11-学习笔记尚硅谷数仓搭建-Maxwell实时流单个表全量数据同步到Kafka
目录
备注:一般Maxwell用作实时流增量数据传输,但也可以全量数据传输,比如本文演示的那样。但整个数仓项目是用Maxwell作增量数据传输,用DataX离线作全量数据传输。这里演示全量数据同步的原因是:在同步增量数据的第一天应该先将数据库中的数据先全量同步一次,然后以后每天才是增量同步,这样做就可以保证整个流程的数据同步
备注:没有特别说明都在atguigu用户执行命令
备注:没有特别说明都在atguigu用户执行命令
一、启动服务(如果没有)
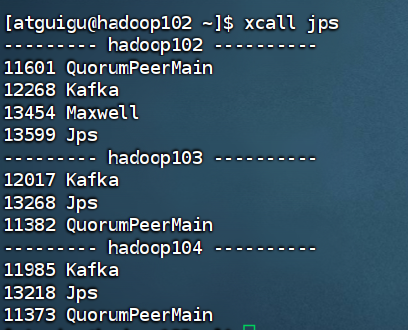
1.查看进程(hadoop102执行下面命令)
xcall jps
如果有下面的进程就不用启动服务,如果没有就输入下面命令启动服务
2.启动服务(hadoop102执行下面命令)
# 启动服务
zk.sh start
kf.sh start
mxw.sh start二、单个表全量数据同步
1.解释概念:历史数据全量同步是指将初始MySQL数据通过Maxwell全部抓取到Kafka(只用项目开始的时候执行一次就行,保证Kafka中有数据库的初始数据),然后以一天为时间间隔,将当天的变更数据也抓取到Kafka,实现Kafka数据与MySQL数据同步,同时保证了Kafka中既有实时数据也有全部数据,且节约了内存。
2.历史数据同步(以activity_info表为例,因为是学习流程所以不用将所有初始数据都同步)(hadoop102执行下面命令)
/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table activity_info --config /opt/module/maxwell/config.properties3.验证数据是否成功同步
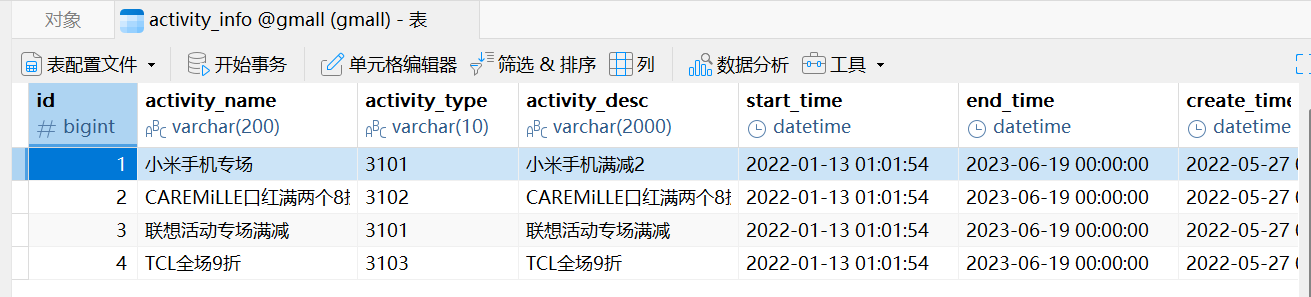
先查看activity_info表的数据如图:
再去Kafka tool工具查看数据是否一致
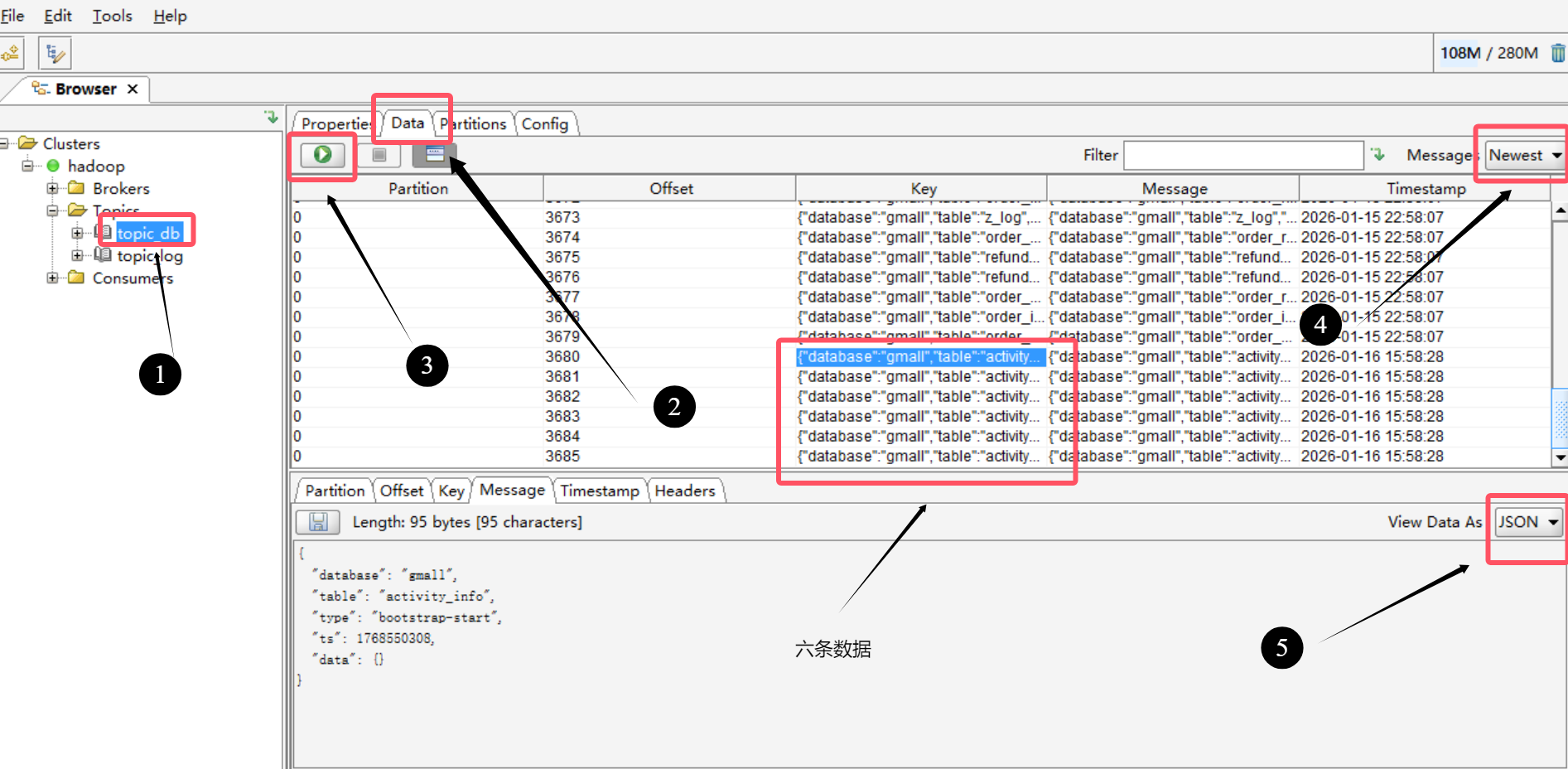
我们运行后滑到最下面,看到有六条activity_info相关的数据
4.为什么我们数据库中是4条数据,而在Kafka上却显示了6条数据?
解释:
我们选择第一条和最后一条,选择message查看数据,发现它们里面根本没有数据
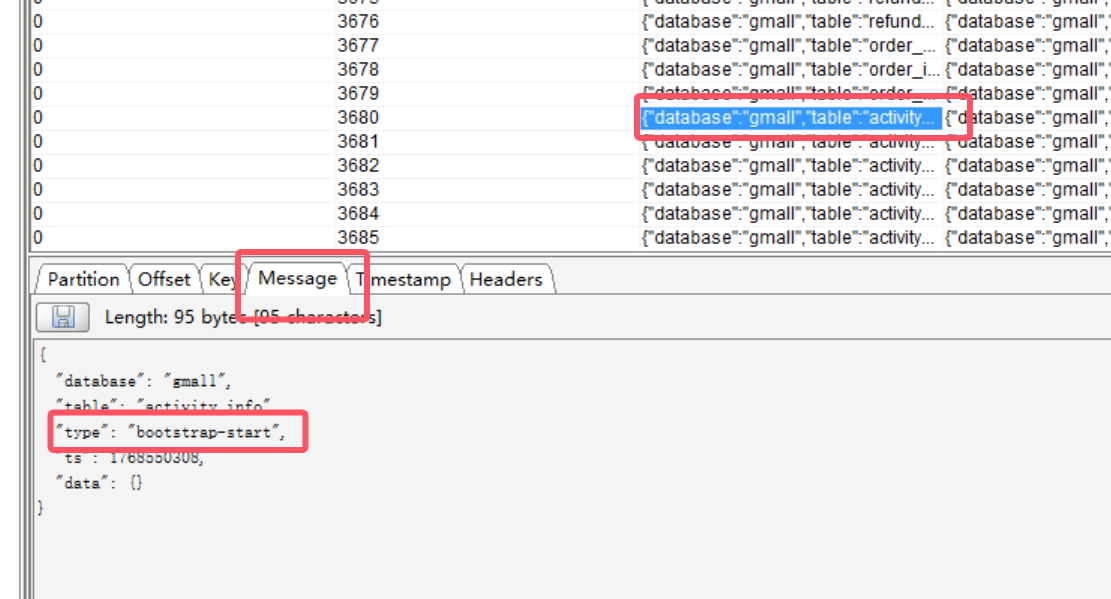
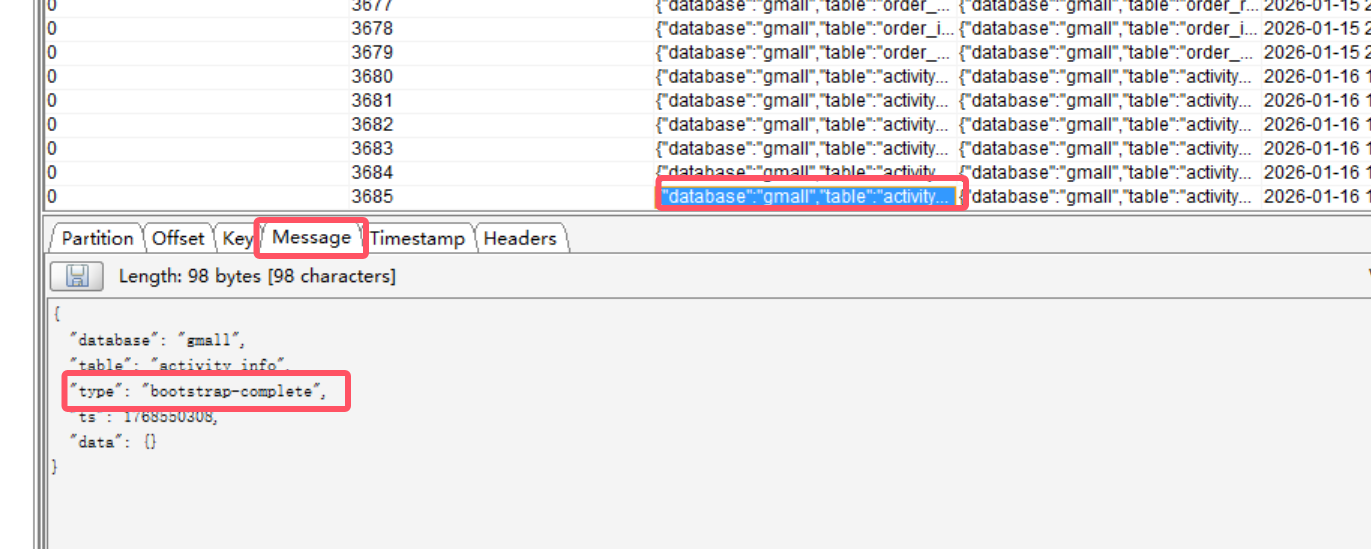
那没有数据为什么要它们呢?因为它们是界定全量数据的一个标志,在在它们之间的数据就是全量数据,是为了与实时数据分隔开。
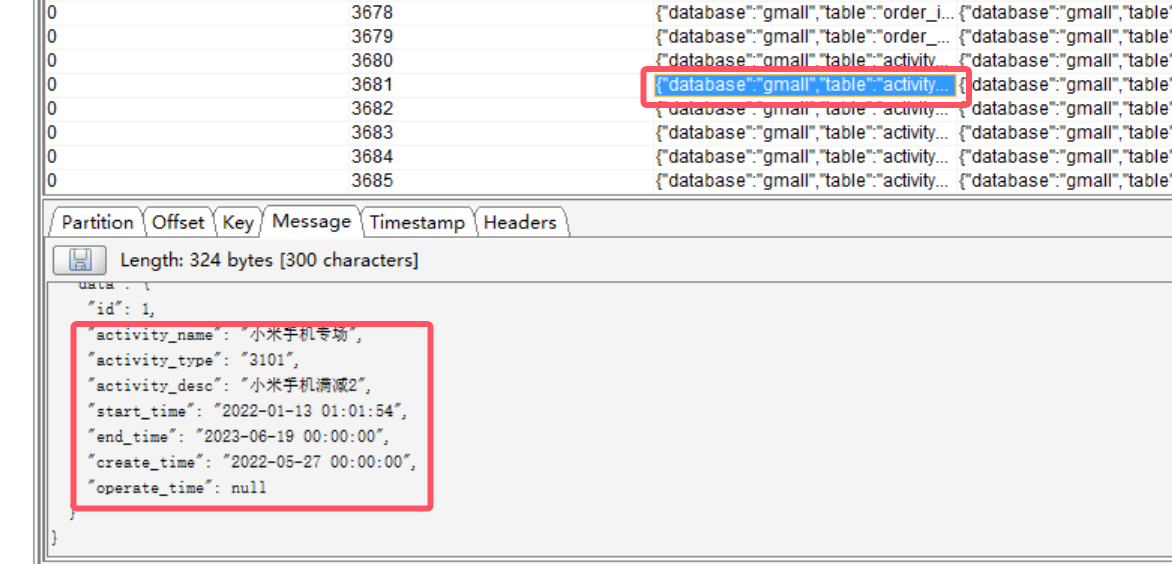
第二个就与我们的数据库数据保持一致了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)