RAG 检索不准?全靠 Rerank 救场!RAG 优化实战教程(非常详细),大模型 RAG 从入门到精通,收藏这一篇就够了!
RAG系统中, 检索(retrieval)步骤完成之后, 可以从矢量数据库中根据相似性, 把相关的文档切片读取出来, 而文档切片的相关性排序, 对于最终的生成结果, 影响很大.
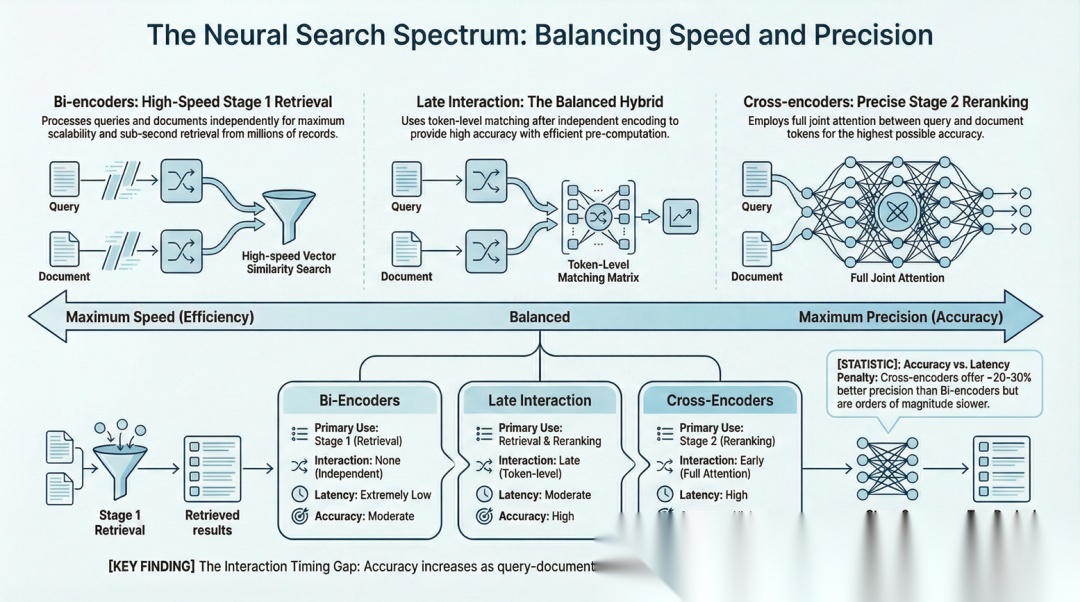
RAG系统中, 检索(retrieval)步骤完成之后, 可以从矢量数据库中根据相似性, 把相关的文档切片读取出来, 而文档切片的相关性排序, 对于最终的生成结果, 影响很大.
今天Chris就来扒一扒, 如果出现了检索文档排序不准确的问题, 应该如何解决?
Rerank
顾名思义, Rerank就是在检索之后, 对检索出来的结果, 再进行一次语义分析, 然后重新对文档进行重新的排序
Rerank的原理
Rerank的原理在于采用了不同的transformer模型架构: Cross-Encoder. 而普通检索阶段的模型架构叫做Bi-Encoder.
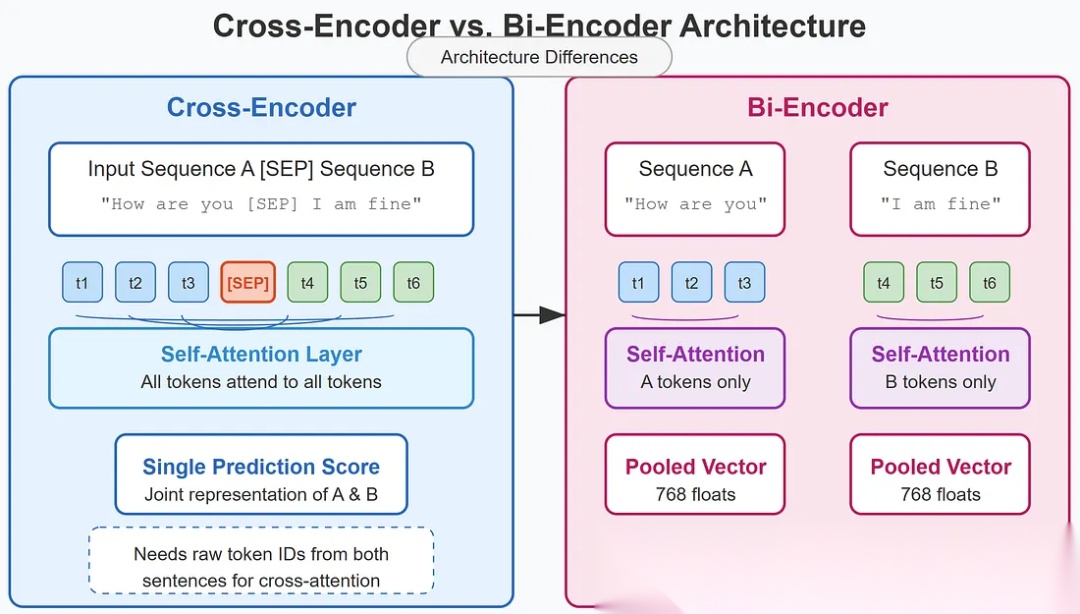
Bi-Encoder 会分别独立处理query和document, 把它们处理成相同维度的矢量. 对于document资料的矢量化处理, 发生在离线状态; 而对于query的矢量化, 发生在检索的过程中. 这样做, 检索的时候性能会非常好, 响应会很快.
相比而言, Cross-Encoder 会同时处理query和document, 彼此作为各自的context上下文, 一起传给transformer. 熟悉注意力(attention)机制的朋友, 一下就能明白此处的玄机了. 因为query 和 document 串接在一起, 作为一个整体去计算注意力权重, 那准确性自然要更高了!!! 当然这样做, 计算成本很高了, 所以不适合大规模的线上检索处理了!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)