【 SQL优化方法:将 IN 改为 UNNEST】
在字段没有索引情况下,优化器采用filter操作。Filter操作针对you_table表的每条记录,都要扫描一遍in结果集生成的整型数组。数组越大,效率越低。列表包含大量值,字段id没有索引的时候,查询计划可能变得低效,因为 PostgreSQL 需要逐个比较每个值。结合使用时,能够更高效地利用索引。这种方法减少了比较次数,优化器可以更好地生成执行计划。是一种更高效的替代方案,尤其适用于数组或列
·
SQL优化方法:将 IN 改为 UNNEST
数据库版本:KINGBASE V8R6
在 PostgreSQL 系列数据库中,使用 IN 子句处理大量数据时可能导致性能问题。UNNEST 是一种更高效的替代方案,尤其适用于数组或列表的查询优化,
使用 IN 子句的典型问题
SELECT * FROM test_table
WHERE id1 IN (1,2,3,...,1000);
当 IN 列表包含大量值,字段id没有索引的时候,查询计划可能变得低效,因为 PostgreSQL 需要逐个比较每个值
使用 UNNEST 优化查询
将 IN 替换为 UNNEST 可以显著提升性能,尤其是处理数组或列表时:
SELECT * FROM test_table
WHERE id1 IN (1,2,3,...,1000);
性能优势
UNNEST 将数组展开为行,与 = ANY 结合使用时,能够更高效地利用索引。这种方法减少了比较次数,优化器可以更好地生成执行计划。
实际应用示例
假设需要查询 ID 在特定列表中的记录:
-- 原始 IN 查询
SELECT * FROM test_table
WHERE id1 IN (1,2,3,...,1000);
-- 优化后的 UNNEST 查询
SELECT * FROM test_table
WHERE id1 = ANY(UNNEST(ARRAY[1,2,3,...,1000]));
实际测试过程:
CREATE TEMP TABLE temp_ids(id integer);
INSERT INTO temp_ids VALUES (1),(2),...,(1000);
SELECT t.* FROM test_table t JOIN temp_ids ti ON t.id1 = ti.id;
优化前SQL及执行计划
在字段没有索引情况下,优化器采用filter操作。Filter操作针对you_table表的每条记录,都要扫描一遍in结果集生成的整型数组。数组越大,效率越低。
可以看到如下对比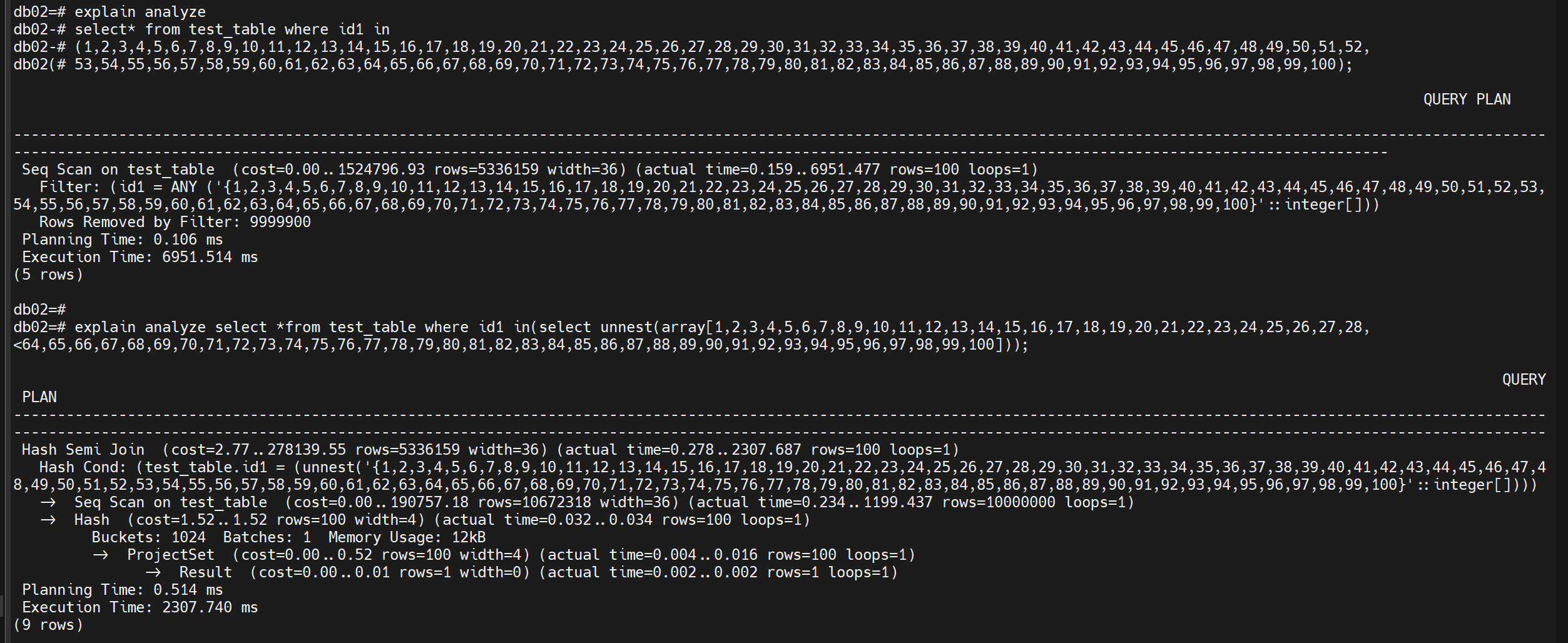
注意事项
- 确保
UNNEST使用的列上有适当的索引。 - 对于非常小的列表,
IN和UNNEST的性能差异可能不明显。 - 测试不同场景下的查询性能,选择最适合的方案。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)