别再花钱用API!Ollama手把手教你本地部署开源大模型5分钟在本地跑通开源大模型
📌 Ollama本地大模型部署指南 Ollama是一款开源工具,支持在本地快速部署Llama、Mistral等大模型,无需API Key,适合开发者和普通用户。 🔹 快速安装 macOS/Linux/Windows一键安装,默认端口11434 运行模型仅需 ollama run <模型名>,自动下载所需文件 🔹 常用模型推荐 Llama 3.2(通用对话)、Mistral(编程推
💡 Ollama 是什么? 一款开源的本地大模型运行工具,无需云服务、无需 API Key,直接在电脑上跑 Llama、Mistral、Gemma 等开源大模型。新手友好,跨平台支持!

📦 一、安装配置
一键安装
| 系统 | 安装命令 |
|---|---|
| 🖥️ macOS | brew install ollama |
| 🐧 Linux | curl -fsSL https://ollama.ai/install.sh | sh |
| 🪟 Windows | 前往 ollama.ai 下载安装包 |

可以查看GPU运行情况
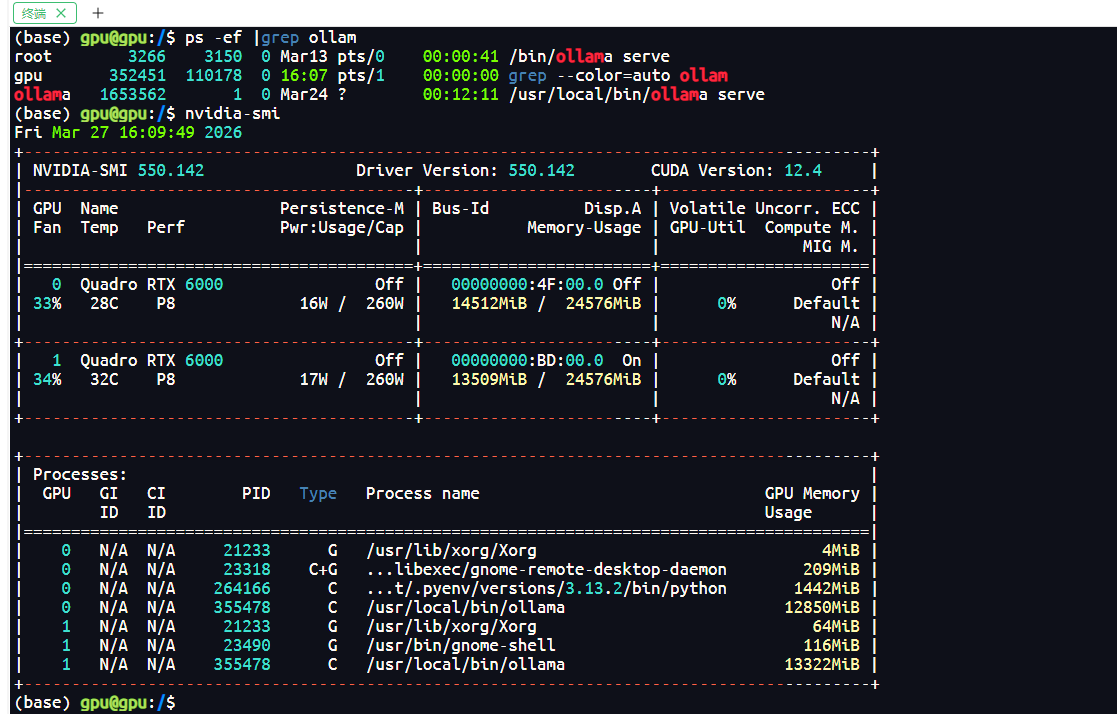
⚠️ 注意:安装完成后,Ollama 服务会自动在后台运行,默认端口
11434。
🚀 二、快速开始
运行你的第一个模型
安装完成后,只需要 一行命令 即可启动大模型:
# 下载并运行 Llama 3.2
ollama run llama3.2
📥 首次运行会自动下载模型(约 1-2GB),耐心等待即可~
也可以搭配 open-webui这个项目
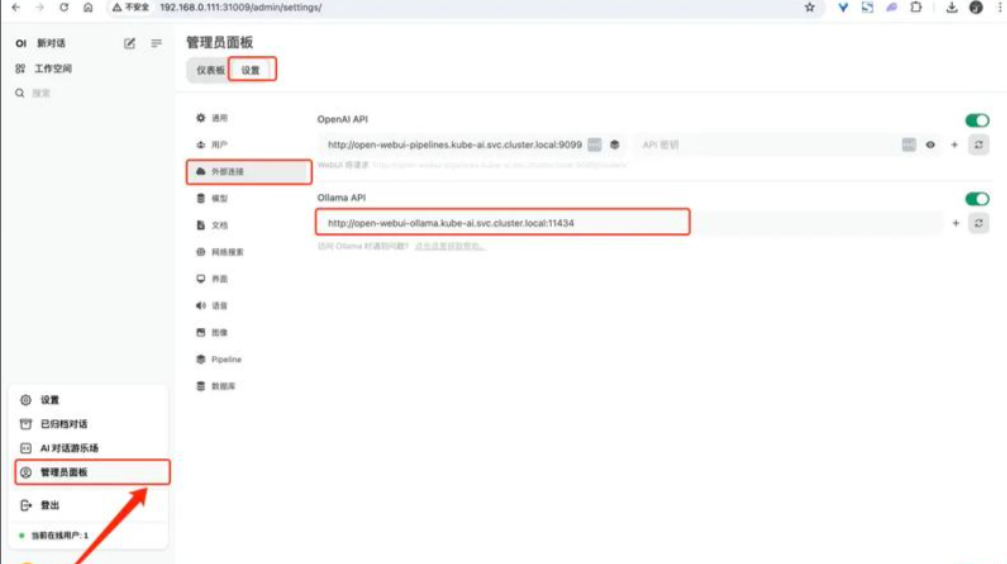
下载完成后即可开始对话:
>>> 你好,请介绍一下你自己
Hello! I'm Llama 3.2, a large language model trained by Meta...
常用模型推荐
| 模型 | 命令 | 适用场景 | 最低内存 |
|---|---|---|---|
| 🦙 Llama 3.2 | ollama run llama3.2 |
日常对话、写作 | 4GB |
| 🌬️ Mistral | ollama run mistral |
编程、推理 | 4GB |
| 💎 Gemma 2 | ollama run gemma2 |
轻量对话 | 4GB |
| 🇨🇳 Qwen 2.5 | ollama run qwen2.5 |
中文对话 | 4GB |
| 💻 CodeLlama | ollama run codellama |
代码生成 | 8GB |
模型管理命令
# 查看已下载的模型
ollama list
# 拉取(下载)新模型
ollama pull mistral
# 删除本地模型
ollama rm llama3.2
# 复制模型(自定义名称)
ollama cp llama3.2 my-llama
🌐 三、API 接口调用
Ollama 提供 REST API,方便开发者集成到自己的应用:
对话接口
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2",
"messages": [
{ "role": "user", "content": "用Python写一个快速排序" }
]
}'
生成接口
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "解释什么是REST API"
}'
📋 四、常用命令速查
| 命令 | 说明 |
|---|---|
ollama run <模型> |
📥 下载并运行模型 |
ollama list |
📋 查看已下载模型 |
ollama ps |
🔍 查看正在运行的模型 |
ollama stop <模型> |
⏹️ 停止运行中的模型 |
ollama pull <模型> |
⬇️ 拉取新模型 |
ollama rm <模型> |
🗑️ 删除模型 |
ollama cp <源> <目标> |
📋 复制并重命名模型 |
ollama show <模型> |
ℹ️ 查看模型详细信息 |
ollama create <名称> -f <Modelfile> |
⚙️ 从 Modelfile 创建模型 |
⚙️ 五、自定义模型配置(Modelfile)
Ollama 支持通过 Modelfile 定制模型行为,创建专属配置:
# 创建 Modelfile
cat > Modelfile << 'EOF'
FROM llama3.2
PARAMETER temperature 0.7
PARAMETER top_p 0.9
SYSTEM """
你是一个专业的中文技术写作助手,
用简洁清晰的语言回答问题。
"""
EOF
# 基于 Modelfile 创建自定义模型
ollama create my-assistant -f Modelfile
# 运行自定义模型
ollama run my-assistant
常用参数说明
| 参数 | 说明 | 常用值 |
|---|---|---|
temperature |
🎯 创造性程度(越低越确定) | 0.1 ~ 1.0 |
top_p |
🎲 采样多样性 | 0.1 ~ 1.0 |
num_ctx |
📏 上下文窗口大小 | 2048 ~ 8192 |
num_gpu |
🎮 使用的 GPU 数量 | 0 ~ 100 |
system |
💬 系统提示词 | 自定义角色设定 |
🎮 六、GPU 加速配置
NVIDIA 显卡
确保已安装 NVIDIA 驱动和 CUDA,Ollama 会 自动 使用 GPU 加速:
这是我的显卡信息
# 查看 GPU 使用情况
ollama show llama3.2
# 运行时会自动调用 GPU
ollama run llama3.2
🍎 macOS Apple Silicon
M 系列芯片会自动使用 Neural Engine 加速,无需额外配置!
手动指定 GPU 使用
# 强制使用 CPU
OLLAMA_HOST=0.0.0.0 CUDA_VISIBLE_DEVICES="" ollama run llama3.2
# 指定 GPU 编号(多卡机器)
CUDA_VISIBLE_DEVICES=0 ollama run llama3.2
🔧 七、常见问题排查
❌ 问题 1:模型下载慢/失败
# 使用代理
export HTTPS_PROXY=http://127.0.0.1:7890
ollama pull llama3.2
❌ 问题 2:内存不足
# 减少上下文大小
ollama run llama3.2 -c 2048
# 换用更小的模型(1B 参数版本)
ollama run llama3.2:1b
❌ 问题 3:端口被占用
# 查看端口占用
lsof -i :11434
# 修改默认端口
OLLAMA_HOST=127.0.0.1:11435 ollama serve
❌ 问题 4:查看运行状态
# 健康检查
curl http://localhost:11434/api/generate \
-d '{"model":"llama3.2","prompt":"/health"}'
# 查看版本
ollama --version
🖥️ 八、Ollama + Web UI
如果觉得命令行不够直观?可以配合 Web UI 使用!
使用 Open WebUI
# 安装 Open WebUI
pip install open-webui
# 启动
open-webui serve
🌐 然后访问
http://localhost:8080,就能用浏览器和本地模型聊天啦!
💻 九、进阶:Ollama 作为编程助手
VS Code 集成
安装 CodeGPT 或 Continue 插件,配置 Ollama 作为后端:
{
"codegpt.llm.provider": "ollama",
"codegpt.llm.options": {
"model": "codellama",
"baseURL": "http://localhost:11434"
}
}
快速代码解释
ollama run codellama "解释这段Python代码的作用:def quick_sort(arr): ..."
✨ 十、总结
Ollama 让本地运行大模型变得 前所未有的简单:
✅ 零配置 — 一行命令即可运行
✅ 跨平台 — Mac/Linux/Windows 全支持
✅ 开源免费 — 无 API 费用,无订阅
✅ 隐私安全 — 数据完全不离开本地
✅ GPU 加速 — 自动识别并利用显卡
🏃 最快体验路径
# 1️⃣ 安装(参考上文)
# 2️⃣ 运行模型
ollama run llama3.2
# 3️⃣ 开始对话!
>>> 你好!
现在,你已经可以在本地 免费、无限制 地使用大模型了!🚀
快去试试吧!
📚 参考资料
详细教程或遇到问题可以关注我咨询


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)