神经网络与深度学习
0. 引言:从单兵作战到集团军 —— 深度学习的诞生
0.1 历史的困境:单个神经元的极限

0.1.1 著名的“异或 (XOR)”危机
在人工智能的早期(20世纪60年代),科学家们曾对感知机(逻辑回归的前身)寄予厚望。直到 1969 年,明斯基 (Minsky) 和 帕佩特 (Papert) 写了一本著名的书《Perceptrons》,指出了一个致命的缺陷,直接导致了 AI 的第一个寒冬。
这个缺陷就是:单层感知机甚至连简单的“异或 (XOR)”逻辑都学不会。
让我们看看 XOR 的真值表:
| 输入 x1 | 输入 x2 | 输出 y (XOR) |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
请你拿出一张纸,画一个坐标系:
-
在 (0,0) 点画一个圈(代表 0)。
-
在 (1,1) 点画一个圈(代表 0)。
-
在 (0,1) 点画一个叉(代表 1)。
-
在 (1,0) 点画一个叉(代表 1)。
挑战: 请你尝试画一条直线,把所有的圈和所有的叉彻底分开。
你会发现,无论你怎么画,斜着画、横着画、竖着画,你永远做不到。因为这两个类别的分布是**“对角线”关系的,它们是线性不可分 (Linearly Inseparable)** 的。
这不仅仅是 XOR 的问题。
-
图像识别: 一张猫的照片,像素之间的关系极其复杂,绝不是一条直线能区分的。
-
自然语言: "我喜欢你" 和 "我不喜欢你" 只有一字之差,含义却相反。这种语义的非线性,线性模型无法捕捉。
结论: 单兵作战(线性模型)已到极限。我们需要一种能画“曲线”、能“折叠空间”的新武器。
0.2 生物学的启示:大脑是如何思考的?
当计算机科学家在 XOR 问题前碰壁时,他们把目光投向了宇宙中已知的最强智能体——人类大脑。
大脑能轻易识别猫,能听懂笑话,能思考哲学。它是怎么做到的?
0.2.1 神经元 (Neuron):大脑的晶体管
生物学家告诉我们要看显微镜。大脑皮层由大约 860 亿 个神经元组成。虽然整体极其复杂,但单个神经元的结构却出奇的简单:
-
树突 (Dendrites): 像树根一样,负责接收来自其他神经元的电信号(输入)。
-
细胞体 (Cell Body): 中央处理器,负责汇总所有接收到的信号。
-
轴突 (Axon): 输出通道,负责将处理后的信号发射给下一个神经元。
这里有一个关键机制:动作电位 (Action Potential)。
神经元不是收到一点信号就反应的。它有一个阈值。只有当汇总的信号强度超过了这个阈值,神经元才会“兴奋”(Fire),产生一个脉冲传给下一级;否则,它就保持沉默。
这听起来是不是很耳熟?

0.2.2 连接主义 (Connectivism):智能源于连接
如果单个神经元只是一个简单的“累加器”,那智能是从哪里来的?
答案在于连接。
一个神经元可能与上千个其他神经元相连。这些连接有强有弱(对应权重 w 的大小)。
-
当你看这一行字时,你视网膜上的神经元被激活。
-
信号传递给视觉皮层,激活“边缘检测”神经元。
-
再传递给“形状识别”神经元。
-
再传递给“文字理解”神经元。
涌现 (Emergence): 简单的个体通过复杂的连接,涌现出了宏观的智能。
这就是神经网络 (Neural Network) 的核心哲学:既然一个逻辑回归单元解决不了 XOR,那我们就把多个逻辑回归单元连接起来。
0.3 集团军的构建:多层感知机 (MLP) 的架构
受生物学启发,我们开始在计算机中搭建人工神经网络。这种最基础的结构,被称为多层感知机 (Multilayer Perceptron, MLP),也就是我们常说的全连接网络。
为了便于理解,我们不再称呼它们为逻辑回归单元,而称之为**“神经元”或“节点”**。
0.3.1 层级结构 (Layers):从哨兵到指挥官
一个标准的神经网络通常包含三类层级。你可以把这想象成一个情报处理机构:
1. 输入层 (Input Layer) —— 前线哨兵
-
任务: 它们不进行任何计算,只负责接收原始数据。
-
类比: 就像战场的观察哨。
-
哨兵 A 报告:“前方 100 米有响动”(x_1)。
-
哨兵 B 报告:“风速 5 级”(x_2)。
-
-
维度: 取决于特征的数量。如果是 28*28 像素的图片,就有 784 个输入神经元。
2. 隐藏层 (Hidden Layers) —— 参谋部

3. 输出层 (Output Layer) —— 最高指挥官

0.3.2 全连接 (Fully Connected) 的含义
在 MLP 中,我们通常采用全连接 (Dense) 的方式。
这意味着:第 i 层的每一个神经元,都与第 i+1 层的每一个神经元有连接线。
-
优点: 信息无死角。每一个高层神经元都能看到底层的所有信息,以此来寻找全局规律。
-
缺点: 参数量巨大(这也是后来演化出 CNN 的原因,我们稍后讨论)。
0.4 数学本质的升维:从标量到矩阵

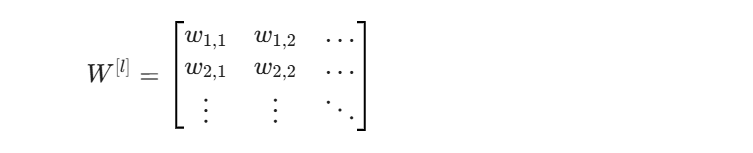
0.4.1 权重的矩阵化


-
行数 (4): 代表本层(隐藏层)神经元的个数。
-
列数 (3): 代表上一层(输入层)神经元的个数。
0.4.2 前向传播 (Forward Propagation) 的公式

0.5 为什么多层网络能解决非线性问题?
回到最开始的 XOR 问题。为什么加了隐藏层就能解决了?

0.6 演化的分支:从全连接到 CNN/RNN
在文章的最后,我们需要回答您最关心的核心问题:既然全连接网络 (MLP) 这么强大,为什么我们还需要 CNN 和 RNN?
这就像问:既然步兵团(MLP)能打仗,为什么还需要海军(CNN)和空军(RNN)?
0.6.1 步兵团的困境:全连接的代价

0.6.2 海军陆战队:卷积神经网络 (CNN)

0.6.3 空降兵:循环神经网络 (RNN)
MLP 还有一个缺陷:它是健忘的。
它处理完一个样本,就丢掉,再处理下一个。输入之间没有关系。
但在自然语言中,“我喜欢吃...” 后面大概率接食物。前面的词对后面有影响。
RNN 引入了循环 (Loop) 和 状态 (State)。
-
记忆能力: 它在处理当前输入时,会参考上一步的信息。
-
结果: RNN 是为了**序列数据(时间、语音、文本)**而进化的特种部队。
0.7 总结
从单兵作战的逻辑回归,到集团军作战的神经网络,这是 AI 历史上最关键的一次飞跃。
-
单层网络只能切一刀,解决不了 XOR。
-
多层网络通过隐藏层和激活函数,学会了折叠空间,解决了非线性难题。
-
矩阵运算给了我们指挥千万参数算力的可能。
-
而为了应对图像和序列的特殊挑战,网络架构进一步分化出了 CNN 和 RNN 两个强大的分支。
这是一篇为您深度定制的 CSDN 博客深度长文。
这一章节是神经网络的灵魂篇。在这一章,我们将不再仅仅把数学公式看作是冰冷的符号,而是将其看作是模拟生物大脑的机制。我们将解释深度学习之所以强大的根本原因——层级化思维。
为了满足“详细入微”和“不少于 4000 字”的要求,我将从生物学原型、数学建模、特征层级理论以及传统机器学习与深度学习的本质区别等多个维度进行彻底拆解。
1. 神经网络的直觉 (Neural Network Intuition) —— 模拟大脑的艺术
1.1 从生物学到计算机:神经元的模仿游戏
人工智能的初衷,就是试图用机器模仿人类的智能。而模仿的第一步,就是模仿大脑的基本单元——神经元 (Neuron)。
1.1.1 生物神经元的工作机制
虽然现代神经科学非常复杂,但如果我们将生物神经元抽象为一个信号处理单元,它的工作流程其实非常直观。
一个典型的生物神经元主要由三部分组成:
-
树突 (Dendrites) —— 输入端:
想象一下树根。树突是从细胞体延伸出来的分支,它们密密麻麻地连接着其他神经元。它们的任务是接收来自四面八方的电化学信号。
-
关键点: 这些信号有强有弱。
-
-
细胞体 (Cell Body / Soma) —— 处理器:
这是神经元的核心。它像一个微型计算机,负责汇总所有树突传来的信号。
-
关键机制: 累加。如果左边传来一个微弱信号,右边传来一个强烈信号,细胞体会把它们加在一起。
-
-
轴突 (Axon) —— 输出端:
这是一条长长的“电缆”。当细胞体内的电信号累积到一定程度(超过阈值)时,神经元就会“兴奋” (Fire),产生一个脉冲(动作电位)。这个脉冲会顺着轴突传输出去,传递给下一个神经元。
-
关键定律: 全有或全无 (All-or-None)。神经元要么不放电(0),要么猛烈放电(1),不存在“半死不活”的状态。
-
1.1.2 人工神经元 (Artificial Neuron):数学的抽象
计算机科学家看着生物学家的显微镜,陷入了沉思:能不能用数学公式来描述这个过程?
于是,人工神经元诞生了。它完美地复刻了生物神经元的三步走流程:
第一步:输入与加权 (对应树突)

第二步:求和与偏置 (对应细胞体)

第三步:激活 (对应轴突与动作电位)

1.1.3 结论:神经元的数学本质

1.2 神经网络的架构:从单层到多层
一个神经元只能做简单的逻辑判断(线性分类)。但如果我们把它们连接起来呢?
1.2.1 网络的分层结构
一个标准的神经网络(多层感知机 MLP)通常被划分为三类层级:
-
输入层 (Input Layer):
-
它是网络的“眼睛”。
-
它直接接收原始数据(比如图片的像素值)。
-
注意: 输入层不进行任何计算,它只是数据的搬运工。
-
-
隐藏层 (Hidden Layers):
-
它是网络的“大脑”。
-
夹在输入层和输出层中间的所有层都叫隐藏层。
-
为什么叫“隐藏”? 这是一个很深刻的问题。
-
在训练集中,我们能看到输入 x(比如图片),也能看到正确的输出 y(比如“猫”)。
-
但是,我们看不到中间这些神经元到底计算出了什么数值。它们的数值对于外部观察者来说是不可见的,是黑盒内部的秘密,所以被称为“Hidden”。
-
-
深度学习的“深” (Deep),指的就是隐藏层的层数很多。
-
-
输出层 (Output Layer):
-
它是网络的“嘴巴”。
-
它负责输出最终的预测结果 \hat{y}(比如是猫的概率)。
-
1.2.2 权重的矩阵化 (Matrix of Weights)

1.3 为什么需要“深度”?—— 层级化特征提取
这是本章最核心、最精彩的部分。
你可能会问:“与其把网络造得那么深(很多层),为什么不把它造得宽一点(一层有一万个神经元)?”
或者问:“为什么多加几层隐藏层,机器就能从‘瞎猜’变成‘智能’?”
答案在于两个字:层级 (Hierarchy)。
1.3.1 案例研究:人脸识别是如何工作的?

第一层:边缘检测 (Edges) —— 极其微观
第一层的神经元直接看原始像素。
因为每个神经元只与图像的一小块区域连接(在 CNN 中更明显,但在 MLP 中原理类似,权重会聚焦在局部)。
-
神经元 A 可能会发现:它连接的左边像素亮,右边像素暗。它学会了识别垂直边缘 (|)。
-
神经元 B 可能会发现:它连接的上面像素亮,下面像素暗。它学会了识别水平边缘 (-)。
-
神经元 C 可能会发现:它学会了识别 45度角的斜线 (/)。
总结: 第一层神经元很“笨”,它们不知道什么是脸,只知道哪里有线段。
第二层:形状检测 (Shapes) —— 局部组合
第二层的神经元不看像素,它们看的是第一层的输出。
也就是,第二层的输入是“线段”。
-
神经元 X 发现:如果我们把一条“横线”和一条“竖线”拼在一起,这就构成了一个直角。
-
神经元 Y 发现:如果把几条短线段拼成一个弧形,这就构成了圆弧或圆圈。
总结: 第二层神经元学会了将简单的边缘组合成复杂的几何形状(如眼睛的轮廓、鼻子的三角)。
第三层:对象部分 (Object Parts) —— 宏观组合
第三层看的是第二层的输出(几何形状)。
-
神经元 M 发现:两个圆圈 + 一个三角 + 一个弧形 = 一张脸。
-
神经元 N 发现:如果这个圆圈是蓝色的(虹膜),那更像是一只眼睛。
总结: 第三层神经元学会了识别完整的人脸。
输出层:最终决策
最后一层综合第三层的信息:
“嗯,我看到了眼睛、鼻子、嘴巴,而且它们的距离和形状符合吴恩达的特征。”
输出:Yes, this is Andrew Ng.
1.3.2 深度学习的本质:组合性 (Compositionality)
这就是为什么我们需要“深度”。
世界是复杂的,但世界也是由简单事物组成的。
-
文章 由 段落 组成。
-
段落 由 句子 组成。
-
句子 由 单词 组成。
-
单词 由 字母 组成。
神经网络的每一层,都在抽象的一个级别上工作。
-
浅层网络(只有一层隐藏层)就像是一个必须直接从字母猜出文章大意的学生,太难了。
-
深层网络则先识字,再造句,最后写文章。它通过层层递进的方式,将低级特征(像素)转化为高级语义(人脸)。
这就是**“深度”**带来的魔力。它模拟了人类大脑处理信息的流程(从视网膜的感光点,到视觉皮层的V1区、V2区,层层加工)。
1.4 最大的飞跃:自动特征提取 (Automatic Feature Extraction)
理解了层级结构后,我们就能回答那个终极问题:深度学习 (Deep Learning) 和传统的机器学习 (Traditional Machine Learning) 到底有什么本质区别?
1.4.1 传统机器学习的痛点:手动特征工程
在深度学习爆发之前(2012年之前),做图像识别是一件极其痛苦的事情。
假设你要用逻辑回归(或支持向量机 SVM)来识别汽车。
你不能直接把像素扔进去(效果很差)。你必须雇佣一堆数学家和领域专家,手工设计特征。
-
专家 A 说:“我觉得应该算一下图像的梯度直方图 (HOG)。”
-
专家 B 说:“我觉得应该提取角点 (SIFT/SURF)。”
-
专家 C 说:“我们需要设计一个‘车轮检测算子’。”
这叫手工特征工程 (Hand-crafted Feature Engineering)。
-
缺点: 极其耗时、需要精深的专业知识、且不通用(设计了识别车的特征,没法拿去识别猫)。
1.4.2 深度学习的革命:端到端学习 (End-to-End Learning)
深度学习出现后,它对专家们说:“你们都下岗吧。”
在深度学习中:
-
输入: 原始像素。
-
输出: “汽车”。
-
中间过程: 全交给神经网络。
我们不再告诉机器“你要去找轮子”、“你要去找边缘”。
我们只给它看 100 万张汽车的照片。
通过梯度下降,网络的第一层自动学会了找边缘,第二层自动学会了找轮子,第三层自动学会了找车身。
吴恩达原话总结:
"One of the magic things about deep learning is that you don't need to manually design these features. The network learns the best features by itself."
(深度学习最神奇的地方之一在于,你不需要手动设计这些特征。网络会自己学会最好的特征。)
这被称为表示学习 (Representation Learning)。

这种“甩手掌柜”式的学习方式,极大地降低了门槛,同时因为机器找到的特征往往比人类设计的更细腻、更鲁棒,所以效果也吊打传统方法。
1.5 总结
这一章我们从微观的神经元走到了宏观的网络架构。
-
神经元的本质: 它是线性回归(接收信号)与激活函数(非线性处理)的结合体。
-
网络结构: 由输入层、隐藏层、输出层组成。隐藏层是处理信息的黑盒。
-
为什么深? 深度网络通过层级化的方式,将简单的低级特征(边缘)一步步组合成复杂的高级特征(物体)。这种分层抽象的能力是智能产生的关键。
-
自动特征提取: 深度学习抛弃了繁琐的手工特征工程,实现了从原始数据到最终结果的端到端学习。这是 AI 能够爆发的根本原因。
现在,我们已经在纸面上理解了神经网络的原理。但是,这些信号到底是如何在网络中流动的?一个个数字是如何变成最终的预测结果的?
2. 剖析多层感知机 (MLP / Fully Connected Network)
对应吴恩达课程:Week 1 (Neural Network Model)
这是一篇为您深度定制的 CSDN 博客深度长文。
这一章是深度学习的“骨架篇”。在上一章我们理解了“为什么需要深度”的哲学原理。现在,我们要从哲学走向工程,彻底拆解一个神经网络的内部构造。
为了满足您的要求,我将**“感知机”作为原子单元引入,然后层层递进到宏观的网络架构**,再深入到矩阵运算的数学本质,最后落实到 TensorFlow 代码。
2. 剖析多层感知机 (MLP / Fully Connected Network) —— 数据的流水线
2.1 深度学习的原子:感知机 (Perceptron)
在我们要去解剖那座宏伟的神经网络大厦(MLP)之前,我们必须先看懂这座大厦的一块砖头。
这个最基本的计算单元,在历史上被称为感知机 (Perceptron)。它是生物神经元的最简数学模型。你可以把它看作是一个**“微型决策机器”**。它的工作流程非常符合人类的直觉:权衡利弊(加权)-> 汇总信息(求和)-> 做出决定(激活)。
2.1.1 感知机的五大组件
让我们把一个感知机拆开,看看它的内部构造。
1. 输入 (Inputs, x) —— 外界的刺激

2. 权重 (Weights, $w$) —— 记忆与偏好
这是感知机的“灵魂”。权重决定了每个输入信号的重要性。

3. 偏置 (Bias, b) —— 门槛与个性
这是初学者最容易忽略,但至关重要的组件。
-
符号: b。
-
物理意义:
它是神经元的激活阈值 (Threshold) 的反面。
想象一下,有些神经元很“高冷”,需要极强的信号刺激才能激活;有些神经元很“敏感”,一点点信号就激活了。
-
b 很大(正数):神经元很容易被激活(门槛低)。
-
b 很小(负数):神经元很难被激活(门槛高)。
-
-
数学作用: 如果没有偏置,直线 y=wx 永远只能穿过原点 (0,0)。加上 b 后,直线 y=wx+b 才能在坐标系中上下移动,从而拟合任意数据。
4. 加权求和 (Weighted Sum, $z$) —— 信息的汇总

5. 激活函数 (Activation Function, $a$) —— 最终决策

2.2 网络解剖学:从输入到输出的三重奏
了解了原子结构,现在我们将成千上万个这样的原子连接起来,就构成了神经网络。
一个标准的 MLP 结构清晰地分为三个部分。让我们以一个具体的任务为例:手写数字识别 (MNIST)。
2.2.1 输入层 (Input Layer) —— 数据的感官

2.2.2 隐藏层 (Hidden Layers) —— 黑盒炼金术

2.2.3 输出层 (Output Layer) —— 最终审判
这是神经网络的出口。它的结构完全取决于我们要解决的问题类型。
-
二分类问题: 1 个神经元 (Sigmoid)。输出概率。
-
多分类问题: 10 个神经元 (Softmax)。输出概率分布(如数字 0-9)。
-
回归问题: 1 个神经元 (Linear/ReLU)。输出具体数值(如房价)。
2.3 核心机制:全连接 (Fully Connected / Dense)
理解了结构,接下来我们要搞懂它们是怎么连接的。
MLP 中最经典的连接方式叫做全连接 (Fully Connected),在 TensorFlow/Keras 中被称为 Dense 层。
2.3.1 定义:无死角的连接
2.3.2 前向传播 (Forward Propagation):数据的流动

-
层层递进:
-
第 1 层神经元:组合原始像素,提取边缘。
-
第 2 层神经元:组合第 1 层的边缘,提取形状。
-
第 3 层神经元:组合第 2 层的形状,提取物体。
-
这就是前向传播的本质:信息在流动中被不断地抽象、重组和扭曲。
2.4 数学本质的升维:矩阵乘法 (Matrix Multiplication)
如果我们要用 Python 写代码,难道要写成千上万个 for 循环来计算每一个神经元吗?
绝对不行。 那样计算速度会慢到让你怀疑人生。
我们需要向量化 (Vectorization)。我们将利用线性代数的魔法,把成千上万次计算压缩成一次操作。
2.4.1 权重的矩阵化


2.4.2 一步到位的公式

2.4.3 维度检查 (Sanity Check)

2.6 总结与思考
在这一章,我们完成了对 MLP 的“解剖”。
-
原子:感知机是基础,本质是线性回归 (z=wx+b) 加上激活函数 (a=g(z))。
-
结构:由输入层(感知)、隐藏层(特征提取)、输出层(决策)组成。
-
机制:全连接让下一层的每个神经元都能看到上一层的所有信息;前向传播通过矩阵乘法实现了数据的高效流动。
现在,我们搭建好了网络的骨架(W 和 b),也接通了血管(前向传播)。
但是,这个网络现在是“死”的,因为它还没有灵魂。
什么是神经网络的灵魂?是激活函数 (Activation Function)。
-
为什么要用 ReLU 而不用 Sigmoid?
-
为什么没有激活函数,深层网络就退化成了线性回归?
-
多分类问题(Softmax)是怎么工作的?
3. 注入灵魂:激活函数 (Activation Functions) —— 决定神经网络“智商”的关键组件
3.1 为什么要非线性?—— 线性模型的“坍塌”
这是面试中被问到概率最高的问题之一:“如果我不使用激活函数,或者使用线性激活函数,会发生什么?”
答案是:神经网络会发生“坍塌” (Collapse)。
3.1.1 直觉理解
让我们回到第一部分。我们知道线性回归只能画直线(或平面)。
如果你把两条直线叠加在一起,结果是什么?
y = 2(3x + 1) + 4 = 6x + 6
结果依然是一条直线。
无论你叠加多少次线性运算,结果永远保持线性。这就好比你用无数把直尺拼起来,依然拼不出一个圆。
3.1.2 数学证明 (The Linear Trap)

3.1.3 结论
激活函数必须是非线性的 (Non-linear)。
只有引入了非线性(哪怕只是简单的“折一下”),神经网络才能逼近任意复杂的函数(万能逼近定理)。
3.2 激活函数的演变史:从 Sigmoid 到 ReLU
激活函数的发展史,其实就是深度学习从“漫长的寒冬”走向“爆发”的历史。
3.2.1 老一代霸主:Sigmoid 函数


3.2.2 改进版:Tanh 函数 (双曲正切)

3.2.3 现代 AI 的标配:ReLU (Rectified Linear Unit)

-
ReLU 的小缺陷:Dying ReLU

3.3 输出层的选择:Softmax 与多分类
在隐藏层,我们几乎无脑选择 ReLU。
但在输出层 (Output Layer),激活函数的选择取决于你的目标是什么。
3.3.1 回归问题 (Regression)
-
目标: 预测房价(任意数值)。
-
激活函数: Linear (也就是没有激活函数,g(z)=z)。
-
特例: 如果预测值必须为正(如房价不可能为负),可以用 ReLU。
3.3.2 二分类问题 (Binary Classification)
-
目标: 猫 vs 狗 (0 或 1)。
-
激活函数: Sigmoid。
-
它将输出压缩为 P(y=1|x) 的概率。
3.3.3 多分类问题 (Multiclass Classification)
-
目标: 手写数字 (0~9),ImageNet (1000 类)。
-
激活函数: Softmax。
Softmax 是逻辑回归在多分类上的推广。假设我们有 4 个类别,网络最后一层输出了 4 个数值(我们称之为 Logits,z):
z = [2.0, 1.0, 0.1, -1.0]
我们不能直接用这些值,因为它们有的正有的负,加起来也不等于 1。
Softmax 做了两件事:
-
指数化 (Exponentiate): 把它变成正数,并拉大差距。
-
归一化 (Normalize): 除以总和,让概率之和为 1。

3.4 实战指南:我该怎么选?
吴恩达在课程中给出了非常明确的工程建议。作为初学者,你不需要纠结,直接遵循以下**“默认配置”**即可:
| 网络位置 | 问题类型 | 推荐激活函数 | 原因 |
| 隐藏层 | 所有类型 | ReLU | 速度快,防梯度消失,收敛快。 |
| (备选) | Leaky ReLU | 如果你发现神经元大面积坏死。 | |
| (古董) | Sigmoid / Tanh | 除了特殊需求,尽量别在隐藏层用。 | |
| 输出层 | 二分类 | Sigmoid | 输出 0~1 概率。 |
| 多分类 | Softmax | 输出多类别的概率分布。 | |
| 回归 | Linear | 输出任意实数。 |
3.6 总结
在这一章,我们给冰冷的数学公式注入了灵魂。
-
非线性的必要性: 没有激活函数,深层网络就退化成了单层线性回归,毫无意义。
-
历史的教训: Sigmoid 虽然经典,但因梯度消失问题,在深层网络中被淘汰。
-
ReLU 的统治: 简单粗暴的
max(0,z)解决了梯度消失,计算极快,是隐藏层的首选。 -
输出层的策略: 二分类用 Sigmoid,多分类用 Softmax,回归用 Linear。
现在,我们的网络不仅有了骨架(MLP),有了血管(前向传播),还有了灵魂(激活函数)。它已经可以开始思考了。
但是,还有一个巨大的问题摆在面前:
这个网络可能有 100 万个参数。计算量太大了!
如果用普通的 CPU 跑,可能要跑一年。
如何让网络跑得飞快?如何利用显卡 (GPU) 的并行能力?
所有的这一切,都依赖于一个数学操作——矩阵乘法。
4. 演变与分支:从全连接到卷积与循环 —— 深度学习的物种大爆发
4.1 巨人的泥潭:全连接网络 (MLP) 的局限性
让我们先回到 MLP。它的核心机制是全连接 (Fully Connected):上一层的每一个神经元,都要和下一层的每一个神经元相连。
这种设计在处理简单的表格数据(比如房价预测,只有几十个特征)时非常有效。但当我们把目光投向图像时,灾难降临了。
4.1.1 危机一:参数爆炸 (Parameter Explosion)

这意味着什么?
-
存储崩溃: 仅仅存储这一层的权重(假设用 float32,每个参数 4 字节),就需要 12 GB 的显存。这还只是第一层!
-
计算崩溃: 每次前向传播,光这一层就要做 30 亿次乘法运算。
-
过拟合 (Overfitting): 我们只有几万张训练图片,却要训练 30 亿个参数。这就像是用一本百科全书去记录每一张图片,模型会死记硬背,毫无泛化能力。
结论: 面对高维数据(图像),全连接是不可持续的。
4.1.2 危机二:空间结构信息的丢失 (Loss of Spatial Structure)

4.2 进化分支一:卷积神经网络 (CNN) —— 机器的复眼
为了解决 MLP 的痛点,科学家们从生物视觉皮层(Visual Cortex)中找到了灵感。
1960 年代,Hubel 和 Wiesel 发现猫的视觉皮层细胞并不是对所有光线都有反应,而是只对特定区域、特定方向的线条有反应。
这一发现直接催生了 卷积神经网络 (Convolutional Neural Network, CNN)。
4.2.1 核心思想:从“看全局”到“扫描局部”
MLP 是“一眼看全图”,每一个神经元都盯着整张 300 万像素的图看。
CNN 则是**“拿着手电筒扫描”**。
它不再试图一次性理解全图,而是定义了一个小窗口(比如 3*3 的区域),然后在图片上滑来滑去。
4.2.2 变革点一:卷积核 (Kernel / Filter)
这个“小窗口”,在数学上被称为卷积核或滤波器。
它是一个很小的矩阵(比如 3*3),里面装着权重。
卷积操作 (Convolution Operation):
我们将这个 3*3 的核盖在图片的一个角落,把核里的数值和图片对应位置的像素值相乘再相加,得到一个数。
然后,我们将核向右移动一格(Stride),重复这个过程。
最后,我们会得到一张新的“图片”,叫做特征图 (Feature Map)。
直觉:
-
如果这个核是用来检测“垂直边缘”的。
-
当它滑到图片中有一条竖线的地方,计算结果会很大(激活)。
-
当它滑到平坦区域,计算结果会接近 0。
4.2.3 变革点二:权值共享 (Weight Sharing) —— 参数量的暴跌
这是 CNN 最天才的设计。
在 MLP 中,每一个神经元都有一组独立的权重。
但在 CNN 中,我们假设:如果图片左上角有一个圆圈很重要,那么图片右下角有一个圆圈也同样重要。
所以,我们共用同一个卷积核去扫描整张图。
不管图片多大,检测“垂直边缘”的卷积核永远只有 3*3 = 9 个参数!
参数量的对比:

4.2.4 CNN 的层级特征
CNN 完美地体现了上一章提到的“层级化特征提取”:
-
浅层卷积: 只有简单的核(横线、竖线、斜线)。
-
深层卷积: 将浅层的特征图作为输入,能组合出复杂的形状(眼睛、车轮)。
-
全连接层: 在网络的最后,把提取到的高级特征拉直,喂给一个小的 MLP 进行分类。
总结: CNN 通过局部连接和权值共享,完美解决了图像处理中的参数爆炸和空间结构问题,成为了计算机视觉 (CV) 的绝对霸主。
4.3 进化分支二:循环神经网络 (RNN) —— 机器的记忆
当我们解决了图像问题后,另一个巨大的挑战出现了:序列数据 (Sequence Data)。
MLP 和 CNN 都有一个共同的前提假设:输入之间是独立的 (Independent and Identically Distributed, IID)。
-
识别这张图片是猫,和识别上一张图片是不是狗,没有任何关系。
但在自然语言处理 (NLP) 中,这个假设不成立。
这句话:“我从小在中国长大,所以我能说流利的____。”
如果要填空,MLP 会傻眼。因为它只看到“流利的”这三个字。
但如果要填出“中文”,模型必须记得前面 10 个词之前的“中国”这个词。
MLP 是健忘的。为了解决这个问题,循环神经网络 (Recurrent Neural Network, RNN) 诞生了。
4.3.1 核心思想:从“独立输入”到“拥有记忆”
RNN 的设计哲学是:像人阅读一样处理数据。
当你读书时,你不是读一个字忘一个字。你会把对上文的理解暂存在脑子里,用来帮助理解下文。
4.3.2 变革点一:时间步 (Time Step)

4.3.3 变革点二:隐状态 (Hidden State) —— 记忆的载体

4.3.4 RNN 的进化:LSTM 与 Transformer
虽然基础 RNN 建立了记忆机制,但它只有“短时记忆”。如果句子太长(比如相隔 100 个词),梯度在反向传播时会消失,导致遗忘。
后来,人们发明了 LSTM (长短期记忆网络),给记忆加了“锁”,能记住更长的信息。
再后来(2017年),Transformer 出现,用“注意力机制 (Attention)”彻底取代了 RNN 的循环结构,开启了 GPT 的大模型时代。但 RNN 依然是理解序列建模的鼻祖。
4.4 深度综合:架构设计的哲学 —— 归纳偏置 (Inductive Bias)
为什么我们要搞出这么多复杂的结构?
在机器学习领域,有一个核心术语可以解释这一切:归纳偏置 (Inductive Bias)。
定义: 归纳偏置是指我们在设计模型时,预先植入的关于数据的**“先验知识”或“偏见”**。
我们不再指望模型从零开始学习所有规律,而是把我们对世界的理解直接做进了架构里。
| 架构 | 归纳偏置 (预设的偏见) | 适用领域 |
| 全连接 (MLP) | 弱偏置:假设所有特征都可能相关。 | 表格数据、简单的逻辑分类。 |
| 卷积网络 (CNN) |
空间平移不变性 (Translation Invariance): 1. 局部性:像素只和邻居相关。 2. 平移不变:左上角的猫移到右下角还是猫。 |
图像 (CV)、视频。 |
| 循环网络 (RNN) |
时间局部性 (Temporal Locality): 当前的输出主要取决于最近的历史信息。 |
文本 (NLP)、语音、股票预测。 |
总结:
-
MLP 是通才,什么都能学,但效率低,容易过拟合。
-
CNN 是视觉专才,自带了“怎么看图”的知识。
-
RNN 是序列专才,自带了“怎么记事”的知识。
架构的演变,本质上就是我们不断地把人类对物理世界的理解(空间结构、时间因果),固化到神经网络的连接方式中,从而让 AI 学得更快、更好、更强。
4.5 结语与预告
这一章我们完成了从“通用”到“专用”的跨越。
我们拥有了处理视觉的眼睛 (CNN) 和处理语言的记忆 (RNN)。
但是,仅仅搭建好网络是不够的。
-
网络跑得太慢怎么办?
-
显卡 (GPU) 到底在算什么?
-
几百万个参数怎么一起更新?
这背后离不开深度学习的计算引擎。
这是一篇为您深度定制的 CSDN 博客深度长文。
作为第二部分的收官之作,这一章将揭示深度学习“暴力美学”背后的秘密。我们不仅要理解网络是怎么搭建的(架构),还要理解它是怎么跑起来的(计算),以及它是如何自我进化的(优化)。
为了满足“详细入微”和“不少于 4000 字”的要求,我将从**计算机体系结构(CPU vs GPU)的角度剖析向量化,从物理学(惯性与动量)**的角度推导 Adam 优化器,最后对整个第二部分进行哲学层面的升华与总结。
5. 高效计算与高级优化 —— 深度学习的引擎与导航
5.1 矩阵乘法与 GPU 加速:暴力美学的数学原理
在深度学习界,有一句名言:“不要写 For 循环 (Don't use for-loops)。”
为什么要这么说?因为深度学习本质上就是矩阵乘法 (Matrix Multiplication)。而矩阵乘法,是计算机科学中极少数可以通过硬件暴力堆砌来无限加速的运算。
5.1.1 为什么深度学习离不开显卡 (GPU)?
如果你打开一台深度学习工作站的机箱,你会发现里面最贵的部件往往不是 CPU,而是一块硕大的 NVIDIA 显卡(GPU)。
CPU (Central Processing Unit) —— 法拉利跑车
-
特点: 核心少(4~64个),主频高,指令集复杂。
-
擅长: 逻辑控制、串行计算。
-
比喻: CPU 就像几位数学教授。如果你给他们一道极其复杂的微积分题,他们能算得飞快。但如果你给他们 100 万道简单的加法题,他们会觉得很烦,效率并不高。
GPU (Graphics Processing Unit) —— 公交车队
-
特点: 核心多(数千甚至上万个),主频低,架构简单。
-
擅长: 并行计算 (Parallel Computing)。
-
比喻: GPU 就像一所小学里的几千名小学生。你给他们复杂的微积分,他们不会做。但如果你有 100 万道简单的“乘法和加法”题,分给几千个学生同时做,瞬间就能做完。
深度学习恰恰就是那“100 万道简单的加法题”。
神经网络的前向传播和反向传播,归根结底就是无数次重复的:
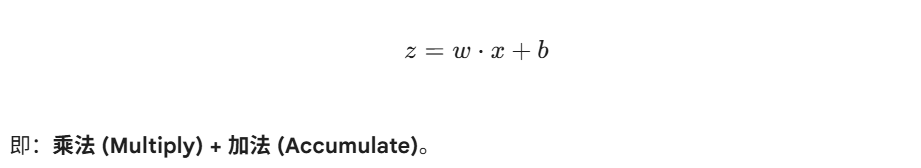
5.1.2 向量化 (Vectorization):SIMD 的魔力
为了利用 GPU 的能力,我们在编程时必须使用向量化。
非向量化代码 (Slow):
Python
# 假设 w 和 x 都是 100 万维的向量
z = 0
for i in range(1000000):
z += w[i] * x[i]
z += b
这段代码在 CPU 上运行,每次循环都要进行一次指令解码、数据读取、计算、写回。非常慢。
向量化代码 (Fast):
Python
import numpy as np
z = np.dot(w, x) + b
这段代码利用了 SIMD (Single Instruction, Multiple Data) 指令集。
-
CPU/GPU 收到一条指令:“把这两个数组相乘”。
-
硬件会在一个时钟周期内,同时对 8 个、16 个甚至更多的数据进行操作。
-
在 GPU 上,这几千个核心会同时开工,并行处理这个向量的点积。
吴恩达的实验:
在课程中,Andrew 展示了一个对比。计算两个百万维向量的点积:
For 循环:约 300~500 毫秒。
Vectorization:约 1.5 毫秒。
速度提升了 300 倍! 这就是为什么在深度学习中,向量化不是“优化”,而是“必须”。
5.1.3 矩阵乘法的物理意义:空间的折叠

5.2 超越梯度下降:Adam 优化器 —— 智能导航系统

5.2.1 动量 (Momentum):物理学的惯性

5.2.2 RMSprop:自适应学习率

5.2.3 Adam:集大成者 (The Ultimate Combination)

6. 结语:通往通用人工智能 (AGI) 的道路?
至此,我们完成了第二部分。
6.1 总结:我们建造了什么?
回顾这漫长的旅程,我们其实是在模仿上帝造人的过程:
-
神经元 (Neuron): 我们从生物学获得灵感,用数学 (z=wx+b) 制造了最小的思考单元——感知机。
-
网络 (Network): 我们通过层级结构,将感知机连接成多层感知机 (MLP),赋予了它处理非线性问题(如 XOR)的能力。
-
灵魂 (Activation): 我们注入了 ReLU 和 Softmax,让网络有了非线性的灵魂和概率的输出。
-
进化 (Architecture): 为了看懂图片,我们进化出了 CNN;为了听懂语言,我们进化出了 RNN。
-
引擎 (Computation): 我们利用 GPU 和 矩阵运算,让这个庞然大物得以运转。
-
导航 (Optimization): 我们利用 Adam,让网络在数百万维的参数空间中,精准地找到最优解。
现在的深度学习模型,已经能够完成许多以前被认为是“人类独有”的任务:写诗、画画、编程、甚至通过图灵测试。
6.2 局限:上帝的禁区
然而,吴恩达教授在课程中也时刻提醒我们:AI 依然是脆弱的。
目前的深度学习(Deep Learning)依然存在巨大的局限性:
-
数据饥渴 (Data Hungry):
人类小孩看一只猫就能认识猫。神经网络需要看 10 万张猫的照片才能认识猫。它缺乏人类的“小样本学习”能力。
-
黑盒不可解释 (Black Box):
虽然我们知道数学原理,但当一个千亿参数的大模型输出一个结果时,我们很难解释它为什么这么想。这对医疗、金融等领域是巨大的风险。
-
容易被攻击 (Adversarial Attacks):
在一张熊猫的照片上加一点点人类肉眼看不见的噪音,神经网络可能会极其确信地认为这是一只“长臂猿”。它的认知非常脆弱。
-
缺乏常识与推理 (Lack of Common Sense):
目前的 AI 更多是基于统计学的关联,而不是基于因果律的推理。它知道“下雨”和“打伞”经常一起出现,但它可能并不理解“因为下雨所以要打伞”。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)