多模态大模型有哪些模态?
多模态”中的“模态”(modality),即指各类数据形式或信息来源。涵盖自然语言文本、经语音识别转换的文本内容等。指视觉图像数据,例如照片、插画、艺术作品等。包含动态影像序列,如短视频、影视片段、监控录像等。指声学信号数据,如人声、音乐、环境音效等。还包括如环境传感器读数、生理信号、指纹、虹膜等非传统信息形式。多模态模型的核心目标,在于融合上述异构模态的信息,以增强模型对输入数据的语义理解、任务
“多模态”中的“模态”(modality),即指各类数据形式或信息来源。在多模态大模型中,典型模态涵盖以下类别:
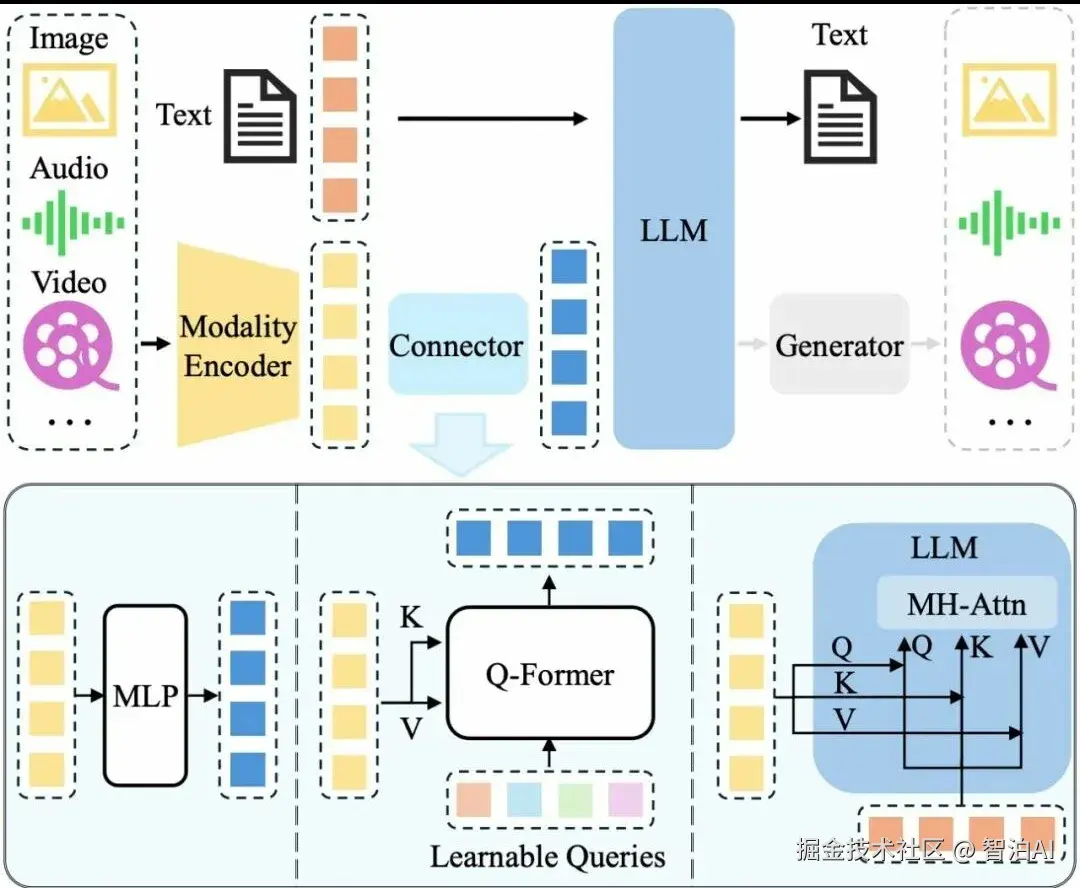
文本模态:
涵盖自然语言文本、经语音识别转换的文本内容等。
图像模态:
指视觉图像数据,例如照片、插画、艺术作品等。
视频模态:
包含动态影像序列,如短视频、影视片段、监控录像等。
音频模态:
指声学信号数据,如人声、音乐、环境音效等。
其他模态:
还包括如环境传感器读数、生理信号、指纹、虹膜等非传统信息形式。
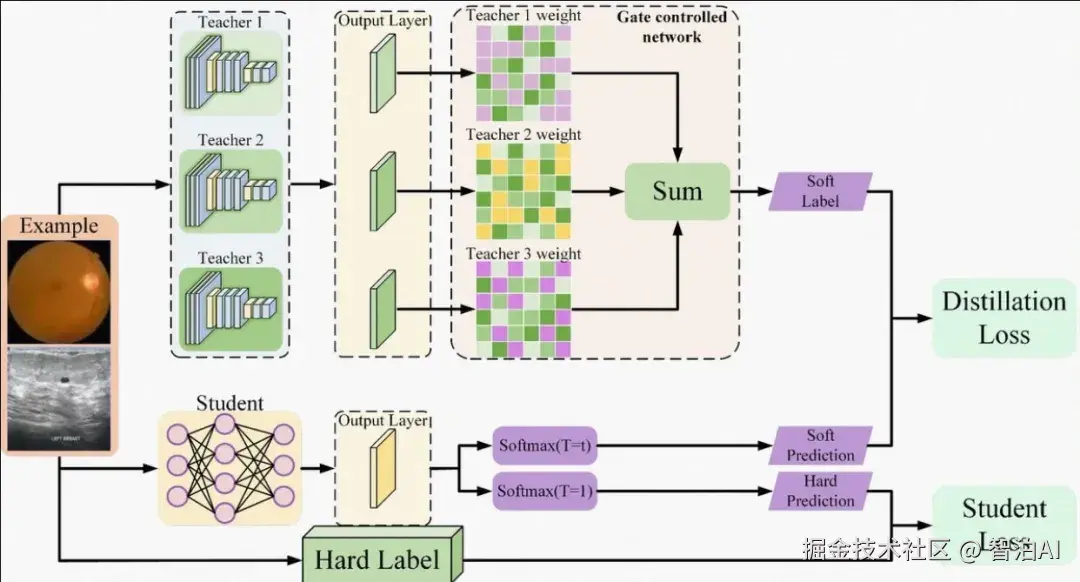
多模态模型的核心目标,在于融合上述异构模态的信息,以增强模型对输入数据的语义理解、任务执行与预测能力。
通过协同利用多源信息,模型得以构建更立体、更精准的认知框架。整合多元模态数据,使系统能够实现更丰富、更灵活的信息解析,从而为复杂智能任务提供坚实支撑。
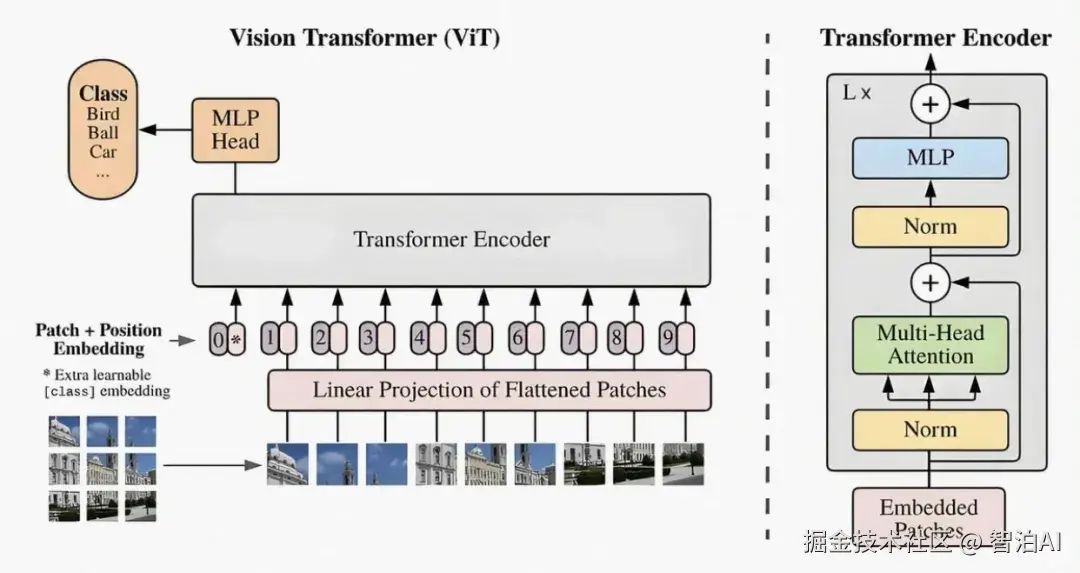
多模态大模型具备以下核心特征:
处理多种数据类型:可同步接收并处理文本、图像、视频、音频等多种输入,实现跨模态语义对齐与联合表征。
综合不同信息源:有效整合来自不同感知通道的数据,提升整体信息处理的完整性与准确性。
提升模型性能:借助多模态互补性,增强模型的泛化性与鲁棒性,拓展其在多样化任务中的适用边界。
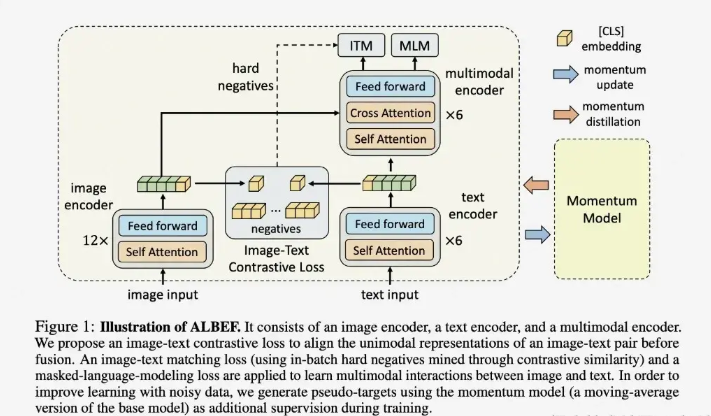
丰富的应用场景:广泛应用于图像字幕生成、视频内容分析、多模态人机交互、跨模态语义推理等前沿领域。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)