OpenClaw 里那些最容易搞混的概念
本文总结了作者使用OpenClaw AI工具的经验教训,重点解析了容易混淆的核心概念和工作原理。作者指出OpenClaw不是单一的智能体,而是一个包含多层次的系统:入口层接收消息,桥接层转发任务,agent执行层处理任务,能力层提供具体技能,结果验证层确认执行效果。常见问题如重复回复、任务未执行等往往源于中间层的桥接问题,而非AI模型本身。文章强调理解系统架构比追求"全自动"更
这篇不是“炫技复盘”,而是把我真实踩坑后总结出的认知地图讲清楚。
这段时间我一直在折腾 OpenClaw。最开始的时候,我以为它就是一个“装好之后就能自己干活”的 AI 工具,后来越用越发现,真正难的不是安装,而是理解它背后那一整套概念和链路。
你会看到很多词一起冒出来:agent、skill、prompt、session、bridge、中间层、飞书机器人、反向代理、执行层、模型、上下文。刚接触的时候,这些词很容易看得人一头雾水。更麻烦的是,它们听起来都像“AI 在干活”,但实际上分工完全不同。如果这些概念没有理顺,后面一出问题,你根本不知道该查哪一层。
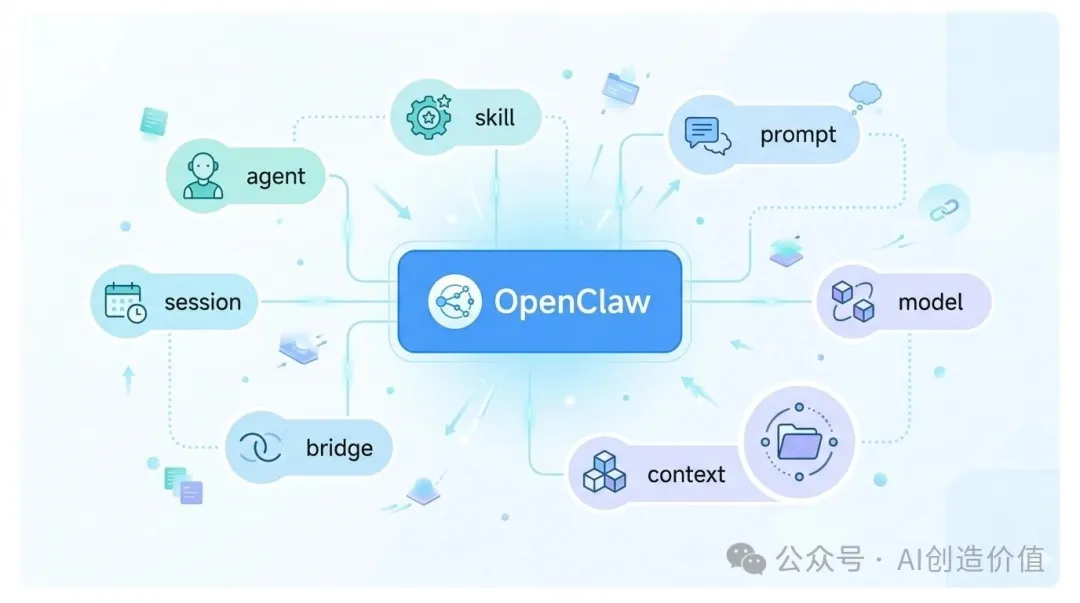
我为什么会开始认真梳理这些概念
我前面在折腾 OpenClaw 的过程中,就踩过很多这种坑。
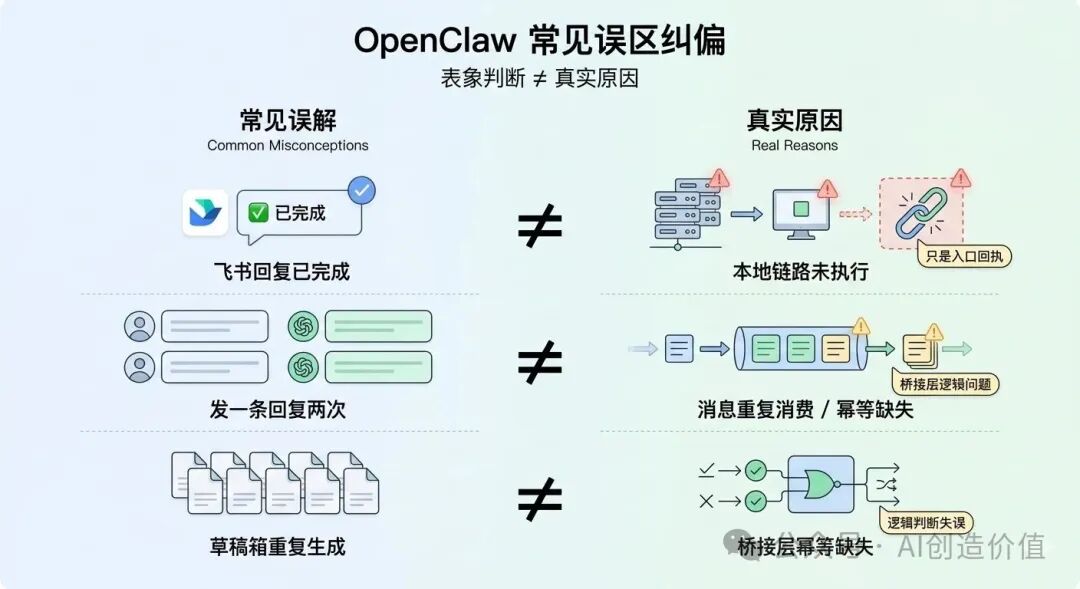
比如我会以为“飞书里回复了我一句任务执行完成”,就代表 OpenClaw 真的开始跑任务了;后来才发现,这可能只是机器人接收到了消息,并不代表真正的本地执行链路已经跑通。
又比如有时候我明明只发了一条消息,结果它回了两次,甚至帮我重复建了两份公众号草稿箱。一开始我以为是模型抽风,后面才慢慢意识到,这背后更可能是消息桥接、转发、中间层消费、幂等控制这些地方出了问题,而不是单纯一句“AI 不稳定”就能解释清楚。
所以这篇文章,我想做的不是泛泛地说 OpenClaw 很火、很厉害,而是把我自己前面真正踩过坑的这些概念,一次性梳理清楚。
希望写完之后,至少能让像我一样刚开始折腾 OpenClaw 的人,脑子里先有一张结构图:到底什么是 agent,什么是 skill,什么是 prompt,飞书机器人和 OpenClaw 本体是什么关系,中间层和桥接层到底在干什么,为什么会出现“看起来执行了,其实没执行”“重复回复”“重复生成草稿”这些现象。
OpenClaw 不是一个单独的“智能体”
先说我后来理解下来最重要的一点:OpenClaw 不是一个单独的“智能体”,而更像是一套让模型、工具、执行环境和外部入口连起来的系统。
你在最外层看到的,也许只是一个聊天窗口,或者一个飞书机器人,但那通常只是入口。真正干活的,往往不是那个“会回复你一句话”的表层,而是后面那一套执行链路。
四个最容易混淆的核心概念
1. agent:执行者
在这套链路里,agent 可以理解成“带着目标、上下文和工具能力去完成任务的执行体”。
很多人一开始会把 agent 理解成“一个 AI 分身”,这个说法不能说完全错,但太模糊了。更准确一点说,agent 是负责接住任务、理解目标、选择要不要调用 skill、要不要读上下文、要不要去执行工具,再把结果组织回来的一层。
它像一个任务执行者,而不只是一个聊天对象。
2. skill:能力包
skill 更像是 agent 可调用的专门能力包,或者一段被封装好的工作流。它不是凭空让 AI 变聪明,而是把某类重复任务的输入、处理逻辑、输出要求固化下来。
比如“联网搜索”“摘要总结”“生成公众号草稿”“执行某种固定格式的工作流”,这些都更接近 skill 的范畴。
所以 skill 的价值,不在于听起来高级,而在于它能不能稳定复用。如果一个流程本身都还不稳定,过早封成 skill,后面只会更难排查。
3. prompt:任务说明书
prompt 也很容易被误解。很多人会把 prompt 当成“让 AI 听话的魔法咒语”,但真正用久了就会发现,prompt 更像是一份任务说明书。
它会影响输出质量,但它不是系统架构本身。也就是说,prompt 决定的是“这次你想让它怎么做”,而 agent、skill、执行器、桥接层这些决定的是“它到底能不能真的做成”。
这也是为什么有时候你写了很长很细的 prompt,它表面答应得很好,但实际上根本没落地,因为问题压根不在 prompt,而在后面的链路没有通。
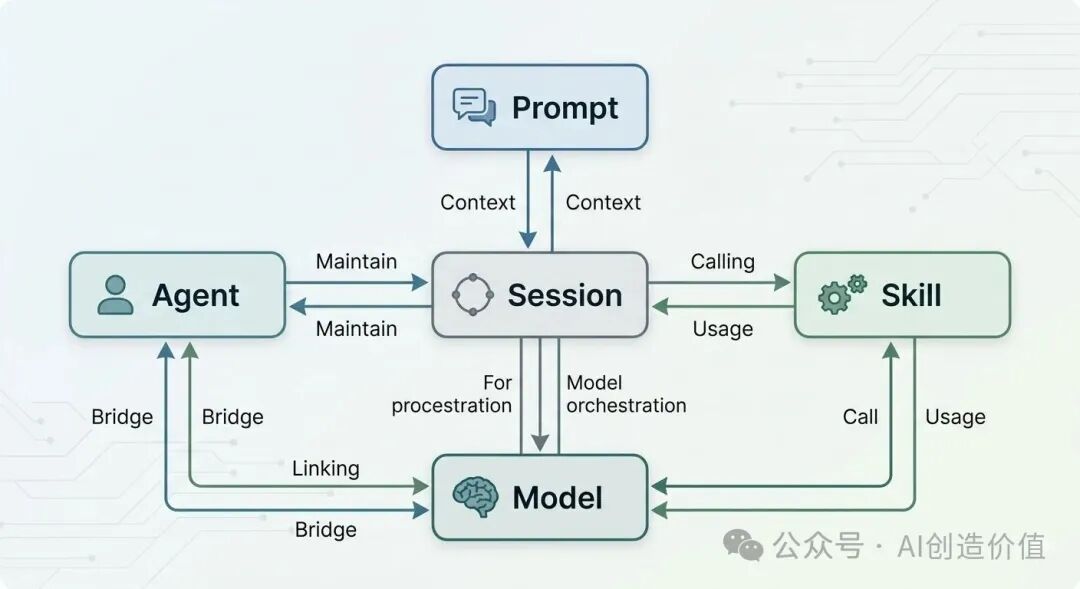
4. session:会话上下文
session 是另一个经常被忽略的概念。它本质上是一次上下文连续的会话范围。你在一个 session 里说过的话、补过的限制、纠正过的偏好,通常会影响后面的回答。
但 session 不等于长期记忆,也不等于 skill。很多人以为自己说过一次,OpenClaw 以后就都记住了,结果下次开新 session 又“失忆”了。这其实不是它故意骗你,而是 session 范围和长期持久化压根不是一回事。
为什么入口层最容易让人误判
再往外一层,就是你最容易直接接触到的飞书机器人、聊天界面、Web 面板这些入口。这个地方特别容易让人误判。
因为从用户视角看,你是“给 OpenClaw 发消息”;但从系统视角看,消息往往是先进入一个外部入口,比如飞书机器人,再被转发到桥接层或者中间层,最后才有可能真正进入 OpenClaw 的执行体系。
所以飞书里回你一句“收到”“执行完成”,并不天然等于任务已经跑完。它可能只是说明入口层收到了消息,真正的执行结果还要看后面的日志、文件产物、接口调用结果。
这也是我后来越来越重视“中间层”和“桥接层”的原因。它们听起来很抽象,但其实非常关键。因为只要你的消息不是直接在本地聊天窗口里发给 OpenClaw,而是经过飞书、网页、转发服务、长连接客户端之类的东西,那中间就一定存在桥接。
桥接层的作用,是把外部消息变成内部可执行请求,再把内部执行结果回传出去。只要这一层做得不够严谨,就特别容易出问题:消息被重复消费、状态回传不完整、任务其实没执行但前端先回了一个“已完成”、或者同一条消息被当成两次任务处理。
我之前遇到的“发一条飞书消息,它却回复两次,甚至生成两份公众号草稿”,现在再回头看,其实就不像是模型自己突然抽风,更像是链路里缺少幂等控制。
也就是说,系统没有很好地判断“这是不是同一条消息、是不是已经处理过、是不是应该只执行一次”。如果没有这层保护,重复回复、重复建稿就会很常见。
很多“不聪明”,其实不是模型问题
同样地,我后来也慢慢接受了一件事:OpenClaw 里很多所谓的“不聪明”,本质上不是模型智商问题,而是系统工程问题。
比如:
- • 消息有没有真正发到执行层
- • 执行层有没有真的读到完整输入
- • 工具有没有被成功调用
- • 本地文件有没有落地
- • 接口有没有真的写入微信公众号草稿箱
- • 最后返回给飞书的那句结果是不是只是一个模板化回执
这些东西如果不拆开看,你就会觉得“AI 又骗我了”;但一旦拆开看,就会发现很多问题其实可以定位,而且定位的方法跟传统工程排障没什么本质区别。
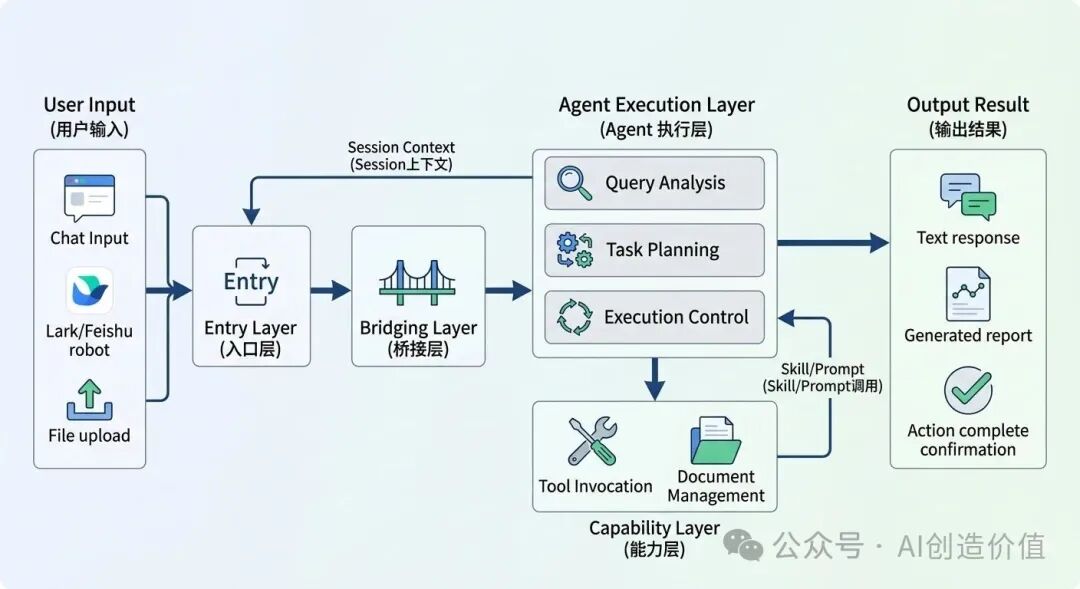
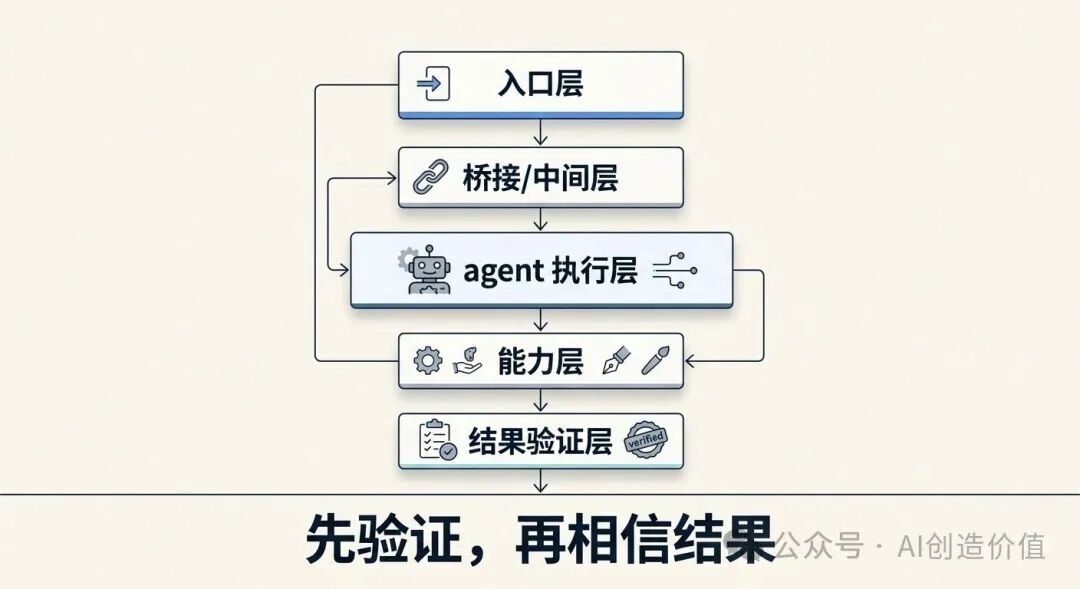
如果让我重新总结一遍,我会把它理解成五层
第一层:入口层
比如飞书机器人、聊天窗口、网页面板。
这一层负责接收你的消息。
第二层:桥接 / 中间层
负责把入口收到的消息转成 OpenClaw 能处理的任务,同时把结果再回传出去。
这一层很容易引入重复消费、假成功回执、状态不同步等问题。
第三层:agent 执行层
它负责理解任务、调度上下文、决定是否调用 skill、是否调用工具、如何组织输出。
第四层:能力层
这里包括 skill、模型、搜索、图像生成、文件读写、API 调用等具体能力。
它们才是真正把任务做出来的部分。
第五层:结果验证层
这一层往往最容易被忽略,但我觉得反而特别重要。因为很多时候真正有价值的,不是它回复你一句“完成了”,而是你有没有看到真实证据:文件有没有生成、图片有没有落地、公众号草稿有没有出现、接口有没有返回可核验结果。
如果没有结果验证层,整个系统就很容易停留在“嘴上完成了”。
这也是我后面越来越在意回执格式的原因。我不再满足于一句“任务执行完成”,而是会要求它明确告诉我:到底生成了哪些文件、路径是什么、最后修改时间是什么、草稿箱接口有没有调用、调用结果是成功还是失败。
因为只有这样,你才能真的知道它是在干活,还是只是在回答。
最后的总结
写到这里,我反而觉得,理解 OpenClaw 的过程,某种程度上就像是在理解一套 AI 外壳下面的系统工程。
它不是装好一个模型就万事大吉,也不是学会几个 prompt 就能横着走。真正决定它好不好用的,是你有没有把入口、桥接、上下文、执行、能力、验证这些层拆开看清楚。
对我来说,前面这段折腾最大的价值,不只是“会用了”,而是终于没那么容易被表象骗了。
以后再遇到问题,我至少会先问自己:
- • 这是飞书入口的问题?
- • 是桥接层重复消费?
- • 是
session上下文没带到? - • 是
skill没有真正被调用? - • 还是本地执行了但结果没回传?
一旦问题被拆成这些层次,很多原来看起来玄学的问题,其实就没那么玄了。
如果你也正在折腾 OpenClaw,我会特别建议你先别急着追求“全自动”“自我进化”“永久记忆”这种听起来很厉害的词,先把这些最基础的概念搞明白。
因为很多时候,真正让一个系统变好用的,不是多装几个华丽的 skill,而是先知道你面对的到底是一套什么结构,它每一层各自负责什么,又该怎么验证它到底有没有真的在工作。
这大概也是我这次最想分享的一点:OpenClaw 不是不能用,也不是纯靠玄学去驯服。它更像是一个需要你慢慢把结构看明白、再一点点驯化的系统。只要你真的把这些概念理顺了,后面不管是排查问题,还是把它接进自己的工作流里,都会顺很多。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)