mAP指标:目标检测(YOLO系列)性能评估的黄金标准
mAP(mean Average Precision,平均精度均值)是目标检测领域,核心作用是同时量化模型的「分类准确性」和「定位准确性」,也是YOLO系列算法迭代的核心衡量标准(从YOLOv1的63.4% mAP@0.5,到YOLOv8的70+% mAP@0.5:0.95,每一次提升都是核心性能的突破)。
mAP(mean Average Precision,平均精度均值)是目标检测领域唯一通用的综合性能指标,核心作用是同时量化模型的「分类准确性」和「定位准确性」,也是YOLO系列算法迭代的核心衡量标准(从YOLOv1的63.4% mAP@0.5,到YOLOv8的70+% mAP@0.5:0.95,每一次提升都是核心性能的突破)。
一、3个前置概念
mAP是“多层概念叠加”的结果,先吃透这3个基础概念,后续理解会丝滑很多,尤其结合YOLO的预测逻辑,避免踩坑。
1. IoU:定位精度的“守门员”
目标检测不仅要“认对类别”,还要“框对位置”,IoU(交并比)就是衡量预测框与真实框(GT)定位偏差的核心指标,也是mAP计算的前提。
计算公式很简单:预测框与真实框的交集面积÷预测框与真实框的并集面积
取值范围0~1,IoU越接近1,说明预测框和真实框重叠度越高,定位越准确;IoU=0,说明完全不重叠,定位失败。
关键补充(YOLO实战重点):我们常说的mAP0.5、mAP0.75,这里的0.5、0.75就是IoU阈值——阈值越高,对定位精度要求越严格。比如YOLO在安防场景中,需要mAP0.75以上,确保框准目标;而普通场景mAP0.5即可满足需求。
2. TP/FP/FN:目标检测专属的“正负样本判定”
很多同学从分类任务直接过渡到目标检测,容易混淆正负样本的判定——分类任务只看类别,而目标检测必须同时满足「类别正确」+「定位合格」,这是mAP计算的核心逻辑,也是最容易踩坑的地方。
结合YOLO的预测场景,设定IoU阈值(默认0.5),严格定义如下(记死,避免后续理解偏差):
-
TP(真正例):① 预测框类别与真实框一致;② 预测框与对应真实框的IoU≥设定阈值;③ 一个真实框只能匹配「置信度最高」的一个合格预测框(禁止重复匹配,后面重点讲)。
-
FP(假正例):不满足TP的所有预测框,比如:类别预测错误、IoU未达阈值、重复匹配同一真实框、把背景误判为目标(YOLO中常见的“背景误检”)。
-
FN(假负例):所有未被匹配到的真实框,也就是模型漏检的目标(比如YOLO小目标检测差,很多小尺寸真实框会被判定为FN)。
-
TN(真负例):目标检测中无意义,因为背景像素远多于目标,无法统计,全程不参与mAP计算(别再问“为什么mAP计算不用TN”了)。
举个YOLO实战例子:一张图中有1个“行人”真实框,模型输出2个预测框——框1(类别行人,IoU=0.6,置信度0.8)、框2(类别行人,IoU=0.7,置信度0.9)。按规则,只有框2(置信度更高)判定为TP,框1判定为FP;若模型未输出任何预测框,则判定为FN。
3. 精确率(Precision)与召回率(Recall):永恒的权衡
精确率和召回率是PR曲线的基础,也是mAP的核心组成,二者存在天然的“此消彼长”关系,直接决定模型的实战效果。
两个核心公式(记熟,实战调参能用到):
-
精确率(Precision):模型预测的所有正样本中,真正是正样本的比例,衡量模型「不误检」的能力(比如YOLO在工业质检场景,精确率要高,避免把合格产品误判为缺陷)。$$Precision = \frac{TP}{TP+FP}$$
-
召回率(Recall):数据集中所有真实正样本中,被模型成功检测出来的比例,衡量模型「不漏检」的能力(比如YOLO在安防场景,召回率要高,避免漏检行人、车辆)。$$Recall = \frac{TP}{TP+FN}$$
YOLO 定义:置信度 = 框内有目标的概率 × 预测框与真实框的 IoU
二、核心拆解:从PR曲线到AP,再到mAP
mAP的逻辑链条很清晰:PR曲线 → AP(单类别) → mAP(全类别),一步步拆解,结合YOLO场景,让你彻底看懂每一步的意义。
1. PR曲线:单类别性能的“直观体现”
PR曲线是以「召回率(Recall)」为横轴、「精确率(Precision)」为纵轴绘制的曲线,核心作用是完整反映模型在「所有置信度阈值」下的性能表现(避免单一阈值的片面性)。
结合YOLO,PR曲线的绘制步骤(实战可直接用代码实现,后面补充):
-
针对单个类别(比如YOLO检测的“人”类),收集该类别所有预测框,按「置信度从高到低」排序;
-
从上到下依次将每个预测框纳入统计,逐次计算当前的Precision和Recall,得到一组(Precision, Recall)坐标点;
-
将所有坐标点连接,即为该类别的PR曲线。
核心特点:理想的PR曲线紧贴右上角(Precision=1,Recall=1),曲线越靠右上角,模型在该类别上的性能越好;正常的PR曲线整体呈下降趋势(Recall升高时,Precision大概率降低)。比如YOLOv8在“人”类上的PR曲线,会比YOLOv1更靠近右上角,说明其单类别检测能力更强。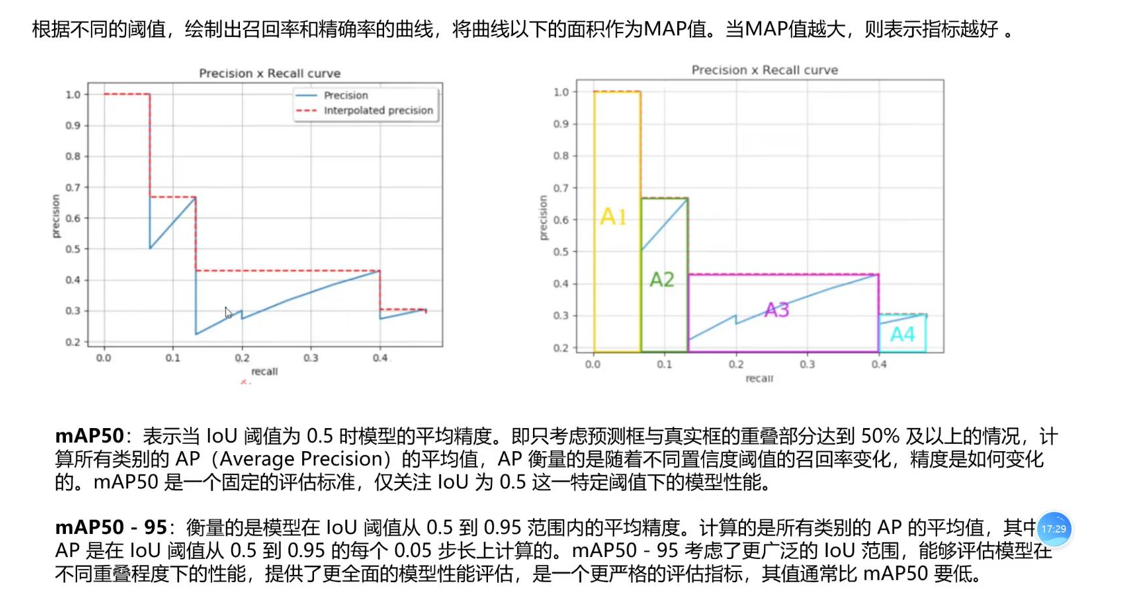
2. AP(Average Precision):单类别性能的“量化评分”
PR曲线能直观看到性能,但无法量化对比(比如两条曲线交叉,无法判断哪个更好),AP就是解决这个问题的——AP是「单类别PR曲线下的面积(AUC)」,取值范围0~1,越接近1,代表该类别检测性能越好。
重点:AP是“单类别”的评分,比如YOLO检测20个类别,就有20个AP值,分别对应每个类别的性能。
两种主流计算标准(YOLO系列必记,避免对比模型时出错):
-
VOC2007 11点插值法(YOLOv1/v2原生使用):取Recall为[0, 0.1, 0.2, ..., 1.0]共11个固定节点,对每个节点,取「所有Recall≥当前值时的最大Precision」(消除曲线抖动,保证单调性),再计算这11个Precision的平均值,即为该类别的AP。
-
VOC2010+ 全点插值法(当前通用,YOLOv3及以后使用):不再固定11个点,而是遍历PR曲线上所有的Recall节点,对每个节点取Recall≥当前值时的最大Precision,得到平滑后的PR曲线,再直接计算平滑后曲线下的积分面积,结果更精准。
3. mAP:模型整体性能的“最终评分”
mAP的计算极其简单,就是「所有类别的AP值取算术平均值」,公式如下:$$mAP = \frac{1}{N} \sum_{i=1}^{N} AP_i$$,其中N为检测任务的总类别数(比如VOC2007有20个类别,COCO有80个类别)。
举个例子:YOLO模型在“人”类AP=0.9、“车”类AP=0.8、“狗”类AP=0.7,3个类别平均后,mAP=(0.9+0.8+0.7)/3=0.8。
关键补充:mAP是“平均”值,能反映模型的整体性能,但也可能掩盖短板——比如某个小类别AP很低(比如YOLO小目标类别),但大类别AP很高,整体mAP依然会偏高,这也是实战中需要重点关注“单类别AP”的原因。
三、YOLO实战重点:mAP的3种核心变体(必懂)
不同场景、不同数据集,mAP的计算标准不同,尤其YOLO系列的论文、实战中,经常出现mAP@0.5、mAP@0.5:0.95等表述,很多同学混淆不清,这里重点拆解,结合参考资料中的行业标准,一次性讲透。
1. mAP@0.5(最常用,YOLOv1-v5主流汇报指标)
定义:IoU阈值固定为0.5时计算的mAP,即PASCAL VOC挑战赛的官方标准,也是工业界最常用的指标。
特点:对定位精度要求相对宽松,核心衡量模型的分类能力和召回能力,适合大多数普通场景(比如监控、人脸检测)。YOLOv1在VOC2007上的mAP@0.5为63.4%,YOLOv2提升至78.6%,YOLOv8可达70%+,每一次提升都代表核心性能的突破。
2. mAP@0.5:0.95(最严格,COCO官方标准)
定义:COCO挑战赛官方标准,也是当前目标检测的通用主流指标,尤其YOLOv3及以后的版本,都会重点报告该指标。
计算规则:从IoU=0.5开始,到IoU=0.95结束,每隔0.05取一个阈值(共10个阈值:0.5、0.55、0.6、...、0.95),分别计算每个阈值下的mAP,再对10个mAP取平均值。
特点:对目标的定位精度要求极高,能更严苛地衡量模型的综合检测能力,适合对定位精度要求高的场景(比如医学影像、工业质检)。比如某YOLO模型mAP@0.5达68.3%,但mAP@0.5:0.95仅45.1%,说明其定位能力较弱,仅能满足宽松场景需求。
3. 分尺度mAP(mAP^S/mAP^M/mAP^L,YOLO小目标优化重点)
这是COCO数据集推荐的延伸指标,也是YOLO实战中优化小目标检测的关键参考,很多同学容易忽略。
按目标尺寸划分(COCO标准):小目标(S:面积<32²)、中目标(M:32²~96²)、大目标(L:面积>96²),分别计算每个尺度下的mAP,即mAP^S、mAP^M、mAP^L。
实战意义:YOLO模型的短板往往体现在小目标检测上,比如mAP整体很高,但mAP^S很低,说明模型漏检小目标,需要针对性优化(比如增加浅层特征融合、调整Anchor尺寸)。如下表所示,能清晰看到不同YOLO模型在不同尺度下的性能差异:
|
模型 |
mAP@0.5 |
mAP@0.5:0.95 |
mAP^S |
mAP^M |
mAP^L |
|---|---|---|---|---|---|
|
YOLOv5s |
67.2 |
42.1 |
28.3 |
45.6 |
58.9 |
|
YOLOv8m |
69.8 |
46.7 |
34.2 |
50.1 |
61.3 |
|
YOLO-NAS |
70.1 |
48.3 |
36.8 |
51.9 |
62.7 |
四、高频误区纠正(YOLO学习者必看,避坑指南)
结合我多年的答疑经验,整理了5个最常见的mAP理解误区,尤其是结合YOLO场景的错误认知,看完再也不会踩坑。
误区1:mAP只评估分类能力,不评估定位能力
纠正:大错特错!mAP的核心前提是IoU阈值——哪怕类别预测完全正确,只要预测框和真实框的IoU未达阈值,就会被判定为FP,直接拉低Precision和AP,最终影响mAP。mAP是同时评估分类和定位的综合指标,这也是它比单纯“分类准确率”更适合目标检测的原因。
误区2:AP和mAP是同一个概念,可以混用
纠正:绝对不能混用!AP是「单类别」的性能评分(比如YOLO检测“人”类的AP),mAP是「所有类别AP的平均值」,代表模型的整体性能。比如某YOLO模型“人”类AP=0.9,但“交通灯”类AP=0.3,整体mAP可能只有0.6,二者不能混为一谈。
误区3:计算mAP需要固定置信度阈值
纠正:不需要!mAP的计算遍历了所有可能的置信度阈值,不受单一阈值的影响——这也是它能成为通用评价标准的核心原因,避免了人为调阈值带来的结果偏差。比如YOLO的置信度阈值调为0.3或0.5,不影响mAP的计算结果。
误区4:同一个真实框(GT)可以被多个预测框匹配为TP
纠正:绝对不可以!这是行业通用的硬性规则,也是很多同学计算mAP出错的核心原因。为了避免模型“作弊式刷分”(对同一个目标重复输出多个框,虚增TP数量),一个真实框只能匹配「置信度最高、IoU达标的一个预测框」为TP,其余匹配的框均为FP。
误区5:mAP越高,模型落地效果一定越好
纠正:不一定!mAP是整体平均性能,落地时需结合具体场景。比如:① 安防场景更看重行人的召回率(不漏检),哪怕mAP稍低,但行人AP高、召回率高,落地效果更好;② 工业质检更看重缺陷类别的AP,避免误检;③ 类别不平衡场景,mAP可能被大类别拉高,掩盖小类别(核心类别)的性能短板。
补充:YOLO的核心优势是“精度与速度的平衡”,落地时除了看mAP,还要关注FPS(推理速度)——比如YOLOv8m的mAP比YOLOv5s高,但FPS更低,嵌入式场景可能更适合YOLOv5s。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)