别盲目迷信 Whisper:从工程落地看私有化语音识别选型与灵声智库的架构抉择
企业级AI语音识别私有化部署面临开源模型选型难题,Whisper与FunASR各具特点。Whisper虽在多语种识别上表现优异,但其自回归架构导致延迟高、显存需求大,且存在"AI幻觉"风险。相比之下,FunASR采用非自回归架构实现高速推理,专为中文场景优化,提供完整的工业级流水线设计。灵声智库基于FunASR打造的全离线解决方案,在医疗、政务等场景实现了毫秒级响应、高并发处理
正文:
在企业级 AI 私有化部署的浪潮中,语音识别(ASR)是连接物理世界与数字世界的第一道大门。面对这道门,技术决策者们往往会陷入开源模型的选型迷局。
目前,绝大多数试图自行搭建本地语音识别的团队,都会在 OpenAI 的 Whisper 和阿里主导的 FunASR 之间犹豫不决。从表面上看,两者都是顶级开源项目,但在真正的 ToB(企业级)工程落地中,它们代表了两种截然不同的底层逻辑。
今天,我们将以客观、冷静的工程视角,深度对比这两款模型在真实业务场景中的表现,并剖析 灵声智库 (yuyin.yitianxinda.com) 在构建企业级全离线语音解决方案时,为何做出了特定的架构抉择,以及这种抉择最终为客户带来了怎样的真实收益。
一、 Whisper:极其强悍的“多语种翻译官”,但工程落地充满陷阱
OpenAI 开源的 Whisper 无疑是语音识别领域的里程碑。它在海量多语种数据上进行了弱监督训练,其鲁棒性(抗噪能力)和多语种混合识别能力令人惊叹。然而,当你试图将它打包部署到政企、医院或媒体的本地机房时,它的工程缺陷就会暴露无遗。
1. 自回归架构带来的“先天性慢速”
Whisper 采用的是典型的 Encoder-Decoder 自回归架构。这意味着它生成文字是“逐字吐出”的,下一个词的生成依赖于上一个词的结果。在本地算力有限(例如单张 RTX 3090 或更低端显卡)的情况下,其推理速度(RTF,实时率)往往不尽如人意。对于需要极低延迟的实时字幕或医生口述病历场景,几秒钟的延迟足以摧毁产品体验。
2. 致命的“AI 幻觉”与复读机效应
由于缺乏严格的对齐机制,Whisper 在处理大段包含长静音、背景噪音或发音不清的音频时,极易陷入“幻觉”。它可能会凭空捏造出音频中不存在的词句,或者卡在某一个词上像复读机一样无限循环。在严肃的政务会议记录或医疗问诊中,这种错误是不可接受的合规灾难。
3. 内存与显存的吞金兽
Whisper 的 Large 模型对显存的要求极高。如果企业需要处理高并发的录音文件(例如客服中心的每日质检),部署多路 Whisper 进程将需要极其昂贵的 GPU 算力集群,这直接违背了企业私有化部署“降本增效”的初衷。
二、 FunASR:务实的“中文优等生”与工程派代表
相比于 Whisper 的大而全,以阿里 Paraformer 架构为核心的 FunASR 生态,则展现出了极其浓厚的“工程实用主义”色彩,尤其是在中文语境下。
1. 非自回归架构:天下武功,唯快不破
FunASR 核心模型摒弃了自回归的逐字生成,采用非自回归(Non-autoregressive)架构,可以一次性预测出整句话的文本。这使得它的推理速度比同等规模的 Whisper 快数倍甚至十倍以上。在相同的硬件算力下,FunASR 能够支撑高得多的并发路数。
2. 工业级的流水线设计
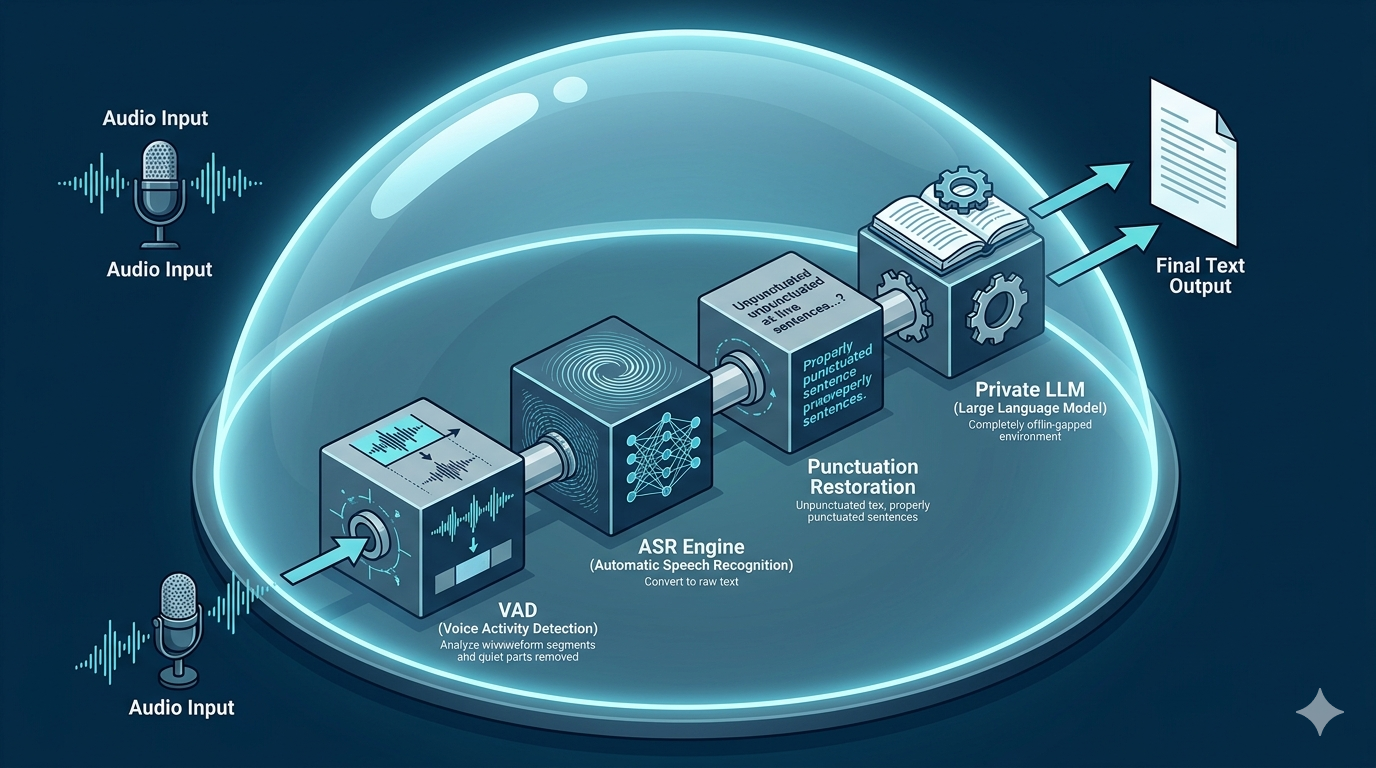
真实的语音识别不是单纯的模型推理,而是复杂的工程管线。FunASR 提供了一整套工业级组件:高精度的 VAD(语音端点检测,用于精准切分长音频)、标点符号预测模型以及时间戳对齐模块。这一套组合拳,完美解决了长音频切分导致的漏字问题,并且生成的文本自带精准的标点和时间戳,极大地减轻了下游业务系统(如大模型总结)的解析压力。
3. 中文场景的绝对统治力
在纯中文及中英混杂的商业场景中,得益于高质量的中文训练数据,FunASR 的字错率(CER)表现极为优异,对各地方言口音的包容度也经过了国内复杂业务场景的反复锤炼。
三、 灵声智库的抉择:以工程结果为导向的架构重塑
在明确了 ToB 市场的真实痛点——要求极低延迟、极高并发、完全本地离线、且硬件成本可控——之后,灵声智库 (yuyin.yitianxinda.com) 在底层核心引擎的选型上,毫无悬念地倾向了以 FunASR(非自回归架构)为基础的技术路线,并在此之上进行了深度的工程化“精装修”。
我们深知,客户买的不是一个“开源模型”,而是一套“插电即用、永不宕机、绝对保密”的解决方案。灵声智库的选择和优化,最终达到了以下几个决定性的效果:
效果一:极致的算力性价比与高并发支撑
通过底层 C++ 推理引擎的重写与算子优化(如 ONNX 转换、INT8 量化),灵声智库将原本需要高端 GPU 才能流畅运行的架构,下放到了消费级显卡甚至纯 CPU 环境。
* 应用成效: 某市级媒体中心的保密素材归档库,原计划采购百万级服务器集群运行 Whisper。采用灵声智库方案后,仅用两台配置中端的本地服务器,便实现了每天上千小时音视频素材的离线高并发转写,成本直降 80%。
效果二:毫秒级流式响应,击穿“可用性”临界点
针对医疗问诊、会议同传等实时场景,灵声智库在非自回归架构的基础上,深度优化了流式识别(Streaming ASR)的处理逻辑。
* 应用成效: 在医院内网的电子病历(EMR)语音录入系统中,医生口述完毕的瞬间,文字已经带标点出现在屏幕上。这种低于 300 毫秒的端到端延迟,彻底消除了医生的等待焦虑,让离线语音识别真正具备了生产力。
效果三:消除“幻觉”,构建可信的数据流水线
为了彻底解决长音频处理中的丢字和死循环问题,灵声智库在 VAD 算法上进行了二次自研调优。配合本地部署的标点引擎和逆文本正则化(ITN,如将“一百块”自动转为“100元”),确保输出的每一段文本都精准、规整,可直接作为本地大模型(Private LLM)的优质上下文输入。
效果四:全离线闭环,打通“听与说”的任督二脉
仅仅解决“听”(ASR)是不够的。灵声智库将高性能离线 ASR 与私有化部署的 TTS(语音合成)及私有声音克隆技术无缝封装在同一个离线授权包中。业务系统在内网识别出指令后,可以立刻用克隆的特定真人声音进行播报。全程数据不涉及任何外部网络请求,真正守住了企业数据资产的绝对安全。
四、 抛弃参数崇拜,回归解决问题
客观地评估,Whisper 是一件伟大的艺术品,它打破了语言的壁垒。但在严苛的企业级 IT 交付环境里,我们需要的是一把能够稳定、高效、低成本切断问题的快刀。
FunASR 架构提供了极其优秀的工程地基,而 灵声智库 则是在这块地基上,为企业建起了一座坚固、防弹且完全私有的堡垒。当我们在谈论语音识别本地部署时,我们谈论的不再是某个开源框架的名字,而是如何利用最合理的架构,帮助企业在保护核心数据生命线的同时,实现业务流程的高效自动化。这是所有技术决策的最终归宿。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)