路径规划:多种智能算法的碰撞与实践
·
路径规划——遗传算法 麻雀算法 狼群优化 粒子群算法 差分进化算法 1 五种算法进行路径规划,在同一个地图中规划 2 能够输出迭代曲线、规划路径长度 3 自定义地图 有注释,适合入门
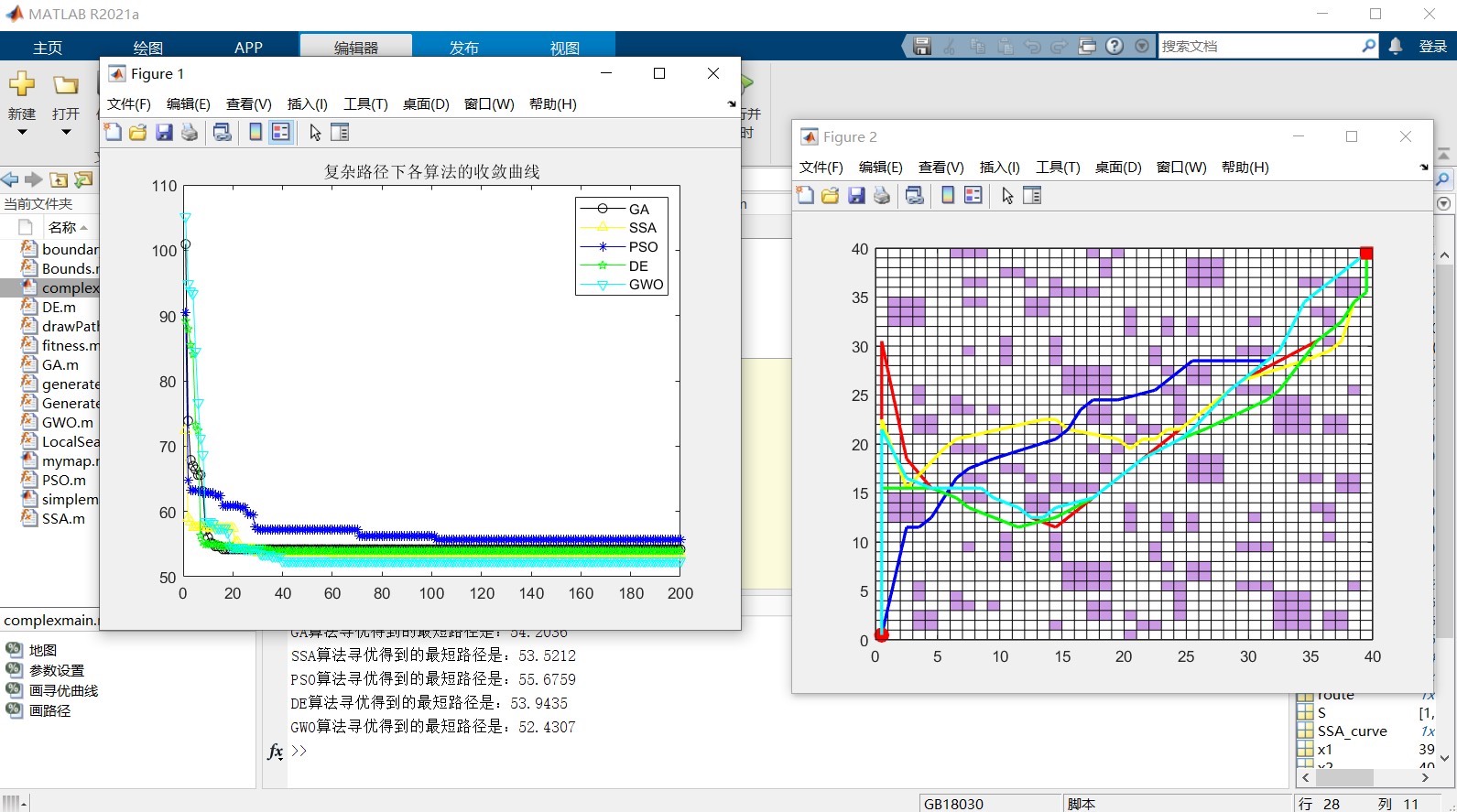
在路径规划领域,遗传算法、麻雀算法、狼群优化算法、粒子群算法以及差分进化算法都有着独特的表现。今天咱们就来探讨下如何用这五种算法在同一个自定义地图中进行路径规划,并输出迭代曲线和规划路径长度。
自定义地图
首先,我们得定义一个地图。假设地图是一个二维矩阵,0 表示可通行区域,1 表示障碍物。
# 自定义地图
map_matrix = [
[0, 0, 0, 0, 0],
[0, 1, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 1, 0]
]这样,我们就有了一个简单的 5x5 的地图。
遗传算法实现路径规划
遗传算法是一种模拟自然选择和遗传机制的搜索算法。它通过对种群中的个体进行选择、交叉和变异操作,逐步进化出适应度较高的个体。
import random
# 初始化种群
def init_population(pop_size, path_length):
population = []
for _ in range(pop_size):
path = list(range(path_length))
random.shuffle(path)
population.append(path)
return population
# 计算适应度(这里简单以路径长度倒数作为适应度)
def fitness(path):
length = 0
for i in range(len(path) - 1):
x1, y1 = divmod(path[i], len(map_matrix[0]))
x2, y2 = divmod(path[i + 1], len(map_matrix[0]))
if map_matrix[x2][y2] == 1:
length += 100 # 遇到障碍物惩罚
else:
length += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
return 1 / length
# 选择操作
def selection(population):
total_fitness = sum([fitness(path) for path in population])
selection_probs = [fitness(path) / total_fitness for path in population]
selected_index = random.choices(range(len(population)), weights=selection_probs)[0]
return population[selected_index]
# 交叉操作
def crossover(parent1, parent2):
crossover_point = random.randint(1, len(parent1) - 1)
child1 = parent1[:crossover_point] + [gene for gene in parent2 if gene not in parent1[:crossover_point]]
child2 = parent2[:crossover_point] + [gene for gene in parent1 if gene not in parent2[:crossover_point]]
return child1, child2
# 变异操作
def mutation(path):
index1, index2 = random.sample(range(len(path)), 2)
path[index1], path[index2] = path[index2], path[index1]
return path
# 遗传算法主循环
def genetic_algorithm(pop_size, generations, path_length):
population = init_population(pop_size, path_length)
best_fitness = 0
best_path = None
fitness_history = []
for generation in range(generations):
new_population = []
for _ in range(pop_size // 2):
parent1 = selection(population)
parent2 = selection(population)
child1, child2 = crossover(parent1, parent2)
child1 = mutation(child1)
child2 = mutation(child2)
new_population.extend([child1, child2])
population = new_population
current_best_fitness = max([fitness(path) for path in population])
if current_best_fitness > best_fitness:
best_fitness = current_best_fitness
best_path = [path for path in population if fitness(path) == best_fitness][0]
fitness_history.append(best_fitness)
return best_path, fitness_history遗传算法代码分析
- 初始化种群:
init_population函数生成初始的种群,每个个体是一条随机打乱的路径。 - 适应度计算:
fitness函数根据路径在地图中的实际情况计算其长度,并以长度倒数作为适应度,这里对遇到障碍物的路径给予了较大惩罚。 - 选择操作:
selection函数根据个体的适应度计算选择概率,然后随机选择个体,适应度高的个体被选中概率更大。 - 交叉操作:
crossover函数通过随机选择交叉点,将两个父代个体的基因进行交换生成子代。 - 变异操作:
mutation函数随机交换路径中两个点的位置,引入新的基因。 - 主循环:
genetic_algorithm函数在指定的代数内不断进化种群,记录每一代的最佳适应度,最终返回最佳路径和适应度历史。
麻雀算法实现路径规划
麻雀算法是一种基于麻雀觅食和反捕食行为的群体智能优化算法。
import numpy as np
# 初始化麻雀位置
def init_sparrows(num_sparrows, dim):
return np.random.rand(num_sparrows, dim)
# 计算适应度(同遗传算法类似的路径长度计算方式)
def sparrow_fitness(sparrows):
fitness_values = []
for sparrow in sparrows:
path = sparrow.astype(int)
length = 0
for i in range(len(path) - 1):
x1, y1 = divmod(path[i], len(map_matrix[0]))
x2, y2 = divmod(path[i + 1], len(map_matrix[0]))
if map_matrix[x2][y2] == 1:
length += 100
else:
length += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
fitness_values.append(1 / length)
return np.array(fitness_values)
# 麻雀算法主循环
def sparrow_algorithm(num_sparrows, generations, dim):
sparrows = init_sparrows(num_sparrows, dim)
fitness_values = sparrow_fitness(sparrows)
best_index = np.argmax(fitness_values)
best_sparrow = sparrows[best_index]
best_fitness = fitness_values[best_index]
fitness_history = [best_fitness]
for generation in range(generations):
r2 = np.random.rand()
if r2 < 0.8:
for i in range(num_sparrows):
if fitness_values[i] > best_fitness:
sparrows[i] = best_sparrow + np.random.randn(dim) * np.abs(sparrows[i] - best_sparrow)
else:
sparrows[i] = sparrows[i] + np.random.randn(dim)
else:
for i in range(num_sparrows):
if fitness_values[i]!= best_fitness:
j = np.random.choice(np.where(fitness_values!= best_fitness)[0])
sparrows[i] = sparrows[i] + np.random.randn(dim) * np.abs(sparrows[i] - sparrows[j])
fitness_values = sparrow_fitness(sparrows)
current_best_index = np.argmax(fitness_values)
current_best_fitness = fitness_values[current_best_index]
if current_best_fitness > best_fitness:
best_fitness = current_best_fitness
best_sparrow = sparrows[current_best_index]
fitness_history.append(best_fitness)
return best_sparrow, fitness_history麻雀算法代码分析
- 初始化麻雀位置:
init_sparrows函数随机生成麻雀的初始位置,每个位置对应路径中的点。 - 适应度计算:
sparrow_fitness函数和遗传算法类似,计算每条路径的适应度。 - 主循环:
sparrow_algorithm函数在循环中根据麻雀算法的规则更新麻雀位置,r2是一个随机数,根据其值不同执行不同的更新策略,不断寻找更好的路径,并记录适应度历史。
狼群优化算法实现路径规划
狼群优化算法模拟狼群的觅食、围攻、游走等行为。
import numpy as np
# 初始化狼的位置
def init_wolves(num_wolves, dim):
return np.random.rand(num_wolves, dim)
# 计算适应度(路径长度相关适应度)
def wolf_fitness(wolves):
fitness_values = []
for wolf in wolves:
path = wolf.astype(int)
length = 0
for i in range(len(path) - 1):
x1, y1 = divmod(path[i], len(map_matrix[0]))
x2, y2 = divmod(path[i + 1], len(map_matrix[0]))
if map_matrix[x2][y2] == 1:
length += 100
else:
length += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
fitness_values.append(1 / length)
return np.array(fitness_values)
# 狼群优化算法主循环
def wolf_algorithm(num_wolves, generations, dim):
wolves = init_wolves(num_wolves, dim)
fitness_values = wolf_fitness(wolves)
alpha_index = np.argmax(fitness_values)
alpha_wolf = wolves[alpha_index]
alpha_fitness = fitness_values[alpha_index]
fitness_history = [alpha_fitness]
for generation in range(generations):
for i in range(num_wolves):
if i!= alpha_index:
wolves[i] = alpha_wolf + np.random.randn(dim) * np.abs(wolves[i] - alpha_wolf)
fitness_values = wolf_fitness(wolves)
current_alpha_index = np.argmax(fitness_values)
current_alpha_fitness = fitness_values[current_alpha_index]
if current_alpha_fitness > alpha_fitness:
alpha_fitness = current_alpha_fitness
alpha_wolf = wolves[current_alpha_index]
fitness_history.append(alpha_fitness)
return alpha_wolf, fitness_history狼群优化算法代码分析
- 初始化狼的位置:
init_wolves函数随机生成狼的初始位置。 - 适应度计算:
wolf_fitness函数同样基于路径长度计算适应度。 - 主循环:
wolf_algorithm函数在每一代中,除了最优的狼(alpha 狼),其他狼向 alpha 狼靠近,不断更新狼群位置并寻找更好的路径,记录适应度历史。
粒子群算法实现路径规划
粒子群算法模拟鸟群觅食行为,每个粒子有自己的位置和速度,通过不断更新位置寻找最优解。
import numpy as np
# 初始化粒子位置和速度
def init_particles(num_particles, dim):
positions = np.random.rand(num_particles, dim)
velocities = np.random.rand(num_particles, dim)
return positions, velocities
# 计算适应度(路径长度相关适应度)
def particle_fitness(positions):
fitness_values = []
for position in positions:
path = position.astype(int)
length = 0
for i in range(len(path) - 1):
x1, y1 = divmod(path[i], len(map_matrix[0]))
x2, y2 = divmod(path[i + 1], len(map_matrix[0]))
if map_matrix[x2][y2] == 1:
length += 100
else:
length += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
fitness_values.append(1 / length)
return np.array(fitness_values)
# 粒子群算法主循环
def particle_swarm_algorithm(num_particles, generations, dim, c1=1.5, c2=1.5, w=0.7):
positions, velocities = init_particles(num_particles, dim)
pbest_positions = positions.copy()
pbest_fitness = particle_fitness(pbest_positions)
gbest_index = np.argmax(pbest_fitness)
gbest_position = pbest_positions[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
fitness_history = [gbest_fitness]
for generation in range(generations):
r1 = np.random.rand(num_particles, dim)
r2 = np.random.rand(num_particles, dim)
velocities = w * velocities + c1 * r1 * (pbest_positions - positions) + c2 * r2 * (gbest_position - positions)
positions = positions + velocities
positions = np.clip(positions, 0, dim - 1)
fitness_values = particle_fitness(positions)
improved_indices = fitness_values > pbest_fitness
pbest_positions[improved_indices] = positions[improved_indices]
pbest_fitness[improved_indices] = fitness_values[improved_indices]
current_gbest_index = np.argmax(pbest_fitness)
current_gbest_fitness = pbest_fitness[current_gbest_index]
if current_gbest_fitness > gbest_fitness:
gbest_fitness = current_gbest_fitness
gbest_position = pbest_positions[current_gbest_index]
fitness_history.append(gbest_fitness)
return gbest_position, fitness_history粒子群算法代码分析
- 初始化粒子位置和速度:
init_particles函数生成粒子的初始位置和速度。 - 适应度计算:
particle_fitness函数计算每个粒子位置对应的路径适应度。 - 主循环:
particleswarmalgorithm函数在每一代中,根据粒子群算法公式更新粒子速度和位置,c1和c2是学习因子,w是惯性权重,不断调整粒子位置以寻找更优路径,并记录适应度历史。
差分进化算法实现路径规划
差分进化算法是一种基于群体差异的启发式搜索算法。
import numpy as np
# 初始化种群
def init_population_de(num_population, dim):
return np.random.rand(num_population, dim)
# 计算适应度(路径长度相关适应度)
def de_fitness(population):
fitness_values = []
for individual in population:
path = individual.astype(int)
length = 0
for i in range(len(path) - 1):
x1, y1 = divmod(path[i], len(map_matrix[0]))
x2, y2 = divmod(path[i + 1], len(map_matrix[0]))
if map_matrix[x2][y2] == 1:
length += 100
else:
length += ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
fitness_values.append(1 / length)
return np.array(fitness_values)
# 差分进化算法主循环
def differential_evolution(num_population, generations, dim, F=0.5, CR=0.9):
population = init_population_de(num_population, dim)
fitness_values = de_fitness(population)
best_index = np.argmax(fitness_values)
best_solution = population[best_index]
best_fitness = fitness_values[best_index]
fitness_history = [best_fitness]
for generation in range(generations):
for i in range(num_population):
r1, r2, r3 = np.random.choice(np.delete(np.arange(num_population), i), 3, replace=False)
mutant = population[r1] + F * (population[r2] - population[r3])
trial = np.copy(population[i])
jrand = np.random.randint(0, dim)
for j in range(dim):
if np.random.rand() < CR or j == jrand:
trial[j] = mutant[j]
trial_fitness = de_fitness(trial.reshape(1, -1))[0]
if trial_fitness > fitness_values[i]:
population[i] = trial
fitness_values[i] = trial_fitness
if trial_fitness > best_fitness:
best_fitness = trial_fitness
best_solution = trial
fitness_history.append(best_fitness)
return best_solution, fitness_history差分进化算法代码分析
- 初始化种群:
initpopulationde函数随机生成初始种群。 - 适应度计算:
de_fitness函数计算种群中每个个体的适应度。 - 主循环:
differential_evolution函数在每一代中,通过对种群中个体进行差分变异和交叉操作生成试验个体,与原个体比较,保留适应度高的个体,不断进化种群寻找最优路径,并记录适应度历史。
输出迭代曲线和规划路径长度
为了输出迭代曲线和规划路径长度,我们可以在每种算法运行后进行相关处理。
import matplotlib.pyplot as plt
# 运行遗传算法
best_path_ga, fitness_history_ga = genetic_algorithm(pop_size=50, generations=100, path_length=len(map_matrix)路径规划——遗传算法 麻雀算法 狼群优化 粒子群算法 差分进化算法 1 五种算法进行路径规划,在同一个地图中规划 2 能够输出迭代曲线、规划路径长度 3 自定义地图 有注释,适合入门

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)