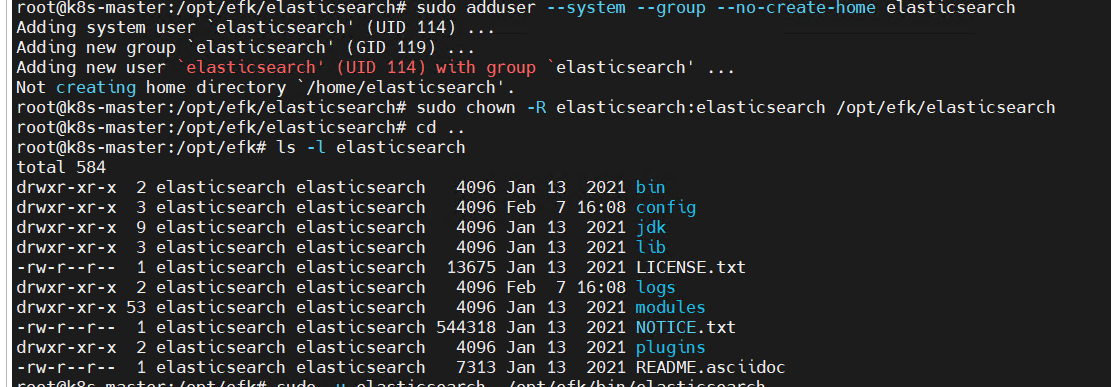
sudo adduser --system --group --no-create-home elasticsearch
sudo chown -R elasticsearch:elasticsearch /opt/efk/elasticsearch
修改配置
vim /opt/efk/elasticsearch/config/elasticsearch.yml
grep -v "^#" /opt/efk/elasticsearch/config/elasticsearch.yml

启动报错添加下方配置,永久生效
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
# 新建一个 Elasticsearch 专用配置文件
echo "vm.max_map_count=262144" | sudo tee /etc/sysctl.d/99-elasticsearch.conf
# 加载配置
sudo sysctl -p /etc/sysctl.d/99-elasticsearch.conf
# 查看配置是否生效
sysctl vm.max_map_count

后台运行 elasticsearch
# -d 后台运行
sudo -u elasticsearch /opt/efk/elasticsearch/bin/elasticsearch -d
# 执行这个命令退出
pkill -u elasticsearch -f elasticsearch
查看运行日志
less /opt/efk/elasticsearch/logs/elasticsearch.log
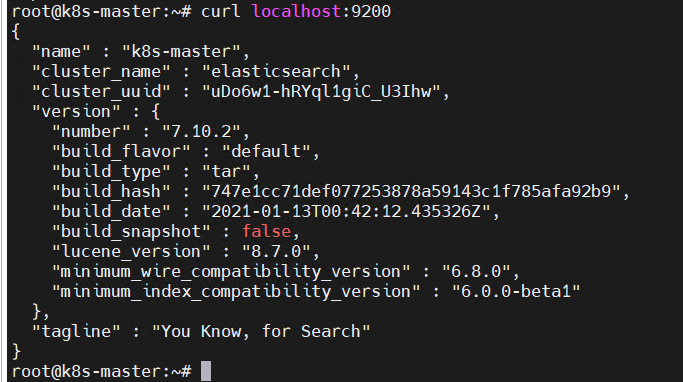
curl localhost:9200
看到下面的图就代表成功
kibana 下载
cd /opt/efk
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.10.2-linux-x86_64.tar.gz
tar xvf kibana-7.10.2-linux-x86_64.tar.gz
mv kibana-7.10.2-linux-x86_64 kibana
修改配置
vim /opt/efk/kibana/config/kibana.yml
grep -Ev "^#|^$" /opt/efk/kibana/config/kibana.yml

后台运行 kibana
nohup /opt/efk/kibana/bin/kibana --allow-root >> /opt/efk/kibana/kibana.log 2>&1 &
# 执行这个命令退出
pkill -f kibana
打开 kibana 链接
http://127.0.0.1:5601
查看运行日志
less /opt/efk/kibana/kibana.log
filebeat 下载
mkdir -p /opt/efk
cd /opt/efk
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.2-linux-x86_64.tar.gz
tar xvf filebeat-7.10.2-linux-x86_64.tar.gz
mv filebeat-7.10.2-linux-x86_64 filebeat
# 跟改默认的配置文件 自己写
mv /opt/efk/filebeat/filebeat.yml /opt/efk/filebeat/filebeat.ymlbak
添加 filebeat 配置文件 输出控制台
vim /opt/efk/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/pods/*/*/*.log
fields:
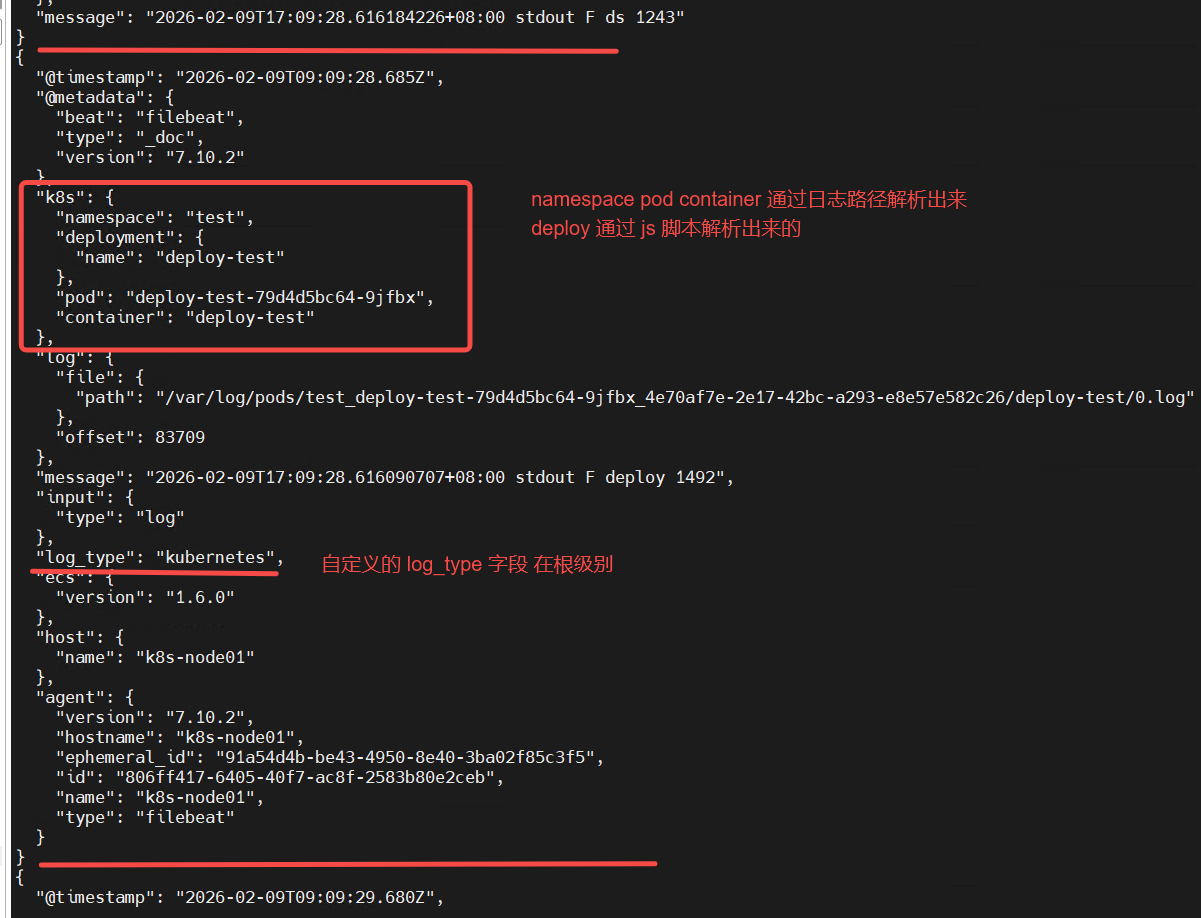
log_type: kubernetes
# 把 log_type 自定义的字段 直接放到日志 根级别
fields_under_root: true
processors:
- dissect:
tokenizer: "/var/log/pods/%{namespace}_%{pod}_%{}/%{container}/%{}.log"
field: "log.file.path"
# 所有提取的字段加上 k8s. 前缀
target_prefix: "k8s"
# 使用 javascript 语言 解析 k8s.pod 获取 pod对应的 sts deploy ds 的名称
- script:
lang: javascript
source: |
function process(event) {
var pod = event.Get("k8s.pod");
if (!pod) return;
var parts = pod.split('-');
var last = parts[parts.length - 1];
var secondLast = parts.length >= 2 ? parts[parts.length - 2] : "";
// 规则判断
if (/^\d+$/.test(last)) {
// sts-test-0 → statefulset
event.Put("k8s.statefulset.name", parts.slice(0, -1).join('-'));
}
else if (/^[a-f0-9]{8,10}$/.test(secondLast)) {
// deploy-test-79d4d5bc64-9jfbx → deployment
event.Put("k8s.deployment.name", parts.slice(0, -2).join('-'));
}
else if (/^[a-zA-Z0-9]{5}$/.test(last)) {
// ds-test-dl9vm → daemonset
event.Put("k8s.daemonset.name", parts.slice(0, -1).join('-'));
}
}
# 输出到控制台查看 调试使用
output.console:
pretty: true
# ubuntu22.04安装filebeat报错 添加下面参数
seccomp:
default_action: allow
syscalls:
- action: allow
names:
- rseq
前台运行filebeat
查看输出是否符合预期
cd /opt/efk/filebeat
./filebeat -e -c filebeat.yml
修改filebeat配置 日志存es
收集系统日志和k8s pod日志
# 日志输入路径
filebeat.inputs:
# 系统日志收集
- type: log
enabled: true
paths:
- /var/log/syslog
# 排除 .gz 结尾的
exclude_files: ['\.gz$']
fields:
log_type: system
log_file: syslog
fields_under_root: true
# k8s pod 日志收集
- type: log
paths:
- /var/log/pods/*/*/*.log
# 排除空行
exclude_lines: ["^\\s+$"]
multiline:
pattern: '^\d{4}-\d{2}-\d{2}'
negate: true
match: after
# 单行日志 最大5M
max_bytes: 5242880
fields:
log_type: kubernetes
# 把 log_type 自定义的字段 直接放到日志 根级别
fields_under_root: true
queue.mem:
events: 2048 # 设置为 bulk_max_size * worker 的 2-4 倍
flush.min_events: 512 # 攒够一个 batch 就立即发送,减少延迟
flush.timeout: 1s # 如果一直攒不够,最多等 1 秒也要发
processors:
- dissect:
tokenizer: "/var/log/pods/%{namespace}_%{pod}_%{}/%{container}/%{}.log"
field: "log.file.path"
# 所有提取的字段加上 k8s. 前缀
target_prefix: "k8s"
# 当日志类型是 kubernetes 才进行这个解析
when:
contains:
log_type: "kubernetes"
# 使用 javascript 语言 解析 k8s.pod 获取 pod对应的 sts deploy ds 的名称
- script:
lang: javascript
source: |
function process(event) {
var pod = event.Get("k8s.pod");
if (!pod) return;
var parts = pod.split('-');
var last = parts[parts.length - 1];
var secondLast = parts.length >= 2 ? parts[parts.length - 2] : "";
// 规则判断
if (/^\d+$/.test(last)) {
// sts-test-0 → statefulset
event.Put("k8s.statefulset.name", parts.slice(0, -1).join('-'));
}
else if (/^[a-f0-9]{8,10}$/.test(secondLast)) {
// deploy-test-79d4d5bc64-9jfbx → deployment
event.Put("k8s.deployment.name", parts.slice(0, -2).join('-'));
}
else if (/^[a-zA-Z0-9]{5}$/.test(last)) {
// ds-test-dl9vm → daemonset
event.Put("k8s.daemonset.name", parts.slice(0, -1).join('-'));
}
}
when:
contains:
log_type: "kubernetes"
# 输出到 Elasticsearch
output.elasticsearch:
hosts: ["http://10.0.3.100:9200"]
worker: 1 # 使用 1 个工作线程 默认也是1个
bulk_max_size: 512 # 每次批量发送 512 条数据
indices:
- index: "log-system-%{+yyyy.MM.dd}"
when.contains:
log_type: "system"
- index: "log-%{[k8s.namespace]}-%{+yyyy.MM.dd}"
when.contains:
log_type: "kubernetes"
# ubuntu22.04安装filebeat报错 添加下面参数
seccomp:
default_action: allow
syscalls:
- action: allow
names:
- rseq
后台运行filebeat
cd /opt/efk/filebeat
nohup ./filebeat -e -c filebeat.yml >> filebeat.log &
# 执行这个命令退出
pkill -f filebeat
# 查看日志
less /opt/efk/filebeat/filebeat.log
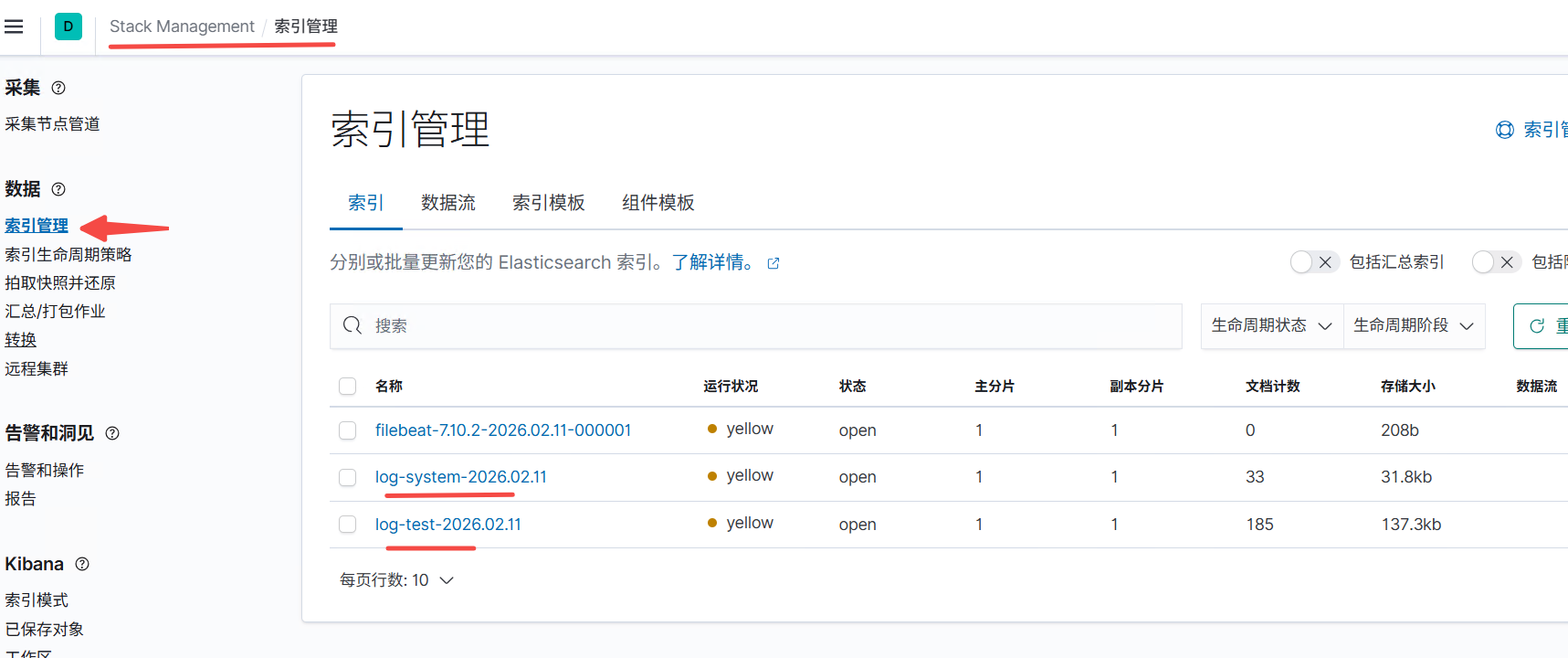
kibana 界面查看
我这是单节点 所以运行状态是 yellow
创建索引模式
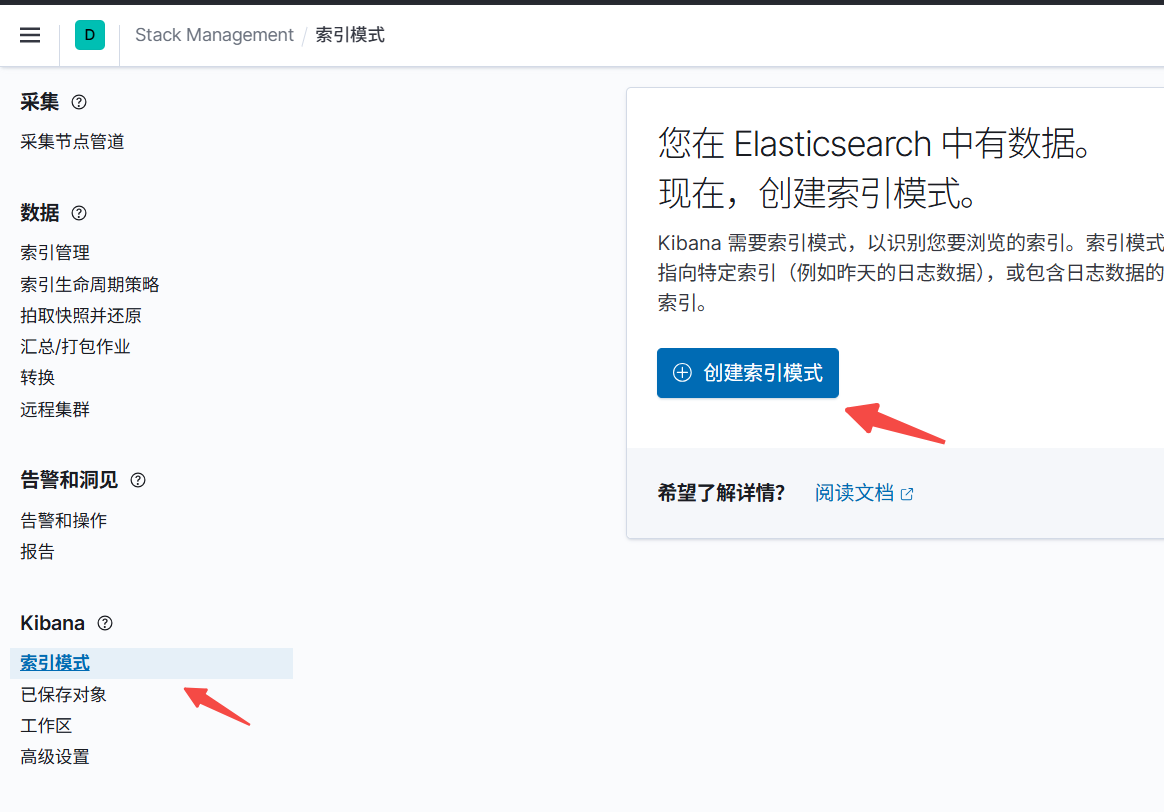
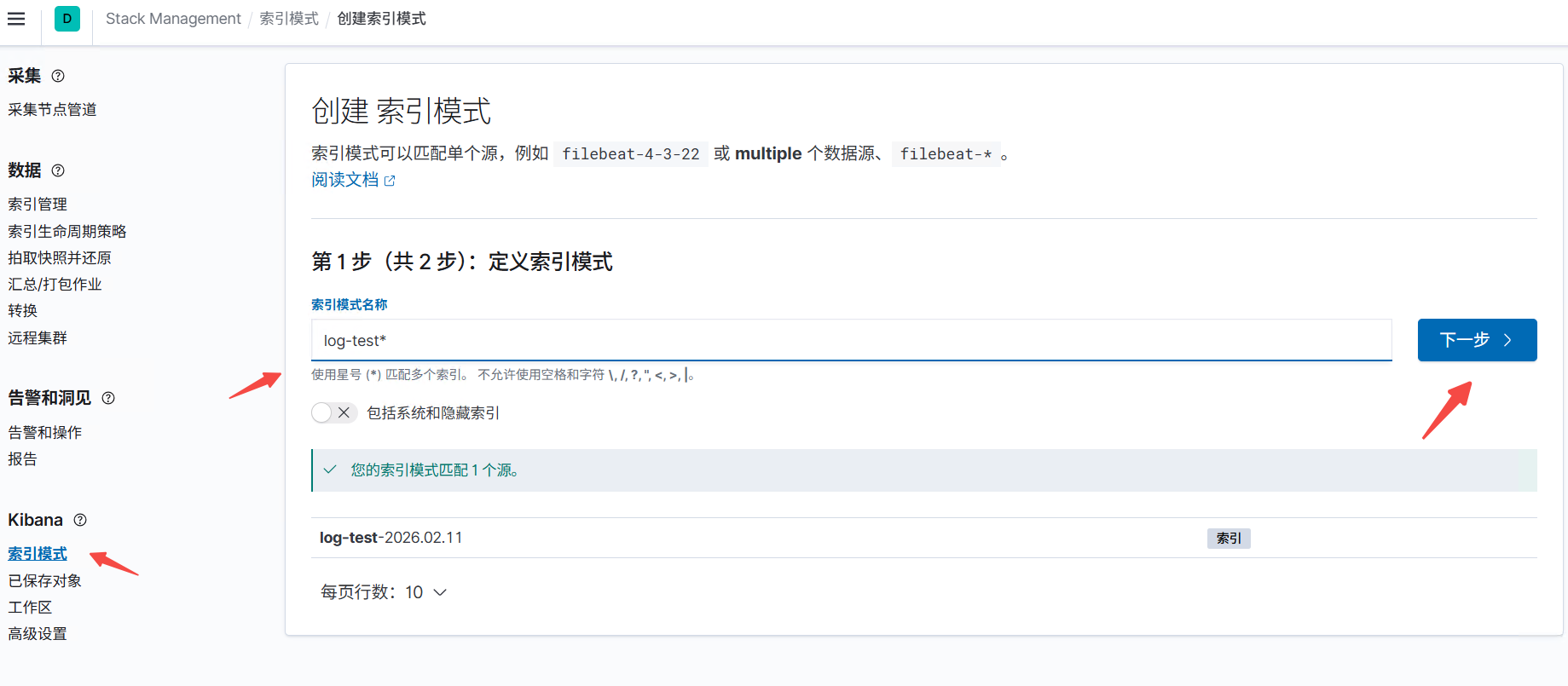
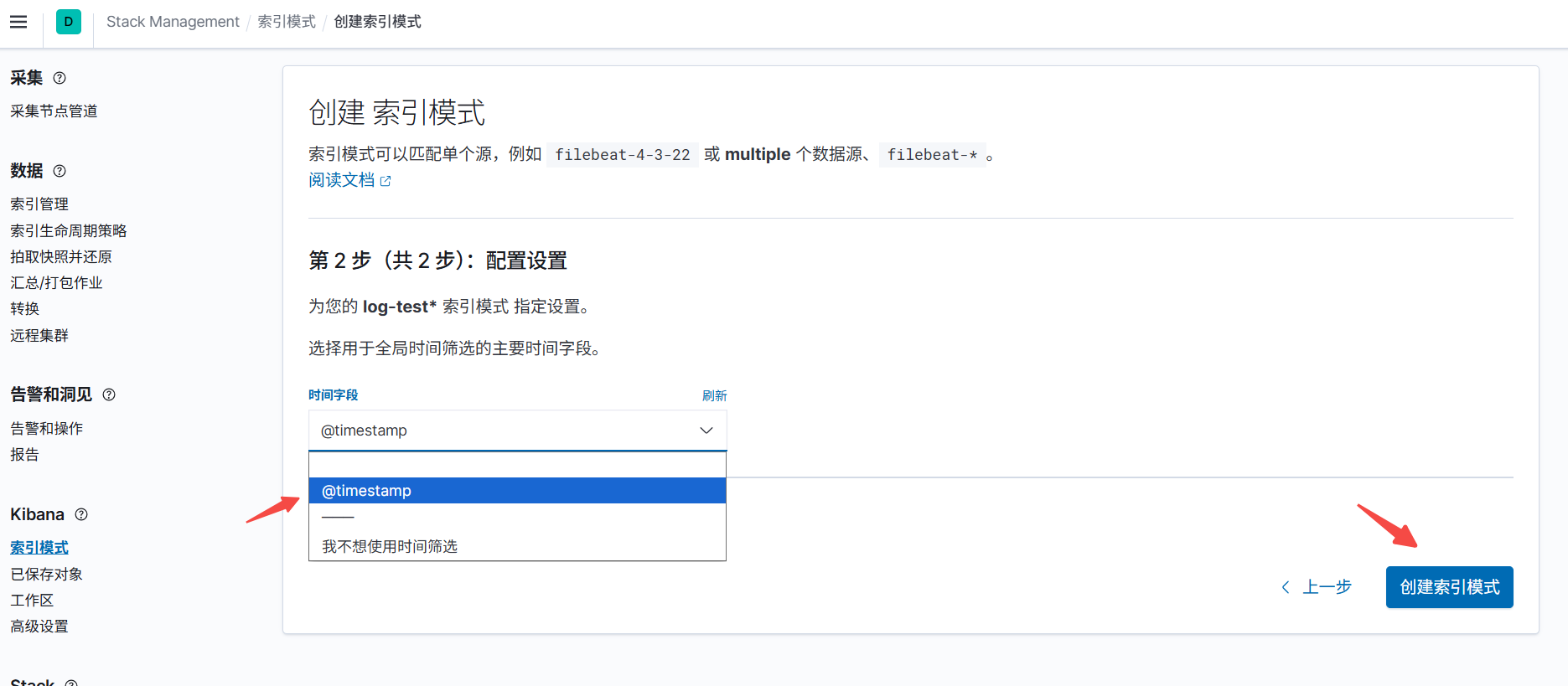
在这里就可以搜索日志了
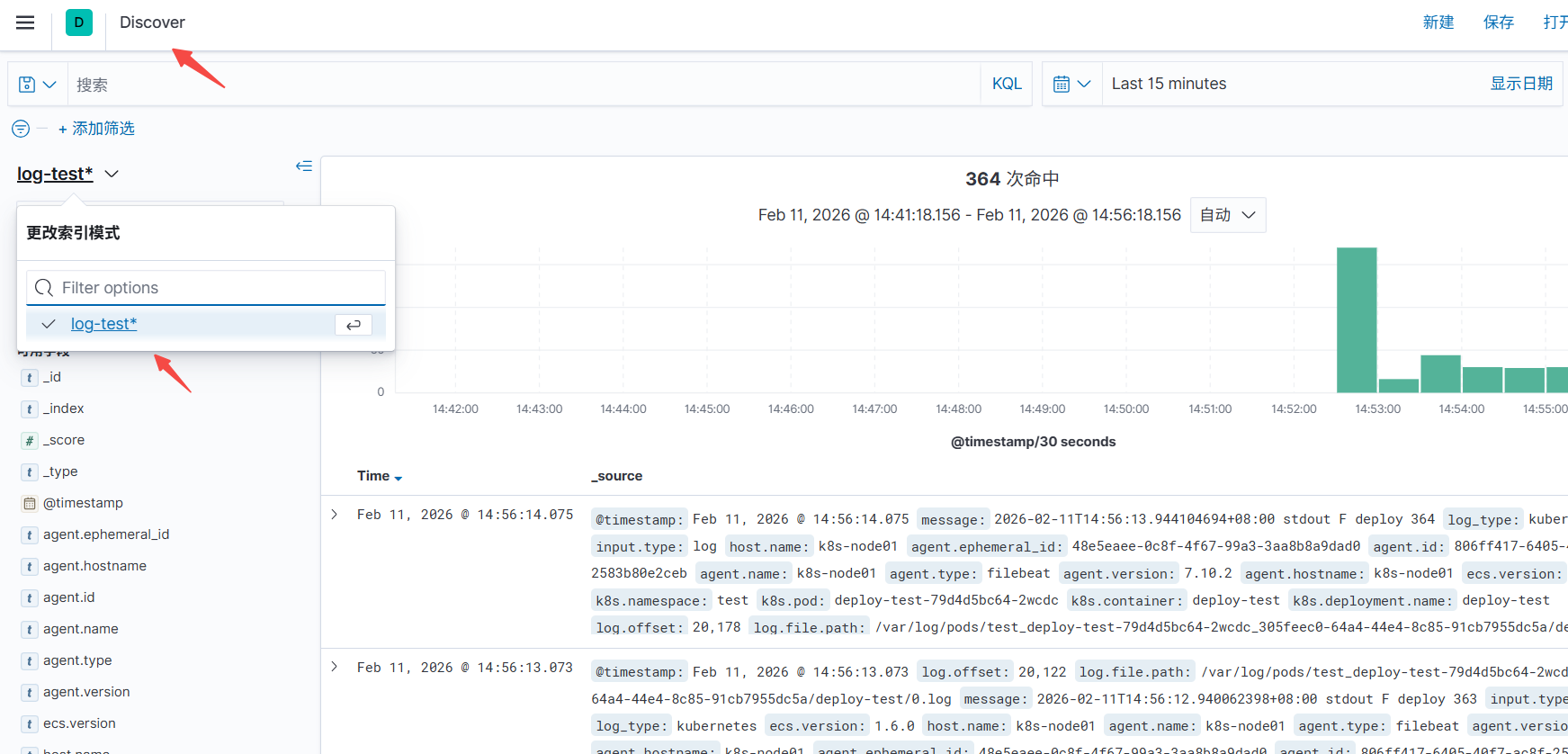
测试使用ILM
为了方便测试设置策略每秒检查一次
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s" // 1s秒检查一次
}
}
查看设置
GET _cluster/settings
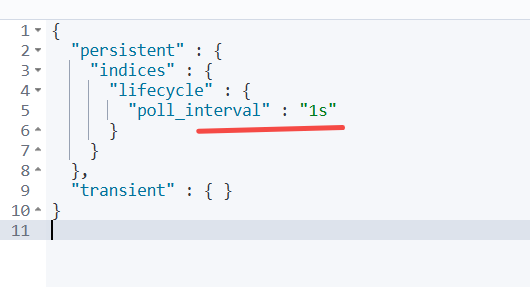
实现 索引过大自动轮询和定期删除
按时间排序升序 查看索引
GET _cat/shards?v=true&h=index,shard,prirep,store,node,&s=index:asc
默认只有下面这些索引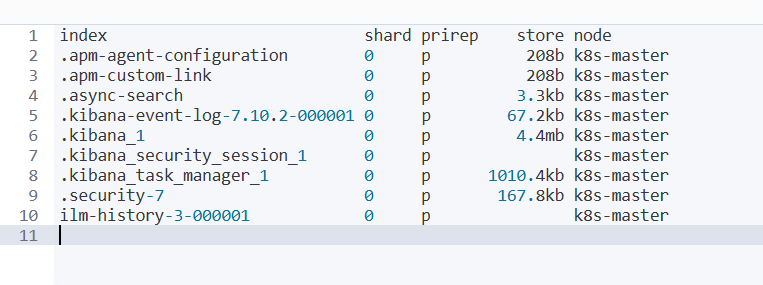
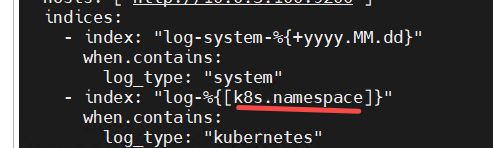
为了方便测试把这里改成下图
启动filebeat后 会自动增加下图两个 主要看索引 名称是 log-test 的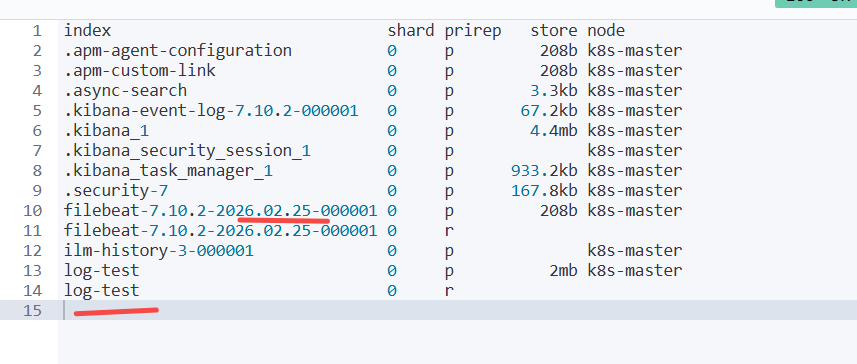
停止filebeat运行 手动删除 log-test 索引
创建 索引生命周期策略
索引大于5m就进行生成新的索引
索引存在1分钟后就开始删除
PUT _ilm/policy/logs_5mb_1m_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": { "max_size": "5mb" }
}
},
"delete": {
"min_age": "1m",
"actions": { "delete": {} }
}
}
}
}
查看创建的策略
GET /_ilm/policy/logs_5mb_1m_policy
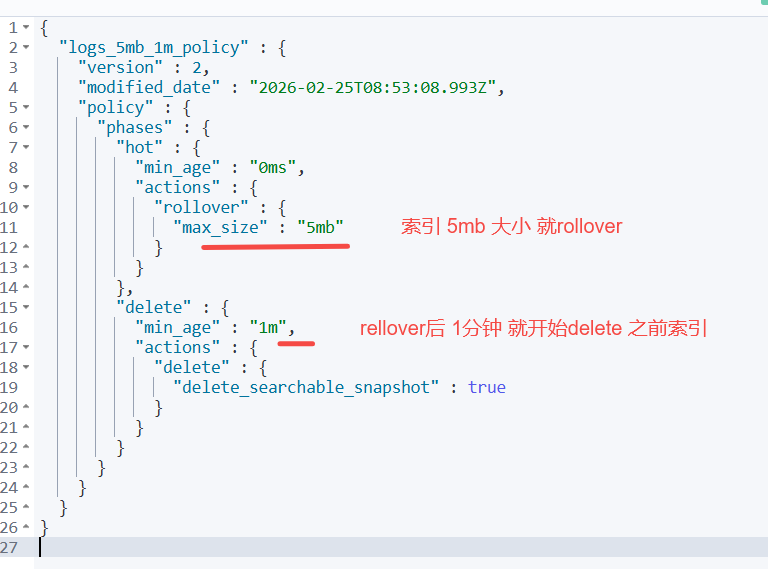
创建 索引模板
PUT _index_template/logs_5mb_1m_template
{
"index_patterns": ["log-test*"],
"template": {
"settings": {
"index.lifecycle.name": "logs_5mb_1m_policy",
"index.lifecycle.rollover_alias": "log-test"
}
}
}
查看 索引模板
GET _index_template/logs_5mb_1m_template

创建索引 绑定别名
PUT log-test-000001
{
"aliases": {
"log-test": {
"is_write_index": true
}
}
}
查看索引的静态配置
GET /log-test-000001/_settings

查看策略 运行情况
GET /log-test-000001/_ilm/explain
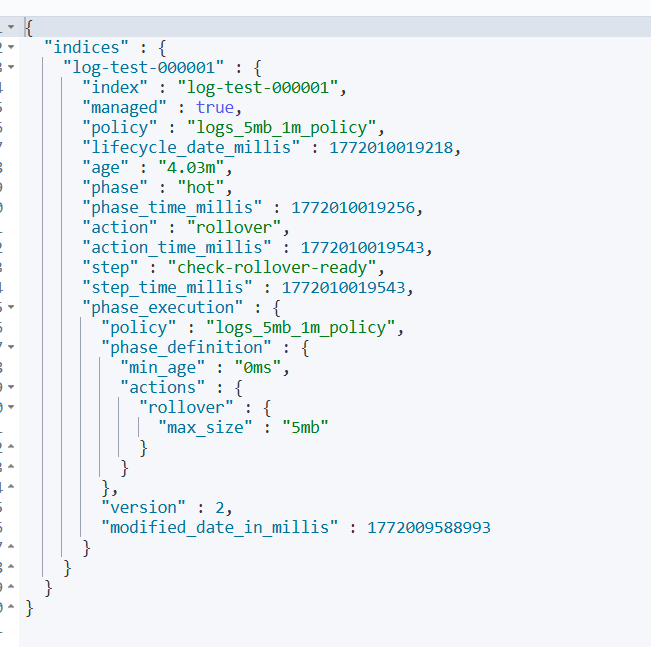
查看索引情况
按时间排序升序
GET _cat/shards?v=true&h=index,shard,prirep,store,node,&s=index:asc
看下图符合预期 5m 一个索引 之前的索引超过1 分钟 已经自动删除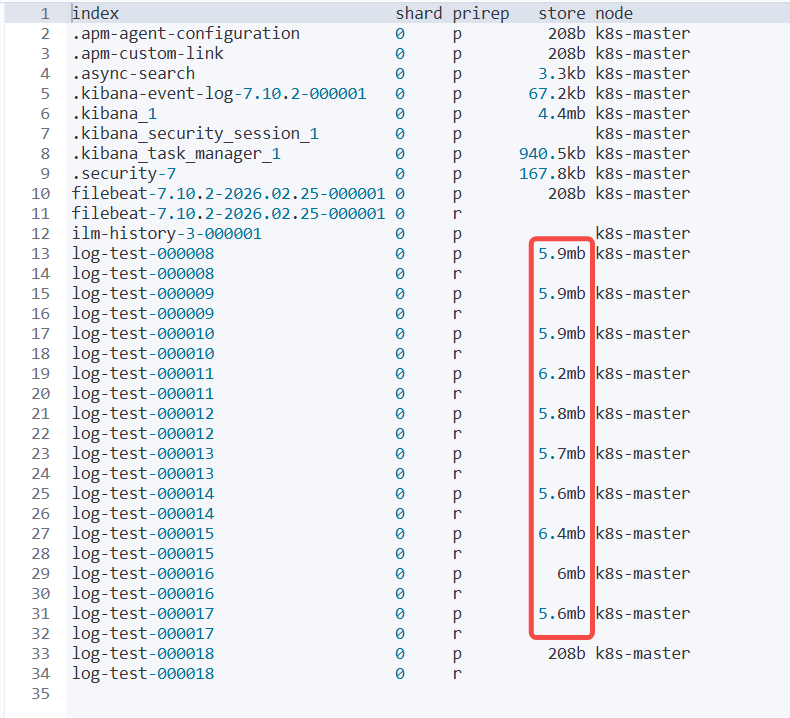
创建根据时间变化的索引 绑定别名
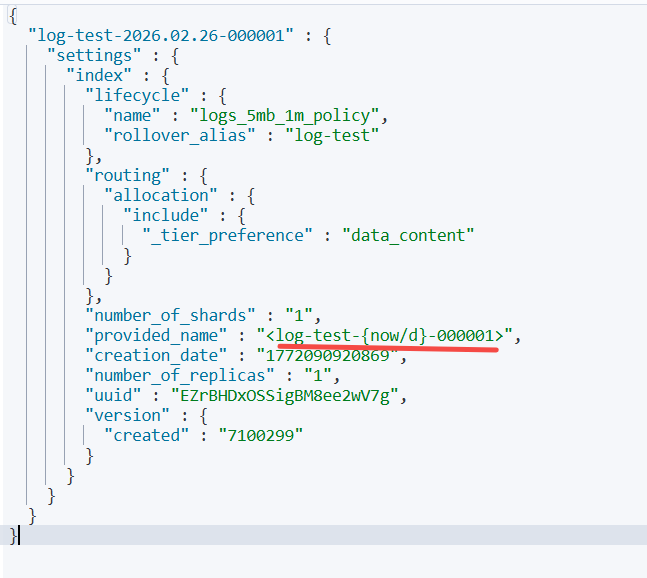
如下索引是<log-test-{now/d}-000001>的URL编码
其创建时默认会带上当天的时间
例如当天日期是“2026.02.26”
创建出来的索引名称是“log-test-2026.02.26-000001”。
PUT %3Clog-test-%7Bnow%2Fd%7D-000001%3E
{
"aliases": {
"log-test": {
"is_write_index": true
}
}
}
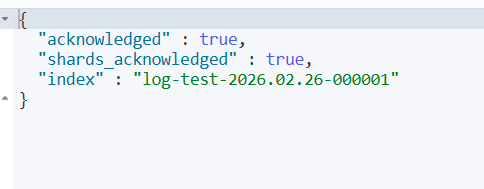
查看索引设置
GET log-test-2026.02.26-000001/_settings

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)