分布式数据库 - 软考备战(三十六)
数据库系统(八)
参考资料:
数据库分片(Database Sharding)详解 - 知乎
联邦架构和集群架构区别_mob64ca12e2442a的技术博客_51CTO博客
5.8 分布式数据库
1. 定义与核心特征
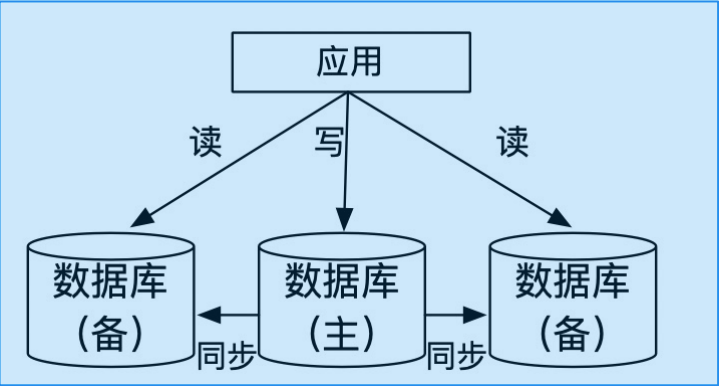
物理上存储在通过计算机网络连接的多个独立节点上,逻辑上作为一个统一整体被用户访问的数据库系统。
DDBS vs 多机集群 vs 联邦数据库
DDBS vs 多机集群
集群通常有一个“主节点”拥有绝对控制权,“从节点”只负责备份或分担读压力,没有站点自治性。
而 DDBS 中没有绝对的老大,每个节点都是平等的,都能独立处理本地事务。
DDBS vs 联邦数据库
联邦数据库是把已经存在的、各自独立的、异构的数据库(比如人事用Oracle,财务用SQL Server)通过中间件“拼”在一起,各库互不相让,没有全局统一的概念模式。
DDBS 是从底座上就被设计成一个整体的。
2. 数据分片
把一张表放到多个节点,必须经过“分片(切)”和“分配(放)”两步。
水平分片(按行切)
按特定条件(如 WHERE 地区='华北')把元组分配到不同片段。
垂直分片(按列切)
把关系模式分解成几个属性子集。
死规定:
垂直分片的每一个片段都必须包含该关系的主码,否则将来拼不回去。
导出分片(跨表切)
半连接操作。
如:根据学生表中的“院系”属性,把选课表切分。
分片的完备性条件
完备性
全局关系的每一个元组,必须至少属于某一个分片(不能丢数据)。
可重构性
所有分片通过特定的关系运算(并、连接),必须能无损地拼回原来的全局关系。
不相交性
除了导出分片(允许通过连接重叠),水平和垂直分片要求片段之间尽量不重叠(避免数据冗余导致更新异常)。
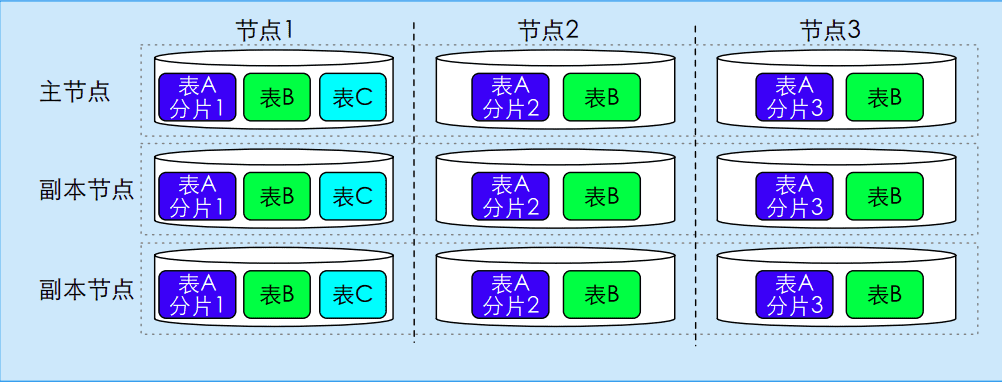
3. 数据分配(物理存放,四选一的工程权衡)
集中式
不分片,全存一个节点。
毫无分布式优势,仅作理论垫底。
分割式(非冗余)
分片后,每个片段只存在一个特定节点。
优点:存储空间利用率100%。
缺点:可靠性极差(节点挂了,那部分数据就没了),查询可能要跨广域网,性能差。
全复制式(完全冗余)
每个节点都保存完整的数据库副本。
优点:极高的可用性和读性能(本地就能读)。
缺点:
- 存储成本极高;
- 写性能极差(更新一条数据,必须同步更新所有节点的副本,网络开销爆炸)。
- 只适合读多写少的特定场景(如图书馆文献库)。
混合式(部分冗余)
核心片段复制两份保命,冷数据片段只存一份。
实际工程中的唯一选择。
4. 分布透明性分层
透明性是 DDBMS 的灵魂,意味着“应用程序不需要因为数据的分布方式改变而修改代码”。
级别由高到低,越往上越牛。
分片透明性(最高级,L4)
程序员面对的是一张完整的“全局表”,SQL 里连分片的名字都不用提。
DDBMS 解析 SQL -> 查分片模式决定切哪里 -> 查分配模式决定去哪取 -> 自动拼接结果。
位置透明性(高级,L3)
程序员知道表被切了(比如知道有员工表_A 和 员工表_B),SQL 里要写 SELECT FROM 员工表_A UNION 员工表_B,但不知道 A 和 B 具体在哪个城市的机房。
DDBMS 自动根据全局目录字典,把对 A 的请求路由到北京,把对 B 的请求路由到上海。
局部映像透明性 / 局部数据模型透明性(最低级,L2/L1)
程序员不仅知道分片和位置,甚至知道北京节点用的是 Oracle,上海节点用的是 MySQL。
如果 Oracle 和 MySQL 的某些数据类型(如时间精度)不一致,程序员必须在代码里自己写转换逻辑。
DDBMS 只负责把 SQL 语句通过网络传过去,仅提供最基础的通信透明。
5. 分布式数据库的体系结构(六层映射图解)
为了实现上面的透明性,DDBMS 内部维护了一张巨大的、层层递进的“地图”:
全局外模式
各终端用户看到的视图(如财务看到的只含金额的视图)。
全局概念模式
描述整个分布式数据库的全局逻辑结构(如:全局员工表的主码、属性)。
映射 1:全局外模式 -> 全局概念模式,保证逻辑独立性
分片模式:描述全局表是怎么被切碎的(如:员工表按水平规则切成 S1, S2)。
映射 2:全局概念模式 -> 分片模式,实现分片透明性
分配模式:描述切好的碎片被放到了哪个物理节点(如:S1 在 Node1,S2 在 Node2)。
映射 3:分片模式 -> 分配模式,实现位置透明性
局部概念模式:描述具体某个节点上的局部表结构(如:Node1 上的本地表结构)。
映射 4:分配模式 -> 局部概念模式,实现局部模型透明性
局部内模式:各节点真实的磁盘物理存储。
6. 要解决的核心技术问题
分布式事务管理(如何保证跨节点 ACID?)
痛点:
本地事务靠锁能保证原子性,跨节点事务(如 A 节点扣钱,B 节点加钱)如果 A 成功 B 断电了,无法用单机锁解决。
解决:
两阶段提交协议(2PC)
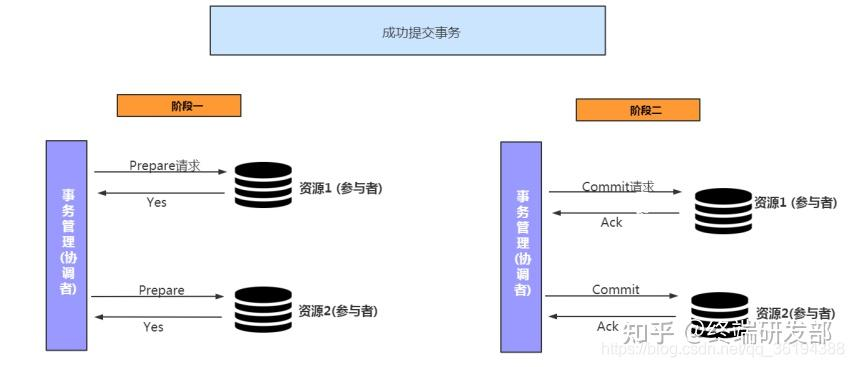
引入一个协调者,其他节点叫参与者。
阶段一:投票阶段。
协调者向所有参与者发“准备提交?”的请求。
参与者把 redo/undo 日志刷盘,锁定资源,然后回答“YES”或“NO”。
阶段二:提交阶段。
协调者收集投票:如果所有人都是 YES,下发“全局提交”指令;
如果有哪怕一个人是 NO,下发“全局回滚”指令。
参与者执行指令并释放锁。
2PC 的致命缺陷(同步阻塞问题)
在阶段一,所有参与者必须把资源锁住等待协调者的决定。
如果协调者挂了,参与者将一直锁着资源无法释放,导致整个系统“卡死”(阻塞)。
注:
现代数据库如 TiDB 引入了 Percolator 算法来规避此问题。
分布并发控制(如何对付跨节点死锁?)
全局死锁的特征
A 节点的事务 T1 锁住了 A 节点的数据 X,等待 B 节点的数据 Y;
B 节点的事务 T2 锁住了 B 节点的数据 Y,等待 A 节点的数据 X。
在各自节点的本地日志里看,它们都只是在“等待网络请求”,并没有死锁,只有站在全局视角才能看出死循环。
集中式死锁检测
指定一个节点专门收集所有节点的“等待图”,拼成全局等待图,有环就死锁。
超时机制
简单粗暴,事务等待网络响应超过设定时间(如 30 秒),直接判定死锁并回滚(容易误杀)。
时间戳排序
每个事务开局分配一个全局唯一的时间戳,发生冲突时,时间戳小(年纪大)的优先,回滚时间戳大(年轻)的事务。
分布式查询优化(如何避免把网络撑爆?)
痛点:
在单机里,多表连接(笛卡尔积)虽然慢,好歹是在内存/本地总线上跑。
在分布式里,如果把两个百万级的大表全部跨网传到一个节点再连接,网络带宽直接被榨干。
核心优化策略:选择下推
只要 SQL 里有 WHERE(选择)或 SELECT 某几列(投影),绝对不要先传数据,而是把这些操作“下推”到数据所在的本地节点先执行。
比如:北京的员工表有 100 万人,上海的项目表有 1000 个。
要查“北京的张三参与了哪些项目”。
正确做法是:
把 SELECT FROM 北京员工 WHERE 姓名='张三' 下推到北京节点执行,北京只查出 1 条记录(张三的工号),把这 1 条记录通过网络传到上海去连接。网络流量从百万级降到 1 条。
高级技术:半连接
专门优化连接操作的。
把连接条件拆开,先只传“连接列”过去做过滤,确认匹配后,再把完整的行传回来。
这也是为了极致压缩网络传输量。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)