基于深度置信网络(DBN)的数据回归预测之旅
基于深度置信网络(DBN)的数据回归预测 多输入单输出 出图真实值与预测值对比图,DBN训练损失图 误差指标包括MAE、ME、RMSE、R2
在数据驱动的时代,精准的回归预测对于众多领域至关重要。今天咱就来聊聊基于深度置信网络(DBN)的多输入单输出数据回归预测,并且看看如何通过可视化真实值与预测值对比图、DBN训练损失图,以及借助误差指标MAE、ME、RMSE、R2来评估模型性能。
深度置信网络(DBN)基础
深度置信网络是一种生成式模型,由多个受限玻尔兹曼机(RBM)堆叠而成。它可以通过无监督学习预训练,为后续的监督学习提供良好的初始化,从而加快收敛速度并提高模型性能。简单理解,就像是先让模型自己摸索数据中的一些潜在模式,再根据这些经验去完成特定的预测任务。
多输入单输出回归预测的实现
咱们以Python和相关深度学习库来实现这个预测。假设使用Keras库来搭建DBN模型,首先导入必要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense数据准备环节,读取数据并划分特征和目标变量,这里假设数据存储在一个CSV文件中:
data = pd.read_csv('your_data.csv')
X = data.drop('target_variable', axis = 1)
y = data['target_variable']接着搭建简单的DBN模型,这里只是个示例结构,实际要根据数据调整:
model = Sequential()
model.add(Dense(64, activation='relu', input_dim = X.shape[1]))
model.add(Dense(32, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')上述代码中,Sequential模型按顺序堆叠各层。第一层输入维度是特征数量,这里设置了64个神经元且使用ReLU激活函数。后续层也用ReLU激活,最后输出层只有一个神经元,因为是单输出回归。编译时使用Adam优化器和均方误差(MSE)损失函数。
训练与评估
开始训练模型:
history = model.fit(X, y, epochs = 100, batch_size = 32, validation_split = 0.2)这里训练100个epoch,批量大小为32,并且拿出20%数据做验证。训练过程中会不断更新模型参数以最小化损失。

基于深度置信网络(DBN)的数据回归预测 多输入单输出 出图真实值与预测值对比图,DBN训练损失图 误差指标包括MAE、ME、RMSE、R2
训练完成后进行预测:
y_pred = model.predict(X)绘制真实值与预测值对比图
plt.scatter(y, y_pred)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.title('True vs Predicted Values')
plt.show()通过这个散点图可以直观看到真实值和预测值的分布情况,如果模型表现好,点应该大致分布在y = x这条直线附近。
绘制DBN训练损失图
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()从这个图能看出训练过程中损失的变化。训练损失和验证损失随着epoch增加而降低,理想情况是两者都平稳下降且差距不大,要是差距过大可能出现过拟合。
计算误差指标
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error, mean_squared_error, r2_score
mae = mean_absolute_error(y, y_pred)
me = mean_absolute_percentage_error(y, y_pred)
rmse = np.sqrt(mean_squared_error(y, y_pred))
r2 = r2_score(y, y_pred)
print(f'MAE: {mae}')
print(f'ME: {me}')
print(f'RMSE: {rmse}')
print(f'R2: {r2}')MAE衡量预测值与真实值绝对误差的平均值,越小越好。ME从百分比角度看误差,RMSE基于MSE计算,考虑了误差的平方,对大误差更敏感。R2评估模型对数据的拟合优度,越接近1表示模型拟合效果越好。
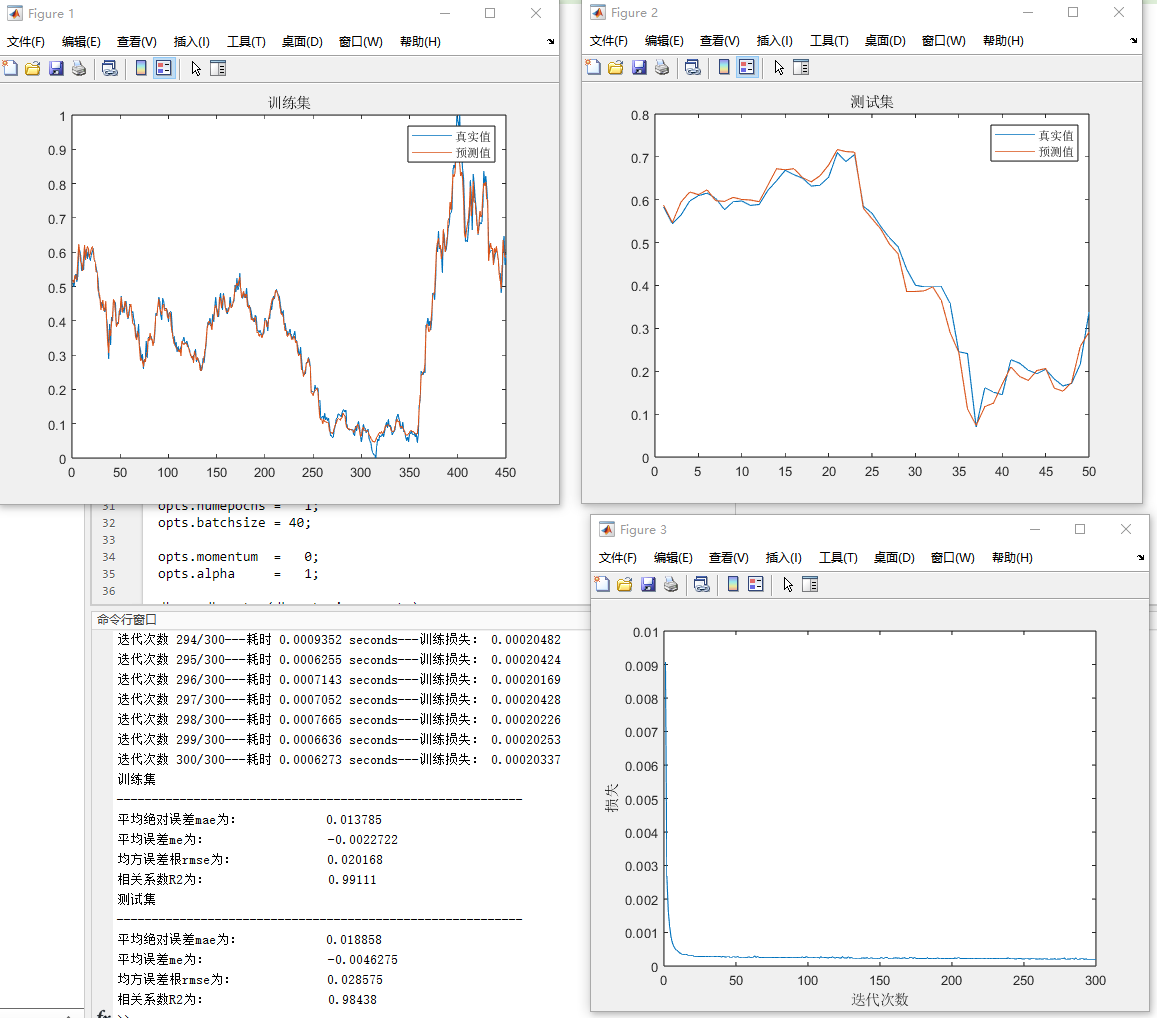
通过上述一系列操作,咱们就完成了基于DBN的多输入单输出数据回归预测,并且从多个角度对模型进行了评估和可视化,帮助我们更好地理解和优化模型性能。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)