Postgres 性能回退:我们到了吗?
本文探讨了在 Linux 7.0 上报告的 PostgreSQL 性能回退问题,分析了根本原因(自旋锁竞争期间的 TLB 未命中和页错误,而非抢占模式本身),解释了为什么大页(Huge Pages)和透明大页(Transparent Huge Pages)能缓解此问题,并强调了在容器化环境中启用大页的更大挑战。
Postgres 性能回退:我们到了吗?
摘要: 本文探讨了在 Linux 7.0 上报告的 PostgreSQL 性能回退问题,分析了根本原因(自旋锁竞争期间的 TLB 未命中和页错误,而非抢占模式本身),解释了为什么大页(Huge Pages)和透明大页(Transparent Huge Pages)能缓解此问题,并强调了在容器化环境中启用大页的更大挑战。
每年,PostgreSQL 都会变得更快。研究人员对 8 到 16 版本的优化器进行基准测试,发现每个主要版本平均有 15% 的性能提升。这是一致且可衡量的十年进步。该项目自 1996 年以来一直在做这件事。
因此,当有报道称 Linux 7.0 将 PostgreSQL 吞吐量减半时,DBA、系统管理员和 DevOps 开始恐慌(特别是那些使用 Ubuntu 26.04 LTS 的人,他们计划尽快采用 Linux 7.0 内核)。在按下恐慌按钮之前,值得深吸一口气。
现实情况更加复杂。让我带你了解实际发生了什么、对你的部署意味着什么,以及你真正应该担心的。
首先,需要一点内核理论
耐心点。我保证这是必要的。
你的操作系统内核负责决定哪个程序可以运行在 CPU 上,以及何时运行。这称为调度。当一个程序在执行过程中被中断以让另一个程序运行时,这称为抢占。
如果你在服务器上运行 PostgreSQL 已经有一段时间了,你会知道标准建议:PostgreSQL 应该拥有这台机器。它应该是该主机上唯一重要的事情。我们通常禁用 OOM killer,这样内核就不会在内存压力下决定牺牲 PostgreSQL 后端。我们调整 vm.swappiness 以将 PostgreSQL 的数据保留在 RAM 中。整个理念是:阻止操作系统对数据库进行二次猜测。
抢占模式符合同样的理念。想象一下外科医生正在进行精细手术。你不希望有人在手术中途拍拍他们的肩膀说"能快速看一下其他东西吗?"当 PostgreSQL 深入关键 section 时,我们真的不希望内核中断它。
不同的抢占模式代表不同的权衡。
PREEMPT_NONE(旧的服务器默认):内核几乎从不中断正在运行的程序。程序运行直到自愿放弃 CPU,或者直到它进行系统调用。更少的上下文切换,更多时间做实际工作。

PREEMPT_FULL:内核几乎可以在任何时刻中断任何正在运行的程序。对响应性和实时应用程序很好。对服务器工作负载的吞吐量不利。

PREEMPT_LAZY(Linux 7.0 新增):一个中间立场。内核会抢占线程,但采用懒惰方式,等待自然机会而不是立即强制中断。旨在减少 PREEMPT_FULL 的开销,同时保持内核的调度模型清洁。

在过去的 20 多年里,服务器内核发货时默认使用 PREEMPT_NONE。PostgreSQL 就是基于这个现实构建的。
Linux 7.0 改变了这一点。Peter Zijlstra 的提交 7dadeaa6e851 在现代架构上移除了 PREEMPT_NONE:arm64、x86、powerpc、riscv、s390、loongarch。所有这些。内核现在只提供 PREEMPT_FULL 和 PREEMPT_LAZY。
为什么这会影响 PostgreSQL 性能?
PostgreSQL 在几个地方使用自旋锁,特别是在缓冲区管理器中。
自旋锁是一种锁机制,当等待锁可用时,线程不是去睡眠,而是在紧密循环中持续检查。想想《怪物史瑞克》中的驴子,被绑在后座上:"我们到了吗?我们到了吗?我们到了吗?"这听起来很浪费,但对于非常短命的锁,也就是 PostgreSQL 缓冲区管理器使用的那种锁,实际上比让线程睡眠和唤醒的开销更快。
自旋锁背后的关键假设是:持有锁的线程很快就会释放它。没有人会在 20ns 关键 section 中途抢占该线程。
在 PREEMPT_NONE 下,这个假设是成立的。锁持有者运行直到完成。其他旋转和等待的线程不会等很久。
在 PREEMPT_LAZY 下,内核可以决定抢占持有自旋锁的线程。那个线程被搁置。每个等待该锁的其他线程继续旋转,消耗 CPU 周期,直到调度器决定恢复原始线程。以下是跨几个线程的样子:

理论上,这是一个真正的问题。实际上,实际发生的情况更有趣。
基准测试实际显示了什么
Salvatore Dipietro 在 AWS 的 pgbench 上运行了一个 96 vCPU Graviton4 实例,1024 个客户端,96 个线程,100GB+ 共享缓冲区。与 Linux 6.x 相比,他得到了 0.51x 的吞吐量,并将其报告给内核邮件列表。
基准测试脚本明确设置了 huge_pages=off。
这一个细节非常重要。Andres Freund 深入研究了邮件列表线程,找到了真正的罪魁祸首:不是自旋锁机制本身,而是 TLB 未命中1 和在持有自旋锁时发生的次要页错误。
这就是实际发生的事情。没有大页2,PostgreSQL 的共享内存使用标准 4KB 页面映射。在 100GB+ 缓冲区池上,对每个页面的首次访问会导致次要错误。当该次要错误发生在持有自旋锁时,线程停滞。每个等待该锁的其他线程继续旋转。PREEMPT_LAZY 然后通过偶尔调度出停滞的锁持有者使事情变得更糟,但根本问题已经是页错误,而不是抢占模式。
Andres 确认了这一点:当他启用大页时,他无法重现该回退。当他禁用了大页时,竞争出现了。Salvatore 也确认了这一点。他重新运行了基准测试,这次在系统上启用了透明大页3,他发现 THP 修复了之前的行为:吞吐量在 Linux 6.x 和 Linux 7.0 上都恢复到约 185k tps。大页和 THP 通过不同的机制工作,但都消除了导致竞争的 4KB 页错误问题。
还有第二个细节值得注意。基准测试中处于竞争状态的自旋锁 StrategyGetBuffer() 只在缓冲区池预热期间触发,即 PostgreSQL 首次将页面加载到共享内存中。一旦缓冲区池达到稳定状态并清空空闲列表,该路径就不再被命中。基准测试正在测量一个短暂的预热阶段并将其作为稳定状态呈现。在新的抢占模式下,PostgreSQL 中至少有另一个自旋锁可能存在竞争,但并发获取的上限要低得多。
Andres 直言不讳地说:一个 100GB 冷缓冲区池,没有大页,运行的活动连接数比 CPU 核心多 10 倍,仅在预热期间,不是一个现实的生产场景。
那么你应该害怕吗?
对于在裸机或专用 VM 上配置良好的部署:可能不会。
如果你的主机上已经启用大页或 THP,并且你的工作负载不是具有大规模缓冲区的极端冷启动场景,Linux 7.0 的变化不太可能在稳定状态影响你。在做出任何决定之前,用你的实际工作负载和实际配置进行基准测试。
在两种情况下情况更加复杂。
首先:如果你在没有大页或 THP 的高并行机器上运行大型共享缓冲区。在这种情况下,PREEMPT_LAZY 确实会在预热期间加剧自旋锁竞争。在这种配置下,竞争在 PREEMPT_NONE 下也存在,PREEMPT_LAZY 只是使其更糟。解决方法是启用大页或 THP,而不是固定你的内核。
其次:如果你在容器中运行 PostgreSQL。这是一个值得花时间关注的问题,因为它的关注度不够。
真正的问题:大页、THP 和容器
大页和 THP 都能缓解回退。在裸 metal 上,启用任一一个都很简单。在容器化环境中,从痛苦到不可能,这是一个在 Linux 7.0 之前就存在的总体 PostgreSQL 性能问题。
THP 由 /sys/kernel/mm/transparent_hugepage/enabled 控制,这是一个主机级 sysfs 路径。Sysfs 在 Linux 中不是命名空间的,意味着容器无法修改它。无论主机配置什么,每个容器都会继承该配置,无法从内部覆盖。
显式大页有相同的约束。内核在容器启动前通过 vm.nr_hugepages 保留一个池。如果主机配置了池,容器可以从中消耗,但无法创建或调整它的大小。
Incus,一个完全开源的系统容器管理器,确实允许 limits.hugepages 来限制给定容器可以通过 hugetlb cgroup 消耗的大页数量,但主机池必须首先存在4。一位在 Incus 中运行 PostgreSQL 的读者报告了这个问题:你必须在主机级别预先调整池的大小。太小的,PostgreSQL 无法使用。太大的,你有浪费的物理 RAM,其他容器无法触及。池是静态的:更改它意味着停止容器、调整主机配置并重新启动。
在 Docker 中,你需要在容器启动前在主机上设置 vm.nr_hugepages,这需要对主机的 root 访问。在 Docker Desktop 上情况更糟,因为你根本无法控制底层 Linux VM。
在 Kubernetes 中,节点必须在 kubelet 可以将大页宣传为可调度资源之前预分配大页。你在 Pod 规格中声明 hugepages-2Mi 或 hugepages-1Gi,但节点必须首先准备好池。在托管节点池上,EKS、GKE、AKS,你通常无法控制节点级内核配置。从 Pod 内部更改 THP 设置需要将主机 /sys 挂载为卷或部署特权 DaemonSet,这两种方式大多数集群管理员都不会批准。
这不仅仅是 Linux 7.0 的故事。使用大缓冲区池和 4KB 页面运行 PostgreSQL 一直是性能问题。Linux 7.0 事件只是以一种戏剧性的方式使其可见。如果你的 PostgreSQL 在容器中运行,而你无法在主机级别控制 THP 或大页,你已经在牺牲性能。行业已经大力转向容器化部署,而没有完全解决这个问题。
Linux 社区解决方案:rseq
几十年来,PREEMPT_NONE 充当了 PostgreSQL 的"请勿打扰"标志,确保线程可以完成其工作而不被中断。Linux 7.0 移除了这个标志。虽然新的"Lazy"模式试图礼貌,但它引入了一定程度的不可预测性,如果线程在错误的时刻暂停,可能将 20 纳秒的锁变成毫秒级的瓶颈。
可重启序列(rseq)是一种 Linux 内核机制,允许用户空间代码向内核信号它正处于关键 section 中,因此内核延迟抢占直到锁释放之后:
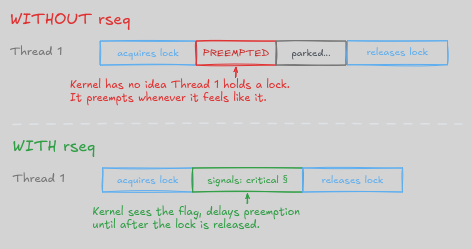
问题不是方向。问题是移除 PREEMPT_NONE 和引入 rseq 发生在同一版本中,中间没有过渡期。正常退休某东西的方式是与旧方式一起提供新方式,废弃它,给人们时间迁移,然后移除它。那一步被跳过了。
内核团队提出的官方解决方案是采用可重启序列(rseq)来缓解这些回退。然而,有一个问题:必要的切片扩展在 Linux 7.0 中默认未启用。它需要一个用 CONFIG_RSEQ_SLICE_EXTENSION 和 EXPERT=1 标志编译的内核。对于使用标准发行版的绝大多数 DBA 和 DevOps 工程师来说,这使得"正确的"修复实际上无法访问。正如所说,这就像被告知紧紧抓住你的刷子,而有人夺走了梯子5。
你实际上应该怎么做?
首先:用你自己的工作负载和配置进行基准测试。在一个 96 vCPU ARM 机器上使用故意禁用大页的综合 pgbench 结果不是你的生产系统的代理。
如果你控制你的主机,并且已经启用大页或 THP,升级到 Linux 7.0 并测量。你可能根本看不到回退。
如果你的主机上既没有启用大页也没有启用 THP,在考虑内核升级之前先启用一个。对于显式大页,在主机上设置 vm.nr_hugepages,在 postgresql.conf 中设置 huge_pages = try。对于 THP,在主机上设置 transparent_hugepage=always。两种方法都解决了潜在的页错误问题。无论 Linux 7.0 如何,这都是很好的建议。
如果你在容器中运行 PostgreSQL 并且无法在主机级别控制 THP 或大页,请注意这是一个大型缓冲区池的总体性能问题。值得与你的基础设施管理者提出这个问题,并值得将其纳入你的部署架构选择中。
如果你在 Ubuntu 26.04 LTS 上,它随 Linux 7.0 一起发货,不要恐慌。用你的实际工作负载进行测试。如果你看到回退,首先检查你的大页配置。
来源:
- Salvatore Dipietro 在 Linux 内核邮件列表上的讨论
- Hacker News 讨论
-
TLB(转换后备缓冲区)是一个 CPU 缓存,存储最近的虚拟到物理内存地址转换。当 CPU 需要访问内存时,它首先检查 TLB。如果翻译不在那里(“TLB 未命中”),它必须遍历页表来查找物理地址,这要慢得多。使用 4KB 页面和非常大的缓冲区池,TLB 很快填满,未命中变得频繁。更大的页面减少了 TLB 中所需的条目数量,因此大大减少了未命中率。 ↩︎
-
大页(也称为 HugeTLB 页面)是一种 Linux 机制,用于预分配大内存页面,通常为 2MB 或 1GB,而不是默认的 4KB。它们必须在使用前明确保留:内核在启动时或通过
vm.nr_hugepages预留一个池,应用程序明确请求它们。PostgreSQL 通过postgresql.conf中的huge_pages = try|on|off支持此功能(默认是try)。因为池是预分配并锁定在 RAM 中的,大页无法被换出,并且在初始分配后不会受到页错误的影响。 ↩︎ -
透明大页(THP)是一种不同的机制。内核不需要明确的预分配,而是自动在后台将 4KB 页面组提升为更大的页面,对应用程序透明。不需要对
postgresql.conf进行任何更改。权衡是不可预测性:内核在后台对页面的提升和降级偶尔会导致延迟峰值。THP 通过/sys/kernel/mm/transparent_hugepage/enabled在系统范围内控制,这是一个 sysfs 路径,对主机全局,不属于任何 Linux 命名空间。 ↩︎ -
Incus 暴露
limits.hugepages.[size]来通过 hugetlb cgroup 限制容器的大页使用,但这需要主机上的 hugetlb cgroup 可用,并且主机大页池必须首先预分配。请参阅 Incus 实例选项文档。 ↩︎ -
这来自一个法国笑话:一个疯子正在重新粉刷他的天花板,就在他到达梯子顶部的那一刻,他的同伙说:"紧紧抓住你的刷子,我把梯子拿走。 ↩︎

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)