基于YOLOV8的车辆检测系统:快速上手与实用功能
基于YOLOV8的车辆检测系统 基于深度学习的车辆检测系统 有数据集 模型已经训练好 直接用即可 报告 +30r 就是售价 包搭配环境 远程运行跑通程序 本项目已经训练好模型,配置好环境可直接使用,运行效果见图像(可找我要演示视频) 项目介绍: 软件:Pycharm+Anaconda 环境:python=3.8 opencv-python PyQt5 torch1.9 文件: 1.完整程序文件(.py等 2.UI界面源文件、图标(.ui、.qrc、.py等) 3.测试图片、视频文件(.jpeg、.mp4、.avi等) 车辆种类一共分为4类[“car”、“bus”、“van”、“others”] 功能: 系统可用于车辆检测系统; 支持图片、视频及摄像头进行检测: 界面可实时显示目标位置、目标总数、置信度等信息: 支持图片或者视频的检测结果保存; ①选择图片进行对于车辆检测 ②选择视频进行对于车辆检测 ③摄像头进行检测对于车辆检测

最近搞了个基于YOLOV8的车辆检测系统,超有意思,今天来跟大家唠唠。这可是基于深度学习的车辆检测,而且数据集也有,模型都训练好了,直接就能用,简直不要太方便。要是你需要报告,加30块钱就行,还包搭配环境,远程帮你把程序跑通,是不是很贴心~
一、整体项目概述
咱们这个项目,软件用的是Pycharm + Anaconda ,环境方面,python版本是3.8 ,还搭配了opencv-python 、PyQt5 以及torch1.9 。文件构成也很清晰:
- 完整程序文件(.py等):这是核心代码所在,负责整个检测流程的逻辑实现。
- UI界面源文件、图标(.ui、.qrc、.py等):打造出一个直观的用户界面,方便操作。
- 测试图片、视频文件(.jpeg、.mp4、.avi等):用来测试系统检测效果的素材。
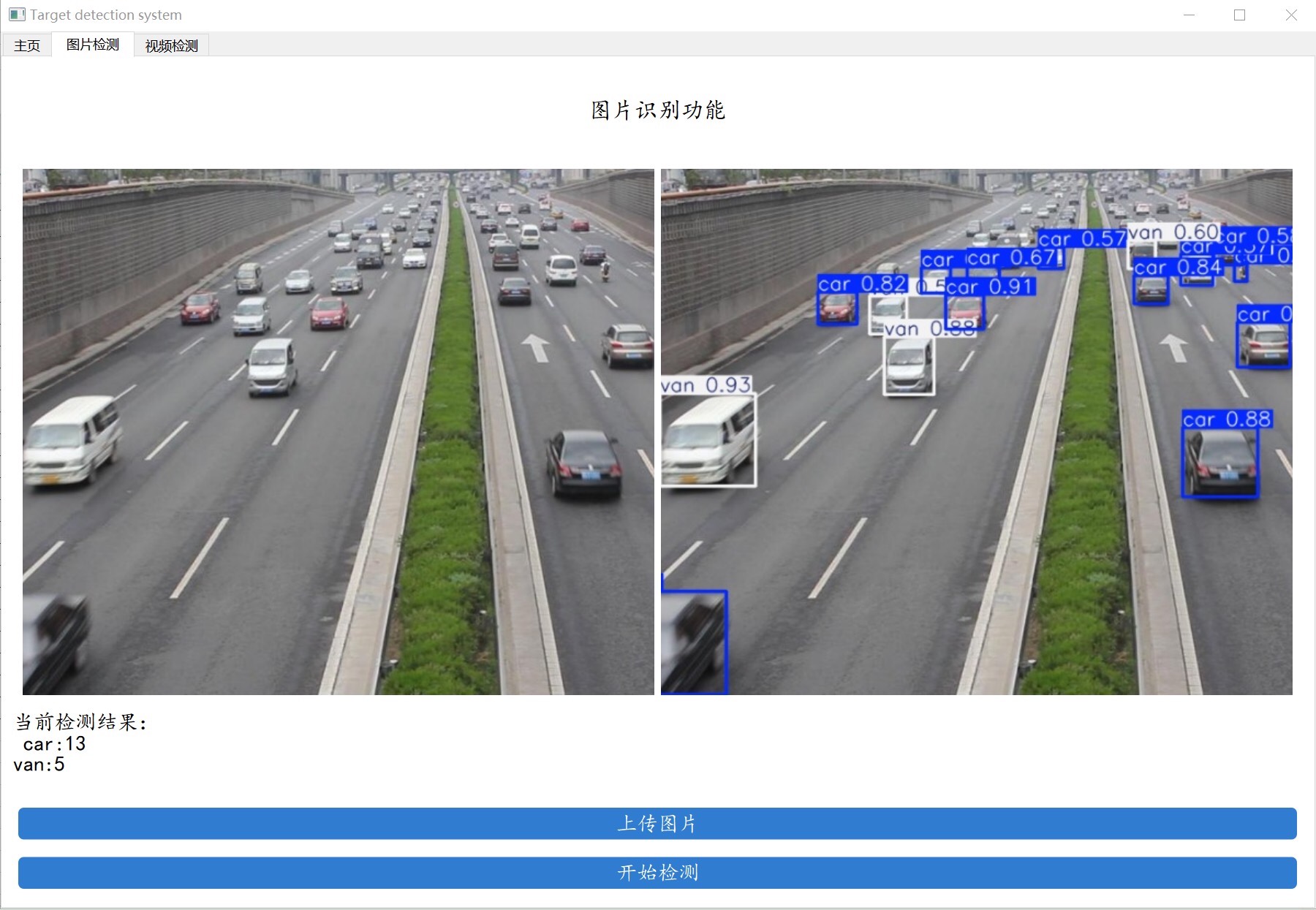
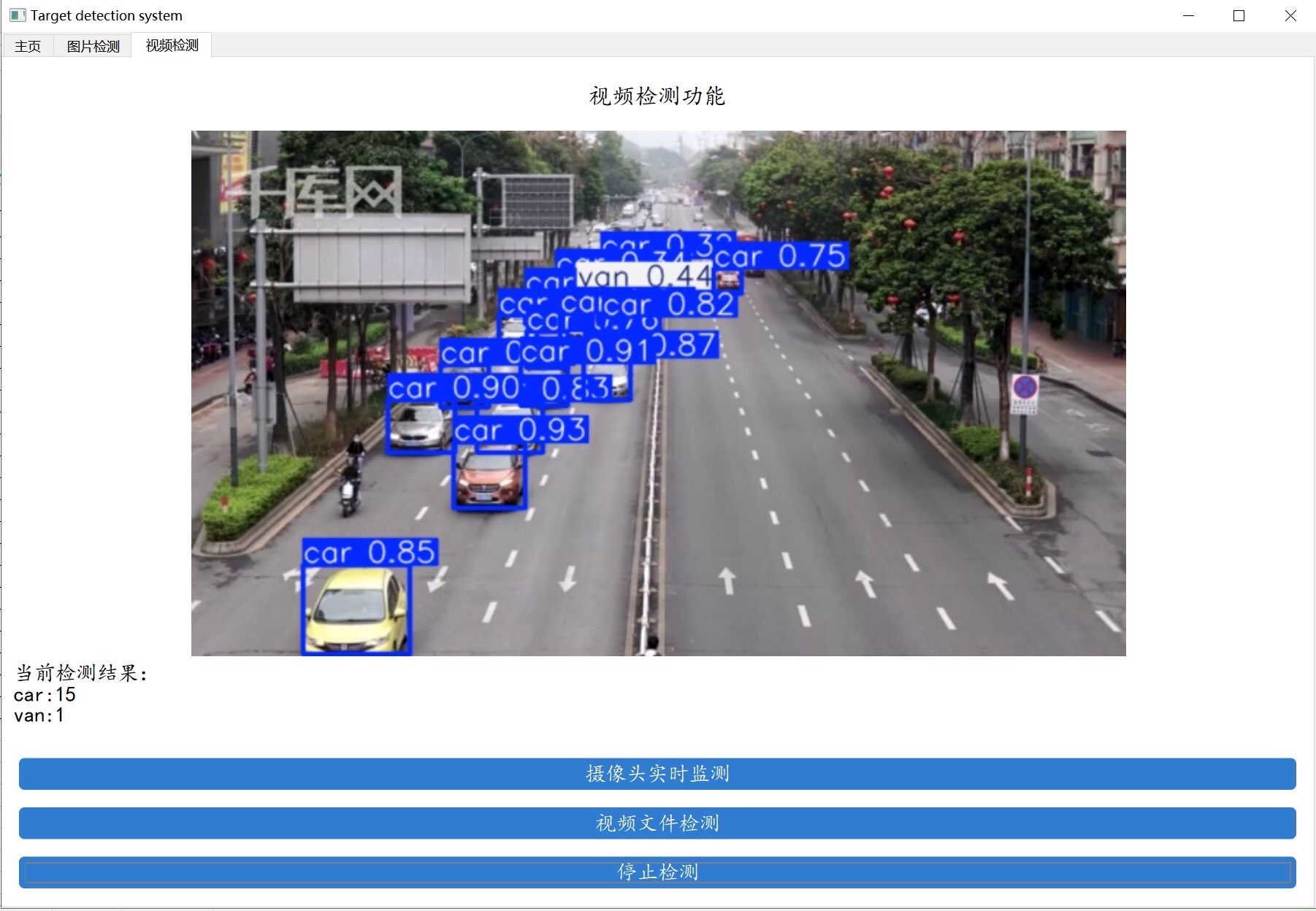
车辆种类一共分为4类:["car"、"bus"、"van"、"others"] 。功能更是实用,不仅能用于车辆检测,还支持图片、视频及摄像头进行检测。界面上能实时显示目标位置、目标总数、置信度等信息,并且支持把图片或者视频的检测结果保存下来。
二、代码探秘
咱们来看看关键代码部分,以使用YOLOV8进行图片检测为例(简化示例):
import cv2
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('path/to/your/trained/model.pt')
# 读取图片
image = cv2.imread('test.jpeg')
# 进行预测
results = model.predict(image)
for result in results:
boxes = result.boxes
for box in boxes:
# 获取边界框坐标
x1, y1, x2, y2 = map(int, box.xyxy[0])
# 获取置信度
confidence = box.conf[0].item()
# 获取类别
class_id = box.cls[0].item()
class_name = model.names[int(class_id)]
# 在图片上绘制边界框和信息
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
label = f'{class_name}: {confidence:.2f}'
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示结果图片
cv2.imshow('Vehicle Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()代码分析
- 模型加载:
model = YOLO('path/to/your/trained/model.pt')这行代码就是加载咱们已经训练好的模型,路径得写对,这样模型才能正常工作。 - 图片读取:
image = cv2.imread('test.jpeg')用OpenCV的imread函数读取要检测的图片。 - 预测部分:
results = model.predict(image)调用模型的predict方法对图片进行预测,这一步会返回包含检测结果的对象。 - 结果处理:通过循环遍历每个检测到的目标,获取边界框坐标
(x1, y1, x2, y2)、置信度confidence以及类别classid,并根据类别ID获取类别名称classname。然后使用OpenCV在图片上绘制边界框和相关信息。 - 显示图片:最后用
cv2.imshow显示带有检测结果的图片,cv2.waitKey(0)等待用户按键关闭窗口,cv2.destroyAllWindows()关闭所有OpenCV窗口。
三、功能演示
- 选择图片进行车辆检测:就像上面代码演示的那样,选择一张图片,系统就能快速检测出车辆,并在图片上标注出相关信息。
- 选择视频进行车辆检测:这部分代码逻辑跟图片检测类似,只不过是逐帧读取视频进行检测,并把检测结果写入新的视频文件或者实时显示在窗口上。
- 摄像头进行检测:调用摄像头设备,实时获取画面并进行车辆检测,同样能在画面上实时显示检测信息。
这个基于YOLOV8的车辆检测系统是不是很赞?运行效果超棒,要是感兴趣可以找我要演示视频瞅瞅。有任何问题,欢迎留言讨论呀~
基于YOLOV8的车辆检测系统 基于深度学习的车辆检测系统 有数据集 模型已经训练好 直接用即可 报告 +30r 就是售价 包搭配环境 远程运行跑通程序 本项目已经训练好模型,配置好环境可直接使用,运行效果见图像(可找我要演示视频) 项目介绍: 软件:Pycharm+Anaconda 环境:python=3.8 opencv-python PyQt5 torch1.9 文件: 1.完整程序文件(.py等 2.UI界面源文件、图标(.ui、.qrc、.py等) 3.测试图片、视频文件(.jpeg、.mp4、.avi等) 车辆种类一共分为4类[“car”、“bus”、“van”、“others”] 功能: 系统可用于车辆检测系统; 支持图片、视频及摄像头进行检测: 界面可实时显示目标位置、目标总数、置信度等信息: 支持图片或者视频的检测结果保存; ①选择图片进行对于车辆检测 ②选择视频进行对于车辆检测 ③摄像头进行检测对于车辆检测

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)