[QA】生成测试用例skill
Agent Skills是一种标准化的 AI 能力封装格式。类似于 IDE 的插件或操作系统的应用,Skill 为 AI Agent(如 Cursor Copilot)提供了特定的领域知识、工具集和工作流。为什么我们需要 Skills?传统的 Prompt 工程往往分散在个人文档中,难以复用和协作。Skills 体系带来了以下核心价值:标准化 (Standardization):统一的目录结构 (
我们知道 AI 的到来,给我们带来了很多的挑战,但也带来了很多便利与机遇。作为测试人员,测试用例的编写很费时间,这个分析和生成的工作可以完全交给 AI。
最近我们也从 Prompt 生成用例变更到了用 skill的方式去完成这件事:
1. 什么是 Agent Skills?
Agent Skills是一种标准化的 AI 能力封装格式。类似于 IDE 的插件或操作系统的应用,Skill 为 AI Agent(如 Cursor Copilot)提供了特定的领域知识、工具集和工作流。
为什么我们需要 Skills?
传统的 Prompt 工程往往分散在个人文档中,难以复用和协作。Skills 体系带来了以下核心价值:
标准化 (Standardization):统一的目录结构 (`SKILL.md`, `README.md`, `scripts/`),便于团队理解和维护。
可移植性 (Portability):一次编写,处处运行。Skills 可以在不同的 Agent 环境(Cursor, Claude, OpenSkills CLI)中加载。
上下文隔离 (Context Isolation):按需加载,避免污染全局上下文窗口(Context Window)。
能力编排 (Orchestration):不仅仅是对话,Skill 可以包含复杂的 Python/Shell 脚本、API 调用(如 `alpha-knowledge`)和多步推理逻辑。
我们之前是利用公司的Smart平台提供的模型,然后自己编写 prompt。平台提供知识库,这种方式来生成测试用例。最后作为一个 agent 接入聊天机器人,比如企业微信。
但这种方式一个最大的弊端,很慢,消耗的是公司模型的 token。存在排队情况。
2. 从 Custom Agent 到 Skills 的迁移案例
> 核心案例:`@skills/test-case-design/`
我们将原本定制化的 Agent 迁移为通用的 Skills,目的是脱离单一内部平台的限制,实现更强的拓展性和灵活性。
以 测试用例生成 (test-case-design) 为例,展示迁移前后的变化:
### 迁移前 (Custom Agent)
依赖特定的 Web 界面或硬编码的 Prompt。
Smart平台可选模型较少且基本都收费,Smart平台的Budget经常超出限额。
输出格式不稳定,往往需要人工二次调整格式才能落库。
迁移后 (Agent Skill)
`test-case-design` 被重构为一个包含完整生命周期的 Skill:
1. 结构化定义 (`SKILL.md`):
定义了清晰的输入源规范(Confluence, Google Docs, Local Files)。
设定了“硬约束”规则(如:禁止假设缺失信息,必须列出 Information Gap)。
2. 精确的参考标准 (`REFERENCE.md`):
将具体的字段枚举、优先级定义、冲突处理策略从 Prompt 中抽离,作为 Reference 文档,降低 Token 消耗并提高准确率。
3. 自动化落地 (`scripts/`):
包含 `generate_excel.py` 脚本。AI 不仅生成文本,还直接调用脚本生成符合团队标准的 `.xlsx` 文件,实现“所见即所得”。
### 迁移后的核心收益
除了工程化结构的改进,迁移到 Cursor Skills 还带来了直接的使用体验提升:
1. 更加稳定 (More Stable)
彻底解决 Excel 生成失败: 解决之前通过 MCP Tool 生成 Excel 后链接无法访问的问题。通过 Python 脚本 (`generate_excel.py`) 本地执行,确保生成的 Excel 文件 100% 可用且格式完美。
摆脱 Budget 限制: 不再受限于 Smart 平台的项目预算配额。
2. 更加灵活 (More Flexible)
模型自主选择: 使用者可以根据任务难度自行选择模型(如 Claude 4.5 Sonnet/gemini-3-pro/gpt-5.2),不再被平台强制绑定。
3. 更加直观 (More Intuitive)
白盒化工作流: Agent 的每一次思考、搜索、文件读取和脚本执行过程都在 IDE 对话框中实时可见。不再是黑盒等待,使用者可以随时干预或基于中间结果进行追问。
架构图
用户请求↓
Cursor AI Model (Claude/GPT/Gemini)↓
读取 test-case-design/SKILL.md (操作手册)↓
按照 SKILL.md 的指令执行工作流
├── 1. 解析用户输入
├── 2. 获取文档(Confluence/Google Docs)
├── 3. 调用 Alpha Knowledge(咨询专家)(这一步是公司搭建的知识库平台)
├── 4. 融合信息生成分析报告
├── 5. 等待用户确认
├── 6. 生成 JSON 格式测试用例
└── 7. 调用 generate_excel.py 生成 Excel↓
输出:Excel 文件 + 总结报告
3. 相关配置
1.我们使用 [`openskills`](https://github.com/numman-ali/openskills) 命令行工具来管理 Skills 生命周期。
#### 1. 安装 openskills
```bash
npm i -g openskills
```
#### 2. 安装/下载 Skills
将远程仓库的 Skills 下载到本地使用:
```bash
# 安装 qa-agent-skills 仓库中的所有 Skills(--global 安装到全局)
openskills install gitlab@git.garena.com:xxxxxxxx/qa-agent-skills.git --global
```
```bash
# 同步到本地,完成后可在 Cursor 中通过 Skill 名称直接触发
openskills sync
2.mcp 配置:
因为我们TD 和 PRD 都是放在 confluence 上,Skills 经常需要结合外部工具(如读取在线文档、查询设计稿)使用。所以需要配置 conflence mcp,采用的json 格式:
"mcp-atlassian": {
"command": "uvx",
"args": [
"mcp-atlassian"
],
"env": {
"ENABLED_TOOLS": "confluence_search,confluence_get_page,confluence_get_comments,jira_search,jira_get_issue",
"CONFLUENCE_URL": "https://confluence.shopee.io",
"CONFLUENCE_USERNAME": "your.email@shopee.com",
"CONFLUENCE_SSL_VERIFY": "false",
"CONFLUENCE_PERSONAL_TOKEN": "YOUR_CONFLUENCE_PAT_HERE",
"JIRA_URL": "https://jira.shopee.io",
"JIRA_USERNAME": "your.email@shopee.com",
"JIRA_SSL_VERIFY": "false",
"JIRA_PERSONAL_TOKEN": "YOUR_JIRA_PAT_HERE"
}
}
4. 案例演示
我们在 cursor 端采用引用的方式执行:在对话框中输入/,之后就可以看到skills下出现了excel-test-case-generator。
拿我们的一个项目演示
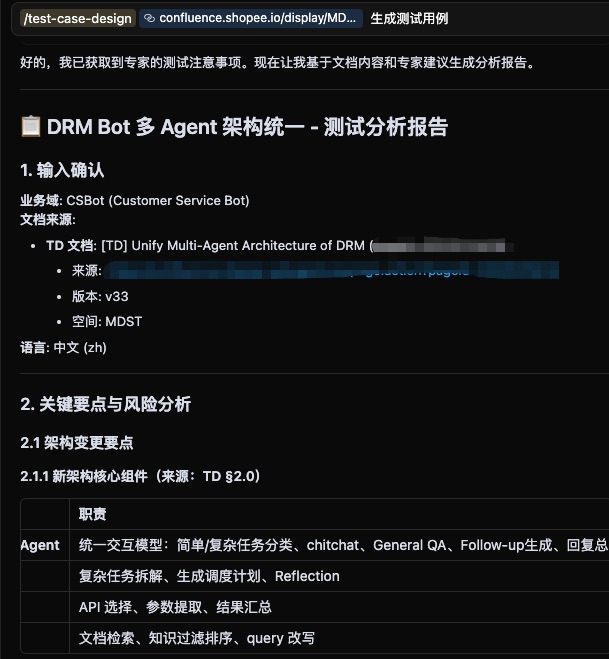
会先做分析,这也是遵守skill.md的"硬闸门“规则
然后输出确认信息:

可以选择继续或者补充信息:
如果确认后:
会进入第二阶段:生产阶段。
中间会调用我们生成用例的工具脚本,比如Excel 生成由 generate_excel.py 脚本完成等,

5. SKILL.md 详解
第一部分:YAML Frontmatter(元数据)
name: test-case-design
description: 测试用例生成引擎,支持多输入源(Confluence/Google Docs/URL/本地文本/GitLab MR),融合业务专家咨询生成可追溯测试用例并落盘 Excel。用于测试用例生成、测试设计、PRD/TD 分析、多文档融合。
作用: 告诉 Cursor AI 何时触发这个 Skill。
第二部分:目标定义
## 目标:执行完整的测试分析与用例生成流程:从**多源文档分析**,到**专家知识融合**与**用户交互确认**,最终生成符合规范的**可追溯测试用例**并落盘 Excel。
关键词解析:
- 多源文档分析: 支持 Confluence、Google Docs、本地文件等
- 专家知识融合: 必须调用 Alpha Knowledge 咨询专家
- 用户交互确认: 两阶段流程,中间有确认环节
- 可追溯测试用例: 每条用例必须标注来源
- 落盘 Excel: 最终输出为 Excel 文件
第三部分:输入定义
## 输入
- **必需**:
- `business_domain`(业务域)
- `inputs`(推荐,多输入源)
- **可选**:
- `mr_links`: GitLab MR 链接列表(最多 3 个,仅限 git.garena.com 域名)
- `link` / `links` / `local_files` / `doc_texts`(兼容旧字段)
- `language`: `zh`(默认)/ `en`
- `user_supplement`: 用户补充信息(交互阶段使用)
> **智能解析支持**:若用户提供非结构化输入(如文本描述链接和业务域),**必须**按照 `REFERENCE.md` 中的"非结构化输入解析"规则先转换为标准 `inputs` 结构。
第四部分:完整工作流程(核心)
这是整个 SKILL.md 的最核心部分,定义了 AI Agent 必须遵循的执行流程。
阶段1: 分析阶段 (Analysis)
步骤1: 输入解析
用户输入: "为 xxxx 生成测试用例,PRD: https://..."
↓
AI Agent 解析:
business_domain: ItemQC
inputs:
- type: confluence
name: PRD
value: https://...
步骤2: 多源获取
inputs 列表:
- Confluence 文档
- Google Docs 文档
- 本地文件
- 直接文本
↓
AI Agent 逐个获取:
├── 调用 mcp-atlassian → confluence_get_page
├── 调用 gas_tools → url-to-markdown
├── 读取本地文件
└── 解析直接文本
↓
获取所有文档内容
步骤3: 专家咨询(MANDATORY - 必须执行)
固定问题(启动即问):
# 问题1
python3 skills/alpha-knowledge/scripts/kb_chat.py \
--expert-id "xxx" \
--api-key "gE2nT..." \
-q "列举 xxxxx 业务的测试注意事项" \
--json
# 问题2
python3 skills/alpha-knowledge/scripts/xxxxx.py \
--expert-id "xxxx" \
--api-key "gE2nT..." \
-q "列举 xxxxxx 的关键业务规则" \
--json
缺口补充(动态咨询):
分析 PRD 文档后发现:
- 审核失败后的重试逻辑不清楚
- 批量处理的上限未说明
↓
针对性咨询:
- "描述 ItemQC 审核失败后的重试机制"
- "ItemQC 批量处理的上限是多少?"
步骤4: 融合输出(生成分析报告)
分析报告结构:
# 测试分析报告
## 1. 输入确认
- 业务域: ItemQC
- 输入源: PRD (Confluence), TD (Google Docs)
## 2. 关键要点
- 审核流程包含初审、复审、终审(来源:PRD §3.2)
- 批量处理上限为 100 个/批次(来源:ExpertQA-#3)
- 审核失败后允许重试 1 次(来源:ExpertQA-#4)
## 3. 信息缺口/待澄清
- ❓ 复审失败后是否需要人工介入?
- ❓ 批量处理的超时时间是多少?
## 4. 风险与建议的测试范围
- P0: 审核流程完整性、状态流转
- P1: 批量处理性能、重试机制
步骤5: STOP & ASK(硬闸门)
这是最关键的约束!
分析报告末尾必须包含:
---
## 待办事项
请您确认以下内容:
A) 确认,继续生成
B) 补充信息如下:...
提示:您也可以在此处补充最多 3 个 GitLab MR 链接
---
硬约束:
在收到用户明确回复前:
❌ 严禁进入生成阶段
❌ 严禁生成 output/test_cases.json
❌ 严禁生成 Excel 文件
为什么需要硬闸门?
- 防止盲目生成: 确保分析报告准确
- 用户参与: 让用户有机会补充信息
- 质量保证: 避免基于错误理解生成用例
- 灵活性: 用户可以补充 MR 链接
阶段2: 生成阶段 (Generation)
步骤1: MR 变更分析(可选)
用户补充: "MR 链接: https://git.garena.com/shopee/itemqc/-/merge_requests/123"
↓
AI Agent 提取:
Project ID: shopee/itemqc
MR IID: 123
↓
调用 gitlab-tool:
python3 skills/gitlab-tool/scripts/get_mr_changes.py \
--project "shopee/itemqc" \
--mr-iid "123"
↓
获取代码变更:
- 修改了 audit.go 的重试逻辑
- 新增了批量处理的限流
↓
分析受影响的业务逻辑:
- 重试机制的边界条件
- 批量处理的性能
↓
增强用例覆盖:
- 新增用例: "验证重试次数限制"
- 新增用例: "验证批量处理限流"
- 备注标注: "来源:MR !123 (Changes Analysis)"
步骤2: 前置检查
检查用户是否已确认:
✅ 用户回复 "确认,继续生成"
或
✅ 用户提供了补充信息
↓
继续执行
步骤3: 设计规范执行
读取 REFERENCE.md:
- 覆盖度要求(正向、负向、边界值)
- 业务域特点(End-to-End vs Service Interface)
- 优先级定义(P0/P1/P2/P3)
↓
应用设计规范:
├── 正向用例: 核心功能验证
├── 负向用例: 异常处理验证
└── 边界用例: 最小/最大/空/零/负值
↓
生成测试用例
实际执行示例(刚才的任务):
业务域: CSBot
文档: TD - Unify Multi-Agent Architecture
应用设计规范:
├── Communication Agent
│ ├── 正向: 验证 General QA 的识别与回答
│ ├── 负向: 验证 Unclear query 的处理
│ └── 边界: 验证空输入、超长输入的处理
├── Planning Agent
│ ├── 正向: 验证简单任务的 Plan 生成
│ ├── 负向: 验证 Reflection 达到最大轮次
│ └── 边界: 验证信息不足时的收敛
└── API Call Agent
├── 正向: 验证 API 选择的准确性
├── 负向: 验证工具调用失败的处理
└── 边界: 验证时间参数的各种情况
步骤4: 自我评估
生成用例后,AI Agent 自检:
├── 优先级检查: P0 是否涵盖最高风险点?
├── 术语一致性: 是否保留原始术语?
├── 无假设: 是否混入了未经验证的假设?
├── 覆盖度: 是否覆盖正向、负向、边界?
└── 可追溯性: 每条用例是否标注来源?
↓
如果发现问题,修正后再输出
步骤5: 落盘
生成 JSON:
output/test_cases.json
↓
调用脚本生成 Excel:
python3 skills/test-case-design/scripts/generate_excel.py \
--input output/test_cases.json \
--business-domain "CSBot" \
--feature-name "multi-agent-architecture-unify"
↓
生成 Excel:
output/CSBot_multi-agent-architecture-unify.xlsx
步骤6: 总结输出
# 任务完成总结
## 1. 交付物
- Excel 文件: output/CSBot_multi-agent-architecture-unify.xlsx
- 原始 JSON: output/test_cases.json
## 2. 用例统计
- 总数: 67 条
- P0: 22 条, P1: 32 条, P2: 10 条, P3: 3 条
## 3. Alpha Knowledge 咨询回顾
| 问题 | 状态 | 关键补充点 |
|------|------|-----------|
| 测试注意事项 | ✅ 已融合 | 补充了13个测试注意事项 |
| 关键业务规则 | ⚠️ 无有效信息 | 已基于 TD 文档提取 |
第五部分:必须遵守的规则(硬约束)
- **禁止假设**:缺失信息必须列入"信息缺口/待澄清",不得编造补齐。
- **专家咨询是必须的**:不得跳过对专家的咨询,尤其是"固定问题"和对模糊点的澄清。
- **术语一致性**:严格保留 PRD/TD 原始术语(服务名/接口名/字段名/错误码)。
- **来源可追溯**:关键要点必须标注来源(文档章节或专家 QA-ID)。
- **多源融合**:必须显式体现专家咨询带来的业务规则补充。
第六部分:输出定义
- **Markdown 分析报告**(阶段 1):供用户审阅确认。
- **JSON 数据文件**(阶段 2):`output/test_cases.json`(必须符合 JSON Schema)。
- **Excel 文件**(阶段 2):
- Sheet:`TestCases`
- 默认落盘:运行 `scripts/generate_excel.py`。
- **Markdown 总结报告**(阶段 2):包含 P0/P1/P2/P3 统计与 Alpha Knowledge QA 回顾。
第七部分:参考文档
- 详细规范与工作流:`REFERENCE.md`
- 专家配置:`expert-config.md`
- 最小示例:`EXAMPLES.md`

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)