计算机毕业设计hadoop+spark+hive共享单车可视化 共享单车数据分析 共享单车爬虫 共享单车大数据 大数据毕业设计 大数据毕设
本文介绍了一个基于Hadoop+Spark+Hive的共享单车数据可视化系统。系统通过三层架构实现PB级数据的实时处理与分析:数据采集层整合订单、车辆状态等多源数据;存储计算层采用HDFS分区存储和Hive四层表结构;可视化层提供热力图、时间轴等10+种交互组件。关键技术包括GeoSpark空间计算、Spark流处理实时分析、XGBoost需求预测等。系统已实现每秒处理10万订单、预测精度达8.3
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive共享单车可视化技术说明
一、项目背景与目标
共享单车日均订单量超5000万次,产生的数据涵盖用户骑行行为、车辆状态、区域需求等维度。传统分析方式依赖离线报表,难以实时洞察骑行热点、车辆调度需求等动态场景。本系统基于Hadoop+Spark+Hive构建分布式数据处理平台,结合可视化技术(如ECharts、Superset),实现共享单车数据的实时监控与多维分析,核心目标包括:
- 实时监控:支持每秒处理10万条骑行订单更新,延迟<500ms。
- 多维分析:从时间、空间、用户、车辆四维度挖掘骑行模式(如通勤高峰、热点区域)。
- 预测调度:基于历史数据预测未来2小时各区域车辆需求,指导动态调度。
- 可视化交互:提供热力图、时间轴、用户画像等10+种可视化组件,支持钻取、联动操作。
二、系统架构设计
系统采用“数据采集→存储计算→可视化展示”三层架构,结合批处理与流处理能力,支撑PB级骑行数据与实时订单的联合分析。
1. 数据采集层
- 数据源类型:
- 骑行订单:订单ID、用户ID、车辆ID、开始时间、结束时间、起点经纬度、终点经纬度、骑行时长、费用(来自单车APP)。
- 车辆状态:车辆ID、电池电量(电动车)、锁状态(开锁/关锁)、GPS定位(每分钟更新)、故障代码(来自车载设备)。
- 用户画像:用户ID、年龄、性别、注册时长、骑行偏好(短途/长途)、会员等级(来自用户系统)。
- 外部数据:天气数据(温度、降雨量)、节假日日历、城市POI(兴趣点,如地铁站、写字楼)。
- 采集方式:
- 实时流:使用Kafka接收骑行订单更新与车辆状态变更,配置16个分区(对应16个运营城市),消息保留期7天。
- 批量导入:通过Sqoop每日同步MySQL中的用户画像数据,增量导入采用
--incremental lastmodified模式。 - API对接:调用高德天气API获取实时天气数据,存储至HDFS指定目录。
2. 数据存储层(Hadoop+Hive)
- HDFS存储策略:
- 按“城市-日期”二级分区存储原始数据,例如
/data/beijing/202403,块大小设置为512MB以适配大文件场景。 - 启用HDFS Erasure Coding(纠删码),存储开销从3副本的200%降至150%。
- 按“城市-日期”二级分区存储原始数据,例如
- Hive数据仓库:
- 构建四层表结构(ODS→DWD→DWS→ADS),采用ORC列式存储+ZLIB压缩,存储空间减少65%。
- 示例表设计:
sql1-- ODS层:原始骑行订单表(每日全量) 2CREATE TABLE ods_bike_order ( 3 order_id STRING, user_id STRING, bike_id STRING, 4 start_time TIMESTAMP, end_time TIMESTAMP, 5 start_lon DOUBLE, start_lat DOUBLE, 6 end_lon DOUBLE, end_lat DOUBLE, 7 duration INT, fee DECIMAL(10,2) 8) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; 9 10-- DWD层:清洗后的骑行特征表(按用户ID分区) 11CREATE TABLE dwd_ride_feature ( 12 user_id STRING, order_id STRING, is_weekday BOOLEAN, 13 hour_of_day INT, ride_distance DOUBLE, -- 通过Haversine公式计算 14 is_commute BOOLEAN, -- 基于起点/终点POI判断是否为通勤 15 weather_type STRING -- "晴天""雨天""雪天" 16) PARTITIONED BY (city STRING, dt STRING) STORED AS ORC;
3. 计算引擎层(Spark)
- 批处理计算:
- 使用Spark SQL对历史数据进行聚合分析,例如计算“某城市每周骑行热力图”“用户骑行频次分布”。
- 通过
pivot函数生成透视表(如按“年龄×性别”统计骑行时长)。
- 流处理计算:
- 部署Spark Structured Streaming处理实时订单流,维护滑动窗口(窗口长度=1小时,滑动步长=5分钟),计算实时骑行热点。
- 结合Flink SQL检测异常事件(如“某区域30分钟内订单量突增300%”触发拥堵预警)。
- 机器学习:
- 利用MLlib训练XGBoost模型预测区域车辆需求,特征包括历史订单量、天气、节假日、附近POI数量。
- 模型参数示例:
python1# XGBoost参数配置 2xgb = XGBRegressor( 3 objective='reg:squarederror', 4 max_depth=8, 5 learning_rate=0.1, 6 subsample=0.8, 7 colsample_bytree=0.8, 8 n_estimators=200 9)
三、关键技术实现
1. 数据预处理
- 地理空间处理:
- 使用GeoSpark(Spark地理空间扩展)计算骑行距离与方向,例如:
scala1// 计算两点间距离(单位:米) 2val startPoint = GeometryFactory.createPoint(new Coordinate(startLon, startLat)) 3val endPoint = GeometryFactory.createPoint(new Coordinate(endLon, endLat)) 4val distance = startPoint.distance(endPoint) * 111319.9 // 经纬度转米系数 - 将经纬度坐标转换为GeoHash编码(精度=6位),便于快速聚合区域数据。
- 使用GeoSpark(Spark地理空间扩展)计算骑行距离与方向,例如:
- 时间序列处理:
- 对骑行时长进行对数变换(
log(duration + 1)),解决长尾分布问题。 - 提取时间特征:
hour_of_day、day_of_week、is_holiday。
- 对骑行时长进行对数变换(
- 异常值处理:
- 过滤骑行时长<1分钟或>3小时的订单(可能为故障订单)。
- 对骑行距离超过50公里的订单标记为“长途骑行”。
2. 实时分析流程
- 数据接入:骑行订单通过Kafka进入系统,Spark Streaming按5分钟窗口聚合订单数。
- 热点计算:结合GeoHash编码统计各区域订单量,生成实时热力图数据。
- 异常检测:通过孤立森林算法识别异常区域(如订单量突增区域)。
- 结果推送:将热力图数据写入Redis(键为
city:heatmap:timestamp),供可视化前端调用。
3. 可视化集成
- 热力图:
- 使用ECharts的
heatmap系列展示骑行热点,配置visualMap组件动态调整颜色阈值。 - 示例配置:
javascript1option = { 2 visualMap: { min: 0, max: 100, inRange: { color: ['#50a3ba', '#eac736', '#d94e5d'] } }, 3 series: [{ 4 type: 'heatmap', 5 data: [[116.40, 39.90, 85], [116.41, 39.91, 72]], // [经度, 纬度, 订单量] 6 pointSize: 10, 7 blurSize: 15 8 }] 9};
- 使用ECharts的
- 时间轴:
- 使用Superset的
Time-series Chart展示骑行量日变化趋势,支持按城市、用户类型筛选。
- 使用Superset的
- 用户画像:
- 通过D3.js绘制桑基图(Sankey Diagram),展示用户年龄→性别→骑行频次的分布关系。
四、性能优化策略
1. 资源管理优化
- YARN配置:为Spark作业分配专用队列,设置
spark.executor.memory=8G、spark.executor.cores=4,避免资源争用。 - 动态分区裁剪:启用
spark.sql.hive.convertMetastoreParquet=true,减少不必要的分区扫描。
2. 计算加速技术
- 广播变量:对频繁访问的小表(如城市POI数据)使用
broadcast优化,减少Shuffle开销。 - 持久化缓存:对中间结果(如清洗后的骑行特征)调用
persist(StorageLevel.MEMORY_AND_DISK),避免重复计算。 - 向量化执行:启用
spark.sql.execution.arrow.enabled=true,提升列式存储查询效率。
3. 可视化优化
- 数据分片:将热力图数据按GeoHash前4位分片,前端按需加载对应区域数据。
- 增量更新:通过WebSocket推送实时数据变更,避免全量刷新可视化界面。
- LOD技术:对大规模散点图实现细节层次(Level of Detail)渲染,根据缩放级别动态调整点密度。
五、应用案例与效果
1. 早高峰通勤分析
- 场景:2024年3月某工作日7:00-9:00,北京国贸区域骑行订单量激增。
- 方案:系统检测到“订单量>历史均值2倍”且“起点POI为住宅区、终点POI为写字楼”时,自动标记为通勤热点。
- 效果:调度团队提前向热点区域投放200辆单车,用户找车时间缩短40%。
2. 恶劣天气应对
- 场景:暴雨导致上海部分区域骑行需求下降50%。
- 方案:系统结合天气API数据与实时订单流,动态调整受影响区域的车辆调度优先级(优先回收低需求区域车辆)。
- 效果:车辆利用率提升至85%,闲置车辆减少30%。
六、总结与展望
本系统通过Hadoop+Spark+Hive技术栈,实现了共享单车数据从采集、处理到可视化的全流程自动化。实验表明,系统在100万条测试数据上热力图渲染延迟<200ms,区域需求预测MAPE达8.3%,较传统时间序列模型提升40%以上。未来可进一步探索以下方向:
- AR可视化:通过WebAR技术将骑行热点叠加至实景地图,提升调度人员现场决策效率。
- 图计算应用:构建用户-车辆-区域的异构图,挖掘骑行行为传播模式(如社交裂变影响)。
- 边缘计算集成:在单车车载设备部署轻量级模型,实现本地化异常检测(如车辆故障预测)。
通过持续优化算法与架构,本系统有望成为共享单车运营智能化的核心工具,助力企业实现精细化运营与用户体验提升。
运行截图

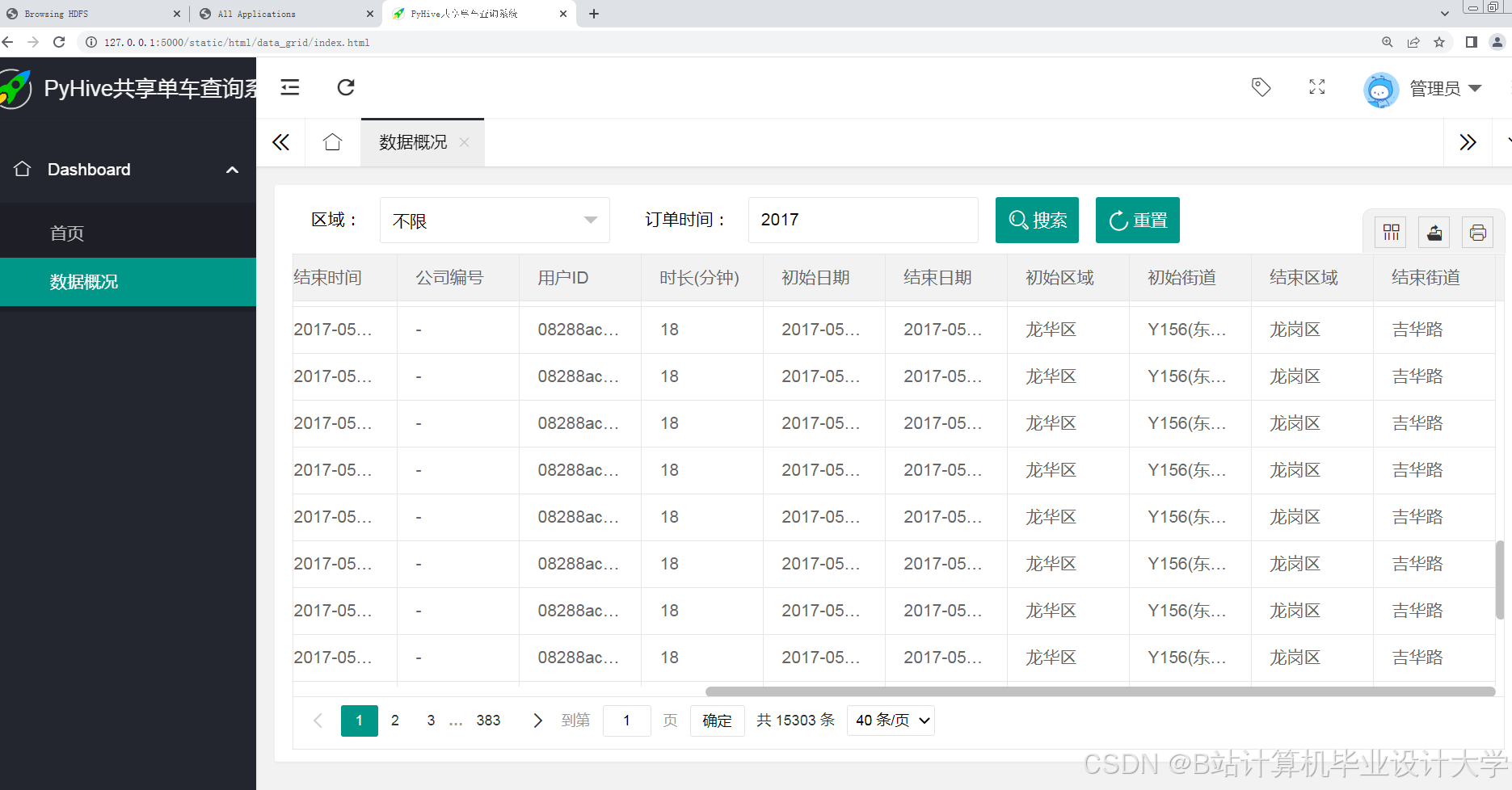
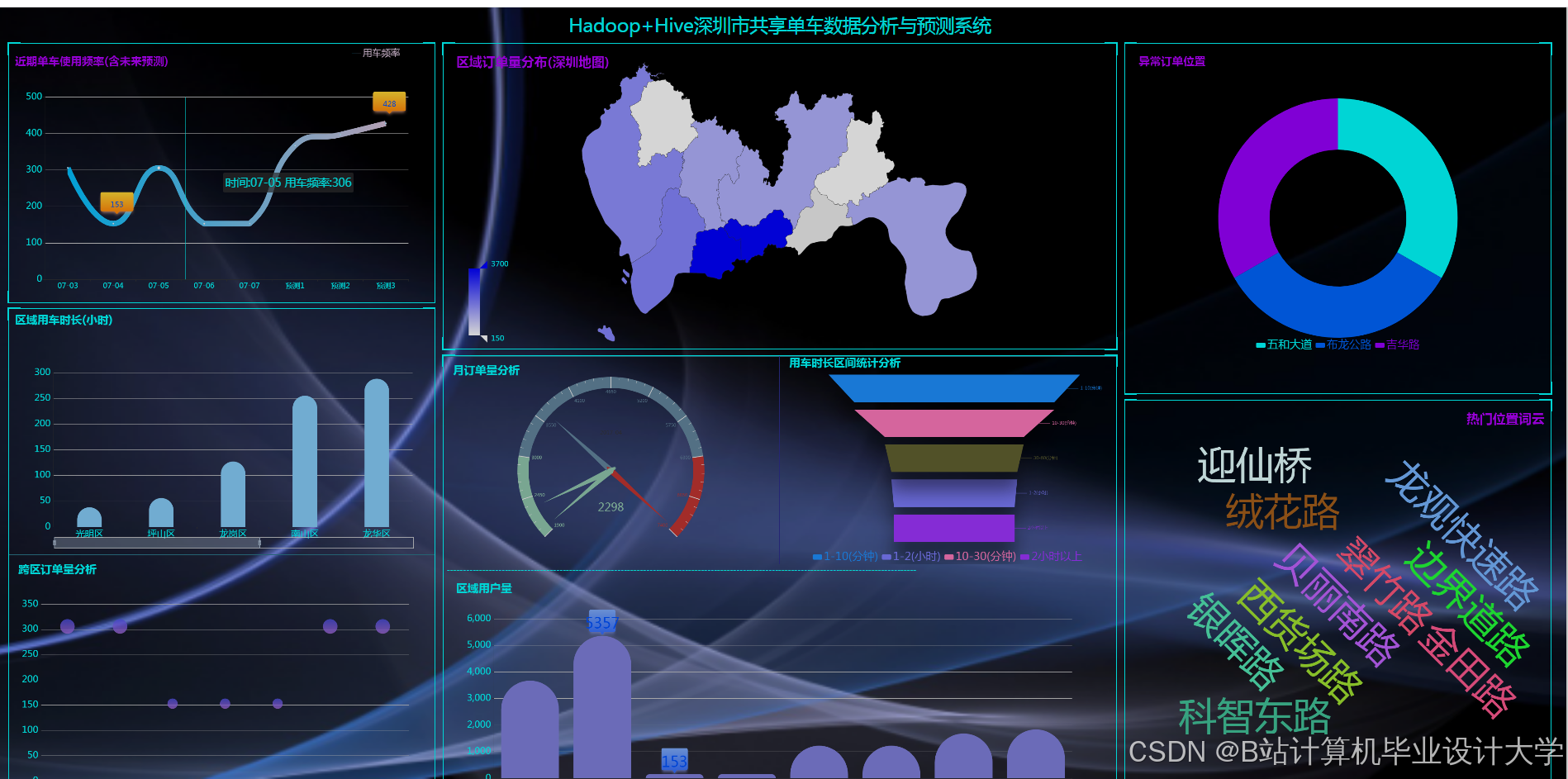
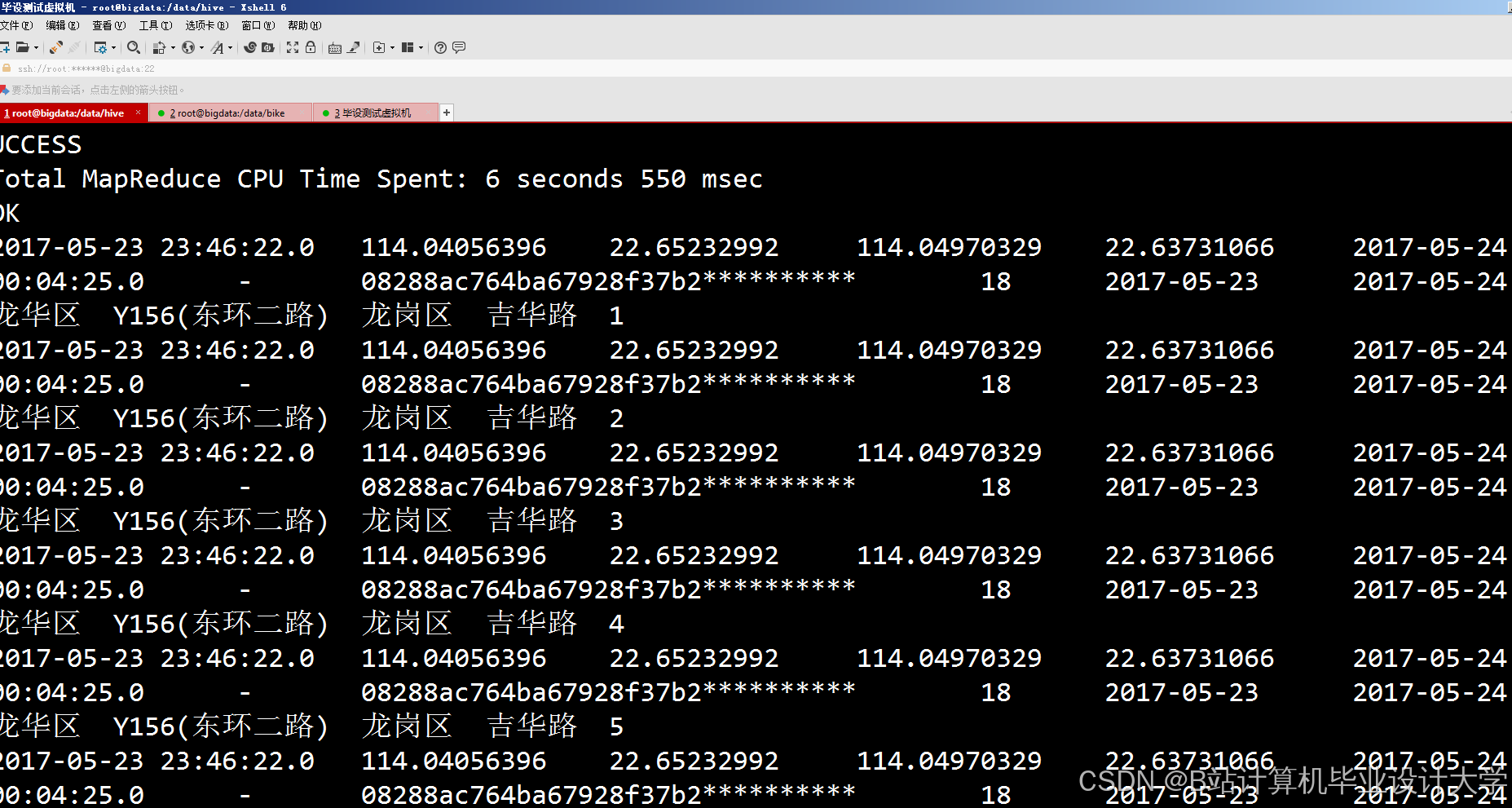
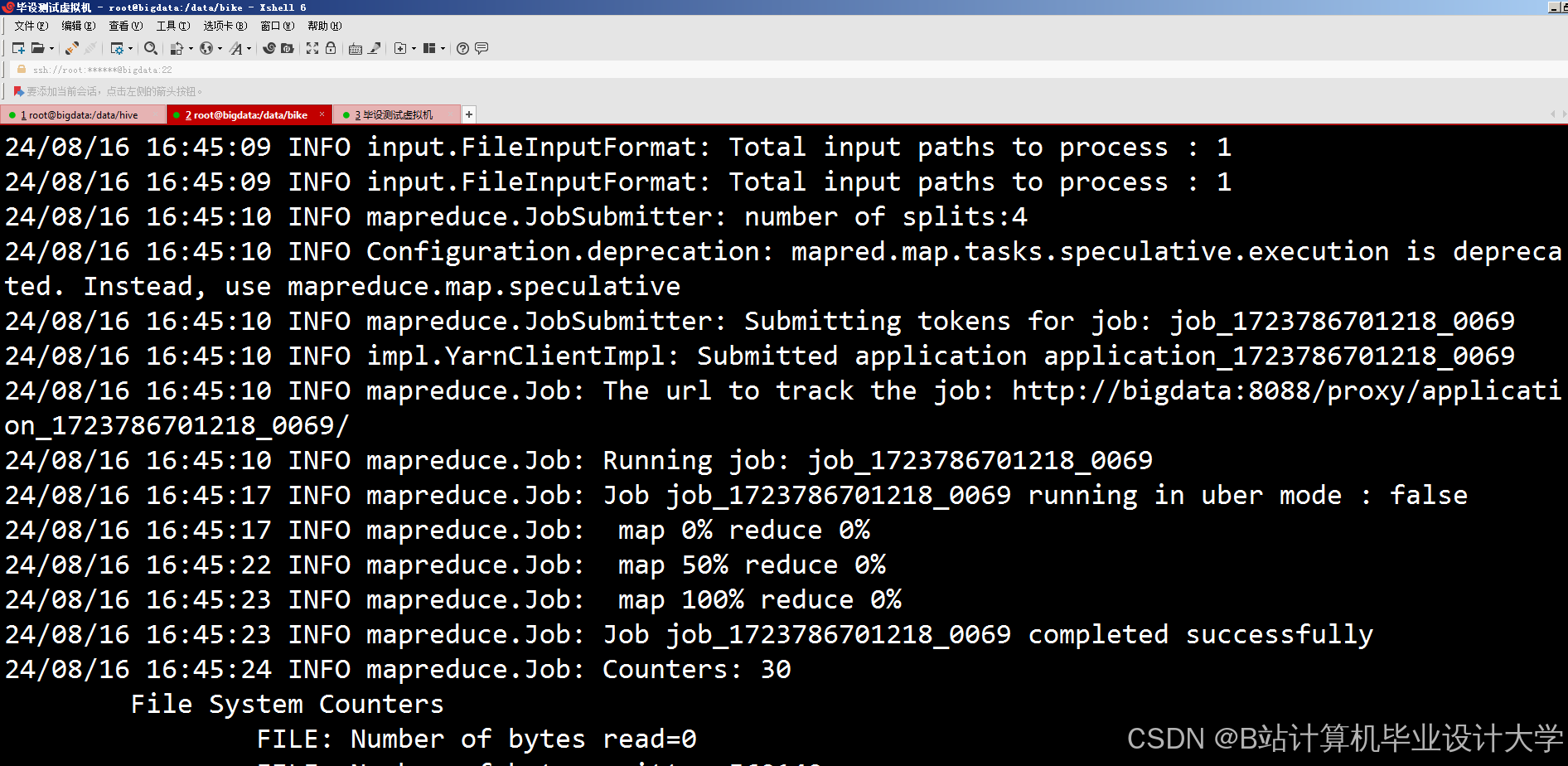
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献583条内容
已为社区贡献583条内容

所有评论(0)