【Paddle系列】利用PaddleDetection训练自己的目标检测模型
1 关于PaddleDetection
PaddleDetection是一个基于PaddlePaddle的目标检测端到端开发套件,在提供丰富的模型组件和测试基准的同时,注重端到端的产业落地应用,通过打造产业级特色模型|工具、建设产业应用范例等手段,帮助开发者实现数据准备、模型选型、模型训练、模型部署的全流程打通,快速进行落地应用。
1.1 训练流程

1.2 代码架构
为方便管理,推理模型统一放到inference文件夹下,数据集放到/train_data文件夹下,训练后的模型放到output文件夹。
detectionProject/
- inference/ # 存放推理模型
- output/ # 存放输出结果
- PaddleDetection/
- train_data/ # 训练数据
2 环境准备
本项目要求python3.8版本,且依赖库需严格遵循给定的版本(没有明确版本的除外)。
2.1 环境要求
- PaddlePaddle 2.3.2
- Python 3.8
2.2 安装
1、 在项目根目录拉取PaddleDetection代码
git clone https://github.com/paddlepaddle/PaddleDetection.git
2、 进入PaddleDetecion文件夹,释放分支
cd PaddleDetection
git checkout release/2.6
3、 先对requirements.txt文件进行修改,将sklearn修改为scikit-learn
-
改动前:

-
改动后:

4、 安装相关依赖库
- cpu版本
pip install -r requirements.txt
pip install paddlepaddle==2.3.2 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
pip install protobuf==3.20.2
pip install numpy==1.23.0
- gpu版本(以cuda11.2为例)
pip install -r requirements.txt
pip install paddlepaddle-gpu==2.3.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
pip install protobuf==3.20.2
pip install numpy==1.23.0
5、 验证是否安装成功
python ppdet/modeling/tests/test_architectures.py
输出以下内容即安装成功: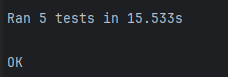
3 数据集准备
数据集的标注采用Labelme工具进行标注。Labelme是由麻省理工学院(MIT)计算机科学实验室开发的开源图像标注工具,擅长不规则物体标注,支持多边形、矩形、关键点、语义分割等标注类型,生成JSON文件可直接用于训练YOLO、Mask R-CNN等模型。
3.1 数据标注
1、 终端执行指令安装labelme
pip install labelme
2、 labelme启动,在Terminal启动指令
labelme
3、 弹出窗口后,打开图片目录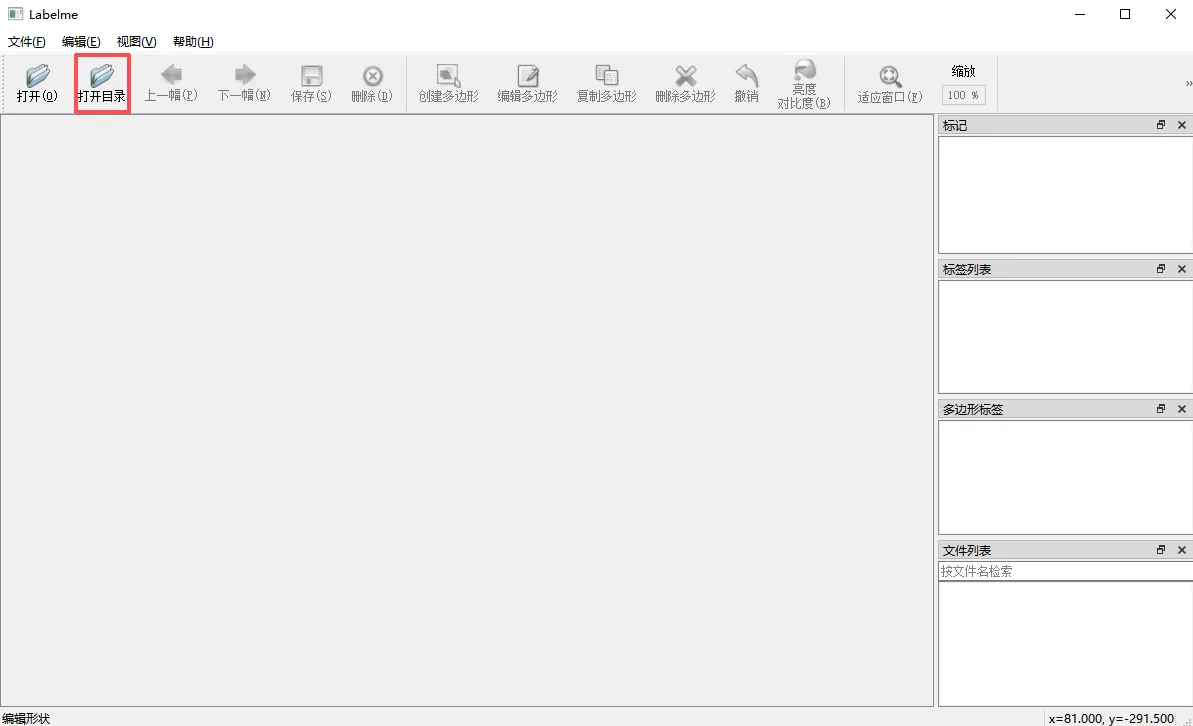
4、 点击【编辑】了,选择合适的形状进行框选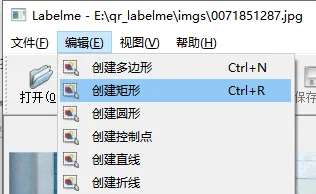
5、 框选完后给标签命名
6、 最后点击【保存】,软件自动将框选结果保存成json文件
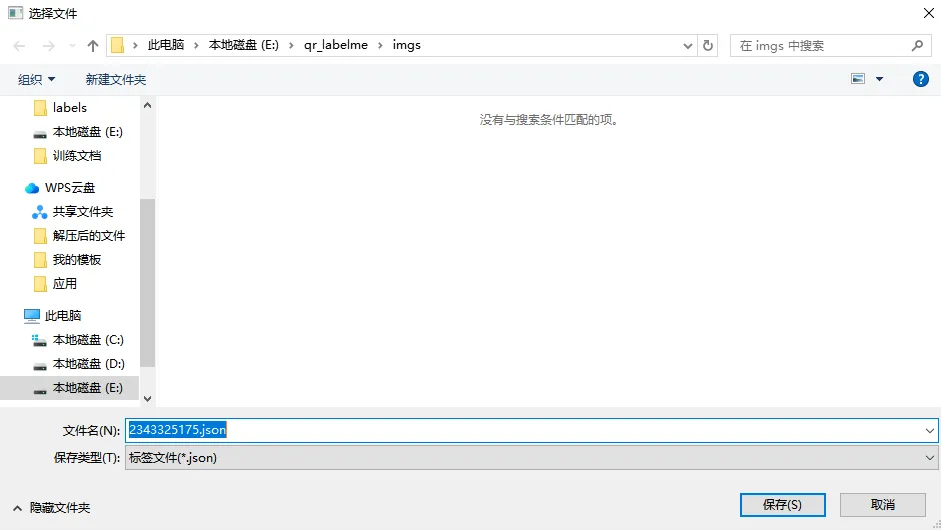
json文件会包含labelme版本号、标记名称、标注范围等信息。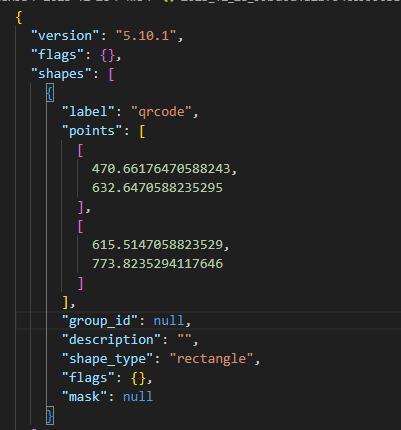
3.2 数据集转换
由于PaddleDetection使用的是PPYolo算法进行训练,需要将标注后的数据转换为coco格式或voc格式。此处仅介绍转coco格式。
在./tools/中提供了x2coco.py用于将voc格式数据集、labelme标注的数据集或cityscape数据集转换为COCO数据集。将整个数据集按照训练集、验证集、测试集进行划分,划分比例为7: 2: 1
python tools/x2coco.py \
--dataset_type labelme \
--json_input_dir "使用labelme标注的json文件所在文件夹" \
--image_input_dir "图像文件所在文件夹" \
--output_dir "转换后的coco格式数据集位置" \
--train_proportion 0.7 \
--val_proportion 0.2 \
--test_proportion 0.1
转换好后会生成四个文件夹,其中annotations存放标注文件,train、val、test分别存放训练集、验证集、测试集的图片。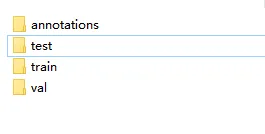
4 模型训练
4.1 预训练模型获取
在官方文档上下载预训练模型,下载之后在PaddleDetection根目录下建立Preliminary_training文件夹,将下载的模型解压至该文件夹。
PaddleDetection模型库:模型地址
4.2 微调训练
- 选择合适的模型,并找到对应的配置文件
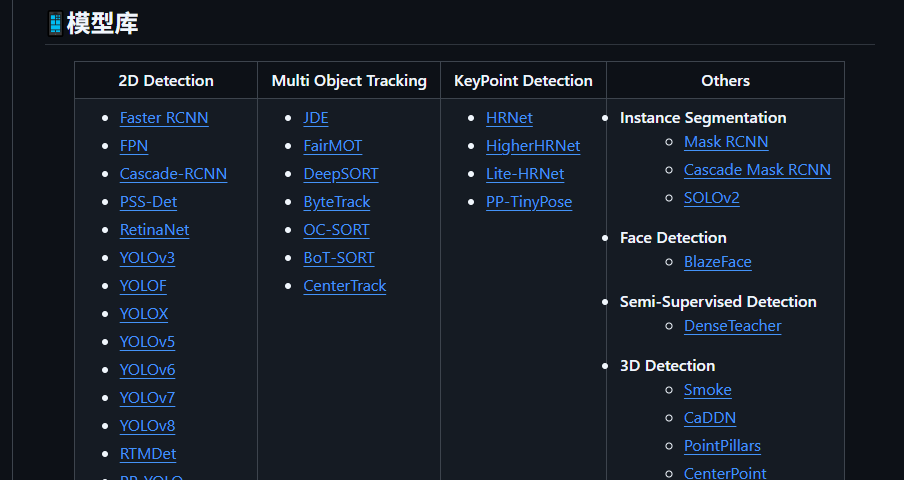
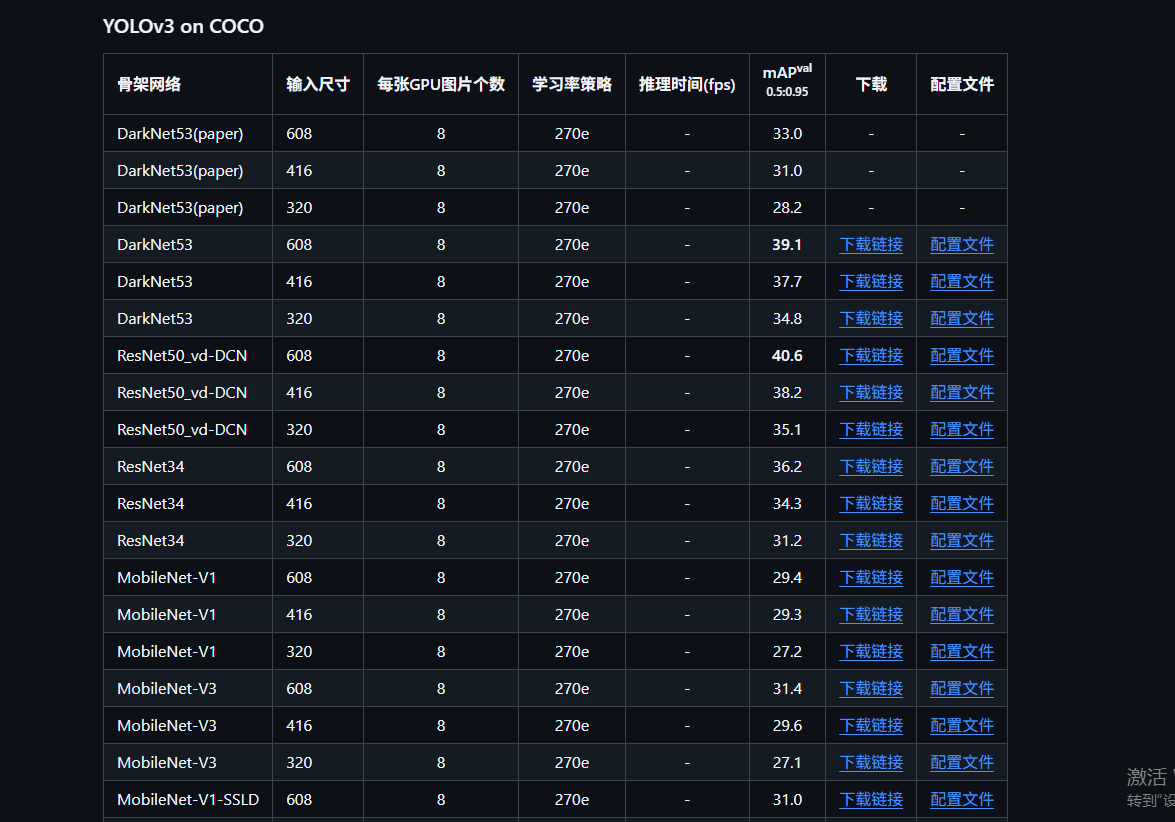
- 在PaddleDetection/configs找到对应的yml文件(或者把yml文件下载)
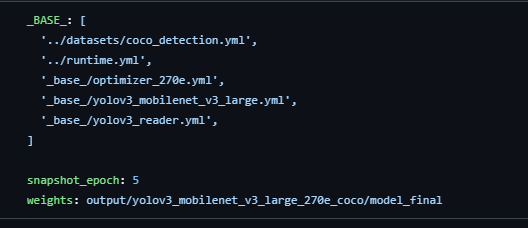
- 为方便修改参数,将_BASE__提到的yml文件的内容都复制到一个新的文件里
use_gpu: true # 是否使用gpu
epoch: 100 # 训练轮数
log_iter: 20 # 打印
save_dir: output # 保存路径
snapshot_epoch: 10
weights:
metric: COCO
num_classes: 1 # 图片标注的类别数
LearningRate:
base_lr: 0.01
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 243
- 324
- !LinearWarmup
start_factor: 0.
steps: 4000
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
architecture: YOLOv3
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/MobileNetV3_large_x1_0_ssld_pretrained.pdparams
norm_type: sync_bn
use_ema: true
ema_decay: 0.9998
YOLOv3:
backbone: MobileNetV3
neck: PPYOLOFPN
yolo_head: YOLOv3Head
post_process: BBoxPostProcess
MobileNetV3:
model_name: large
scale: 1.
with_extra_blocks: false
extra_block_filters: []
feature_maps: [13, 16]
PPYOLOFPN:
in_channels: [160, 368]
coord_conv: true
conv_block_num: 0
spp: true
drop_block: true
YOLOv3Head:
anchors: [[11, 18], [34, 47], [51, 126],
[115, 71], [120, 195], [254, 235]]
anchor_masks: [[3, 4, 5], [0, 1, 2]]
loss: YOLOv3Loss
YOLOv3Loss:
ignore_thresh: 0.5
downsample: [32, 16]
label_smooth: false
scale_x_y: 1.05
iou_loss: IouLoss
IouLoss:
loss_weight: 2.5
loss_square: true
BBoxPostProcess:
decode:
name: YOLOBox
conf_thresh: 0.005
downsample_ratio: 32
clip_bbox: true
scale_x_y: 1.05
nms:
name: MultiClassNMS
keep_top_k: 100
nms_threshold: 0.45
nms_top_k: 1000
score_threshold: 0.005
TrainDataset:
!COCODataSet
image_dir: train
anno_path: annotations/instances_train.json
dataset_dir: train_data # 数据集地址
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
image_dir: val
anno_path: annotations/instances_val.json
dataset_dir: train_data # 数据集地址
TestDataset:
!ImageFolder
image_dir: test
anno_path: annotations/instance_test.json
dataset_dir: train_data # 数据集地址
worker_num: 2
TrainReader:
inputs_def:
num_max_boxes: 50
sample_transforms:
- Decode: {}
- Mixup: {alpha: 1.5, beta: 1.5}
- RandomDistort: {}
- RandomExpand: {fill_value: [123.675, 116.28, 103.53]}
- RandomCrop: {}
- RandomFlip: {}
batch_transforms:
- BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeBox: {}
- PadBox: {num_max_boxes: 50}
- BboxXYXY2XYWH: {}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
- Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]}
batch_size: 24
shuffle: true
drop_last: true
mixup_epoch: 25000
use_shared_memory: true
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {target_size: [608, 608], keep_ratio: False, interp: 2}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
batch_size: 8
TestReader:
inputs_def:
image_shape: [3, 608, 608]
sample_transforms:
- Decode: {}
- Resize: {target_size: [608, 608], keep_ratio: False, interp: 2}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
batch_size: 1
根据显卡显存情况和模型泛化能力偏向,调整batch_size参数。
- 开始训练
在PaddleDetection目录下,输入指令开始训练
python tools/train.py -c "上面的配置文件路径" -o ...(临时修改的配置项,如use_gpu=False)
“-c"指的是训练的配置文件;”-o"代表替换配置文件的值,临时替换某些配置项。训练完成后save_dir路径下会出现以下文件:
output/
- *.pdopt
- *.pdparams
表示的是第几轮的模型。
- 模型评估
训练过程中可观察Loss值,Loss值下降缓慢说明训练效果几乎不变,可以认为训练完成。
python tools/eval.py -c "上面的配置文件路径" -o weights="训练后的权重模型地址"
# python tools/eval.py -c configs.yml -o weights=output/100.pdparams
此时的weights必须修改,不修改的话评估模型指向的还是原来的预训练模型。
- 测试模型识别效果
python tools/infer.py -c "上面的配置文件路径" \
--infer_dir=train_data/test
--output_dir=output/test
-o weights="要测试的模型参数" # 例如dataset/99.pdparams
- 转换成推理模型
python tools/export_model.py -c "上面修改的yml文件" -o weights="训练后的模型地址"
导出成功后,PaddleDetection/output_inference目录下会生成4个文件
output_inference/
- infer_cfg.yml
- model.pdiparams
- model.pdiparams.info
- model.pdmodel
- 测试推理模型的推理效果
python deploy/python/infer.py \
--model_dir="推理模型地址" \
--image_file="图片路径" \
--use_gpu=True
5 常见问题
1、训练报错
原因:ubuntu22.04会出现该报错,换一个版本

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)