R²AIN SUITE 智能园区服务管理平台——技术方案
园区数字化转型的困境与解决方案 当前园区数字化面临的核心问题是数据孤岛现象严重,60%的项目失败源于系统割裂而非技术问题。本文提出分层架构解决方案:从底层的智能硬件协议整合,到技术层的微服务与湖仓一体数据管理,再到应用层的业务流程数字化。特别强调AI落地的三个阶段——从基础数据分析到预测决策支持,再到生成式AI应用。方案采用务实策略,通过API集成现有系统而非强制替换,并建立统一身份认证体系。真正
一、背景:为什么园区数字化转型这么难落地
先说结论:大多数园区信息化项目死在"竖井"里。
典型的失败路径是这样的:物业公司上了一套物业系统,招商团队买了个CRM,能耗管理找了个做硬件的厂家捆绑了个App,安防系统更是独立王国,五套系统的账号密码都不一样。到了年底要出一张"园区运营报告",数据分析师要从五个系统里手工导出Excel,这和数字化转型的初衷背道而驰。
Gartner在2023年的报告里明确指出,大型基础设施的数字化项目中,超过60%的失败原因不是技术问题,而是数据孤岛和集成烂尾。这是个老生常谈的问题,但绝大多数园区至今没有解决。
R²AIN SUITE 的核心设计哲学是:先打通数据,再谈智能。这听起来很朴素,但真正把这件事做对,需要在架构上做很多反直觉的选择。
二、架构逻辑:从下往上,分层解耦
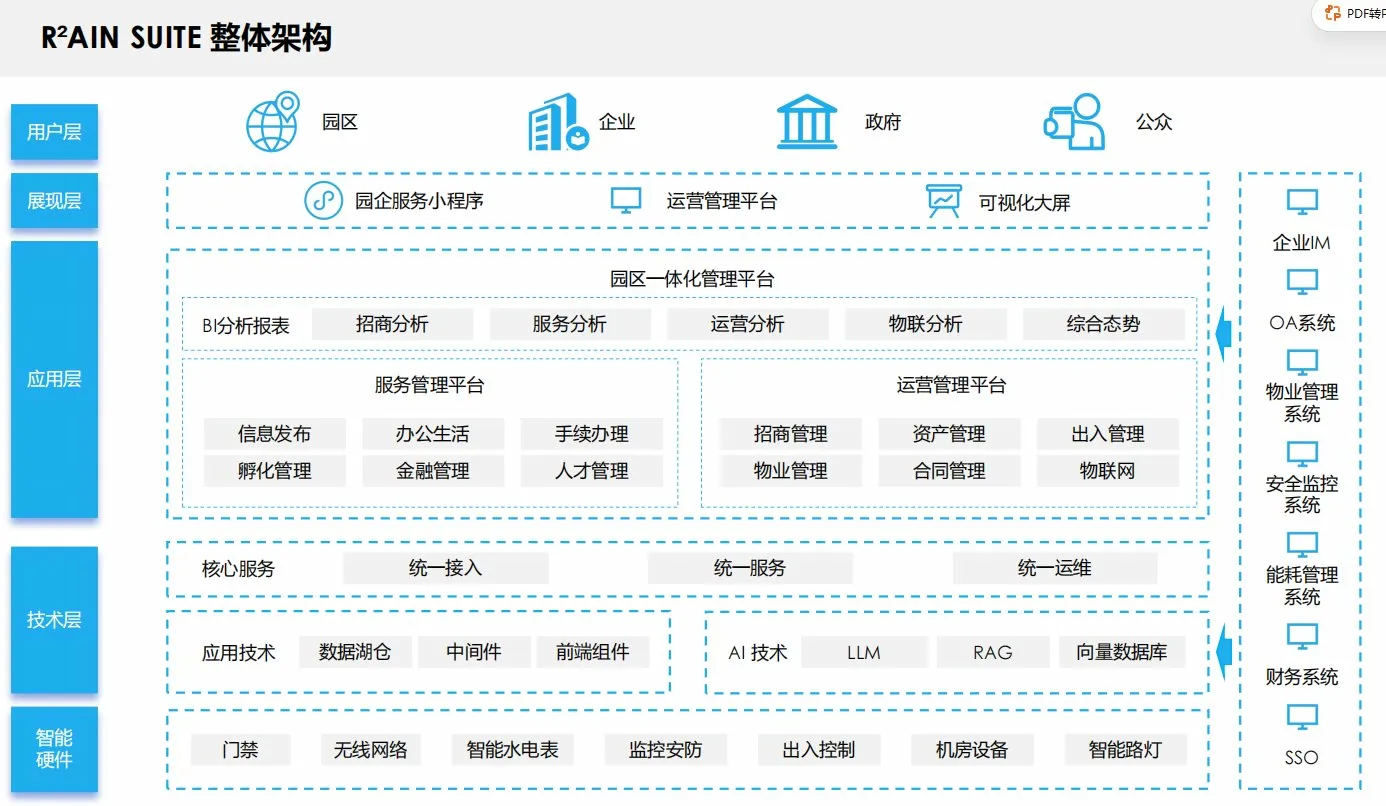
整个平台分为五层,但这不是普通的"分层架构图"装饰品——每一层都有非常明确的职责边界,层间通过标准接口通信,这才是架构图有价值的前提。
第一层:智能硬件层——物理世界的感知网络
门禁、水电表、摄像头、路灯控制器……这些是整个系统的"神经末梢"。这一层的核心挑战不是设备有多智能,而是协议碎片化。
现实情况是:某品牌门禁走Wiegand协议,某家水电表走Modbus,安防摄像头走ONVIF,楼宇自控走BACnet。一个中等规模的园区,硬件协议能有十几种。我们的做法是在边缘侧部署轻量级协议网关(基于EMQX或类似的工业IoT平台),在数据进入核心系统之前完成协议转换和数据规范化。这是关键的一步——让上层应用彻底不感知底层硬件差异。
边缘侧还承担一件重要的事:本地决策。比如门禁的刷脸识别,如果每次都要回到云端做推理,100ms的网络延迟会让用户觉得"慢",体验很差。所以人脸识别的推理模型必须部署在边缘设备本地,云端只负责模型更新和审计日志。这是典型的端云协同架构。
第二层:技术层——系统的底盘
这一层是整个平台的工程底座,外行不关注,但内行一眼就能看出水平。
核心服务采用微服务架构,服务网格用Istio做流量管理和可观测性,这不是追时髦,而是因为园区场景下各业务系统的更新节奏完全不同:招商系统可能一个月更新一次,能耗采集服务可能一天更新好几次,微服务架构才能让这两件事互不干扰。
数据层是全平台的核心资产,采用湖仓一体架构(Lakehouse)。结构化数据(租户合同、缴费记录)走关系型数据库;时序数据(传感器、能耗)走时序数据库,我们评估了InfluxDB和TDengine,后者在国内私有化部署场景有明显的运维优势;非结构化数据(监控视频、文档)走对象存储。
三类数据的统一查询入口是数据湖层,基于Apache Iceberg做表格式管理,支持跨源联邦查询。听起来复杂,但实际意义很直接:运营总监想看"过去三个月,每个楼层的能耗与入驻率的相关性",一条SQL就能出结果,不需要数据工程师手工拼数据。
AI技术栈是这次的重点,专门放一节来讲。
第三层:应用层——核心业务逻辑
招商管理、物业管理、资产管理、合同管理……这些是园区运营团队每天打交道的业务系统。这一层没有太多"高科技"可以炫耀,但有很多"工程细节"决定成败。
举一个例子:合同管理。传统做法是PDF扫描存档,续签靠人工提醒,漏单情况时有发生。我们的做法是:合同结构化入库(关键条款用NLP提取),到期预警自动触发工作流,续签谈判记录关联CRM,财务确认打通财务系统API。看似是"加了几个功能",但背后是把五个部门的线下协作流程整体数字化。这是真正困难的部分——不是技术难,是组织变革难。
第四层:展现层——触达用户的最后一公里
三个触达端:微信小程序面向园区企业员工,运营管理后台面向园区管理方,可视化大屏面向领导汇报和对外展示。
小程序技术栈选择微信原生框架,放弃跨端方案(如Taro/uni-app),理由很务实:园区用户群体微信使用率接近100%,跨端方案在性能和体验上的损耗在这个场景里不划算。推送通知走微信服务通知,比短信的打开率高3倍以上,这是有数据支撑的。
可视化大屏用AntV G2Plot做图表层,Three.js做园区3D楼宇模型,WebSocket实时推送传感器数据。大屏的设计原则是"决策者在30秒内能看懂",所以默认展示的只有三类信息:园区出租率、今日能耗对比和当前告警数量。其他所有数据都在二级钻取里。
三、AI落地:不是"加了个大模型"这么简单
这是整个方案里最需要认真讲的部分,也是最容易被说烂的部分。
园区场景的AI应用,我们把它分成三个成熟度级别:
Level 1:描述性分析(已经是标配) 把历史数据做成图表,“上个月能耗比上上个月增加了12%”。这个阶段的技术难点已经不是AI,是数据治理。没有干净的数据,AI什么都做不了。
Level 2:预测性决策支持(当前的主战场) 基于历史数据预测未来。典型应用:空调负荷预测(结合天气API和历史用电量,预测未来24小时各楼层制冷需求,提前调度,节能10-15%,这个数字在行业内有多个实测案例支撑);招商预测(基于企业工商数据、融资信息、行业热度,给出某类企业未来12个月是否会扩张搬迁的概率评分)。
这个级别不需要LLM,XGBoost加上好的特征工程就够了。
Level 3:生成式AI能力(正在探索落地的阶段) 这才是LLM、RAG、向量数据库在架构图里出现的理由。
最实际的落地场景是园区知识库问答。园区运营涉及大量文档:物业管理规定、消防规范、租约模板、政策补贴说明……传统做法是存在共享盘里,员工要靠人工查找,效率低且容易信息失真。
我们的方案是把所有文档向量化入库(用text-embedding-3系列模型),构建RAG系统。新来的物业客服员工问"B座公共区域的空调是否24小时开放",系统秒级检索相关文档片段,LLM基于原文生成准确答案,并附上文档出处链接。对比传统做法,客服培训周期从2周缩短到3天——这是真实可以衡量的ROI。
向量数据库的选型:我们评测了Pinecone(云端方案)、Milvus(自托管)和pgvector(PostgreSQL扩展)。对于大多数园区场景,数据量在千万级向量以下,pgvector在私有化部署场景下已经足够,不需要引入额外的基础设施复杂度。Milvus适合数据量更大、检索并发更高的头部园区运营商。
四、集成策略:对已有系统的态度
架构图右侧列出了七类集成系统:企业IM、OA、物业管理、安全监控、能耗管理、财务和SSO。
这里有一个根本性的判断要先做清楚:哪些系统要替换,哪些要集成。
大多数甲方已经有在用的OA系统(钉钉企业版、金蝶、用友等),这些系统动则数百万的采购成本,替换的阻力极大。我们的原则是:核心业务数据必须打通,系统界面层尽量保留。具体做法是通过开放API或Webhook机制做事件级别的数据同步,而不是粗暴地全量数据迁移。
SSO是集成体系的基础——所有系统用一套身份认证体系,用户不需要记多套密码。我们选择基于OIDC协议的SSO方案,兼容性最广,无论对接国产系统还是国际主流SaaS都没有障碍。
五、一句实话
市面上做智慧园区的方案很多,PPT层面几乎没有区别:都有物联网、都有大数据、都有AI。真正的差异在三个地方:数据治理的质量、业务流程的理解深度、交付团队的工程能力。一个架构图只能展示第一个维度,剩下两个要靠真实的交付案例和团队背景去验证。
这份方案给出的是技术逻辑框架,具体的技术选型(特别是数据库、AI推理平台、边缘硬件适配)需要结合甲方的现有IT资产、团队能力和预算约束做二次定制。没有哪个框架是放之四海而皆准的——凡是声称"开箱即用"的智慧园区方案,都值得认真追问一句:你们的数据治理是怎么做的?

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)