计算机视觉——Opencv(摄像头动态轮廓识别)
在数字化办公场景中,文档扫描是高频需求 —— 无论是纸质合同、手写笔记还是纸质报表,都需要快速转化为规整的数字格式。传统扫描仪操作繁琐,而手机 / 电脑摄像头扫描又容易因拍摄角度导致文档变形。本文将手把手教你用 Python+OpenCV 实现实时摄像头文档扫描与自动矫正,无需专业硬件,只需几行代码就能完成从画面捕捉、边缘检测到透视变换的全流程,最终输出规整的文档图像。
一、核心技术原理
1.图像预处理:将摄像头捕获的彩色帧转为灰度图,通过滤波去噪、边缘检测提取文档轮廓;
2.轮廓识别:从边缘图像中筛选出面积最大的矩形轮廓(即文档区域);
3.透视变换:根据文档的四个顶点坐标,将倾斜 / 变形的文档矫正为正射视角;
4.二值化优化:将矫正后的文档转为黑白对比图,提升可读性。
二、设计流程
本项目实现的核心能力可以概括为以下 5 步:
-
调用电脑摄像头,实时捕获画面;
-
对每一帧图像做灰度化、高斯模糊、Canny 边缘检测,突出文档边界;
-
在边缘图中寻找轮廓,自动筛选出最大的四边形(即文档区域);
-
对识别到的四边形区域执行四点透视变换,把倾斜、扭曲的文档拉正;
-
对矫正后的文档执行二值化增强,让文字更清晰、背景更干净,接近扫描件效果。
整个过程全自动执行,无需手动框选、无需手动调节参数,将文档对准摄像头即可自动完成处理。
三、完整代码
本项目只依赖两个最基础的科学计算与计算机视觉库:
-
numpy:用于数值计算、坐标处理、矩阵运算等; -
cv2(OpenCV):实现图像读取、预处理、边缘检测、轮廓查找、透视变换、窗口显示等。
import numpy as np
import cv2
def cv_show(name, img):
"""
图像显示函数:添加ESC键退出逻辑,避免窗口阻塞
参数:
name: 窗口名称
img: 要显示的图像数组
返回:
True-按下ESC键退出,False-未按ESC键
"""
cv2.imshow(name, img)
# 等待1ms检测按键,0xFF处理跨平台兼容性
key = cv2.waitKey(1) & 0xFF
if key == 27: # ESC键的ASCII码为27
return True
return False
def order_points(pts):
"""
对检测到的四个顶点坐标进行排序(左上、右上、右下、左下)
参数:
pts: 包含4个坐标点的数组,形状为(4,2)
返回:
rect: 排序后的坐标数组
"""
rect = np.zeros((4, 2), dtype="float32")
# 左上点:x+y值最小;右下点:x+y值最大
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 右上点:x-y值最小;左下点:x-y值最大
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
"""
透视变换:将倾斜文档矫正为正射视角
参数:
image: 原始图像
pts: 文档的四个顶点坐标
返回:
warped: 矫正后的图像
"""
# 对顶点坐标排序
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算矫正后图像的宽度(取左右两边的最大值)
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
# 计算矫正后图像的高度(取上下两边的最大值)
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 定义目标图像的四个顶点(正射视角)
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype="float32")
# 计算透视变换矩阵并应用
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
# 主程序逻辑
def main():
# 打开摄像头(0为默认摄像头,多摄像头可尝试1、2)
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("错误:无法打开摄像头,请检查摄像头是否被占用")
return
print("提示:按ESC键可随时退出程序,将文档置于摄像头前,程序会自动检测并处理")
while True:
detect_flag = 0 # 文档检测标识:0-未检测,1-已检测
ret, frame = cap.read() # 读取摄像头帧
orig_frame = frame.copy() # 保存原始帧(用于后续透视变换)
if not ret:
print("错误:无法读取摄像头画面")
break
# 显示原始摄像头画面
if cv_show("原始画面", frame):
break
# 1. 图像预处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转为灰度图
gray = cv2.GaussianBlur(gray, (5, 5), 0) # 高斯滤波去噪
edged = cv2.Canny(gray, 15, 45) # Canny边缘检测
# 显示边缘检测结果
if cv_show("边缘检测", edged):
break
# 2. 轮廓检测与筛选
# 查找外部轮廓(RETR_EXTERNAL),压缩轮廓点(CHAIN_APPROX_SIMPLE)
contours = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
# 按轮廓面积降序排序,取前3个(减少计算量)
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:3]
# 绘制所有候选轮廓(绿色)
frame_contours = cv2.drawContours(frame, contours, -1, (0, 255, 0), 2)
# 显示轮廓检测结果
if cv_show("轮廓检测", frame_contours):
break
# 3. 筛选文档轮廓(4个顶点+面积足够大)
for cnt in contours:
peri = cv2.arcLength(cnt, closed=True) # 计算轮廓周长
# 轮廓近似:减少点数(0.05*peri为近似精度)
approx = cv2.approxPolyDP(cnt, 0.05 * peri, closed=True)
area = cv2.contourArea(approx) # 计算近似轮廓面积
# 筛选条件:4个顶点(矩形)+ 面积>40000(排除小轮廓,可根据实际调整)
if len(approx) == 4 and area > 40000:
doc_contour = approx
detect_flag = 1
print(f"检测到文档:周长={peri:.2f},面积={area:.2f}")
break
# 4. 检测到文档后执行矫正与优化
if detect_flag == 1:
# 绘制文档轮廓(加粗显示)
frame_doc = cv2.drawContours(frame, [doc_contour], 0, (0, 0, 255), 3)
if cv_show("文档轮廓", frame_doc):
break
# 透视变换矫正文档
warped_doc = four_point_transform(orig_frame, doc_contour.reshape(4, 2))
if cv_show("矫正后文档", warped_doc):
break
# 二值化处理(提升对比度)
warped_gray = cv2.cvtColor(warped_doc, cv2.COLOR_BGR2GRAY)
# OTSU自动阈值二值化
binary_doc = cv2.threshold(warped_gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if cv_show("最终文档(二值化)", binary_doc):
break
print("文档处理完成!")
break # 处理完成后退出循环
# 释放资源(关键:避免摄像头占用)
cap.release()
cv2.destroyAllWindows()
print("程序正常结束")
if __name__ == "__main__":
main()四、核心函数解析
key == 27:检测是否按下 ESC 键(ASCII 码 27),按下则返回 True,触发程序退出
key = cv2.waitKey(1) & 0xFF:
0xFF 是为了保证在不同系统(Windows/Linux/macOS)上都能正确获取按键值。
顶点排序函数 order_points
文档的四个顶点坐标是无序的,必须按 左上、右上、右下、左下 排序才能正确执行透视变换:
x+y 最小值:左上点(画面中最靠左上的点);
x+y 最大值:右下点(画面中最靠右下的点);
x-y 最小值:右上点(x 大 y 小);
x-y 最大值:左下点(x 小 y 大)。
透视变换函数 four_point_transform
这是文档矫正的核心:
-
计算矫正后图像的宽度 / 高度:取文档左右 / 上下两边的最大长度,避免矫正后图像缺失;
-
定义目标坐标:将文档映射到「(0,0) → (maxWidth-1,0) → (maxWidth-1,maxHeight-1) → (0,maxHeight-1)」的矩形区域;
-
cv2.getPerspectiveTransform:计算透视变换矩阵 M; -
cv2.warpPerspective:应用变换矩阵,得到矫正后的文档。
图像预处理流程:彩色帧→灰度图→高斯滤波→Canny 边缘检测,逐步提取文档
轮廓筛选:
1.cv2.findContours:查找外部轮廓(排除内部小轮廓);
2.按面积排序取前 3 个:减少非文档轮廓的干扰;
3.cv2.approxPolyDP:轮廓近似,将不规则轮廓转为多边形;
4.筛选条件:4 个顶点(矩形)+ 面积 > 40000(排除小物体,可根据摄像头分辨率调整);
五、实际效果展示
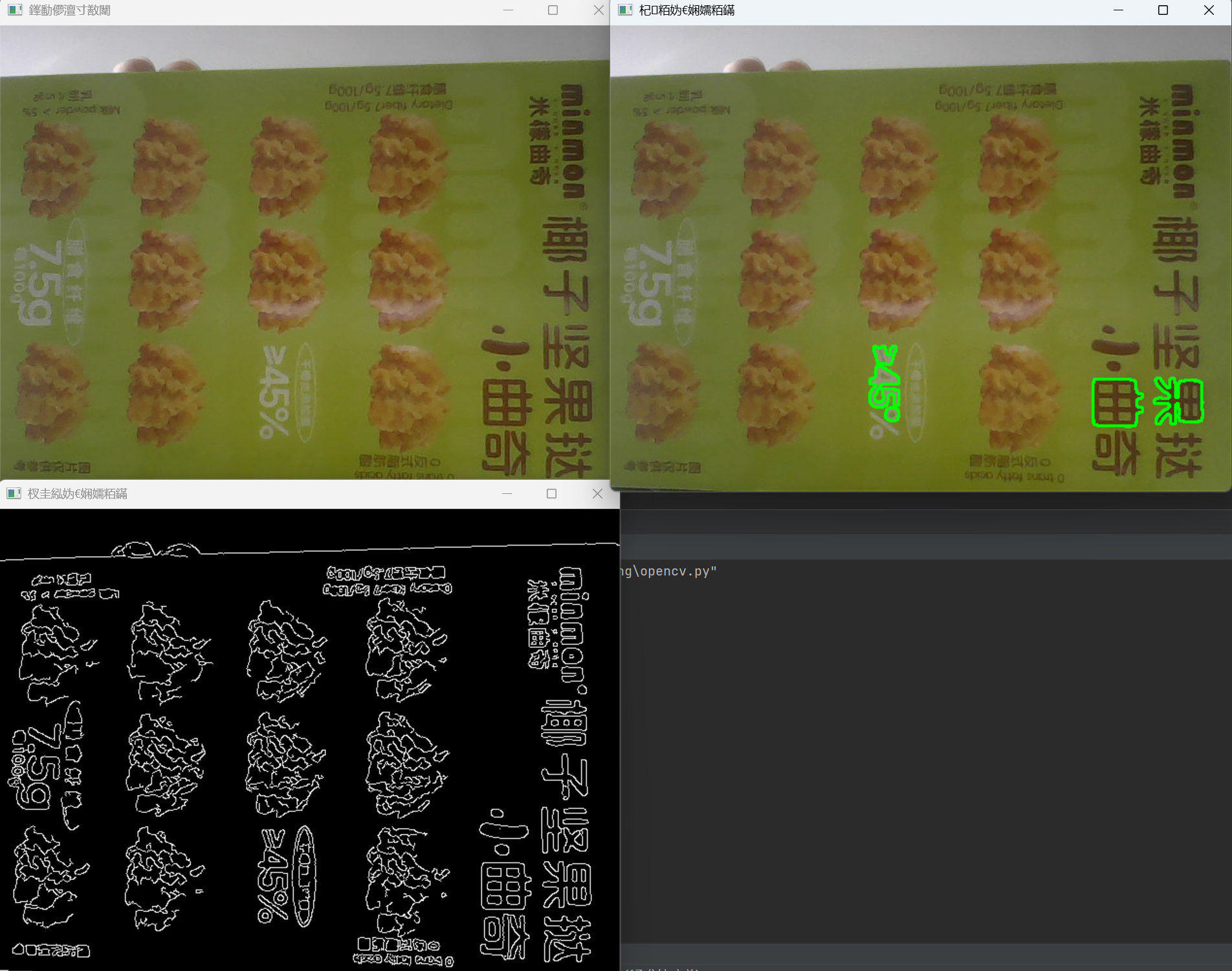

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)