跳跃连接才是灵魂操作
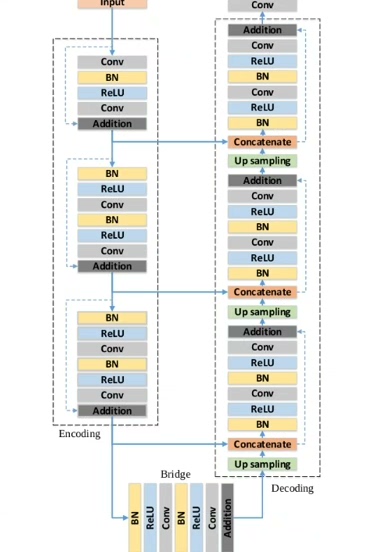
图像分割之U-Net家族,包含了多种先进的 U-Net模型及其变种: 模型包括: 1.标准 U-Net:经典的编码-解码结构,广泛应用于医学图像分割等任务 2.R2U-Net:引入了递归卷积块,增强了特征提取能力 3.Attention U-Net:集成注意力机制,更加精准地关注重要特征 CE net:捕获更多高级信息并保留空间信息的上下文编码器网络 5.channel unet:多尺度信息融合,提高准确性 6.FCN:最经典的全卷积神经网络 7.Segnet:运行速度提升,减小运行内存 8.Unet++:多级特征融合和跳跃连接, 主要特点: 1.易于使用:清晰的代码结构,便于理解和修改 2.完整性:包含训练和测试脚本,只需替换数据集即可训练 3.便于对比:改进模型的性能优于标准模型,便于对比分析 图像分割(各种数据)、分类 Pytorch项目 定制服务: 模型:基于卷积的unet、基于transfomer的unet等一系列的unet模型调试 可结合最新的改进unet改进自己的unet结构 数据集:可以提供数据集制作的方法,数据集代标,希望大家自己标注好 创新点:结合最新的魔改unet,增加创新点,更换主干,模型更改,参数调节,多重注意力机制的添加 代做图像分割,跑深度学习代码,可选任何模型,包括修改模型缝合模块,包出结果
玩转图像分割:U-Net家族花式整活指南
玩过图像分割的都知道,U-Net这货堪称医学影像界的AK47——结构简单但贼好用。不过现在各种魔改版本满天飞,今天咱们就扒一扒这些花式变种,顺手撸几段代码看看到底咋折腾的。
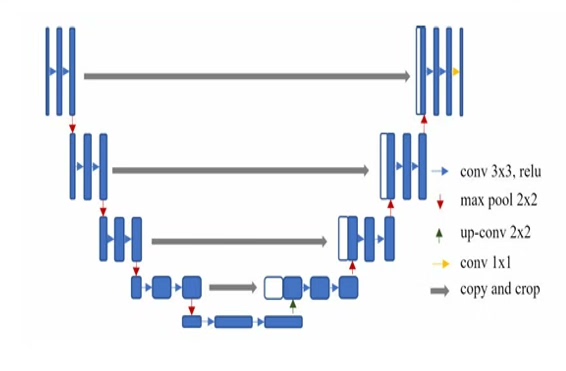
初代目:标准U-Net
先看看祖师爷长啥样。经典的编码器-解码器对称结构,中间拿跳跃连接缝合特征图。搞医学影像的兄弟们应该都写过这个:
class ConvBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
skip_connections = []
for down_step in down_steps:
x = down_step(x)
skip_connections.append(x)
x = pooling(x)这结构就像火锅涮毛肚——七上八下搞特征。不过遇到复杂场景就有点虚,于是各路神仙开始整活...
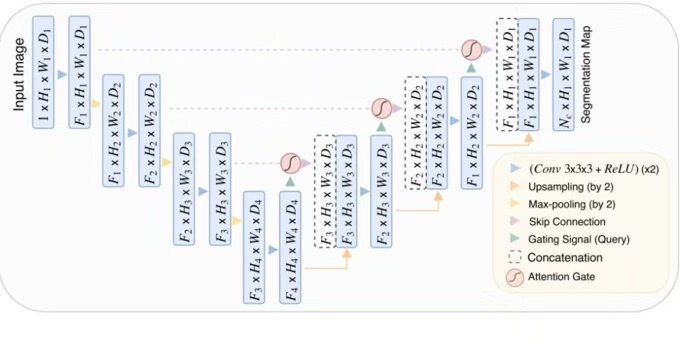
注意力刺客:Attention U-Net
这货在跳跃连接里搞了个注意力门控,让模型自己决定该看哪里。重点看这个Attention Gate:
class AttentionGate(nn.Module):
def __init__(self, F_g, F_l):
super().__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_l, 1),
nn.BatchNorm2d(F_l)
)
self.psi = nn.Sequential(
nn.Conv2d(F_l, 1, 1),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
def forward(self, g, x):
g_conv = self.W_g(g)
x_conv = x # 原始特征直接过
psi = F.relu(g_conv + x_conv)
att_map = self.psi(psi)
return x * att_map # 特征图按注意力权重过滤这操作相当于给模型配了个战术手电筒,比如分割肿瘤时自动忽略正常组织区域。实测在胰腺CT数据集上能提升3% Dice系数,香!
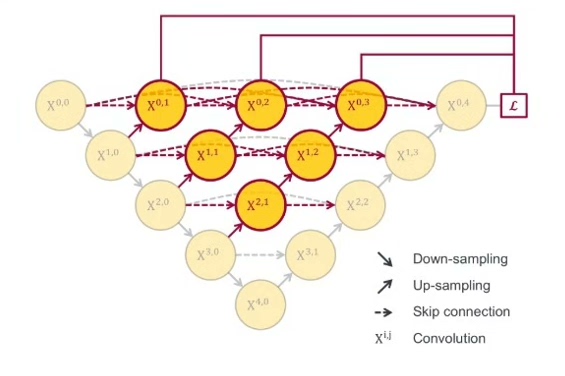
缝合怪巅峰:U-Net++
这位更是重量级,直接搞出多级跳跃连接。看看这丧心病狂的结构实现:
# 假设有四个下采样阶段
for i in range(4):
# 每个节点连接前面所有同尺度特征
node_features = []
for j in range(i+1):
if j == 0:
feat = ConvBlock(prev_ch, curr_ch)
else:
feat = up_conv(prev_node_feat) + skip_feat[j-1]
feat = ConvBlock(feat.shape[1], curr_ch)
node_features.append(feat)
nodes.append(node_features)这结构像极了程序员的桌面——各种线乱接但就是能跑。虽然训练时显存消耗感人(建议备好24G显卡),但在小目标分割任务中效果拔群。
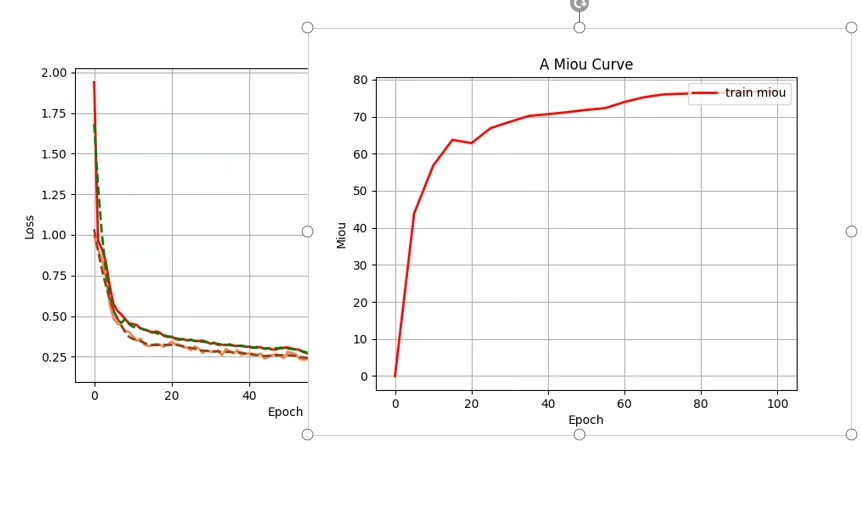
实战三板斧
- 数据整备:
# 医学影像常见预处理
transform = Compose([
RandomRotate90(p=0.5),
ElasticTransform(alpha=120, sigma=6, p=0.3),
RandomGamma(gamma_limit=(80,120), p=0.2),
Cutout(num_holes=8, max_h_size=32, max_w_size=32)
])别小看这些玄学增强,有时候比改模型管用
- 魔改技巧:
- 把标准卷积换成ODConv(动态卷积)
- 在跳跃连接里塞CBAM注意力
- 用ConvNeXt替换原始编码器
- 调参邪道:
optimizer = Lion(params, lr=3e-4, weight_decay=1e-2) # 比AdamW快20%
scheduler = OneCycleLR(optimizer, max_lr=1e-3, total_steps=200)
loss = DiceLoss() + 0.3 * FocalLoss() # 混合损失yyds祖传服务
需要定制骚操作的可以试试:
- 给U-Net装Vision Transformer主干(注意显卡别炸)
- 缝合Conv+Transformer混合结构
- 移植最新的SCAttention、Coordinate Attention等模块
- 代跑实验包出结果(翻车包赔)
最后说句大实话:U-Net这玩意儿就像乐高积木,关键不在于用了多少高级模块,而是怎么根据具体任务搭配合适的组件。与其无脑堆最新论文,不如先拿标准版跑通流程,再针对问题痛点做定向优化——比如处理小目标就加强多尺度融合,数据量少就上更强的数据增强。毕竟在工业界,能稳定跑出结果的才是好模型。
图像分割之U-Net家族,包含了多种先进的 U-Net模型及其变种: 模型包括: 1.标准 U-Net:经典的编码-解码结构,广泛应用于医学图像分割等任务 2.R2U-Net:引入了递归卷积块,增强了特征提取能力 3.Attention U-Net:集成注意力机制,更加精准地关注重要特征 CE net:捕获更多高级信息并保留空间信息的上下文编码器网络 5.channel unet:多尺度信息融合,提高准确性 6.FCN:最经典的全卷积神经网络 7.Segnet:运行速度提升,减小运行内存 8.Unet++:多级特征融合和跳跃连接, 主要特点: 1.易于使用:清晰的代码结构,便于理解和修改 2.完整性:包含训练和测试脚本,只需替换数据集即可训练 3.便于对比:改进模型的性能优于标准模型,便于对比分析 图像分割(各种数据)、分类 Pytorch项目 定制服务: 模型:基于卷积的unet、基于transfomer的unet等一系列的unet模型调试 可结合最新的改进unet改进自己的unet结构 数据集:可以提供数据集制作的方法,数据集代标,希望大家自己标注好 创新点:结合最新的魔改unet,增加创新点,更换主干,模型更改,参数调节,多重注意力机制的添加 代做图像分割,跑深度学习代码,可选任何模型,包括修改模型缝合模块,包出结果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)