草莓成熟度检测迎来公开数据集!YOLOv8/v9/v11同台竞技,最佳模型竟是它
本文核心贡献如下:
-
构建公开草莓成熟度数据集:首个包含566张图像、1,734个标注对象的多条件数据集,采集自土耳其两个温室不同光照环境,涵盖完全成熟、半熟、未熟三类。
-
系统对比YOLO多代模型:在统一实验条件下,全面评估YOLOv8、YOLOv9、YOLO11共15个变体的精度与计算效率。
-
揭示模型规模-性能关系:发现10-12M参数的中小模型性能最优,YOLOv8s达86.09% mAP@50,YOLOv9c精确率90.94%,YOLO11s召回率83.74%。
-
提供可重复性基准:为智慧农业成熟度检测建立参考框架,验证超大模型在有限数据集上性能饱和现象。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
-
YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
-
技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
-
荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
-
全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
-
具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原创自研系列, 26年计算机视觉顶会创新点
原创自研系列, 25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
0.原理介绍

论文:https://arxiv.org/pdf/2602.15656v2
摘要:草莓(Fragaria × ananassa)因其经济价值和丰富的营养价值而闻名于世,是一种被广泛种植的水果。在收获期确定正确的成熟度对于防止生产者损失和确保消费者获得优质产品至关重要。然而,传统方法(即仅靠视觉评估)可能具有主观性且误差率较高。因此,需要计算机辅助系统。然而,文献中缺乏可供所有人使用的全面数据集,这使得该领域的研究难以进行比较。在本研究中,向文献界提出了一个新的、公开的草莓成熟度数据集,该数据集包含在土耳其两个不同温室中于可变光照和环境条件下采集的566张图像和1,201个标注对象。使用基于YOLOv8、YOLOv9和YOLO11的模型对数据集进行的对比测试表明,YOLOv9c模型的最高精确率达到90.94%,而YOLO11s模型的最高召回率达到83.74%。就总体性能指标mAP@50而言,YOLOv8s模型表现最佳,成功率达到86.09%。结果表明,中小型模型在此类数据集上工作得更加平衡和高效,同时也为智能农业应用建立了基本的参考基准。
1. 引言
草莓是全球范围内具有高经济价值且被广泛消费的水果。如今商业化种植的草莓,最早于18世纪出现在欧洲,是由原产于北美的维珍尼亚草莓和原产于南美的智利草莓自然杂交衍化而来[1, 2]。最初在法国栽培,由于其果实大、香气浓郁且具有高产潜力,迅速从欧洲传播到美洲大陆,随后又传入亚洲。随着时间的推移,人们培育出了许多能够适应不同气候和生长条件的商业草莓品种[3]。
草莓富含营养,是健康饮食中最重要的食物之一。它不仅因其高维生素C含量、酚类化合物和抗氧化能力而成为支持免疫系统的水果,还因其膳食纤维含量对消化健康有重要益处[4, 5]。由于其营养特性,草莓对于鲜食和食品工业中的加工产品都具有很强的吸引力[6]。然而,草莓的物理结构和水分含量也给采后处理带来了重大挑战[7, 8]。特别是其非常短的货架期,使得在收获和销售过程中准确、一致地确定果实成熟度变得至关重要[9, 10]。
在正确的时间收获果实至关重要。如果果实在完全成熟前采摘,它无法发展出预期的香气;颜色不够鲜艳,营养价值也无法达到要求水平。另一方面,如果收获延迟,果实会过熟;这会增加在运输和储存过程中变质、碰伤和质量损失的风险。结果,不仅生产者和供应链面临经济损失,到达消费者手中的产品质量也会出现显著波动。审视全球草莓产量,中国、美国、墨西哥、土耳其和西班牙等国是主要生产国[11-13]。随着温室栽培的普及,温室内全年大量生产草莓,使得使用快速可靠的方法确定成熟度变得更加重要。
在传统种植过程中,草莓的成熟度是基于颜色、光泽和表面纹理等果实特征通过视觉观察来确定的。然而,这个评估过程是主观的,取决于评估人员的经验,因此无法提供标准的质量基准[14-16]。此外,在大型温室中人工检查数千个果实既耗时又增加了劳动力成本。长时间视觉评估会增加人为错误,而多变的光照条件和环境因素可能导致感知差异,从而引起产品质量不一致和营销过程中的重大经济损失。
在此背景下,自动、快速、客观地检测草莓成熟度已成为现代农业实践的重要研究课题[17, 18]。特别是,计算机视觉和基于深度学习的方法克服了基于人工观察的方法的局限性,实现了高精度[19, 20]。此外,草莓成熟度检测作为智慧农业系统框架内开发的机器人应用和自主采摘系统的关键组成部分脱颖而出。自主采摘机器人在正确的时间收获正确果实的能力直接取决于成熟度检测的准确性。因此,开发实时、高精度且计算高效的自动成熟度检测系统对于学术研究和工业应用都具有重要意义。
2. 相关工作
近年来计算机视觉和深度学习的进展显著加速了农业生产中自动化质量评估和成熟度检测的研究。针对草莓的研究围绕多种问题定义展开,具体如下:
(i) 成熟度检测,
(ii) 果实与茎的同时检测,
(iii) 基于分割的方法,
(iv) 收获时间预测,
(v) 物理缺陷与变形分析,
(vi) 适应多变和挑战性环境条件的模型。
然而,在所使用的模型架构、数据集和性能评估指标方面,文献中存在显著的方法论差异。
在处理田间环境成熟度检测问题的研究中,基于Transformer的架构表现突出。Zhao等人[21]提出了基于Transformer的FruitQuery模型,用于对草莓和桃子进行田间成熟度检测。该模型以1408万个参数实现了67.02%的AP值,优于YOLOv8、YOLOv9和YOLOv10模型。然而,对于小型和远处物体的精度下降,在实际温室条件下限制了其泛化能力。
Yang等人[22]提出了PDSE-DETR模型,用于检测温室环境中的草莓成熟度。PDSE-DETR在将参数和计算成本分别降低30.2%和30.7%的同时,将精度提高了2.1%。然而,所提模型的推理速度相较于其他基于YOLO的模型仍然较低。这些研究表明Transformer架构可以提高精度,但在速度-效率平衡方面仍有改进需求。
由于效率在实时应用中至关重要,文献中提出了基于YOLO的方法。Yu等人[23]提出了Ripe-Detection模型,用于复杂环境条件下的成熟度检测系统。作者实现了96.4%的mAP50,比YOLO模型提高了3.9%–13%。然而,有报告指出在复杂背景下容易产生误报。
Ma等人[24]提出了YOLOv11-GSF模型用于成熟度检测;与YOLOv11相比,该模型的AP提高了1.8%,精度提高了1.3%,召回率提高了2.1%。然而,尚未在动态田间条件下进行全面验证。
Wang等人[25]提出了一种基于YOLOv11的模型,用于开发实时腐烂果实检测和智能分拣系统,实现了83.6%的mAP;然而,仅使用RGB图像限制了早期低对比度缺陷的检测。
Jiang等人[26]提出了一种基于YOLOv11的模型和几何距离度量,用于评估草莓变形和对称性分析,实现了91.11%的精度和92.9%的AP50。他们报告称在密集种植区域需要进行实时性能优化。
分割和多阶段方法在文献中也扮演着重要角色。Crespo等人[27]使用TensorRT优化了Mask R-CNN模型,以提供适用于实时应用的高效分割,优化前实现了83.45%的mAP和4 FPS,优化后实现了83.17%的mAP和25.46 FPS。
Lin等人[28]开发了一个两阶段模型,用于预测草莓收获日期,在分割方面实现了0.977 mIoU,在收获时间预测方面实现了0.859的精度和F1分数。Sun等人[29]提出了SRR-Net模型,以抵抗可变光照条件下的成熟度预测,实现了0.037的MAE值,相比Mask R-CNN提升了超过70%;然而,该模型高度依赖于光强度归一化。
Wu等人[30]开发了一种半监督的SSEFNet模型以提高收获效率,在复杂数据集上实现了91.1%的精度;然而,该模型对高质量标注数据的依赖性限制了其泛化能力。
Nagaki等人[31]提出了一种基于EfficientNetV2的模型,用于基于排序预测成熟度;他们实现了R² = 0.84和0.83的总体精度,但依赖于评估者的一致性被认为是一个显著限制。
当综合评估表1中总结的研究时,出现了三个主要局限性:
(1) 大多数研究侧重于单一架构,并未在相同实验条件下系统比较不同的模型代际。
(2) 所使用的数据集大多是私有的且无法访问,这降低了可比性和可复现性。
(3) 虽然报告了精度指标,但并未全面分析计算成本、参数量和实时性能等应用关键标准。
本研究通过两种方式弥补了文献中的空白。首先,提供了一个公开可用的数据集,该数据集采集自两个不同的温室,并在不同光照条件下收集。其次,在相同的数据集和实验条件下评估了YOLOv8、YOLOv9和YOLO11架构;全面分析了精度指标以及计算成本。通过这种方式,既确保了方法论的一致性,也系统地揭示了草莓成熟度检测背景下的架构规模-性能关系。
3. 材料与方法
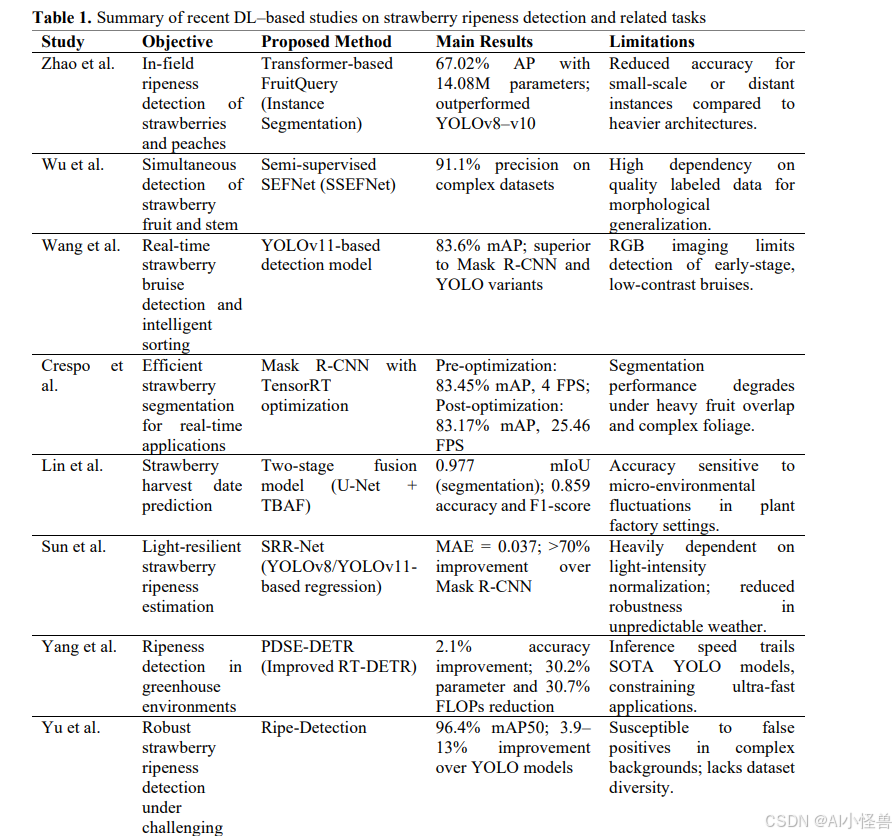
该研究设计了一个端到端的深度学习流程,用于草莓成熟度检测。该过程包括从两个不同温室采集图像、基于边界框的手动标注、将数据划分为训练集、验证集和测试集,以及在相同实验条件下训练YOLOv8、YOLOv9和YOLO11架构。使用准确性指标和计算效率指标对模型进行评估,并根据准确性-成本平衡确定最合适的模型。研究的实验流程如图1所示。
3.1. 数据集
本研究中使用的数据集由作者使用三星NX相机和手机相机创建,以反映不同的成像条件。图像采集自土耳其开塞利两个不同的温室。选择不同的温室确保了背景、密度、光照和栽培类型等因素能够在数据集中得到体现。

在数据采集过程中,图像是在一天中不同时间、不同的自然光照条件下拍摄的。考虑了直射阳光、部分遮阴和温室内漫射光等不同场景。
创建的数据集共包含566张图像。数据集分为两个子集:训练集和测试集。训练集有465张图像,测试集有101张图像。子集的分布信息如表2所示。

数据集共包含1,734个对象标注。图像根据三个不同的成熟度类别——完全成熟、半熟和未熟进行标注。各类别的图像分布详见表3。总共有520个完全成熟、247个半熟和967个未熟的草莓标注。

所有标注均使用边界框方法手动执行,并仔细检查了标注准确性。数据集中的示例图像如图2所示。此外,为提高研究的可复现性并为文献做出贡献,所创建的数据集已公开提供。
3.2. YOLO 模型
目标检测算法分为一阶段和两阶段方法[32]。在两阶段方法中,首先生成候选区域,然后对这些区域进行分类。虽然两阶段方法通常提供高精度,但由于其高计算成本,在实时应用中不受青睐[33]。另一方面,单阶段方法在单一步骤中预测对象位置和类别信息。它们工作速度更快,并且可以在相对较低的硬件要求下运行[33]。YOLO架构凭借其实时处理优势,在温室环境、露天应用和移动机器人系统等农业领域具有显著潜力。
YOLO系列自首次发布以来不断改进。在本研究中,对当前版本的YOLOv8、YOLOv9和YOLO11进行了对比测试。每个模型的基本架构特征总结如下。
YOLOv8
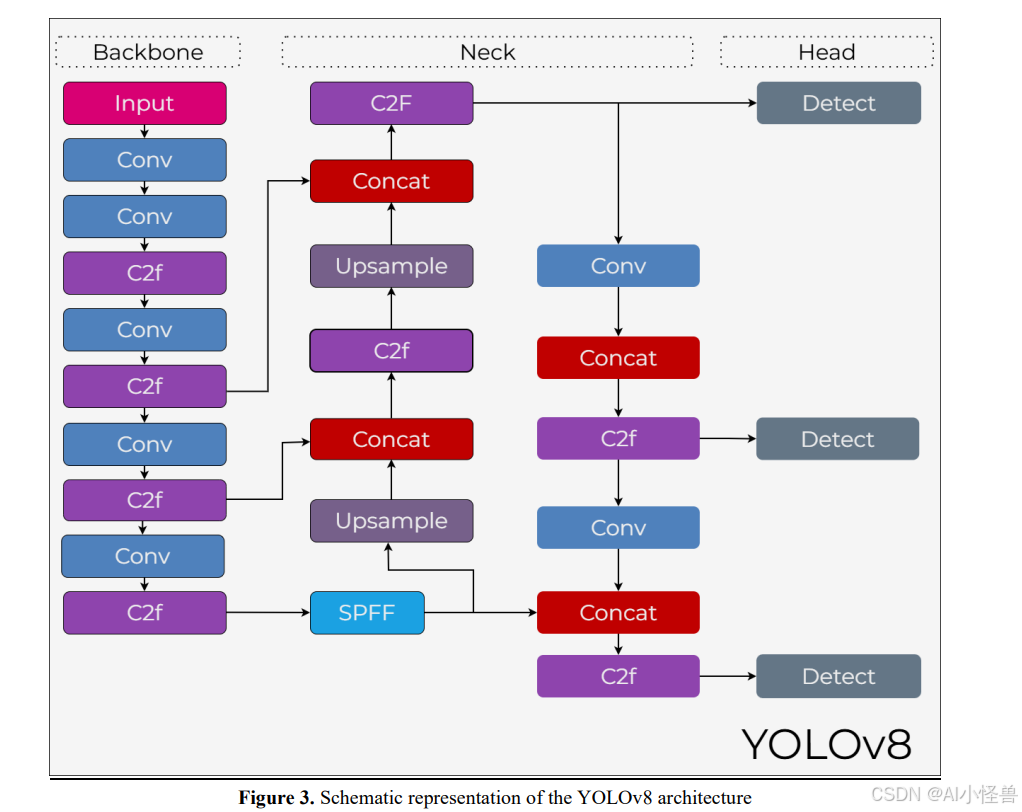
YOLOv8[34]架构基于骨干-颈部-检测头的范式构建,旨在相较于之前的YOLO版本具有更轻量、更模块化和更高效的结构。YOLOv8的架构图如图3所示。
在骨干阶段,输入图像通过连续的卷积层和C2f模块转换为多级特征图。与传统的基于CSP的结构相比,C2f模块提供了更高效的梯度流,增加了深层表示能力,同时提高了参数效率。位于骨干网络更深层的SPPF模块,通过组合不同感受野的池化操作来丰富上下文信息,并增加网络对小尺度和大尺度对象的敏感性。它允许在不增加额外计算负载的情况下将全局上下文信息集成到模型中。
在颈部阶段采用了类似于PANet的结构。在此阶段,通过上采样和拼接操作将来自上下层级的特征图结合起来。得益于多尺度特征融合,不同分辨率下的对象得到了更好的表示。颈部内使用的C2f模块确保了组合特征以具有判别性和高效的方式进行处理,同时保持较低的计算成本。
在检测头阶段,YOLOv8使用了无锚框检测范式,这不同于之前的YOLO版本。每个尺度生成的特征图被传递到单独的检测层,在那里通过回归直接获得类别概率和边界框预测[34]。
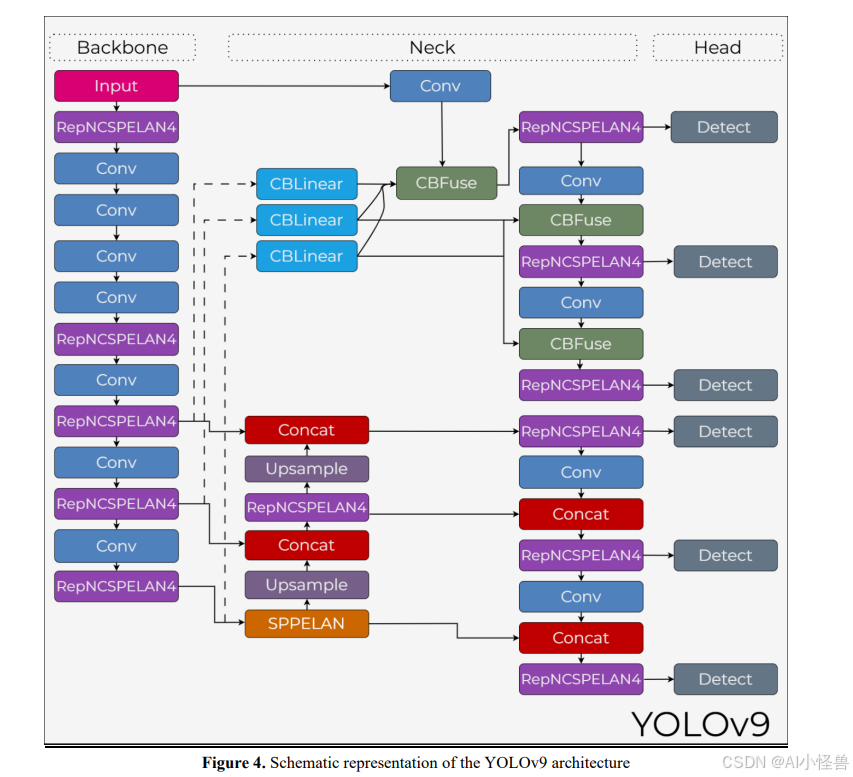
YOLOv9
YOLOv9[35]架构与YOLOv8一样基于骨干-颈部-检测头的区分。然而,它具有减少深层信息丢失和改善梯度流的组件。YOLOv9的架构结构如图4所示。
在骨干阶段,输入图像通过连续的卷积层和RepNCSPELAN4模块转换为多级特征表示。基于重参数化原理的RepNCSPELAN4块提供多分支表示,同时转换为单分支且更轻量的结构。位于骨干网络深层的SPPELAN模块,通过组合从不同感受野获得的空间信息来改善上下文表示。
当从骨干过渡到颈部阶段时,使用CBLinear层更有效地组合来自不同层级水平的特征,并平衡通道大小。
在颈部阶段,CBFuse模块,YOLOv9的特色组件之一,发挥着重要作用。CBFuse结构通过直接且选择性地合并不同分辨率的特征图,减少信息丢失并增加多尺度表示的有效性。在此阶段,通过上采样和拼接操作创建类似PAN的多尺度融合结构。RepNCSPELAN4块确保融合后的特征以计算高效且具有判别性的方式进行处理。
在检测头阶段,从不同尺度获得的特征图被馈送到多个检测层以执行多尺度目标检测[35]。
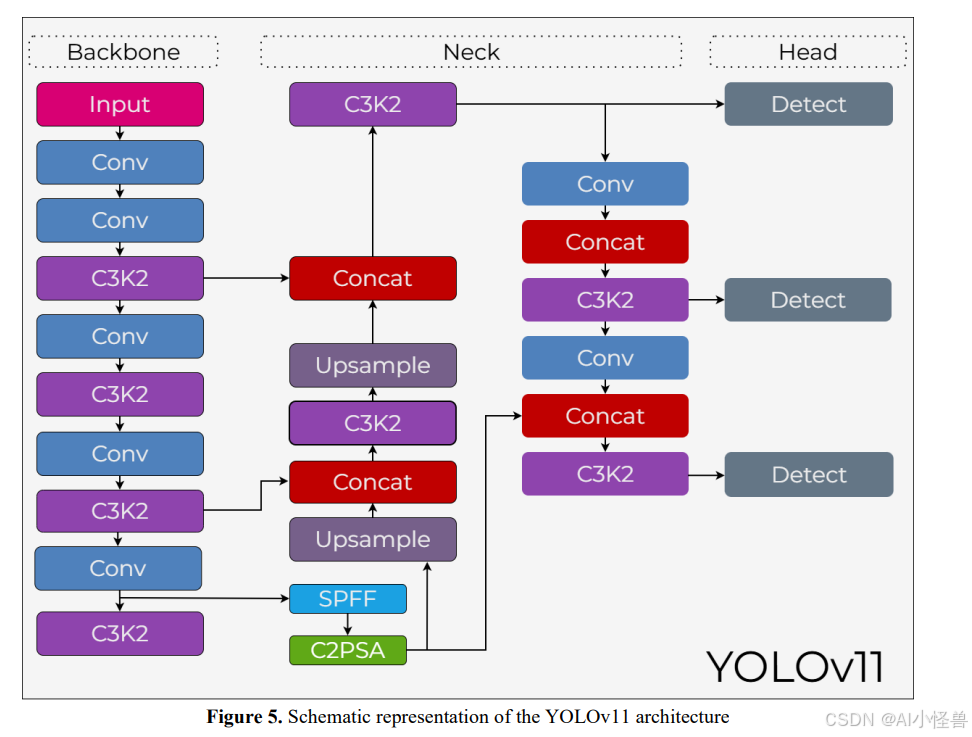
YOLOv11
YOLOv11[36]架构同样依赖于骨干-颈部-检测头结构。YOLOv11架构的示意图如图5所示。
在骨干阶段,输入图像通过连续的卷积层和优化的C3k2模块转换为多尺度特征图。与先前版本中使用的C2f结构相比,C3k2模块通过使用更小的卷积核减少了参数量。位于骨干网络的空间金字塔池化-快速模块,组合从不同感受野获得的上下文信息以提取全局特征。随后的并行空间注意力卷积模块使网络能够关注关键区域。
在颈部阶段,使用上采样和拼接操作将来自较低和较高层级的特征图组合起来。在颈部内重复使用的C3k2模块使得组合后的特征能够以低计算成本和高判别力进行处理。
在检测头阶段,在不同尺度生成的特征图被馈送到单独的检测层以执行多尺度目标检测。
最终,通过C3k2、SPPF和C2PSA模块的联合使用,YOLOv11呈现出一个可扩展且高效的架构。凭借这些特性,它为边缘设备和高性能GPU系统上的实时应用提供了一种模型[36]。
3.3. 评估指标
在本研究中,使用了不同的指标来评估基于YOLO的模型在准确性和计算效率方面的性能。精确率衡量模型的正面预测中有多少是正确的。召回率指示模型正确捕获了多少个真正的正例。
平均精度均值是计算所有类别的AP值的平均值。在本研究中,使用了IoU阈值为0.5时的mAP@50值。mAP是目标检测模型中广泛接受的基准。浮点运算数表示模型在预测期间执行的数学运算次数。每秒帧数表示模型每秒可以处理多少张图像。这些指标的数学方程见公式1-5。

4. 结果
在本研究收集的数据集上进行了全面的实验分析。对YOLOv8、YOLOv9和YOLO11的不同规模版本进行了对比评估。获得的结果呈现在表4中。审视该表,可以看出模型在计算成本和性能指标方面表现出广泛的范围。FLOPs值范围从10.4到344.1,参数量范围从2.9M到71.8M,精确率值范围从79.1%到90.94%,召回率值范围从73.13%到83.74%,mAP@50值范围从82.0%到86.09%。这清楚地表明模型规模和性能之间存在非线性关系。
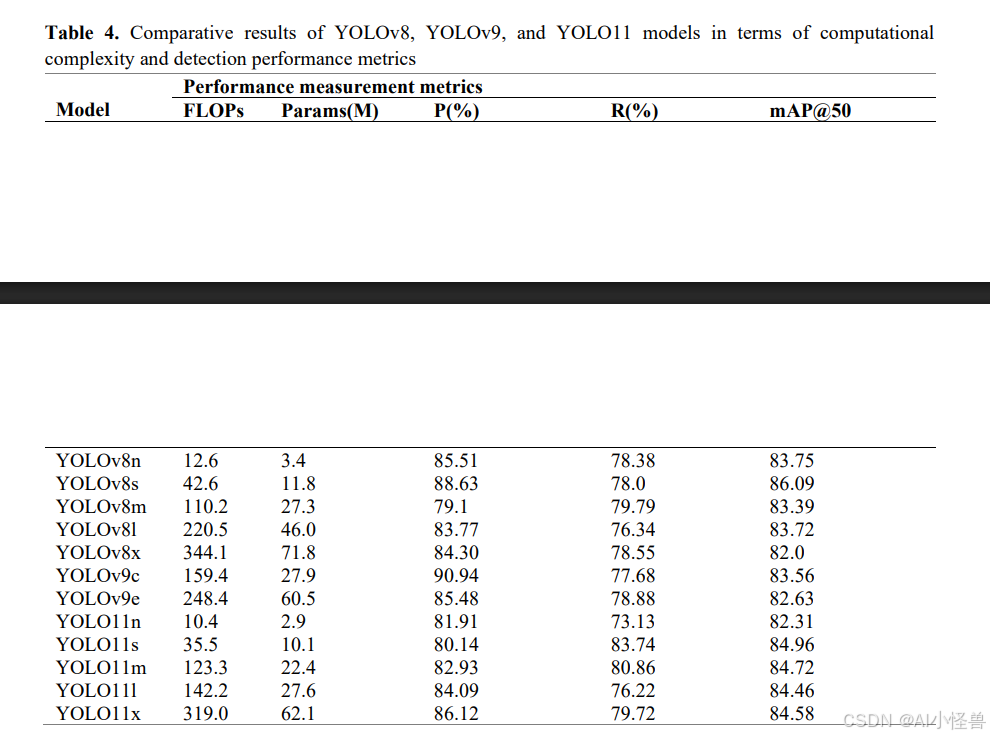
从FLOPs角度评估,计算成本最低的模型是YOLO11n,而计算成本最高的是YOLOv8x模型。然而,观察到具有最高FLOPs值的模型并未提供最高的精度性能。这表明当高计算复杂度与数据集的规模和多样性不匹配时,并不会带来性能增益。
从参数量角度审视,参数量最少的模型是YOLO11n,为2.9M,而参数量最多的模型是YOLOv8x,为71.8M。然而,显然参数量最高的模型在mAP@50方面并非最成功的模型。处于1000-1200万参数范围内的YOLOv8s和YOLO11s模型展现出更平衡且更高的性能,这一事实值得注意。
就精确率指标而言,最成功的模型是YOLOv9c,达到90.94%。在确定草莓成熟度时,减少假阳性至关重要,因为错误分类的果实可能导致收获时机失误。在此背景下,可以得出结论,YOLOv9c模型遵循了更保守和选择性的预测策略。相比之下,最低的精确率值出现在YOLOv8m模型中,为79.1%。就召回率指标而言,YOLO11s是最成功的模型,达到83.74%。召回率指标是最大化减少漏检对象数量的关键指标,尤其是在检测半熟这类形态上处于中间状态的类别时。在此背景下,显然YOLO11s模型采用了更敏感的策略。最低的召回率值由YOLO11n模型实现,为73.13%。
mAP@50指标是代表整体成功的综合度量。就这一指标而言,最成功的模型是YOLOv8s,达到86.09%。最低的mAP@50值由YOLOv8x模型实现,为82.0%。基于模型规模进行总体分析,Nano模型以低参数和低FLOPs运行,但其性能指标仍然有限。小规模模型提供了最平衡且最高的性能。在中型和大型模型中,性能增长在达到某点后趋于饱和。
超大型模型尽管计算成本高,但并未提供有意义的性能优势。
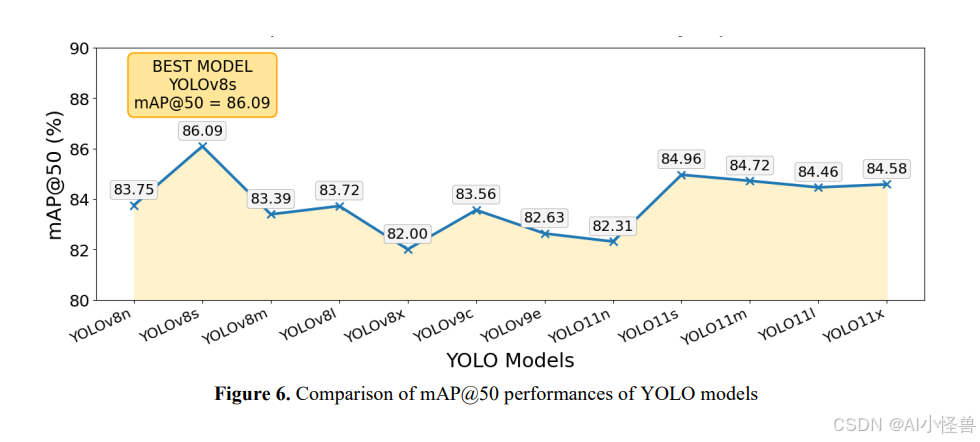
图6直观比较了YOLO模型的mAP@50性能。审视该图,很明显性能并未随模型规模线性增长。最高的mAP@50值为86.09%,属于YOLOv8s模型,在图上也被标记为"最佳模型"。
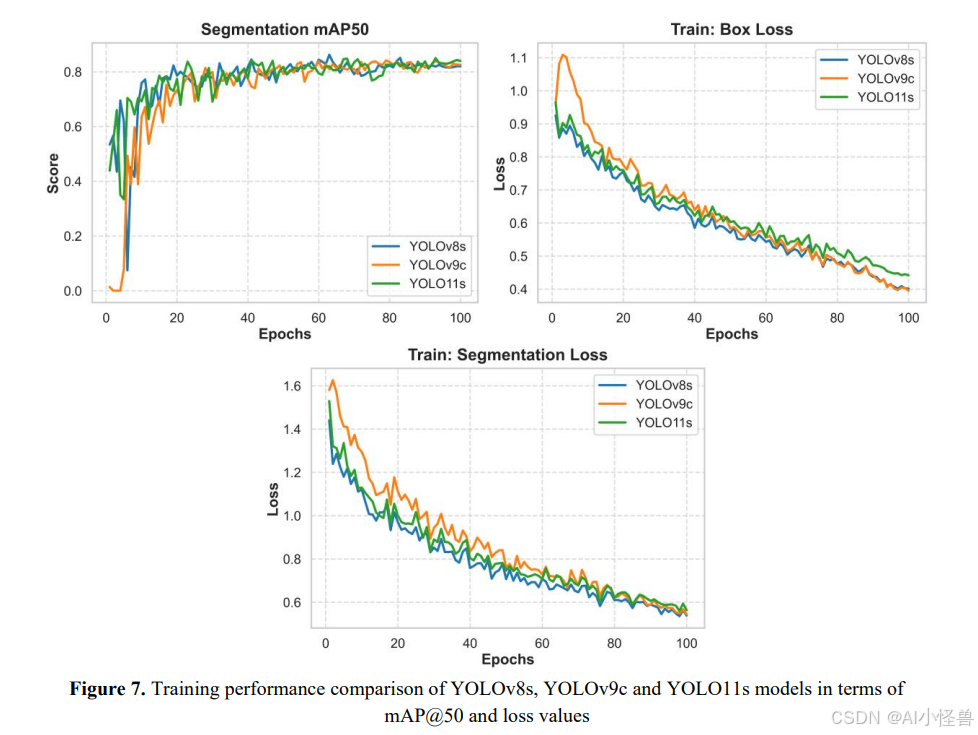
图7展示了三个最成功模型(YOLOv8s、YOLOv9c和YOLO11s)训练过程的性能曲线。审视这些图,可以看出模型达到了相似的最终精度水平,但在收敛速度和优化特性方面有所不同。
评估mAP@50图时,可以看到YOLOv8s和YOLO11s模型在最初的10-15个轮次内快速增加,达到0.6-0.7的范围。而YOLOv9c模型在最初几个轮次中初始性能较低,但在大约15-20个轮次后急剧增加,达到与其他模型相似的水平。在训练过程的后期,所有三个模型都稳定在0.80-0.83范围内,并收敛到相似的最终mAP值。
审视边界框损失曲线,观察到所有模型的损失值稳步下降,表明优化过程稳定。尽管YOLOv9c最初产生更高且波动更大的损失值,但在随后的轮次中迅速下降,达到与其他模型相当的水平。YOLOv8s展现出更平衡且低方差的下降曲线,而YOLO11s在适中的初始损失后稳步下降。训练结束时,三个模型的边界框损失值处于非常接近的水平。
分割损失曲线也显示出相似的趋势。尽管YOLOv9c模型最初具有最高的损失值,但在此过程中表现出显著改善。而YOLOv8s和YOLO11s则表现出较低的初始损失和更稳定的下降曲线。特别是,YOLOv8s模型在整个训练过程中展现出更稳定的优化曲线。
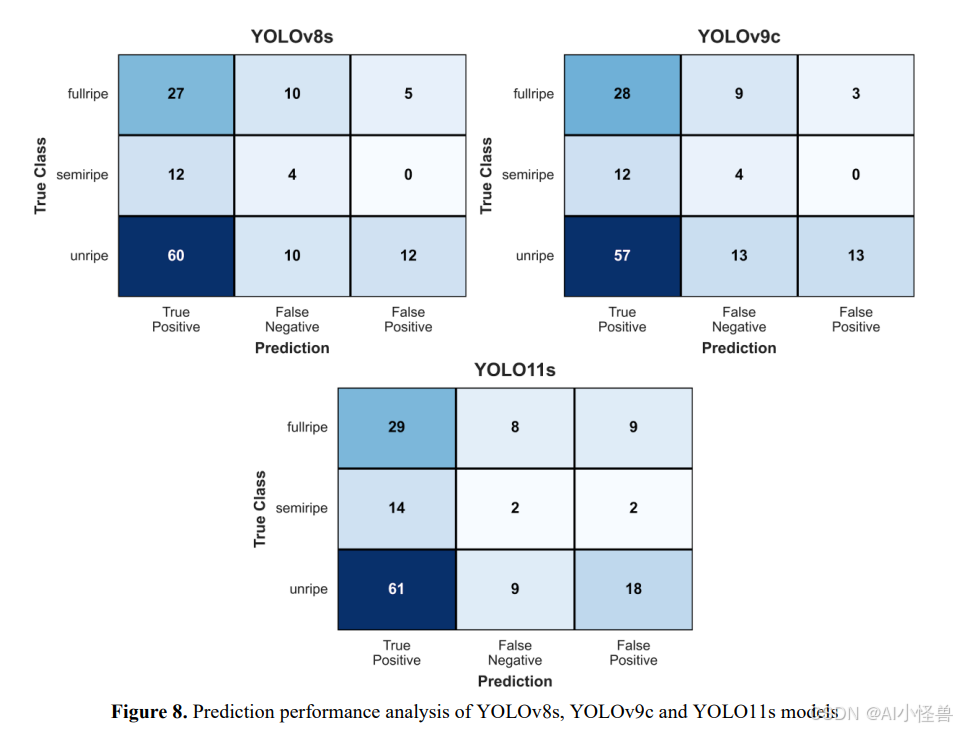
在图8中,基于真正例、假负例和假正例的分布,分析了YOLOv8s、YOLOv9c和YOLO11s模型基于类别的预测性能。审视这些图,可以看到模型在半熟类别上存在差异。
就完全成熟类别而言,YOLO11s模型实现了最高的真正例值,有29个正确检测。YOLOv9c产生了28个正确检测,而YOLOv8s产生了27个。然而,YOLO11s模型在此类别中产生了9个假正例,表明它采用了更强的预测方法。而YOLOv9c在此类别中假正例率最低,仅有3个假正例,这解释了其高精确率值。
半熟类别由于其形态过渡特性,成为最具挑战性的类别。在此类别中,YOLO11s模型以14个真正例优于其他两个模型。此外,YOLO11s的假负例值较低,为2。相比之下,YOLOv8s和YOLOv9c模型中观察到4个假负例。这一结果表明YOLO11s模型在区分中间成熟度水平方面具有更高的敏感性。
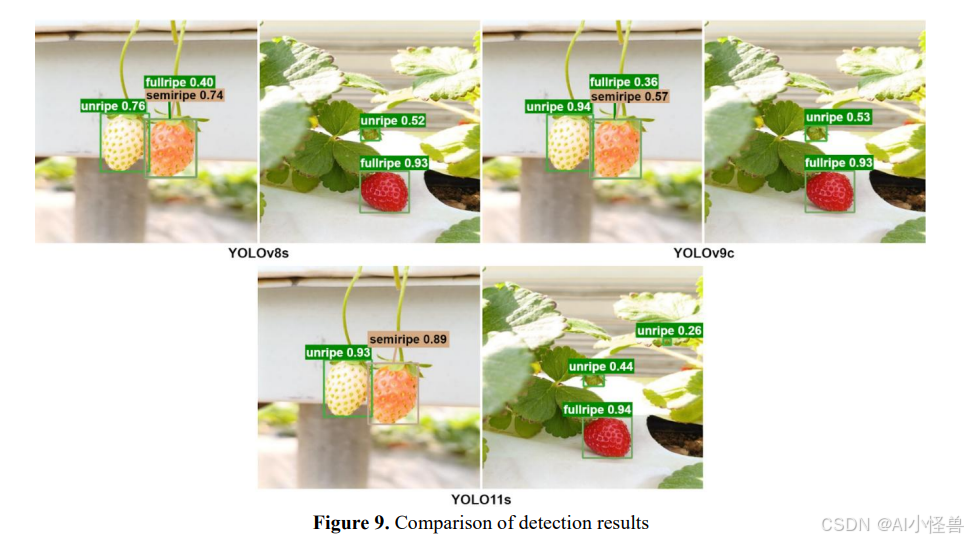
在图9中,比较了模型在测试图像上的检测结果。YOLOv8s和YOLOv9c模型成功检测到明显成熟和未熟的草莓,但在半熟样本上产生了较低的置信度分数,并偶尔对其进行错误分类。YOLO11s模型以更高的置信度值正确区分了半熟类别,但在一些背景区域产生了低置信度的假正例。

在图10中,展示了YOLOv8s模型在不同测试图像上的预测结果。审视这些图像,可以看到模型在完全成熟和未熟类别上以高置信度分数成功检测。在颜色差异明显的示例中,分类准确性尤其高。相比之下,值得注意的是,在半熟类别中置信度分数相对较低,并且在某些示例中表现出与完全成熟混淆的趋势。此外,在叶片重叠、阴影和复杂背景的场景中,会出现低置信度预测和偶发的类别转换错误。总体而言,YOLOv8s模型在视觉区分明显的情况下表现出高精度;然而,在过渡成熟度水平和复杂环境条件下,它可能在区分类别方面存在困难。
5. 讨论
在本研究中,在一个从两个不同温室、不同光照条件下收集的新的、公开可用的草莓成熟度数据集上,系统比较了YOLOv8、YOLOv9和YOLO11架构。研究结果清晰地表明了模型规模与性能之间的非线性关系。具体来说,在1000-1200万参数范围内的小型和中等规模模型在精度和计算成本方面产生了最平衡的结果。本研究最显著的结果之一是,最高的mAP@50值是由YOLOv8s模型实现的。这一发现表明,在相对有限且存在类别不平衡的数据集上,较小但平衡的架构可以更好地泛化。最高的精确率结果由YOLOv9c模型实现,而最高的召回率值由YOLO11s模型提供。这种情况表明,架构设计偏好对精确率-召回率平衡具有决定性作用。特别是,YOLO11s更高的召回率值揭示了它在检测形态上处于中间状态的类别时提供了更敏感的结构。在定性分析中,也观察到YOLO11s在颜色过渡细微的样本上做出了更准确的分类。相反,同一模型在复杂背景中产生更多假正例的倾向表明,高灵敏度有时可能以牺牲精确率为代价。
文献中的许多研究通过优化单一架构报告了性能提升;然而,在同一数据集和实验条件下对不同代际YOLO模型进行系统比较的研究有限。本研究中获得的结果表明,"更大的模型提供更好的性能"这一假设并非对每个数据集都成立。特别是,像YOLOv8x和YOLOv9e这样参数更多的模型与较小的变体相比产生更低的mAP值,这突显了模型复杂度需要与数据集的规模相匹配。
此外,文献中经常使用私有数据集,这使得研究之间的直接比较变得困难。在此背景下,提供从两个不同温室环境收集的公开可用的数据集,对于方法论的透明度和可复现性是一项重要贡献。数据集中反映了多变光照条件、叶片重叠和果实密度等现实挑战,增强了结果向实际应用的转化性。
研究中一个意外的发现是,随着参数数量增加,性能超过某点后开始下降。特别是,像YOLOv8x和YOLO11x这样的大型模型达到的mAP分数低于较小的变体,这表明数据集的规模和多样性未能为高容量模型提供足够的代表性。这可以通过过拟合倾向的增加或模型对噪声敏感度的增加来解释。另一个重要的观察是,YOLOv9c尽管具有高精确率,但并未在mAP@50中排名第一。这表明仅精确率并不能代表整体性能;当与召回率平衡时,平均成功率指标可能会受到限制。因此,理解到模型选择应根据应用场景进行。本研究存在一些局限性。首先,尽管数据集收集自两个不同的温室,但地理和气候多样性有限。不同国家的温室类型、露天生产条件或不同的草莓品种可能给模型带来不同的分布。其次,类别之间存在显著的不平衡。尽管这反映了实际生产条件,但可能使得学习决策边界变得困难,尤其是在半熟类别上。在未来的研究中,通过从不同地理区域和不同生产系统收集的图像来扩展数据集,将提高模型的泛化能力。此外,可以尝试数据增强策略和类别加权损失函数来减少类别不平衡问题。
6. 结论
本研究向文献界引入了一个新的公开可用的草莓成熟度数据集,该数据集使用从两个不同温室环境和多变光照条件下收集的图像创建,并在相同实验条件下全面比较了YOLOv8、YOLOv9和YOLO11架构。结果表明,性能并未随模型规模线性增长;相反,在1000-1200万参数范围内的紧凑模型在精度-灵敏度-计算成本平衡方面提供了最合适的性能。这一发现表明,在智慧农业应用和实时采摘系统中,应优先考虑架构效率而非高硬件要求。本研究最重要的贡献之一是它提供了一个可重复和可比较的实验框架。然而,数据集的有限地理范围和类别分布的不平衡等因素应在结果泛化能力方面加以考虑。
未来使用不同生产系统、不同品种和更大规模数据集进行的研究将有助于在实地层面验证所提出的发现。总之,这项研究不仅提出了模型比较,还为草莓成熟度检测中的架构规模-性能关系建立了一个实用且方法论上的参考框架。在这方面,它构成了迈向开发实时且可靠的成熟度检测系统的基础性一步。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)