Ultralytics 实战:YOLOv8n 边缘部署全维度评估
1. 前言:评估背景与目标
现代AI应用开发中,模型训练完成后如何高效部署到生产环境是一个至关重要的环节。特别是对于计算机视觉任务,如目标检测、语义分割、姿态估计等,模型不仅要保持较高的检测精度,还要满足实时性要求。这就引出了模型部署中的核心矛盾:精度与速度之间的权衡。
为了科学地评估不同部署方案的优劣,本文依托Ultralytics代码库,并基于 YOLO V8网络框架和COCO128数据集,围绕模型的速度与精度从多个维度进行了相关实验。
另外,本文侧重于实验,关于代码本身的解读,请参考以下章节:
🚩Ultralytics代码库深度解读【一】:onnx模型导出
🚩Ultralytics代码库深度解读【二】:TensorRT 引擎文件的构建与序列化
🚩Ultralytics 代码库深度解读【三】:YOLO V8/V11 核心模块可视化拆解(网络结构与参数解析)
🚩Ultralytics 代码库深度解读【四】:YOLO V8/V11 网络配置文件解析与完整模型构建流程
🚩Ultralytics 代码库深度解读【五】:数据预处理与增强Pipeline
🚩Ultralytics 代码库深度解读【六】:数据加载机制深度解析
2. 实验设计与模型准备
2.1 模型格式选择策略:ONNX、TensorRT(FP32/FP16/INT8)
在深度学习模型部署中,存在多种模型格式,每种格式都有其特定的优势和适用场景。我们选择以下几种主流格式进行对比评估:
💥PyTorch原生格式(.pt/.pth):
- 特点:保留完整的模型结构和权重,支持动态图
- 优势:调试友好,功能完整,易于修改
- 劣势:推理速度相对较慢,文件体积较大
- 适用场景:模型开发、调试、研究
💥ONNX格式(.onnx):
- 特点:开放神经网络交换格式,跨平台兼容
- 优势:一次导出,多平台部署,生态系统丰富
- 劣势:某些PyTorch特性可能不完全支持
- 适用场景:跨平台部署,推理引擎转换
💥TensorRT引擎格式(.engine):
- 特点:NVIDIA优化的推理引擎,高度优化
- 优势:推理速度最快,支持INT8量化,内存优化
- 劣势:平台依赖,构建时间较长
- 适用场景:NVIDIA GPU部署,性能优先
2.2 评估指标体系:精度指标、速度指标、资源指标
为了全面评估模型性能,我们建立了一个多维度的指标体系:
🌍2.2.1 精度指标体系
mAP@0.5:IoU阈值为0.5时的平均精度,衡量检测的基本准确性Precision:精确率 /查准率,衡量检测结果的准确性Recall:召回率/查全率,衡量检测结果的完整性F1-Score:精确率和召回率的调和平均数
📈精确率/查准率的计算公式为:
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP + FP} Precision=TP+FPTP
公式很好理解,T/F就是模型预测的结果与真实标签一致✅️或者不一致❌️,P就是模型将该目标预测成了正例✅️,该指标衡量模型预测为正例的样本中,真实正例的比例。
精确率计算中,TP或者FP的判定是以预测的边界框与标定边界框的交并比阈值决定的,不同的算法可能不一样,Ultralytics中是0.5。
📈召回率又叫查全率,反应模型对目标物的检测有无遗漏,计算公式为:
R e c a l l = T P T P + F N Recall= \frac{TP}{TP + FN} Recall=TP+FNTP
同样,T/F就是模型预测的结果与真实标签一致✅️或者不一致❌️,N就是模型将该目标预测成了负类❌️,很明显,分母就是所有的正样本,分子是检测出的正样本,整个表达式就表示的召回率。
召回率的计算,TP或者FN的判定同样是以预测的边界框与标定边界框的交并比阈值决定的,不同的算法可能不一样,Ultralytics中是0.5。
📈F1-score在实际模型评估中,有时候既想要较高的查准率又想要较高的查全率,这时候就需要用到F1分数了,F1分数是二者调和平均数再×2,如下式所示:
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
为什么要用到调和平均值,而不是简单求和,或者其他平均值(比方说算数平均值)呢?
调和平均值,可以更好地惩罚两个指标不均衡的情况,简单计算一下,假设两个模型的两个指标和都为1,一个查准率是0.1,一个是0.5。
那么对于第一种情况:
F 1 = 2 × 0.1 × 0.9 0.1 + 0.9 = 0.18 F1 = 2 \times \frac{0.1\times 0.9}{0.1+ 0.9}=0.18 F1=2×0.1+0.90.1×0.9=0.18
然而第二种情况:
F 1 = 2 × 0.5 × 0.5 0.5 + 0.5 = 0.5 F1 = 2 \times \frac{0.5\times 0.5}{0.5+ 0.5}=0.5 F1=2×0.5+0.50.5×0.5=0.5
所以第二个模型更优,因为更加均衡,没有明显的短板👍。
🌍2.2.2 性能指标体系
- 推理延迟(Latency):单张图片的处理时间,单位毫秒
- FPS(Frames Per Second):每秒处理的图片数量
🌍2.2.3 资源指标体系
- GPU显存占用:模型推理时占用的GPU显存大小
- 功耗:设备运行时的功率消耗
2.3 实验环境配置:硬件平台、软件环境
此次的环境配置如下:
🚩硬件环境(NVIDIA orin super开发板)
GPU:NVIDIA 安培架构,1024 CUDA Cores,32 Tensor Cores
CPU:6核ARM Cortex-A78AE
内存:8GB 128-bit LPDDR5E
存储:256GB SSD
关于安培架构设计的更多细节,请参考:万字长文:英伟达 GPU 硬件架构发展史全景回顾
🚩软件环境
操作系统:Ubuntu 20.04.5 LTS
CUDA版本:12.6
TensorRT版本:10.7.0.23
Python版本:3.10.2
PyTorch版本:2.5.1
查询各个软件版本的命令如下:



3. 精度评估:多维度性能对比
在Ultralytics的项目路径下,输入以下命令,即可输出精度评估结果。
# pt 模型评估
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640 device=0
# onnx 模型评估
yolo val model=yolov8n.onnx data=coco128.yaml batch=1 imgsz=640 device=0
# FP32精度(最高精度)模型评估
yolo val model=yolov8n_fp32.engine data=coco128.yaml batch=1 imgsz=640 device=0
# FP16精度(平衡性能和精度)模型评估
yolo val model=yolov8n_fp16.engine data=coco128.yaml batch=1 imgsz=640 device=0
# INT8精度(最高性能)模型评估
yolo val model=yolov8n_int8.engine data=coco128.yaml batch=1 imgsz=640 device=0
在评估结果曲线中,有的曲线横轴是置信度阈值,所谓置信度,是目标得分和分类得分的乘积。
C o n f i d e n c e = o b j s c o r e × c l a s s s c o r e Confidence= obj_{score} × class_{score} Confidence=objscore×classscore
在早期的目标检测框架中,只有2个分支的输出,一个分类一个回归。
而YOLO系列将其分成了3个分支。也就是说,将分类任务进行了拆分,先区分前景和背景,然后才关注“是什么”。
上面这个图是YOLO-X的网络框架head部分,虽然主要是想说明的是“解耦”,但输出的预测信息是基本一致。
- 🌊边界框分支:输出 4 个坐标偏移值(cx, cy, w, h);
- 🌊obj score 分支:输出 “这个框有目标的概率”(Sigmoid 激活,0-1);
- 🌊分类得分分支:输出 “目标属于每个类的概率”(Sigmoid/Softmax 激活,0-1)。
3.2 P 曲线对比:精确率随置信度变化分析
P曲线反映了各模型在不同置信度阈值下的精确率表现,最终指标是能刚好能检测出所有类别时的精确度。
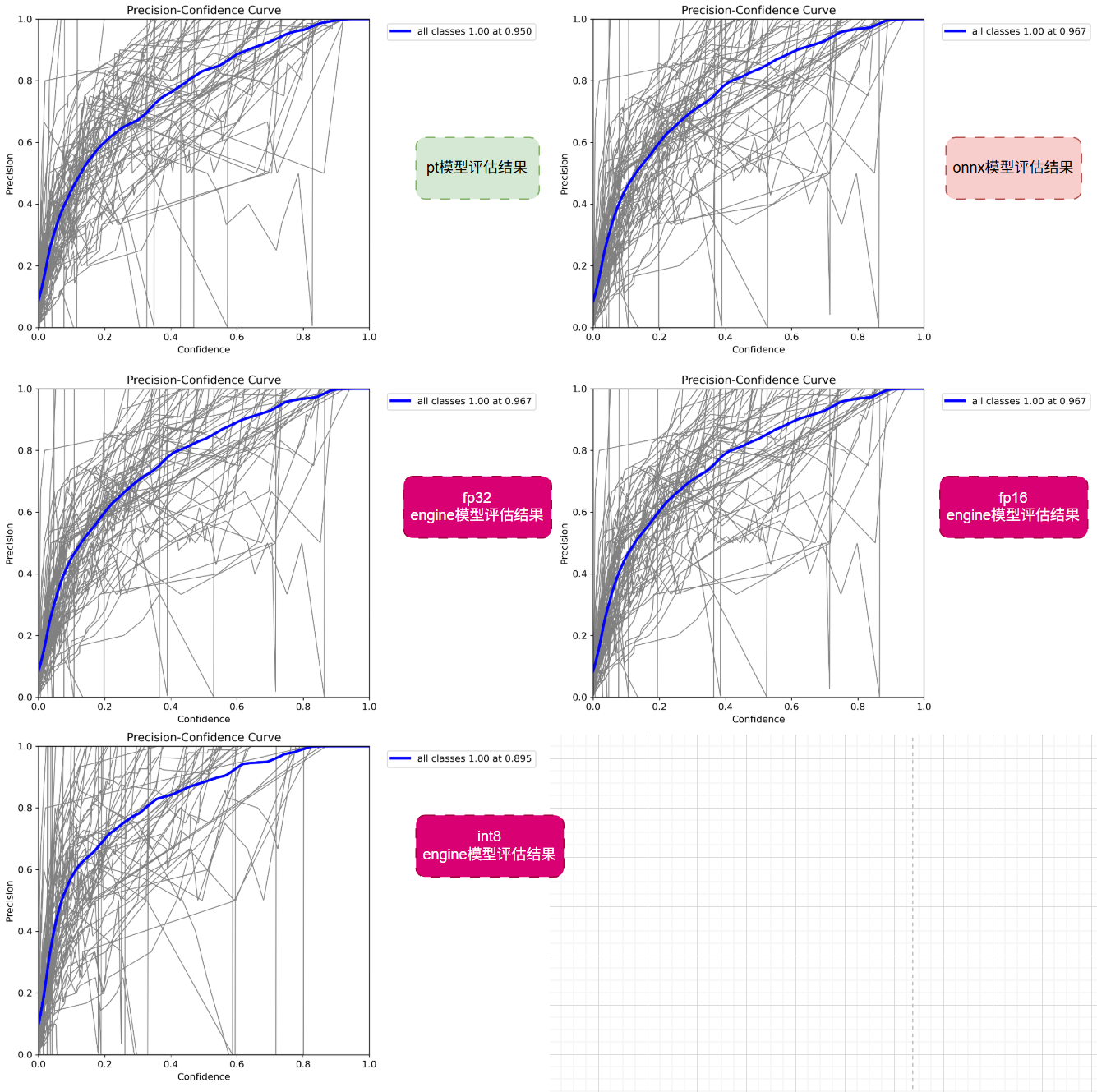
曲线的绘制过程如下:
假设有以下预测结果(已按置信度排序)
⭐️预测1: conf=0.9, IoU=0.75 (与GT的IoU)
⭐️预测2: conf=0.8, IoU=0.45
⭐️预测3: conf=0.7, IoU=0.65
⭐️预测4: conf=0.6, IoU=0.35
当IoU阈值=0.5时:
🌙预测1: IoU=0.75 ≥ 0.5 → TP✅️
🌙预测2: IoU=0.45 < 0.5 → FP❌️
🌙预测3: IoU=0.65 ≥ 0.5 → TP✅️
🌙预测4: IoU=0.35 < 0.5 → FP❌️
精确率源于预测框与GT的交并比
当置信度取0.7的时候,精确率=2/3=0.67
当置信度取0.8的时候,精确率=1/2=0.5
理论上来说,这个曲线的最终指标,all Classes 1.00 at XXX,这个数值越小越好
数值越低:代表 “用更宽松的阈值就能达到 100% 查准率”—— 既保证了 “检测准”,又能保留更多有效框(减少漏检)。
数值越高:代表 “必须用很严格的阈值才能避免误检”—— 虽然查准率满了,但会漏掉很多低置信度的真实目标(召回率低)。
但int8能在低阈值能达到 100% 查准率,不是因为 “模型更准”,而是因为 “量化把所有框的置信度都打低了,误检框被提前过滤”—— 但同时也把 “真实的有效框” 一起过滤了,属于 “为了准,牺牲了全”,不符合自动驾驶 “既要准、又要全” 的需求。
因此不能仅仅以此曲线的结果说明int8的精度好,理论上int8的精度更差才对,因此需要结合其他几个精度曲线综合分析。
IoU的阈值,可以从代码中得出:
DetectionValidator类中
self.iouv = torch.linspace(0.5, 0.95, 10) # IoU vector for mAP@0.5:0.95
创建了10个IoU阈值:[0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95]
然后计算Precision曲线数据
# Precision
precision = tpc / (tpc + fpc) # precision curve
p_curve[ci] = np.interp(-x, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if j == 0:
prec_values.append(np.interp(x, mrec, mpre)) # precision at mAP@0.5
precision 数组的形状是 (nc, 10),其中nc是类别数,10是IoU阈值数,precision[:, 0] 表示使用第一个IoU阈值(索引为0)下的precision值,即0.5。
3.3 R曲线对比:召回率随置信度变化分析
R曲线反映的是模型在不同置信度下的召回率,可以看到,随着置信度阈值越来越高⬆️,就会漏掉越来越多的预测结果,召回率也就越来越低⬇️。
💊 最终的评估指标,是置信度阈值取0时的召回率,很好理解,就是拿模型最“原生”的预测结果来计算召回率,这样对比也比较公允。
从评估结果来看,除了最后的int8 engine模型有点差,其他模型均在置信度为0的时候,有着不错的召回率。因此,其他模型更优。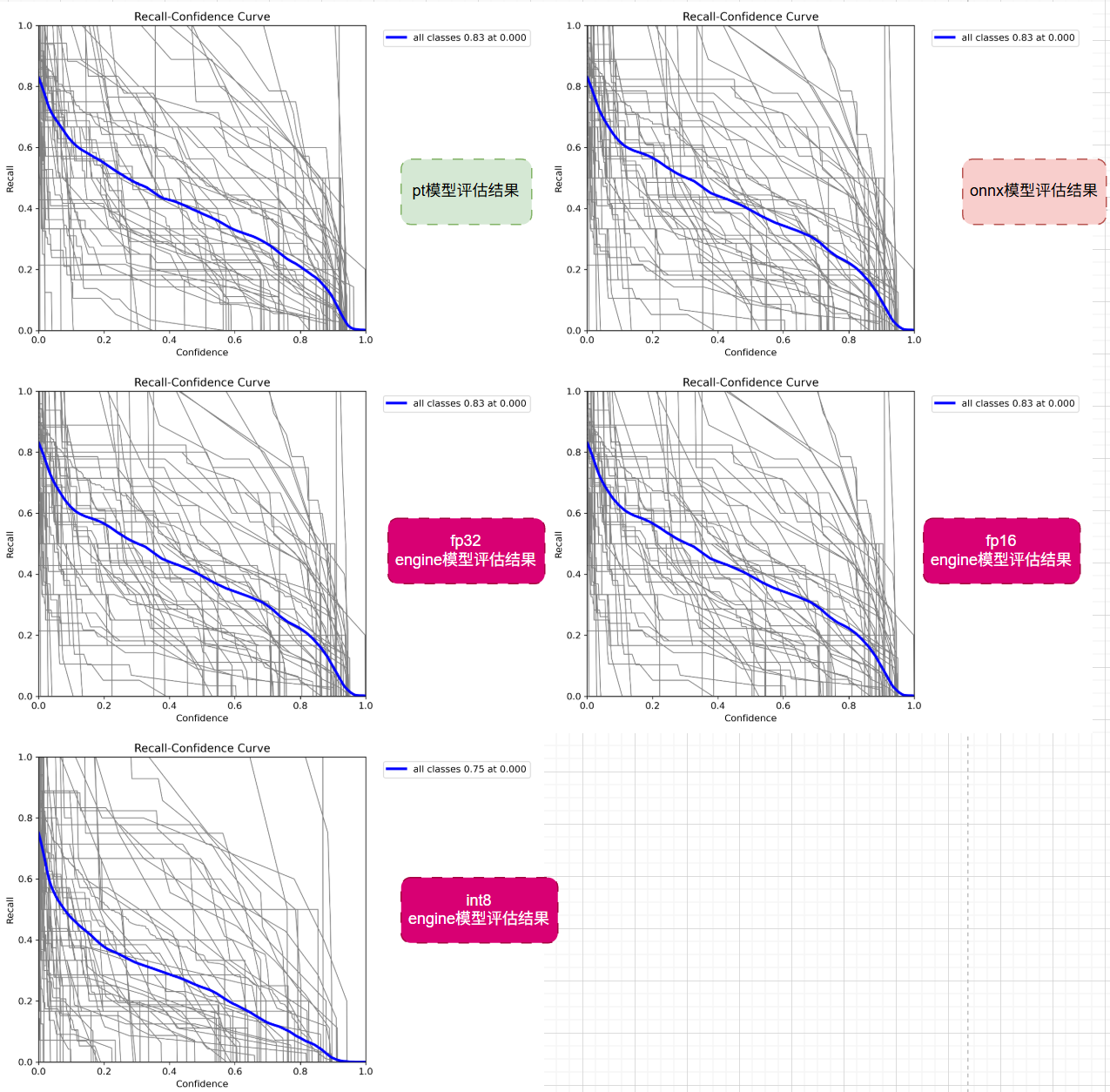
3.4 PR曲线对比:精确率-召回率权衡分析
PR曲线反映的是精确率和召回率之间的关系,最终指标是当准确度mAP为0.5的时候的召回率,也就是相同准确度下比较召回率,越高越好⬆️。
💊 比较反直觉的是,fp16的结果反而比fp32的结果要好,按道理浮点数存储位数越高,所能表达的范围就越大,越精确,检测结果越好才对。
不过我们的实验样本本身就不多,加之这个指标并不是很客观,只取了mAP@0.5,并没有取其他位置的准确度。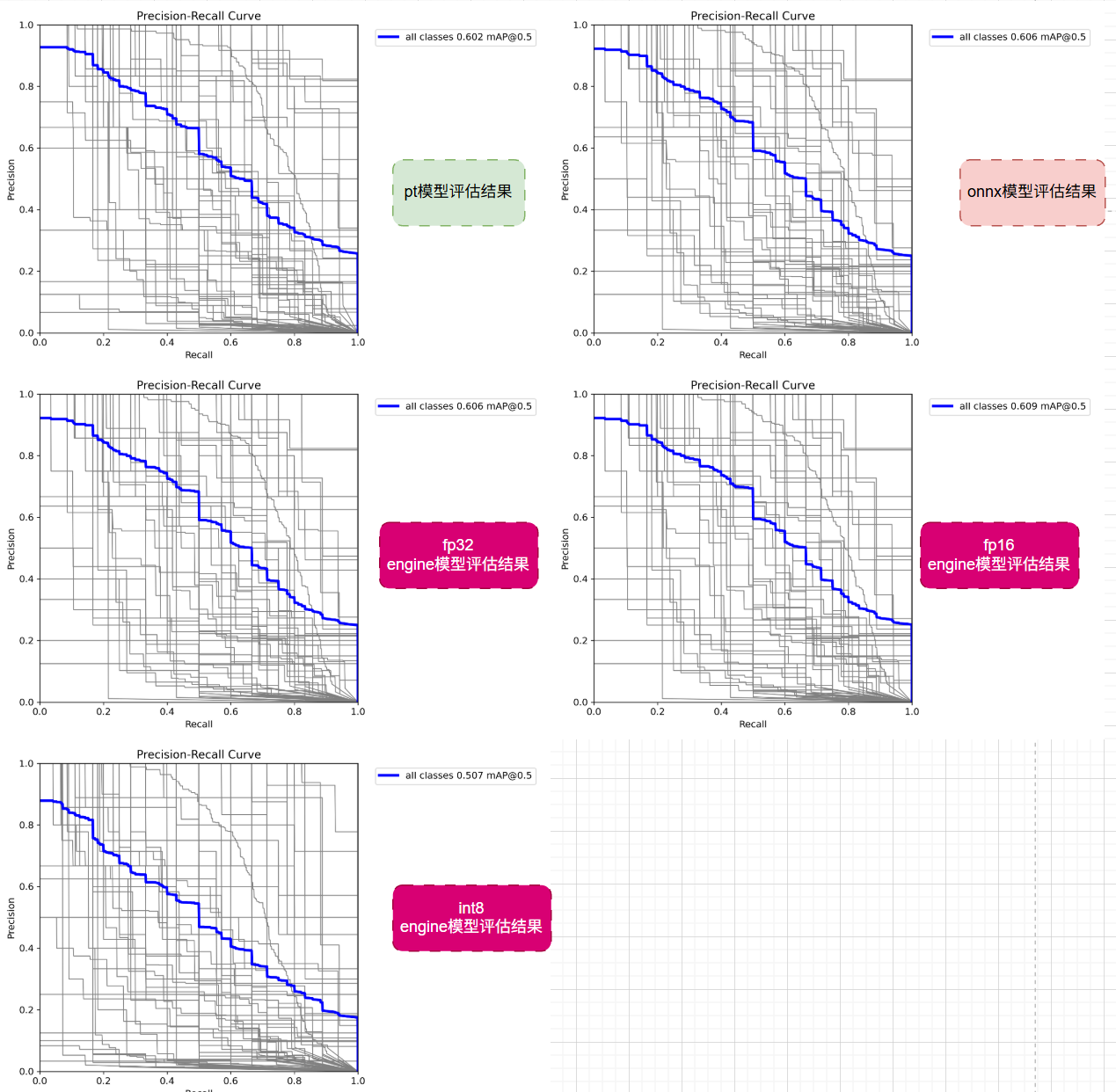
3.1 F1曲线对比:F1分数随置信度变化分析
F1曲线反映的是不同置信度下的F1指标。最终指标是整个曲线上的F1最大值,数值越大越好。
从评估结果来看, 除了最后的int8 engine模型有点差,其他模型的F1参数都在不同的置信度处取得了最大值,且最大值相同。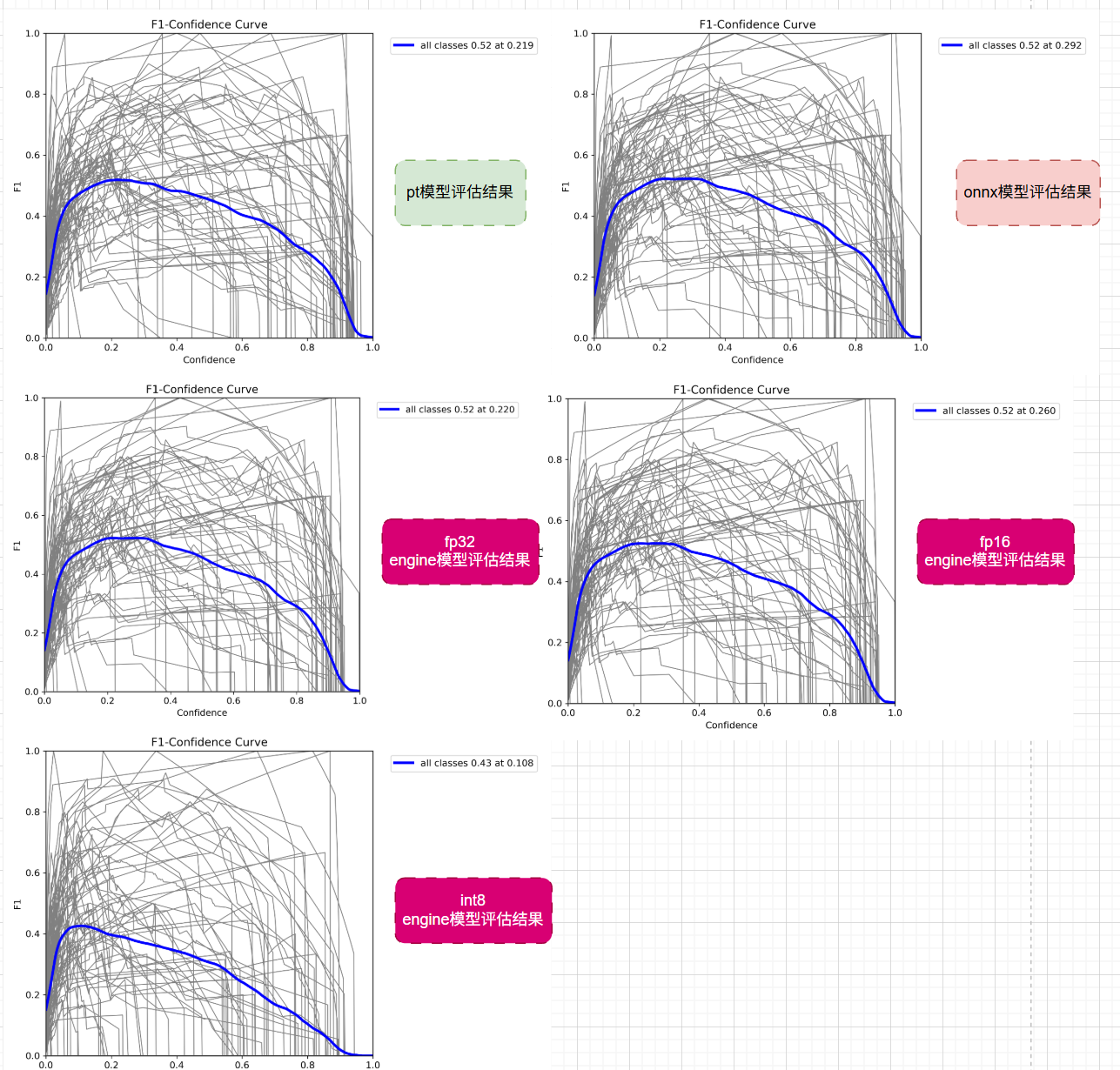
4. 推理性能与资源占用评估
在模型部署场景中,推理性能(速度)和资源占用(显存 / 内存)是衡量模型实用性的核心指标,尤其对于Jetson 这类边缘计算平台,二者的权衡直接决定了模型能否落地。本章将从自定义性能评估方案和官方工具评估两个维度,系统评估 YOLOv8 不同格式模型(FP32/FP16/INT8 Engine、ONNX、TorchScript)的性能表现,并通过交叉验证确保结果的可靠性。
4.1 自定义性能评估方案
为了更好地对模型的性能做出尽可能客观的评估,可以自己写一套评估代码。
4.1.1 评估目标与设计思路
针对 Jetson 边缘平台的特性,实现以下核心评估目标🎯:
- 量化不同模型的端到端推理耗时(预处理 + 推理 + 后处理);
- 精准统计模型运行时的 GPU/CPU 资源占用;
- 分析批量大小、精度格式对性能的影响;
- 验证性能数据的稳定性(过滤硬件波动带来的异常值)。
📐设计原则 📐
- 轻量化:适配 Jetson 平台有限的计算资源,避免评估工具本身占用过多资源;
- 鲁棒性:通过 “预热 - 测试” 机制排除前 10 次推理的波动,取后序数据的平均值;
- 针对性:专门适配 TensorRT Engine 模型(FP32/FP16/INT8),解决官方工具对边缘设备支持不足的问题;
- 可扩展性:支持多模型批量对比、批次大小测试、精度 - 性能权衡分析。
4.1.2 核心代码逻辑拆解
整个测试代码的内容比较多,我也是反复调试了很多次,取了最理想的一套代码。
import os
import glob
import csv # 新增:CSV导出依赖
from ultralytics import YOLO
import numpy as np
import cv2
import torch
import time
from collections import defaultdict
import onnxruntime as ort # ONNX Runtime依赖
# ===================== 通用显存监控函数 =====================
def get_gpu_memory_usage():
if not torch.cuda.is_available():
return {"used": 0.0, "allocated": 0.0, "max_allocated": 0.0}
torch.cuda.synchronize()
used_mem = torch.cuda.memory_allocated() / 1024 / 1024
cached_mem = torch.cuda.memory_reserved() / 1024 / 1024
max_allocated = torch.cuda.max_memory_allocated() / 1024 / 1024
return {
"used": used_mem,
"cached": cached_mem,
"max_allocated": max_allocated
}
def print_memory_status(step_name):
if not torch.cuda.is_available():
return
mem = get_gpu_memory_usage()
print(f"\n📊 【{step_name}】显存状态:")
print(f" 实际使用显存: {mem['used']:.2f} MB (模型+临时数据)")
print(f" 缓存显存: {mem['cached']:.2f} MB (可自动回收)")
print(f" 峰值已分配: {mem['max_allocated']:.2f} MB")
# ===================== Jetson平台专属优化配置 =====================
def jetson_hardware_optimize():
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = False
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated()
torch.cuda.set_per_process_memory_fraction(0.7, device=0)
print_memory_status("硬件优化后-初始状态")
print("✅ Jetson硬件优化完成,已清理显存并限制显存使用比例")
def load_and_preprocess_images_jetson(image_folder, target_size=(640, 640), num_samples=30):
extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp']
image_paths = []
for ext in extensions:
image_paths.extend(glob.glob(os.path.join(image_folder, ext)))
image_paths.extend(glob.glob(os.path.join(image_folder, ext.upper())))
if len(image_paths) < num_samples:
print(f"警告: 图片数量不足,重复使用图片补充至{num_samples}张")
image_paths = (image_paths * (num_samples // len(image_paths) + 1))[:num_samples]
else:
image_paths = image_paths[:num_samples]
preprocessed_imgs_np = []
for path in image_paths:
img = cv2.imread(path)
if img is None:
raise ValueError(f"无法读取图片: {path}")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, target_size, interpolation=cv2.INTER_NEAREST)
img = img.transpose(2, 0, 1).astype(np.float32) / 255.0
preprocessed_imgs_np.append(img)
imgs_np = np.stack(preprocessed_imgs_np)
imgs_tensor = torch.from_numpy(imgs_np)
if torch.cuda.is_available():
imgs_tensor = imgs_tensor.cuda()
print_memory_status("图片加载并转移到GPU后")
return imgs_np, imgs_tensor
def init_onnx_session_jetson(model_path):
providers = ['CPUExecutionProvider']
if torch.cuda.is_available():
providers = [
('CUDAExecutionProvider', {
'device_id': 0,
'arena_extend_strategy': 'kNextPowerOfTwo',
'gpu_mem_limit': 1 * 1024 * 1024 * 1024,
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
}),
'CPUExecutionProvider'
]
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_BASIC
sess_options.intra_op_num_threads = 4
sess = ort.InferenceSession(model_path, sess_options=sess_options, providers=providers)
input_name = sess.get_inputs()[0].name
print_memory_status("ONNX模型加载完成")
return sess, input_name
# ===================== 核心测试函数(适配FP32 Engine) =====================
def batch_speed_test_jetson(model_path, image_folder, batch_size=1, num_batches=30, warmup_batches=3):
jetson_hardware_optimize()
target_size = (640, 640)
max_mem = 0.0
print(f"\n📌 加载模型: {model_path}")
model_basename = os.path.basename(model_path).lower()
model_format = os.path.splitext(model_path)[-1].lower()
is_onnx = model_format == '.onnx'
is_engine = model_format == '.engine'
is_pt = model_format == '.pt'
is_fp32_engine = is_engine and 'fp32' in model_basename
is_fp16_engine = is_engine and 'fp16' in model_basename
is_int8_engine = is_engine and 'int8' in model_basename
model = None
onnx_sess = None
onnx_input_name = None
if is_onnx:
onnx_sess, onnx_input_name = init_onnx_session_jetson(model_path)
else:
model = YOLO(model_path, task='detect')
if is_pt:
model.fuse()
if torch.cuda.is_available():
model = model.cuda().half()
override_params = {
'conf': 0.25,
'iou': 0.45,
'imgsz': target_size,
'device': 0 if torch.cuda.is_available() else 'cpu'
}
if is_pt:
override_params['half'] = True if torch.cuda.is_available() else False
model.overrides.update(override_params)
print_memory_status("YOLO模型加载完成(仅模型权重)")
total_samples = (num_batches + warmup_batches) * batch_size
imgs_np, imgs_tensor = load_and_preprocess_images_jetson(image_folder, target_size, total_samples)
print(f"🔥 预热中... ({warmup_batches} batches)")
for i in range(warmup_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
if is_onnx:
batch_np = imgs_np[start_idx:end_idx].astype(np.float32)
_ = onnx_sess.run(None, {onnx_input_name: batch_np})
else:
batch_tensor = imgs_tensor[start_idx:end_idx]
with torch.no_grad():
_ = model.predict(
source=batch_tensor,
verbose=False,
imgsz=target_size,
device=0 if torch.cuda.is_available() else 'cpu'
)
print_memory_status("预热完成后")
print(f"🚀 正式测试... ({num_batches} batches)")
infer_times = []
e2e_times = []
monitor_batches = min(3, num_batches)
for i in range(num_batches):
start_idx = (warmup_batches + i) * batch_size
end_idx = start_idx + batch_size
if i < monitor_batches:
print_memory_status(f"第{i + 1}批次推理前")
e2e_start = time.perf_counter()
if torch.cuda.is_available():
torch.cuda.synchronize()
infer_start = time.perf_counter()
if is_onnx:
batch_np = imgs_np[start_idx:end_idx].astype(np.float32)
_ = onnx_sess.run(None, {onnx_input_name: batch_np})
else:
batch_tensor = imgs_tensor[start_idx:end_idx]
with torch.no_grad():
predict_kwargs = {
'source': batch_tensor,
'verbose': False,
'imgsz': target_size,
'device': 0 if torch.cuda.is_available() else 'cpu',
'stream': False
}
_ = model.predict(**predict_kwargs)
if torch.cuda.is_available():
torch.cuda.synchronize()
infer_end = time.perf_counter()
e2e_end = time.perf_counter()
if i < monitor_batches:
print_memory_status(f"第{i + 1}批次推理后")
infer_time = infer_end - infer_start
e2e_time = e2e_end - e2e_start
if infer_time < 1.0:
infer_times.append(infer_time)
e2e_times.append(e2e_time)
print_memory_status("所有批次测试完成后")
def robust_stats_jetson(data):
if not data:
return {'avg': 0, 'median': 0, 'min': 0, 'max': 0}
sorted_data = sorted(data)
trim_len = max(1, int(len(sorted_data) * 0.1))
trimmed_data = sorted_data[trim_len:-trim_len] if trim_len > 0 else sorted_data
return {
'avg': np.mean(trimmed_data),
'median': np.median(trimmed_data),
'min': np.min(trimmed_data),
'max': np.max(trimmed_data)
}
infer_stats = robust_stats_jetson(infer_times)
e2e_stats = robust_stats_jetson(e2e_times)
if torch.cuda.is_available():
max_mem = torch.cuda.max_memory_allocated() / 1024 / 1024
print("\n【最终显存统计】")
print(f" 测试全程峰值GPU显存占用: {max_mem:.2f} MB")
if is_engine:
if is_fp32_engine:
print(f" 说明:FP32 Engine模型权重显存约为FP16的2倍,临时显存占用也更高")
elif is_fp16_engine:
print(f" 说明:FP16 Engine是平衡显存和性能的最优选择(Jetson推荐)")
elif is_int8_engine:
print(f" 说明:INT8 Engine显存占用最低,但精度略有损失")
elif is_onnx:
print(f" 说明:ONNX模型显存由ONNX Runtime独立管理,以上仅为PyTorch侧统计")
precision_tag = ""
if is_fp32_engine:
precision_tag = "(FP32)"
elif is_fp16_engine:
precision_tag = "(FP16)"
elif is_int8_engine:
precision_tag = "(INT8)"
print("\n==================== 推理性能测试结果(Jetson版) ====================")
print(
f"模型格式: {model_format.upper()} {precision_tag} | 批次大小: {batch_size} | 有效测试批次: {len(infer_times)}")
print("\n【核心推理性能】")
print(f" 平均批次时间: {infer_stats['avg']:.4f}s")
print(f" 中位数批次时间: {infer_stats['median']:.4f}s")
print(f" 平均每帧时间: {infer_stats['avg'] / batch_size * 1000:.2f}ms")
print(f" 推理FPS: {batch_size / infer_stats['avg']:.2f} FPS")
print("\n【实际部署性能】")
print(f" 平均批次时间: {e2e_stats['avg']:.4f}s")
print(f" 平均每帧时间: {e2e_stats['avg'] / batch_size * 1000:.2f}ms")
print(f" 端到端FPS: {batch_size / e2e_stats['avg']:.2f} FPS")
print("\n【稳定性指标】")
print(f" 推理时间标准差: {np.std(infer_times):.4f}s")
if infer_stats['avg'] > 0:
print(f" 推理时间变异系数: {np.std(infer_times) / infer_stats['avg'] * 100:.2f}%")
else:
print(f" 推理时间变异系数: N/A")
return {
'model_path': model_path,
'model_format': model_format,
'precision': 'fp32' if is_fp32_engine else 'fp16' if is_fp16_engine else 'int8' if is_int8_engine else 'fp32',
'batch_size': batch_size,
'infer_fps': batch_size / infer_stats['avg'],
'e2e_fps': batch_size / e2e_stats['avg'],
'avg_infer_time_per_frame': infer_stats['avg'] / batch_size * 1000,
'avg_e2e_time_per_frame': e2e_stats['avg'] / batch_size * 1000,
'peak_gpu_mem_mb': max_mem
}
# ===================== CSV导出函数(Excel专用) =====================
def export_results_to_csv(results, csv_path="jetson_yolo_performance.csv"):
"""将测试结果导出为CSV文件,方便Excel打开和制作图表"""
# 定义CSV列名(和Excel表头对应,中文更易读)
fieldnames = [
"模型路径", "格式", "精度", "批次大小",
"推理FPS", "端到端FPS", "平均每帧时间(ms)",
"端到端每帧时间(ms)", "峰值显存(MB)"
]
# 写入CSV文件
with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # 写入表头
for res in results:
# 数据四舍五入保留2位小数,Excel里更整洁
writer.writerow({
"模型路径": res['model_path'],
"格式": res['model_format'],
"精度": res['precision'],
"批次大小": res['batch_size'],
"推理FPS": round(res['infer_fps'], 2),
"端到端FPS": round(res['e2e_fps'], 2),
"平均每帧时间(ms)": round(res['avg_infer_time_per_frame'], 2),
"端到端每帧时间(ms)": round(res['avg_e2e_time_per_frame'], 2),
"峰值显存(MB)": round(res['peak_gpu_mem_mb'], 2)
})
print(f"\n✅ CSV数据文件已导出到:{os.path.abspath(csv_path)}")
print("👉 直接用Excel打开该文件,即可一键生成FPS/显存对比图表!")
# ===================== 主函数 =====================
def main():
# 测试配置
MODEL_PATHS = [
"./yolov8n.pt",
"./yolov8n.onnx",
"./yolov8n_fp32.engine",
"./yolov8n_fp16.engine",
"./yolov8n_int8.engine"
]
IMAGE_FOLDER = "./datasets/coco128/images/train2017"
BATCH_SIZE = 1
NUM_BATCHES = 30
WARMUP_BATCHES = 3
# 环境检查
if not torch.cuda.is_available():
print("⚠️ 未检测到CUDA,将使用CPU推理(速度极慢)")
if not os.path.exists(IMAGE_FOLDER):
raise FileNotFoundError(f"图片文件夹不存在: {IMAGE_FOLDER}")
# 过滤有效模型
valid_models = []
for model_path in MODEL_PATHS:
if os.path.exists(model_path):
valid_models.append(model_path)
else:
print(f"⚠️ 模型文件不存在,跳过: {model_path}")
if not valid_models:
raise ValueError("没有找到有效的模型文件,请检查MODEL_PATHS配置")
# 开始测试
print("===== 开始Jetson平台模型推理速度测试 =====")
print(f"测试配置:批次大小={BATCH_SIZE} | 测试批次={NUM_BATCHES} | 预热批次={WARMUP_BATCHES}")
print(f"图片文件夹:{IMAGE_FOLDER}")
print(f"待测试模型数量:{len(valid_models)}")
all_results = []
for model_path in valid_models:
try:
print("\n" + "-" * 60)
result = batch_speed_test_jetson(
model_path=model_path,
image_folder=IMAGE_FOLDER,
batch_size=BATCH_SIZE,
num_batches=NUM_BATCHES,
warmup_batches=WARMUP_BATCHES
)
all_results.append(result)
except Exception as e:
print(f"❌ 测试模型 {model_path} 失败: {str(e)}")
import traceback
traceback.print_exc()
continue
# 1. 对齐的表格输出(命令行)
print("\n" + "=" * 120)
print("==================== 所有模型性能汇总(Jetson版) ====================")
header = f"{'模型路径':<35} | {'格式':<6} | {'精度':<5} | {'FPS':<8} | {'每帧时间(ms)':<15} | {'峰值显存(MB)':<15}"
print(header)
print("-" * 120)
# 准备文本报告内容
report_content = [
"===== Jetson Orin Super YOLOv8 性能测试报告 =====",
f"测试时间: {time.strftime('%Y-%m-%d %H:%M:%S')}",
f"测试配置:批次大小={BATCH_SIZE} | 测试批次={NUM_BATCHES} | 预热批次={WARMUP_BATCHES}",
f"图片文件夹:{IMAGE_FOLDER}",
"\n" + header,
"-" * 120
]
# 打印并收集每一行数据
for res in all_results:
line = (
f"{res['model_path']:<35} | "
f"{res['model_format']:<6} | "
f"{res['precision']:<5} | "
f"{res['infer_fps']:<8.2f} | "
f"{res['avg_infer_time_per_frame']:<15.2f} | "
f"{res['peak_gpu_mem_mb']:<15.2f}"
)
print(line)
report_content.append(line)
# 2. 输出最优模型
if all_results:
best_model = max(all_results, key=lambda x: x['infer_fps'])
best_lines = [
"\n🏆 最优性能模型:",
f" 模型路径:{best_model['model_path']}",
f" 模型精度:{best_model['precision']}",
f" 推理FPS:{best_model['infer_fps']:.2f}",
f" 每帧耗时:{best_model['avg_infer_time_per_frame']:.2f}ms",
f" 峰值显存:{best_model['peak_gpu_mem_mb']:.2f}MB",
"\n📊 精度-性能对比总结:"
]
for line in best_lines:
print(line)
report_content.append(line)
# 精度对比
engine_results = [r for r in all_results if r['model_format'] == '.engine']
for res in engine_results:
engine_line = f" {res['precision'].upper()} Engine: {res['infer_fps']:.2f} FPS | {res['avg_infer_time_per_frame']:.2f} ms/帧"
print(engine_line)
report_content.append(engine_line)
# 3. 导出CSV文件(核心:供Excel使用)
export_results_to_csv(all_results)
if __name__ == "__main__":
main()
✏️如果想评估自己的模型,只需要自己替换导出的模型文件路径即可。
MODEL_PATHS = [
"./yolov8n.pt",
"./yolov8n.onnx",
"./yolov8n_fp32.engine",
"./yolov8n_fp16.engine",
"./yolov8n_int8.engine"
]
整体上,软件设计尽可能做到对推理性能的客观评估,将帧率分成了端到端FPS和推理FPS:
- 纯推理时间:仅计算模型前向传播耗时,反映模型本身性能;
- 端到端时间:包含数据传输、推理、结果处理全流程,贴合实际部署;
另外,将模型先预热(3 个批次)再测试,避免 GPU 初始化、算子编译等首次耗时干扰。
不仅如此,还专门针对英伟达的硬件设备,做了专属优化:
- 针对性开启cudnn.benchmark、TF32等 GPU 优化开关,限制显存使用比例(70%),避免 Jetson 显存溢出;
- 清理显存缓存、重置显存统计,确保每次测试从 “干净环境” 开始,数据无干扰。
💥重点在以下配置:
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.deterministic = False
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
benchmark = True,让 cuDNN(英伟达的 GPU 加速库)先 “试跑” 找最优算法,后续推理固定用这个最优算法。deterministic = False,关闭 “确定性计算”,允许 cuDNN 用非确定性算法换速度。设为True时,每次运行同一个模型,输出结果的小数点后几位完全一致(确定性),但会禁用部分高速并行算法。
matmul.allow_tf32 = True和allow_tf32 = True,TF32英伟达定制的 “精简版 FP32”。
FP32:符号位 1 + 指数位 8 + 尾数位 23;
TF32:符号位 1 + 指数位 8 + 尾数位 10;
用 TF32 替代 FP32 做计算,速度提升 2~4 倍,精度几乎无损失。
关于浮点运算的更多细节,请参考:嵌入式视角下的浮点运算性能之迷
4.1.3 评估过程展示
新建.py文件,然后将上述代码复制进去,就可以直接用命令行运行了。运行中的输出如下: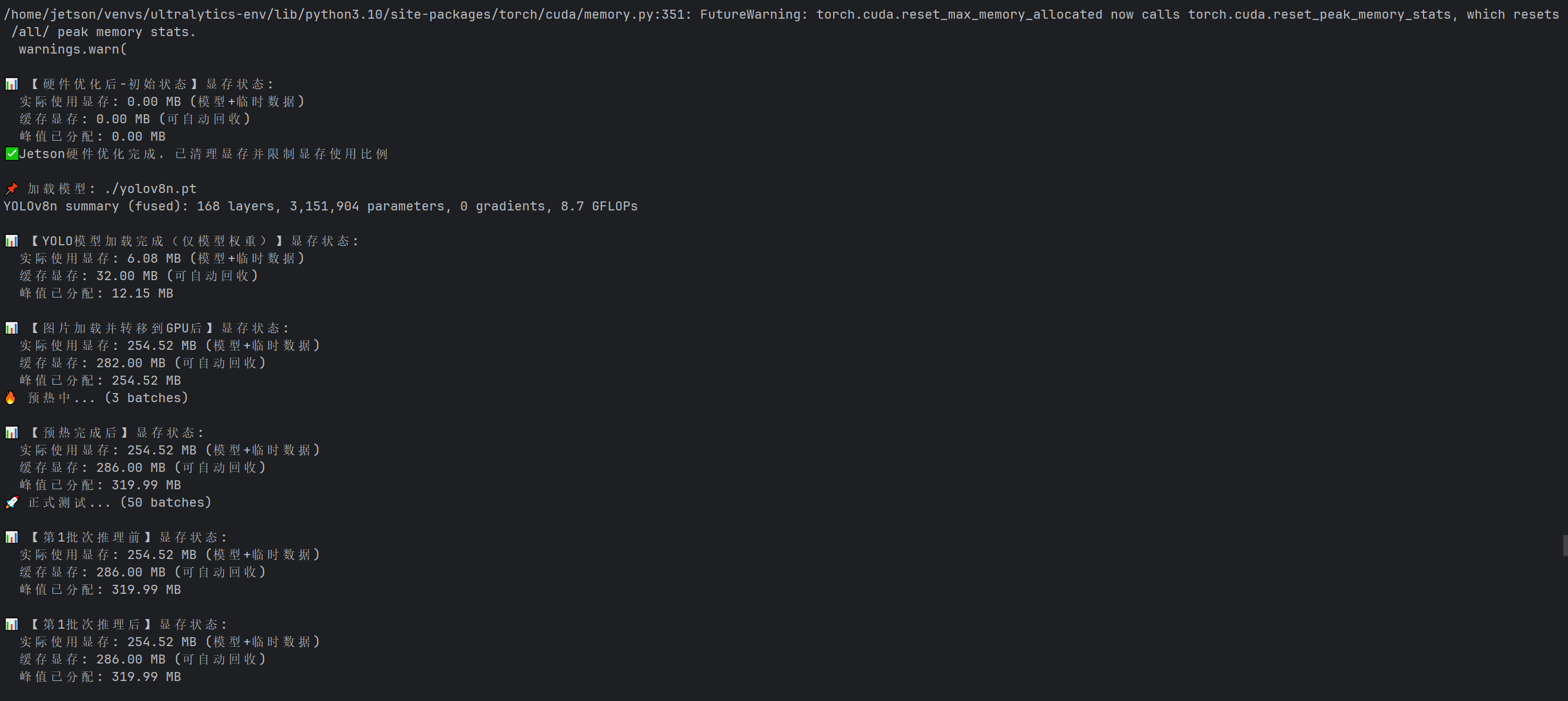

这里只贴出.pt模型的输出结果,其他4种模型都是类似的。
在命令窗口输出的结果中可以看到,每个批次推理前后的实际显存与实际显存变化并不大,这恰恰是 batch_size=1 在 Jetson 上的理想表现:
模型权重(约 6MB)和输入张量(约 4.6MB)的显存占用是固定的;
推理产生的临时张量在计算结束后被 PyTorch 自动回收,显存立刻回到初始水平;
“推理后显存无残留” 的状态,完全适配边缘设备 “单帧连续推理” 的场景,不会因为显存累积导致 OOM。
4.1.4 评估结果展示
测试代码不仅可以在命令行输出各种测试参数,同时也可以输出一份csv表格,可以直接看csv表格中的数据即可。
✏️1. 推理帧率分析
-
TensorRT 引擎碾压式领先:
TensorRT 引擎(尤其是 INT8/FP16 版本)相比 ONNX 模型有 12–22 倍 的性能提升,这是因为 TensorRT 对 Jetson 的 GPU 做了深度优化(层融合、量化、自动调优)。 -
量化精度的加速效果:
INT8 Engine 比 FP32 Engine 快 1.69×,FP16 Engine 比 FP32 Engine 快 1.53×,说明量化是边缘设备上比较有效的加速手段。 -
原生 .pt 模型的瓶颈:
PyTorch 原生模型的推理速度只有 TensorRT INT8 引擎的 29%,主要因为缺少硬件级优化,推理效率较低。 -
ONNX 模型的性能陷阱:
ONNX 模型在 Jetson 上的表现最差,仅 7.56 FPS,这是因为 ONNX Runtime 对 Jetson 的 GPU 优化不足,大量计算 fallback 到 CPU,导致性能严重下降。
✏️2. 显存占用分析
-
量化与显存的关系:
INT8 Engine 的显存占用(286.59 MB)略高于 FP16/FP32 Engine,这是因为 INT8 量化需要额外的校准表和量化参数,以及 TensorRT 为保持精度而引入的补偿计算,导致显存略有增加。 -
原生 .pt 模型的显存冗余:
PyTorch 原生模型的显存占用最高(319.99 MB),主要是因为 PyTorch 运行时的缓存机制和未优化的张量分配,显存利用率较低。 -
ONNX 模型的显存假象:
ONNX 模型显存占用最低(254.52 MB),但这是以牺牲性能为代价的 —— 大部分计算在 CPU 上完成,GPU 仅用于部分算子,显存占用低但速度极慢(onnx模型是所有模型中推理速度最慢的),没有实际部署价值。
5. 总结
实验以 Jetson Orin Super 为硬件平台,对 YOLOv8n 模型的 PyTorch 原生、ONNX、TensorRT 3种不同程度的量化模型共 5 种格式展开系统性评估。
通过精度曲线(F1/P/R/PR)验证了非量化模型及 FP16 模型的精度稳定性,仅 INT8 模型存在较大精度损失;性能测试则显示 TensorRT 量化模型表现突出,其中 INT8 Engine 实现 165.99 FPS 的推理速度,是 ONNX 模型的 22 倍,FP16 Engine 则以 149.62 FPS 的性能和几乎无损失的精度成为边缘部署的黄金选择,PyTorch 原生模型因动态编译导致显存波动大、ONNX 模型因 CPU fallback 性能极差,均不适合实际部署。
表面上FP32比FP16的数据表达准确很多,但FP32 的额外精度更多是 “长尾噪声”,FP32 的 23 位尾数位能提供更高的绝对精度,但对 CV 任务来说,这部分额外精度大多是 “无用的长尾噪声”:
- 模型训练时的梯度更新、权重初始化本身就带有随机性,FP32 的额外精度无法消除这些固有噪声;
- 实际部署中,输入图片的噪声、光线变化等干扰,对精度的影响远大于 FP16 与 FP32 的数值差异;
- 对于 Jetson Orin Super 平台来说,安培架构的FP32是自定义的TF32,是“精简版”的32位浮点数,并不是真正意义上的32位浮点数,这样也会对评估结果有轻微的影响。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)