深度学习降噪利器:手把手教你三分钟部署 FRCRN 单麦语音降噪程序
本文介绍了如何利用阿里巴巴达摩院开源的FRCRN语音降噪模型搭建本地降噪服务。内容包括:1)环境准备,安装PyTorch、ModelScope等依赖;2)快速验证模型效果;3)使用FastAPI封装为Web API服务;4)关键注意事项,如采样率必须为16kHz、GPU/CPU切换等。FRCRN是目前单麦克风场景下效果最佳的降噪方案之一,通过本文指南可以低成本部署工业级语音降噪系统。
前言
在语音交互和音频处理领域,背景噪声一直是影响识别率和通话质量的痛点。阿里巴巴达摩院开源的 FRCRN (Frequency-Recurrent Convolutional Recurrent Network) 模型是目前的业界标峰之作,尤其在 DNS-Challenge 等国际赛事中表现卓越。
本文将带你从零开始,在自己的服务器上部署一个基于16k 单麦语音降噪服务。
1. 环境准备
首先,我们需要一个干净的 Python 环境(建议使用 Python 3.8 或 3.9)。
1.1 安装基础依赖
FRCRN 依赖 PyTorch 和 ModelScope 框架。执行以下命令安装:
# 安装 PyTorch (根据你的环境选择 CPU 或 GPU 版本)
# 这里以常用的 CUDA 11.7 为例,如果没有 GPU,直接 pip install torch
pip install torch torchvision torchaudio
如果你选择的直接配置好Pytorch的镜像就可以跳过以上这步
# 安装 ModelScope 音频相关库
pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 安装其他辅助库
pip install soundfile librosa
1.2 系统级依赖
如果你的系统中没有 ffmpeg,处理多种格式音频时可能会报错,建议安装:
- Ubuntu:
sudo apt-get install ffmpeg - CentOS:
yum install ffmpeg
2. 快速上手:几行代码实现降噪
在正式部署前,我们先写一个脚本验证模型是否能正常工作。
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 1. 初始化模型 pipeline
# 模型名称:damo/speech_frcrn_ans_cirm_16k
ans_pipeline = pipeline(
Tasks.acoustic_noise_suppression,
model='damo/speech_frcrn_ans_cirm_16k'
)
# 2. 指定输入输出文件
input_path = 'test_noisy.wav' # 确保这是一个 16k 采样率的 wav 文件
output_path = 'test_denoised.wav'
# 3. 执行降噪
ans_pipeline(input_path, output_path=output_path)
print(f"处理完成!降噪后的音频已保存至:{output_path}")
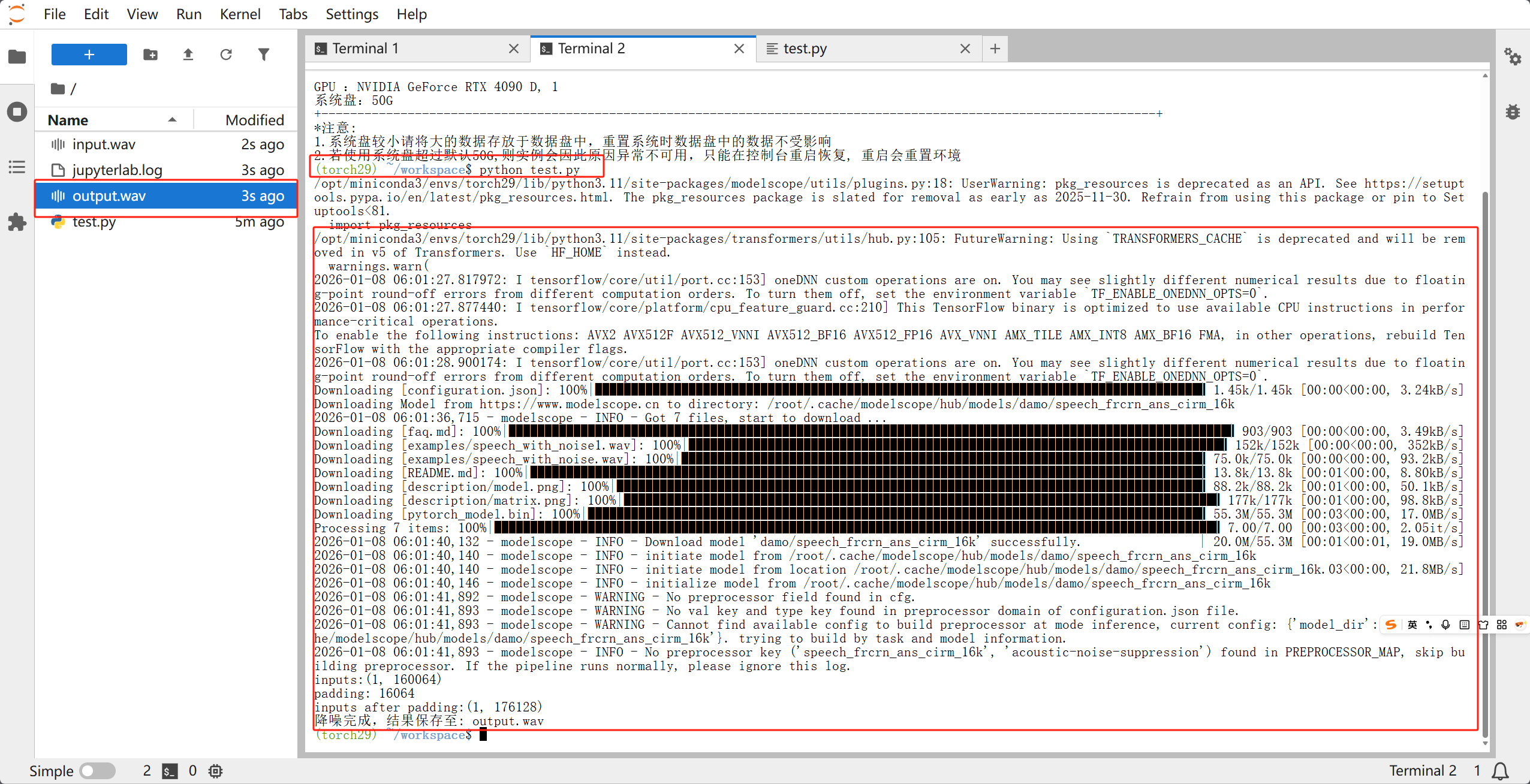
第一次运行的时候会下载模型,模型不大,根据网络波动下载时间大概在一两分钟左右
3. 进阶:部署为 Web API 服务
为了让前端或其他微服务能够调用降噪功能,我们使用 FastAPI 封装一个接口。
3.1 安装 Web 框架
pip install fastapi uvicorn python-multipart
3.2 编写服务端代码 main.py
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.responses import FileResponse
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import shutil
import uuid
import os
app = FastAPI(title="FRCRN 语音降噪 API")
# 全局加载模型,避免每次请求重复加载耗时
print("Loading Model...")
ans_pipeline = pipeline(
Tasks.acoustic_noise_suppression,
model='damo/speech_frcrn_ans_cirm_16k'
)
print("Model Loaded!")
@app.post("/denoise")
async def denoise_api(file: UploadFile = File(...)):
# 1. 生成唯一文件名,防止并发冲突
task_id = str(uuid.uuid4())
in_file = f"temp_in_{task_id}.wav"
out_file = f"temp_out_{task_id}.wav"
try:
# 2. 保存上传的音频
with open(in_file, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
# 3. 调用 FRCRN 推理
ans_pipeline(in_file, output_path=out_file)
# 4. 返回处理后的文件
return FileResponse(out_file, media_type="audio/wav", filename="denoised.wav")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
finally:
# 5. 清理临时输入文件(输出文件建议由后台定时清理或发送后删除)
if os.path.exists(in_file):
os.remove(in_file)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
4. 关键注意事项(避坑指南)
4.1 采样率必须是 16k
FRCRN 模型是针对 16kHz 采样率训练的。如果你的原始音频是 44.1k 或 48k,模型不会报错,但降噪效果会极其糟糕(声音变调或全是杂音)。
- 解决方法: 在调用模型前,先用
librosa进行重采样。
4.2 GPU 与 CPU 切换
- 如果有 NVIDIA 显卡且安装了 CUDA,ModelScope 会自动使用 GPU,推理速度极快。
- 如果显存不足,可以在初始化时强制指定 CPU:
ans_pipeline = pipeline(Tasks.acoustic_noise_suppression, model='...', device='cpu')
4.3 处理长音频
对于超过 5 分钟的长音频,直接处理可能会导致内存溢出(OOM)。建议在 API 层增加逻辑:将音频切分成 30 秒一段,逐段处理后再拼接。
5. 总结
通过 ModelScope 提供的 FRCRN 模型,我们可以极低成本地搭建出一套工业级的语音降噪系统。
部署流程回顾:
- 环境: PyTorch + ModelScope。
- 核心: 使用
pipeline调用damo/speech_frcrn_ans_cirm_16k。 - 服务化: 使用 FastAPI 提供远程调用接口。
- 规范: 严格控制输入音频采样率为 16,000Hz。
如果你正在寻找一种开源且效果稳健的降噪方案,FRCRN 绝对是目前单麦场景下的首选。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)