好用的文本特征提取算法——TF-IDF 算法
在我们的日常生活当中,肯定会遇到很多地方需要用到关键词提取,就比如说:你想在CSDN当中搜索哪些算法可以处理自然语言,那么TF-IDF 是最基础也最核心的文本特征提取算法,小到关键词提取、文本查重,大到搜索引擎排序、文本分类,都能看到它的身影。
在我们的日常生活当中,肯定会遇到很多地方需要用到关键词提取,就比如说:你想在CSDN当中搜索哪些算法可以处理自然语言,那么TF-IDF 是最基础也最核心的文本特征提取算法,小到关键词提取、文本查重,大到搜索引擎排序、文本分类,都能看到它的身影。
一、TF-IDF 是什么?
TF-IDF(Term Frequency-Inverse Document Frequency),即词频 - 逆文档频率。
我们要搜索CSDN当中介绍Python的文章,这里我们需要的关键词有两个:CSDN、Python。如果我们在百度搜索CSDN当中介绍Python的博客,因为百度会提供所有介绍Python的文章,所以我们的关键词更希望CSDN比重大一点,但是如果我们在CSDN当中搜索,我们则更希望关键词Python比重大一点。
TF-IDF(Term Frequency-Inverse Document Frequency)即词频 - 逆文档频率,核心思想是:
一个词对文档的重要性,既和它在该文档中出现的频率成正比,又和它在整个语料库中出现的文档数成反比。简单来说:在本文档中出现多,且在其他文档中出现少的词,才是 “关键词”。
二、TF-IDF 计算公式
2.1. 词频(TF)
表示某个词在单个文档中出现的频率:

2.2. 逆文档频率(IDF)
表示某个词在整个语料库中的稀缺程度:

(+1 是为了避免分母为 0,即某个词在所有文档中都没出现的情况)
2.3. TF-IDF 最终值
![]()
值越大,说明该词对当前文档的 “代表性” 越强。
三、代码实现
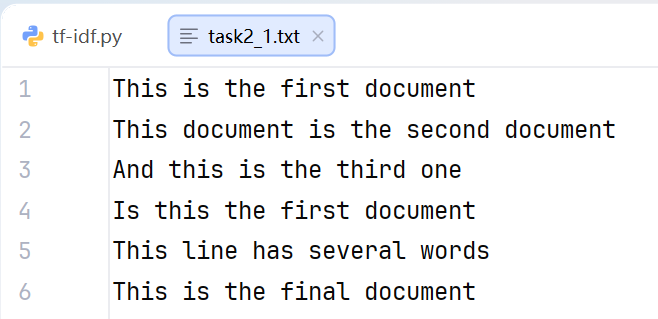
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
inFile = open('task2_1.txt','r')
corpus = inFile.readlines()
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
print(tfidf)
wordlist = vectorizer.get_feature_names_out()
print(wordlist)
df = pd.DataFrame(tfidf.T.todense(), index= wordlist)
print(df)
for j in range(len(corpus)):
featurelist = df.iloc[:, j].to_list()
resdict = {}
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
resdict_sorted = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
print(f"文档{j+1}的前5关键词:{resdict_sorted[:5]}")
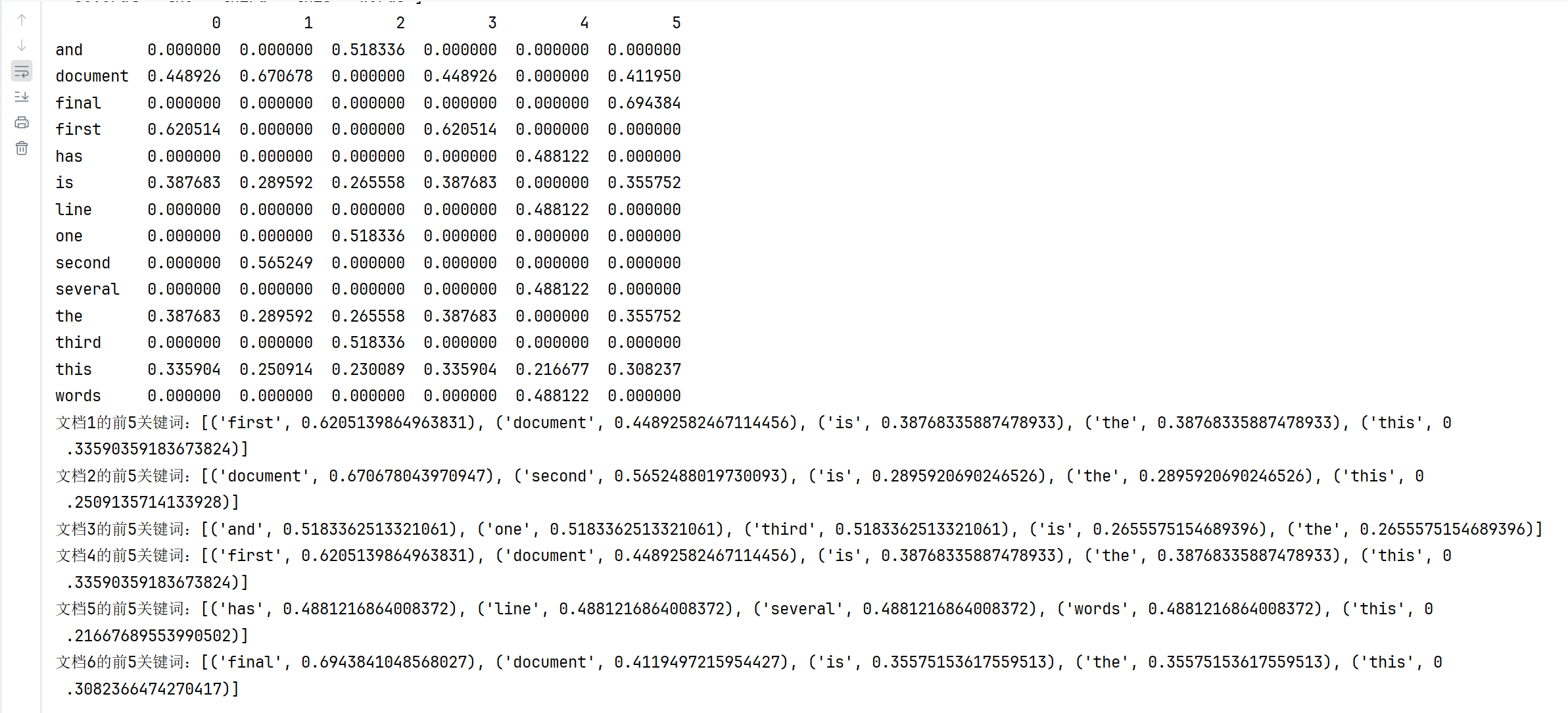

第一步导入依赖库。

然后使用只读模式打开文件,然后读取文档。

初始化 TF-IDF 向量器并计算 TF-IDF 矩阵,输出 TF-IDF 稀疏矩阵和特征词列表,之后转换为 DataFrame 并输出。

提取每个文档的前 5 关键词,来看文档哪个关键词出现频率最高。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)