▲基于Q-Learning强化学习的无人驾驶小车城市道路行驶控制系统matlab性能仿真
本文介绍了一种基于Q-Learning强化学习的无人驾驶小车城市道路行驶控制系统。系统将城市道路环境离散化为网格世界,定义小车的状态空间、动作空间(上、下、左、右、静止)和奖励函数。通过Q-Learning算法迭代训练,小车逐步学习最优行驶策略。Matlab仿真程序实现了三维城市场景的可视化,展示小车沿最优路径行驶过程。仿真结果表明,系统能有效使小车学会避开障碍物、遵守车道约束并到达目标位置。完整
目录
1.引言
基于Q-Learning强化学习的无人驾驶小车城市道路行驶控制系统,是将经典的Q-Learning表格型强化学习算法应用于城市道路环境中的自主驾驶决策问题。该系统的核心思想是:无人小车作为智能体(Agent),通过与城市道路环境(Environment)的不断交互,在每一个决策时刻感知当前状态,选择一个动作(如加速、减速、左转、右转、保持),并根据环境反馈的奖励信号逐步学习到一个最优策略,使得小车能够在城市道路中安全、高效地行驶,避开障碍物,遵守车道约束,最终到达目标位置。
2.系统实现基本原理
无人驾驶小车的行驶控制问题可以建模为一个马尔可夫决策过程,用五元组表示:
M=⟨S,A,P,R,γ⟩
其中,𝑆为状态空间,表示小车所有可能的状态集合;𝐴为动作空间,表示小车可以执行的所有动作集合;𝑃为状态转移概率函数,描述在状态𝑠下执行动作𝑎后转移到下一状态𝑠′的概率;𝑅为奖励函数,描述智能体执行某个动作后获得的即时奖励;γ∈[0,1]为折扣因子,用于权衡当前奖励与未来奖励的重要性。
2.1 环境建模与状态空间定义
将城市道路环境离散化为网格世界。小车的状态由其在网格中的位置坐标(x,y)(x,y)表示,状态空间大小为:

其中NxNx和NyNy分别为网格在xx和yy方向的格数。环境中设置道路区域、障碍物区域(建筑物、路障等)、起点与终点。
2.2 动作空间定义
定义无人小车在每个时刻可执行的动作集合为五个离散动作:
A={上,下,左,右,静止}A={上,下,左,右,静止}
每个动作对应位置的变化量:
![]()
2.3 奖励函数设计
奖励函数的设计直接影响学习效果,定义如下:


2.4 Q表初始化
创建Q表,维度为∣S∣×∣A∣∣S∣×∣A∣,初始化为零矩阵:
![]()
2.5 迭代训练过程
对于每一个训练回合(Episode)k=1,2,…,Kk=1,2,…,K:
(1)将小车置于起点s0s0;
(2)在每个时间步tt,根据ϵϵ-贪心策略选择动作atat;
(3)执行动作,观测下一状态st+1st+1和奖励rt+1rt+1;
(4)按照Q-Learning公式更新Q值:
![]()
(5)更新状态st←st+1st←st+1;
(6)若到达终点或碰撞或超出最大步数,结束本回合。
每回合结束后记录累积奖励:

2.6 策略提取
训练完成后,最优策略从Q表中提取:
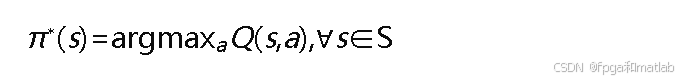
绘制训练过程中每回合的累积奖励曲线和每回合步数曲线,评估收敛情况。最终在三维城市场景中动画展示小车按照最优策略行驶的完整过程。
3.Matlab仿真程序
% --- 动画循环 ---
fprintf('开始三维动画演示...\n');
trailX = []; trailY = []; trailZ = [];
trailLine = plot3(nan, nan, nan, 'r-', 'LineWidth', 3);for i = 1:size(optimalPath, 1)
px = optimalPath(i, 2);
py = optimalPath(i, 1);
% 删除旧车体
delete(carBody);
delete(carRoof);
% 绘制新位置的车体
carBody = drawBox(px, py, carBodyZ, carLength/2, carWidth/2, carHeight, [0.1 0.3 0.9], ax);
carRoof = drawBox(px, py, carBodyZ+carHeight, carLength/3, carWidth/2.5, carHeight*0.5, [0.3 0.5 1], ax);
% 更新轨迹
trailX = [trailX, px];
trailY = [trailY, py];
trailZ = [trailZ, 0.1];
set(trailLine, 'XData', trailX, 'YData', trailY, 'ZData', trailZ);
% 动态视角跟随
if i > 5
view(35 + i*0.3, 40 + 10*sin(i*0.05));
end
title(sprintf('三维城市道路 - 步骤: %d/%d', i, size(optimalPath,1)), 'FontSize', 14);
drawnow;
pause(0.15);
endfprintf('动画演示完成!\n');
4.仿真结果分析
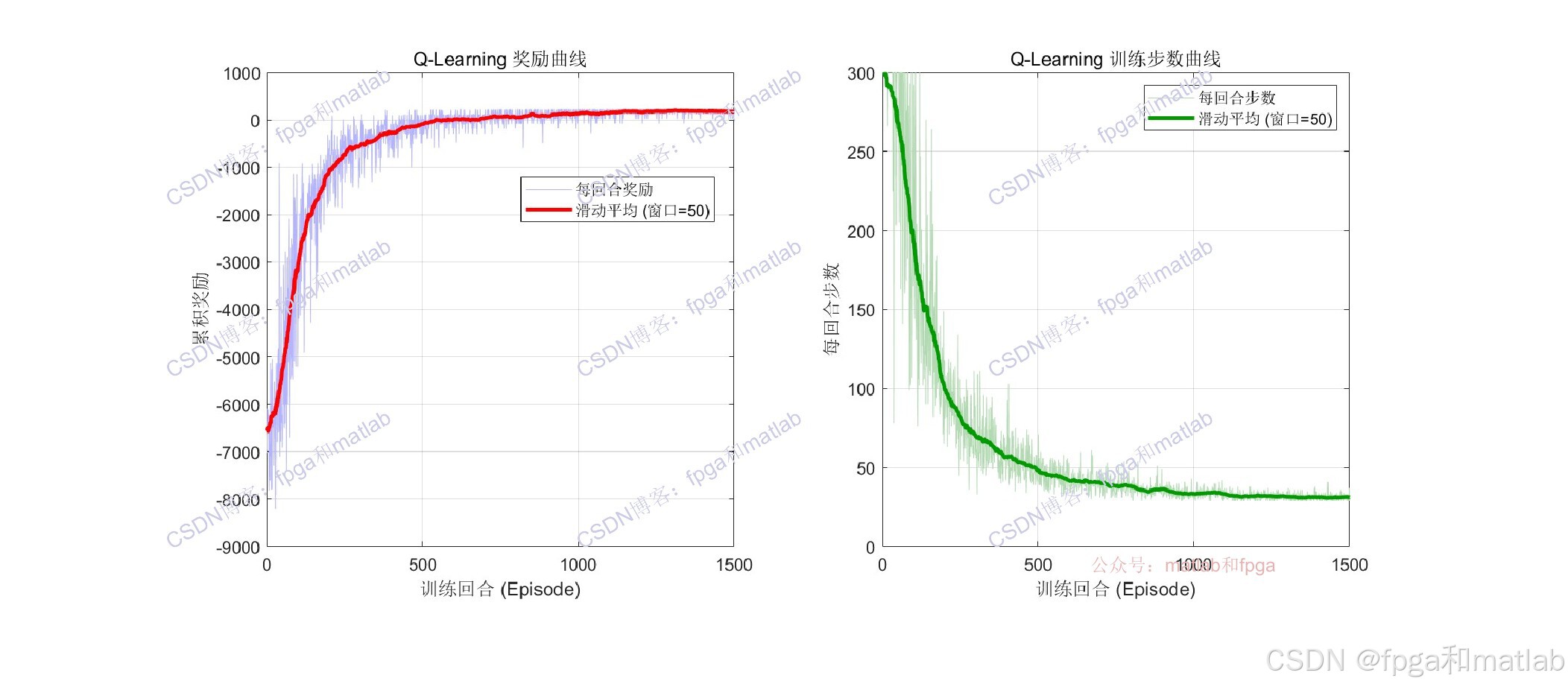
左图显示每回合累积奖励(浅蓝色)及其滑动平均(红色),可观察到奖励从负值逐步上升并收敛到正值。右图显示每回合步数逐步减少,表明小车学会了更短路径。
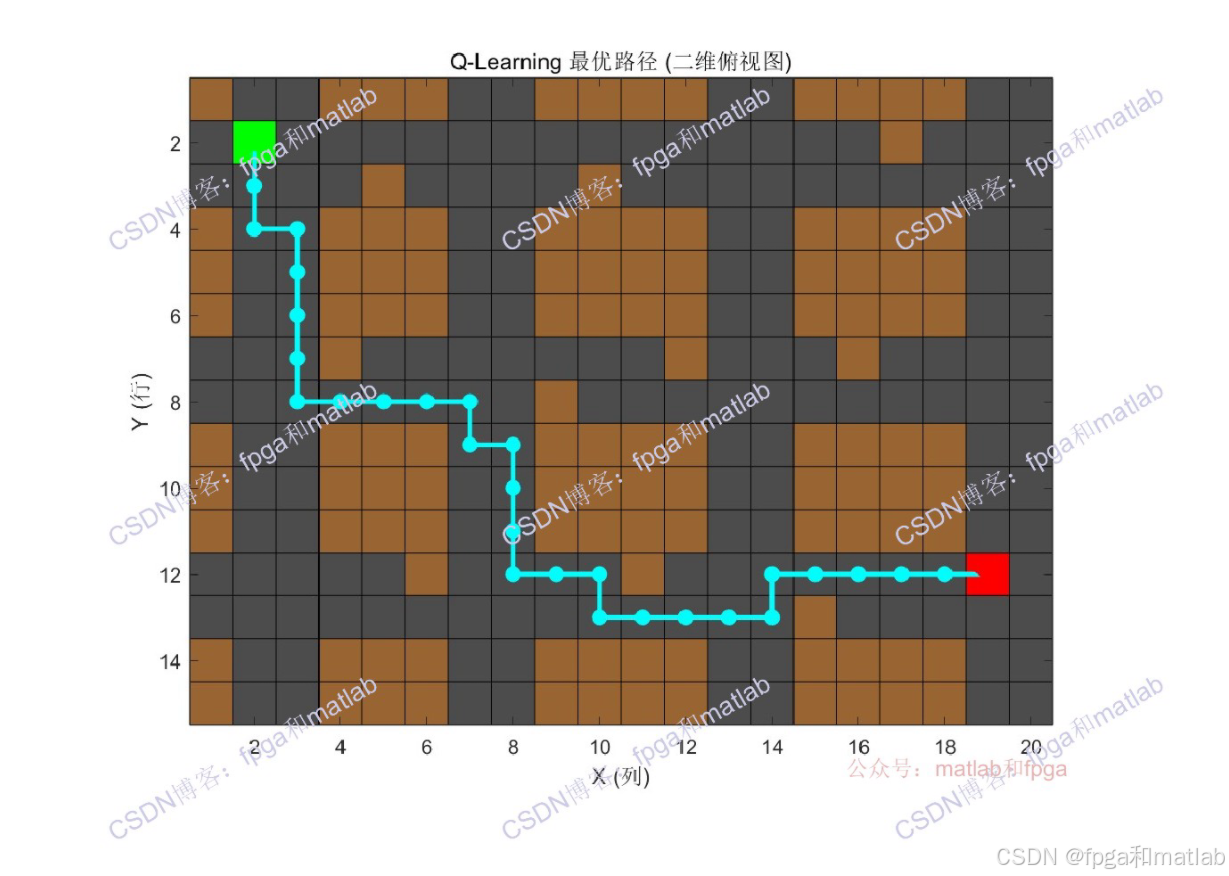
在网格地图上展示最优路径,深灰色为道路,棕色为建筑。
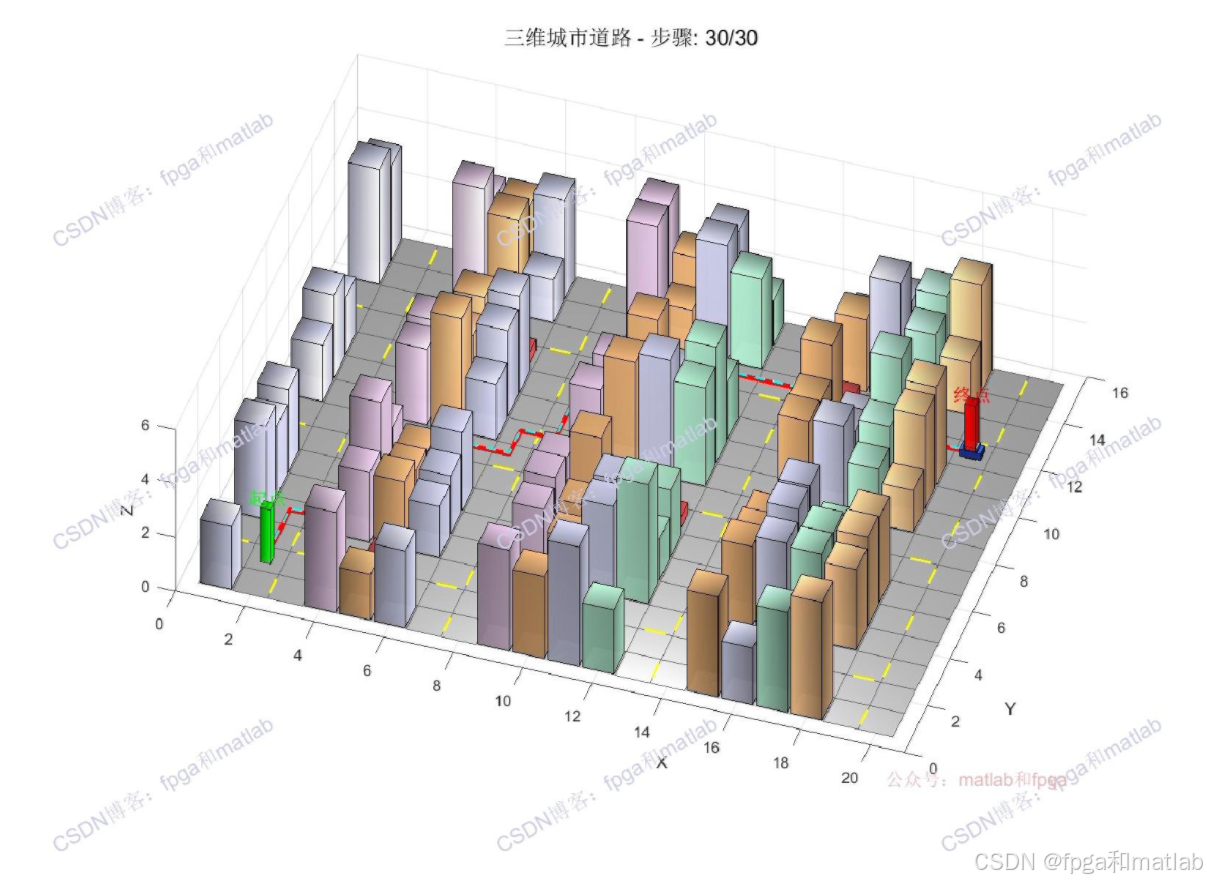
三维城市场景中,蓝色小车沿学习到的最优路径行驶,建筑物高低错落,红色轨迹实时显示。
5.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)