“老 中 新 ”三代日志系统
日志存储引擎
1.Elasticsearch
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。主要负责将日志索引并存储起来,方便业务方检索查询。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构 ,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类 日志统一收集、过滤后,转发给 Elasticsearch 进行下一步处理。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
Packetbeat(搜集网络流量数据)
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat(搜集文件数据)
Winlogbeat(搜集 Windows 事件日志数据)
Elasticsearch基本架构
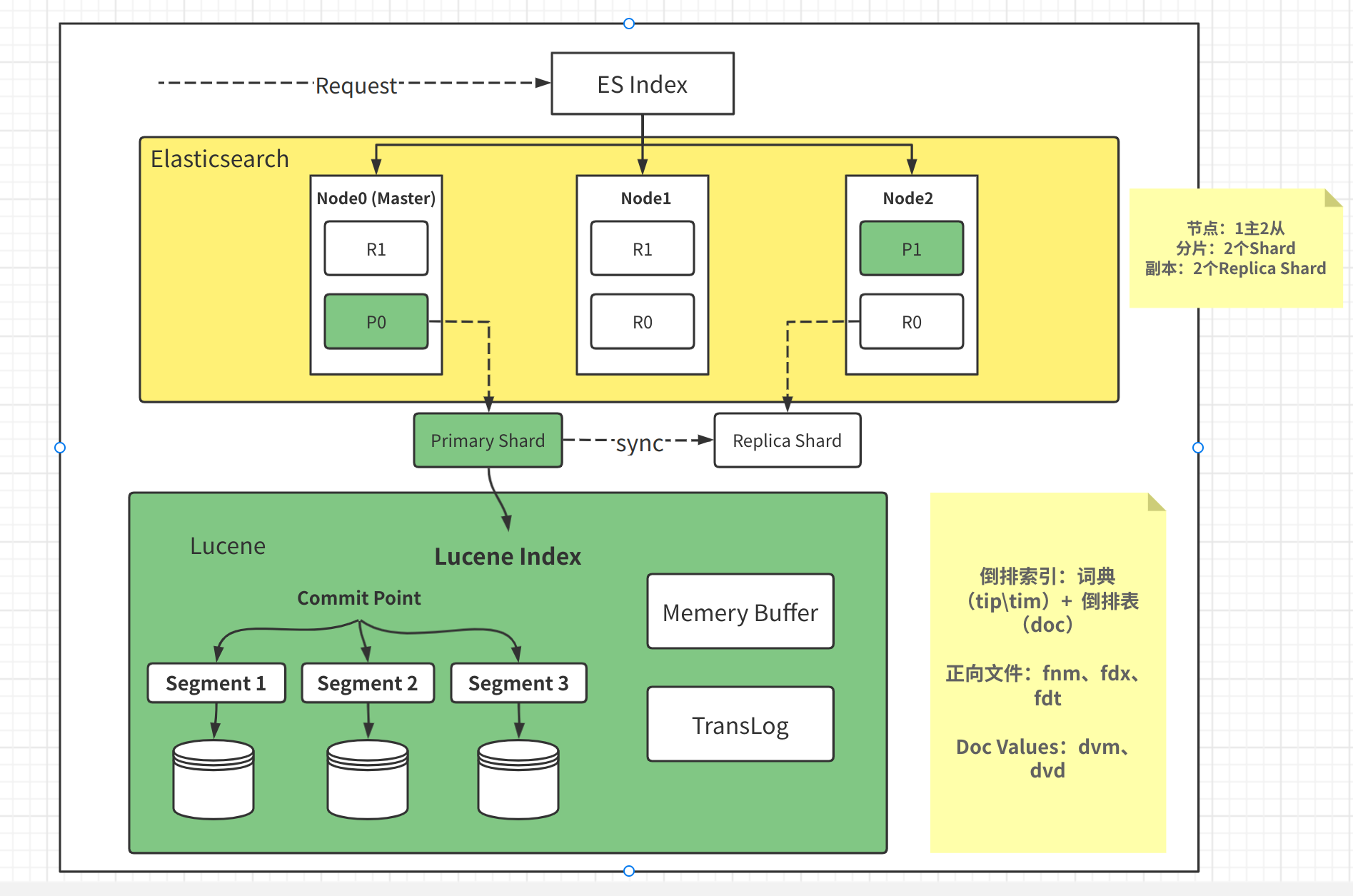
对于Elasticsearch更详细的介绍可以看frank大佬的教学写的十分详细:
倒排索引
倒排索引是整个 ES 的核心,正常的搜索以一本书为例,应该是由 “目录 -> 章节 -> 页码 -> 内容” 这样的查找顺序,这样是正排索引的思想。
但是设想一下,我在一本书中快速查找 “elasticsearch” 这个关键字所在的页面该怎么办?
倒排索引的思路是通过单词到文档ID的关系对应。
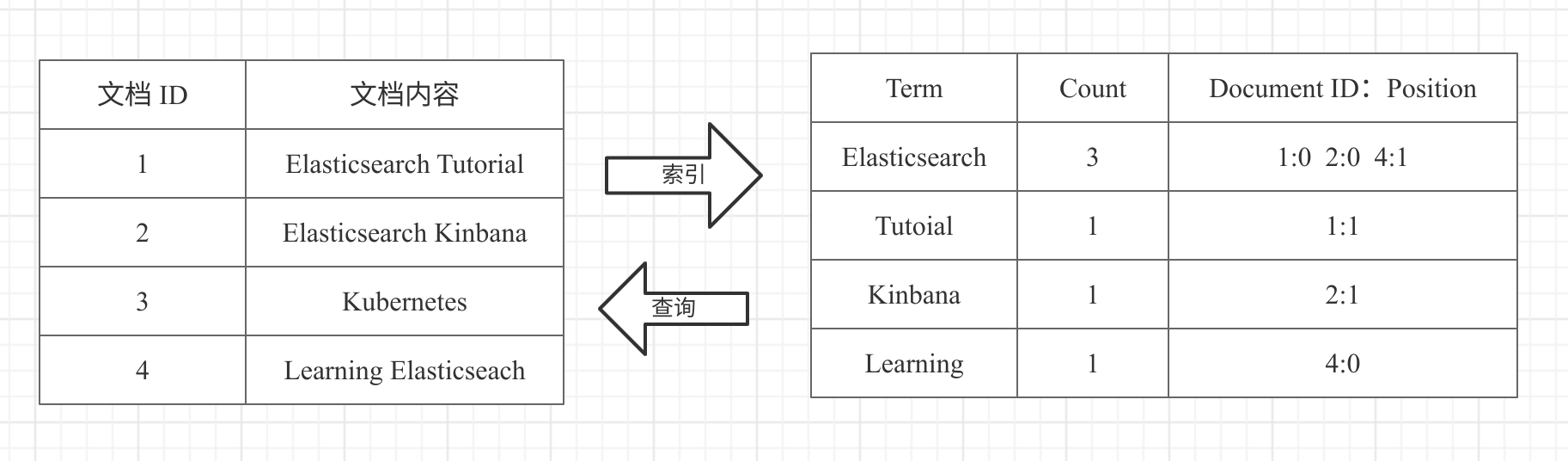
倒排索引包含两个部分:
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系(单词词典一般比较大,通过 B+ 树或哈希拉链法实现,以满足高性能的插入与查询)
倒排表(Posting List):记录了单词对应的文档结合,由倒排索引组成。
文档ID
- 词频 TF - 该单词在文档中分词的位置。用于语句搜索
- 位置(Position)- 单词在文档中分词的位置,用于语句搜索
- 偏移(Offset)- 记录单词的开始结束位置,实现高亮显示。
如何理解倒排索引呢?假如现有三份数据文档,文档的内容如下分别是:
- Java is the best programming language.
- PHP is the best programming language.
- Javascript is the best programming language.
为了创建倒排索引,我们通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
结果如下所示:
Term Doc_1 Doc_2 Doc_3
-------------------------------------
Java | X | |
is | X | X | X
the | X | X | X
best | X | X | X
programming | x | X | X
language | X | X | X
PHP | | X |
Javascript | | | X
-------------------------------------这种结构由文档中所有不重复词的列表构成,对于其中每个词都有一个文档列表与之关联。
这种由属性值来确定记录的位置的结构就是倒排索引。带有倒排索引的文件我们称为倒排文件。
我们将上面的内容转换为图的形式来说明倒排索引的结构信息,如下图所示:
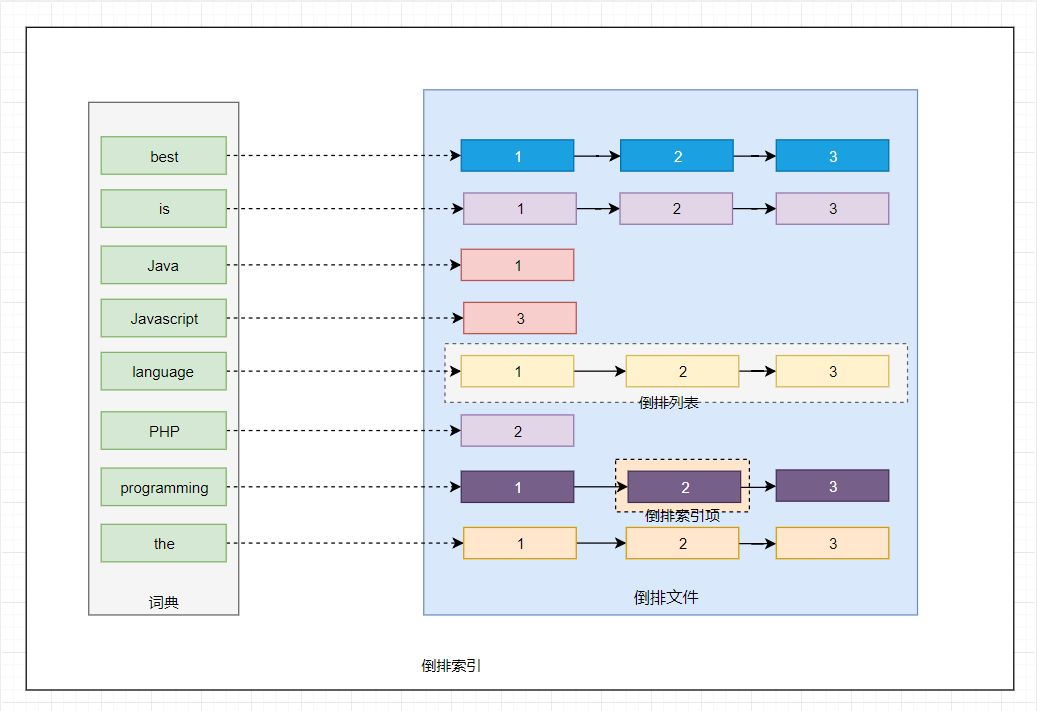
其中主要有如下几个核心术语需要理解:
词条(Term):索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
词典(Term Dictionary):或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。
每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储 了词频等信息。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
像 B+ 树一样,可以在页里实现二分查找。
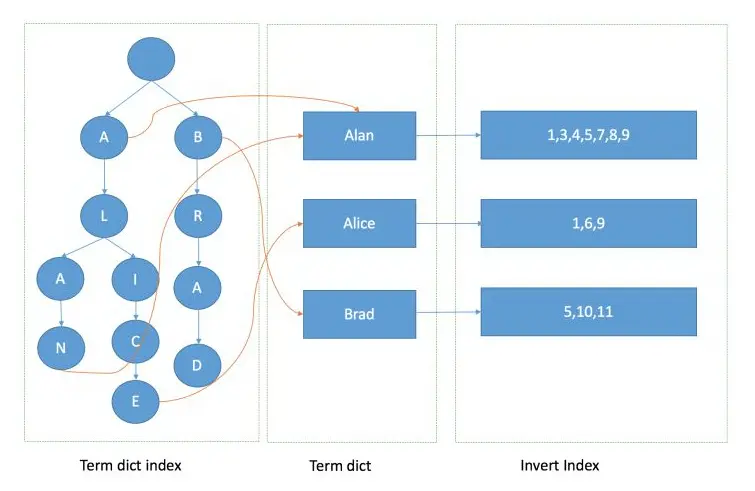
Lucene 的倒排索引,增加了最左边的一层「字典树」term index,它不存储所有的单词,只存储单词前缀,通过字典树找到单词所在的块,也就是单词的大概位置,再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
Lucene 的实现会要更加复杂,针对不同的数据结构采用不同的字典索引,使用了FST模型、BKDTree等结构。
真实的倒排记录也并非一个链表,而是采用了SkipList、BitSet等结构
2 loki
Grafana Loki 是一套可以组合成一个功能齐全的日志堆栈组件,与其他日志记录系统不同,Loki 是基于仅索引有关日志元数据的想法而构建的:标签(就像 Prometheus 标签一样)。日志数据本身被压缩然后并存储在对象存储(例如 S3 或 GCS)的块中,甚至存储在本地文件系统上,轻量级的索引和高度压缩的块简化了操作,并显著降低了 Loki 的成本,Loki 更适合中小团队。由于 Loki 使用和 Prometheus 类似的标签概念,所以如果你熟悉 Prometheus 那么将很容易上手,也可以直接和 Grafana 集成,只需要添加 Loki 数据源就可以开始查询日志数据了。
Loki 还提供了一个专门用于日志查询的 LogQL 查询语句,类似于 PromQL,通过 LogQL 我们可以很容易查询到需要的日志,也可以很轻松获取监控指标。Loki 还能够将 LogQL 查询直接转换为 Prometheus 指标。此外 Loki 允许我们定义有关 LogQL 指标的报警,并可以将它们和 Alertmanager 进行对接。
Grafana Loki 主要由 3 部分组成:
loki: 日志记录引擎,负责存储日志和处理查询promtail: 代理,负责收集日志并将其发送给 lokigrafana: UI 界面
概述
Loki 是一组可以组成功能齐全的日志收集堆栈的组件,与其他日志收集系统不同,Loki 的构建思想是仅为日志建立索引标签,而使原始日志消息保持未索引状态。这意味着 Loki 的运营成本更低,并且效率更高。
多租户
Loki 支持多租户,以使租户之间的数据完全分离。当 Loki 在多租户模式下运行时,所有数据(包括内存和长期存储中的数据)都由租户 ID 分区,该租户 ID 是从请求中的 X-Scope-OrgID HTTP 头中提取的。 当 Loki 不在多租户模式下时,将忽略 Header 头,并将租户 ID 设置为 fake,这将显示在索引和存储的块中。
运行模式
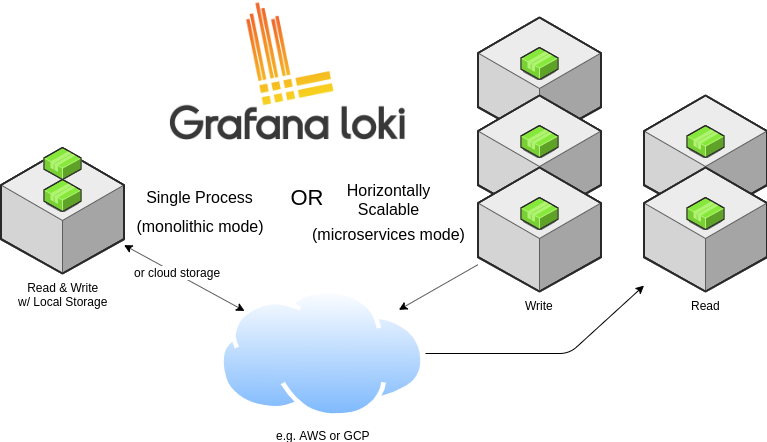
Loki 针对本地运行(或小规模运行)和水平扩展进行了优化,Loki 带有单一进程模式,可在一个进程中运行所有必需的微服务。单进程模式非常适合测试 Loki 或以小规模运行。为了实现水平可伸缩性,可以将 Loki 的服务拆分为单独的组件,从而使它们彼此独立地扩展。每个组件都产生一个用于内部请求的 gRPC 服务器和一个用于外部 API 请求的 HTTP 服务,所有组件都带有 HTTP 服务器,但是大多数只暴露就绪接口、运行状况和指标端点。
Loki 运行哪个组件取决于命令行中的 -target 标志或 Loki 的配置文件中的 target:<string> 配置。 当 target 的值为 all 时,Loki 将在单进程中运行其所有组件。,这称为单进程或单体模式。 使用 Helm 安装 Loki 时,单体模式是默认部署方式。
当 target 未设置为 all(即被设置为 querier、ingester、query-frontend 或 distributor),则可以说 Loki 在水平伸缩或微服务模式下运行。
Loki 的每个组件,例如 ingester 和 distributors 都使用 Loki 配置中定义的 gRPC 监听端口通过 gRPC 相互通信。当以单体模式运行组件时,仍然是这样的,尽管每个组件都以相同的进程运行,但它们仍将通过本地网络相互连接进行组件之间的通信。
单体模式非常适合于本地开发、小规模等场景,单体模式可以通过多个进程进行扩展,但有以下限制:
- 当运行带有多个副本的单体模式时,当前无法使用本地索引和本地存储,因为每个副本必须能够访问相同的存储后端,并且本地存储对于并发访问并不安全。
- 各个组件无法独立缩放,因此读取组件的数量不能超过写入组件的数量。
组件
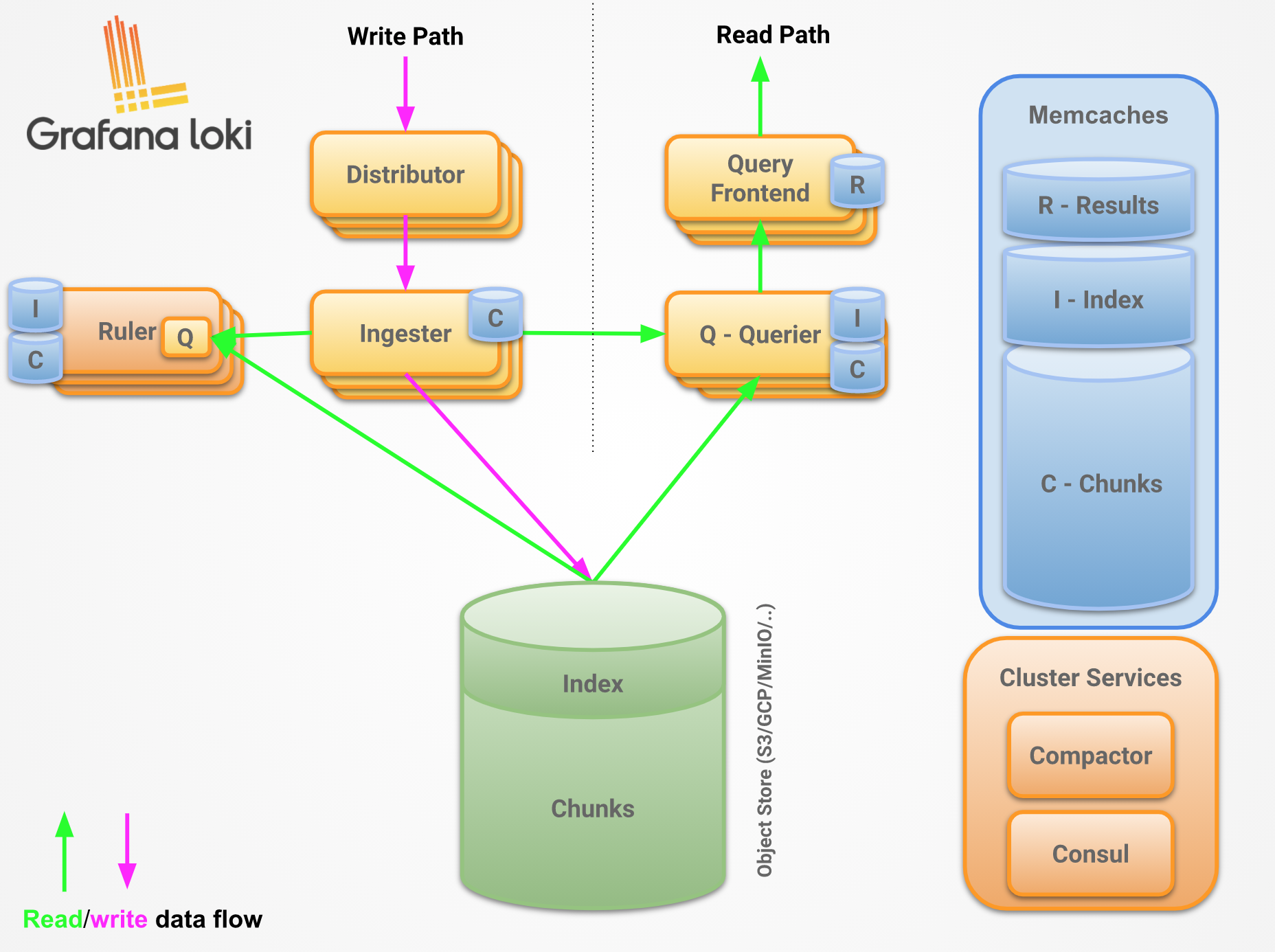
Distributor
distributor 服务负责处理客户端写入的日志,它本质上是日志数据写入路径中的第一站,一旦 distributor 收到日志数据,会将其拆分为多个批次,然后并行发送给多个 ingester。distributor 通过 gRPC 与 ingester 通信,它们都是无状态的,所以可以根据需要扩大或缩小规模。
Hashing
distributor 将一致性 Hash和可配置的复制因子结合使用,以确定 ingester 服务的哪些实例应该接收指定的数据流。
流是一组与租户和唯一标签集关联的日志,使用租户 ID 和标签集对流进行 hash 处理,然后使用哈希查询要发送流的 ingester。
存储在 Consul/Etcd 中的哈希环被用来实现一致性哈希,所有的 ingester 都会使用自己拥有的一组 Token 注册到哈希环中,每个 Token 是一个随机的无符号 32 位数字,与一组 Token 一起,ingester 将其状态注册到哈希环中,状态 JOINING 和 ACTIVE 都可以接收写请求,而 ACTIVE 和 LEAVING 的 ingester 可以接收读请求。在进行哈希查询时,distributor 只使用处于请求的适当状态的 ingester 的 Token。
为了进行哈希查找,distributor 找到最小合适的 Token,其值大于日志流的哈希值,当复制因子大于 1 时,属于不同 ingester 的下一个后续 Token(在环中顺时针方向)也将被包括在结果中。
这种哈希配置的效果是,一个 ingester 拥有的每个 Token 都负责一个范围的哈希值,如果有三个值为 0、25 和 50 的 Token,那么 3 的哈希值将被给予拥有 25 这个 Token 的 ingester,拥有 25 这个 Token 的 ingester 负责1-25的哈希值范围。
Ingester
ingester 负责接收 distributor 发送过来的日志数据,存储日志的索引数据以及内容数据。此外 ingester 会验证摄取的日志行是否按照时间戳递增的顺序接收的(即每条日志的时间戳都比前面的日志晚一些),当 ingester 收到不符合这个顺序的日志时,该日志行会被拒绝并返回一个错误。
- 如果传入的行与之前收到的行完全匹配(与之前的时间戳和日志文本都匹配),传入的行将被视为完全重复并被忽略。
- 如果传入的行与前一行的时间戳相同,但内容不同,则接受该日志行,表示同一时间戳有两个不同的日志行是可能的。
来自每个唯一标签集的日志在内存中被建立成 chunks(块),然后可以根据配置的时间间隔刷新到支持的后端存储。在下列情况下,块被压缩并标记为只读:
- 当前块容量已满(该值可配置)
- 过了太长时间没有更新当前块的内容
- 刷新了
每当一个数据块被压缩并标记为只读时,一个可写的数据块就会取代它。如果一个 ingester 进程崩溃或突然退出,所有尚未刷新的数据都会丢失,Loki 通常配置为多个副本来降低这种风险。
当向持久存储刷新时,该块将根据其租户、标签和内容进行哈希处理,这意味着具有相同数据副本的多个 ingester 实例不会将相同的数据两次写入备份存储中,但如果对其中一个副本的写入失败,则会在备份存储中创建多个不同的块对象。
WAL
上面我们提到了 ingester 将数据临时存储在内存中,如果发生了崩溃,可能会导致数据丢失,而 WAL 就可以帮助我们来提高这方面的可靠性。
在计算机领域,WAL(Write-ahead logging,预写式日志)是数据库系统提供原子性和持久化的一系列技术。
在使用 WAL 的系统中,所有的修改都先被写入到日志中,然后再被应用到系统状态中。通常包含 redo 和 undo 两部分信息。为什么需要使用 WAL,然后包含 redo 和 undo 信息呢?举个例子,如果一个系统直接将变更应用到系统状态中,那么在机器断电重启之后系统需要知道操作是成功了,还是只有部分成功或者是失败了(为了恢复状态)。如果使用了 WAL,那么在重启之后系统可以通过比较日志和系统状态来决定是继续完成操作还是撤销操作。
redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生断电之类的情况时系统可以在重启后继续操作。undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。
Loki 中的 WAL 记录了传入的数据,并将其存储在本地文件系统中,以保证在进程崩溃的情况下持久保存已确认的数据。重新启动后,Loki 将重放日志中的所有数据,然后将自身注册,准备进行后续写操作。这使得 Loki 能够保持在内存中缓冲数据的性能和成本优势,以及持久性优势(一旦写被确认,它就不会丢失数据)。
Querier
Querier 接收日志数据查询、聚合统计请求,使用 LogQL 查询语言处理查询,从 ingester 和长期存储中获取日志。
查询器查询所有 ingester 的内存数据,然后再到后端存储运行相同的查询。由于复制因子,查询器有可能会收到重复的数据。为了解决这个问题,查询器在内部对具有相同纳秒时间戳、标签集和日志信息的数据进行重复数据删除。
Query Frontend
Query Frontend 查询前端是一个可选的服务,可以用来加速读取路径。当查询前端就位时,将传入的查询请求定向到查询前端,而不是 querier, 为了执行实际的查询,群集中仍需要 querier 服务。
查询前端在内部执行一些查询调整,并在内部队列中保存查询。querier 作为 workers 从队列中提取作业,执行它们,并将它们返回到查询前端进行汇总。querier 需要配置查询前端地址,以便允许它们连接到查询前端。
查询前端是无状态的,然而,由于内部队列的工作方式,建议运行几个查询前台的副本,以获得公平调度的好处,在大多数情况下,两个副本应该足够了。
队列
查询前端的排队机制用于:
- 确保可能导致
querier出现内存不足(OOM)错误的查询在失败时被重试。这样管理员就可以为查询提供稍低的内存,或者并行运行更多的小型查询,这有助于降低总成本。 - 通过使用先进先出队列(FIFO)将多个大型请求分配到所有
querier上,以防止在单个querier中进行多个大型请求。 - 通过在租户之间公平调度查询。
分割
查询前端将较大的查询分割成多个较小的查询,在下游 querier 上并行执行这些查询,并将结果再次拼接起来。这可以防止大型查询在单个查询器中造成内存不足的问题,并有助于更快地执行这些查询。
缓存
查询前端支持缓存查询结果,并在后续查询中重复使用。如果缓存的结果不完整,查询前端会计算所需的子查询,并在下游 querier 上并行执行这些子查询。查询前端可以选择将查询与其 step 参数对齐,以提高查询结果的可缓存性。
读取路径
日志读取路径的流程如下所示:
- 查询器收到一个对数据的 HTTP 请求。
- 查询器将查询传递给所有
ingester。 ingester收到读取请求,并返回与查询相匹配的数据。- 如果没有
ingester返回数据,查询器会从后端存储加载数据,并对其运行查询。 - 查询器对所有收到的数据进行迭代和重复计算,通过 HTTP 连接返回最后一组数据。
写入路径

整体的日志写入路径如下所示:
distributor收到一个 HTTP 请求,以存储流的数据。- 每个流都使用哈希环进行哈希操作。
distributor将每个流发送到合适的ingester和他们的副本(基于配置的复制因子)。- 每个
ingester将为日志流数据创建一个块或附加到一个现有的块上。每个租户和每个标签集的块是唯一的。
3 VictoriaLogs
VictoriaLogs 是一款由 VictoriaMetrics 团队开源的、专为海量日志管理设计的高性能日志数据库。
在云原生时代,随着微服务架构的普及,日志量呈指数级爆发。传统的通用型搜索引擎(如 Elasticsearch)在处理纯日志场景时,往往面临着“吃内存、占磁盘、维护复杂”的痛点。而 VictoriaLogs 的诞生,正是为了以极低的硬件资源消耗,提供极速的全文检索体验。
1. 底层存储架构:列式存储 (Columnar Storage)
传统的 Elasticsearch 会对几乎所有字段建立“倒排索引”,导致索引体积比原始日志还大;而 Loki 虽然省空间,但在全文检索时往往需要暴力解压扫描(Grep)。
-
VictoriaLogs 的解法: 采用列式存储。同一列(例如同一个业务模块的所有的
status字段,或所有的IP字段)的数据在物理磁盘上是连续存放的。 -
降本原理(解释你的 45% 成本下降): 因为同一列的数据类型高度一致,VictoriaLogs 能够应用极其高效的压缩算法(如 ZSTD)。这使得它的磁盘占用率极低,甚至通常比未压缩的原始文本还要小得多(最高可达 15 倍的压缩比),直接大幅削减了存储成本。
2. 核心查询加速机制:布隆过滤器 (Bloom Filter) 与稀疏索引
你在项目中解决了海量数据检索的超时难题,面试官一定会问:“它是怎么做到全文检索又快又不怎么占内存的?”
-
Stream 概念: 类似于 Loki,VictoriaLogs 也会根据日志的标签(Labels,如
namespace,app,pod)将数据划分成不同的数据流(Stream)。 -
布隆过滤器魔法(解释你的 20 倍性能提升): VictoriaLogs 不建全量倒排索引,而是为数据块建立布隆过滤器。当用户搜索关键字
"NullPointerException"时,引擎会先问布隆过滤器:“这个数据块里有这个词吗?”-
如果布隆过滤器说“没有”,引擎直接跳过这个块,实现了极速的查询剪枝(Skipping),彻底避免了 Loki 那种全量扫盘造成的 CPU 飙升和超时。
-
如果说“可能有”,再去解压对应的数据块进行精确匹配。
-
3. 特有字段规范与采集端改造
你在主导平滑迁移时,肯定处理过字段和标签的兼容问题。
-
保留字段: VictoriaLogs 对日志结构有一些强制的最佳实践约定。比如,它强烈建议将真正的日志文本内容放在
_msg字段中,时间戳放在_time字段中,流标签放在_stream_id中。 -
采集器(Fluent Bit)适配: 面试时可以说出你的实战细节——在使用 Fluent Bit 采集数据时,需要通过
modify或renameFilter 插件,将原始日志的log或message字段重命名为_msg,以完美契合 VictoriaLogs 的底层存储预期,保证查询效率最大化。
4. 查询语言:LogsQL (管道式查询)
VictoriaLogs 使用的 LogsQL 是一种非常符合直觉的管道式(Piped)查询语言,类似 Linux 的命令管道 |。
-
语法特点: 先通过标签和时间范围快速过滤出基础数据流,然后再通过管道符进行全文搜索、正则匹配或统计聚合。
-
面试表达示例: “在排障时,我们可以通过
_time:5m AND app:"payment" | ~"timeout|error" | stats by (host) count()这样的语法,极速定位过去 5 分钟内支付服务不同节点的报错量。它的学习成本比 ES 的 DSL 低很多,也比 Loki 的 LogQL 在复杂统计上更直观。”
5. 高可用与平滑迁移策略
在生产集群部署时,稳定性是第一位的。
-
无损接入: VictoriaLogs 原生兼容多种写入协议(包括 Elasticsearch Bulk API、Loki API、JSON 等)。这意味着在迁移过程中,无需大规模重构前端业务代码。
-
双写过渡: 在架构演进期,可以通过 Fluent Bit 的配置,将日志同时
Output到原有的 Loki 和新的 VictoriaLogs 集群(双写)。经过灰度试点、数据比对和验证,确认 VictoriaLogs 各项指标稳定后,再平滑切断 Loki 的写入,实现业务零感知的迁移。
我们是否要革新我们的日志系统?
首先我们要确认的是:有些工具能在某些场景下解决某些问题,但绝对不是解决一切的工具
Loki VS Elasticsearch VS Victorialogs
| Elasticsearch (ES) | Grafana Loki | VictoriaLogs (Vlogs) | |
| 设计定位 | 通用型搜索引擎 | 云原生轻量级日志聚合 | 高性能、高压缩日志数据库 |
| 索引机制 | 全量倒排索引 (最重) | 仅索引标签 (Labels) (最轻) | 布隆过滤器 + 稀疏索引 (折中) |
| 存储开销 | 极高 (由于索引膨胀) | 极低 (仅存压缩块) | 极低 (列式存储+极致压缩) |
| 资源消耗 | 内存与 CPU 消耗极大 (JVM) | 低内存,但全文检索时 CPU 极高 | 极低的内存与 CPU 开销 |
| 全文检索 | 极快 (依赖倒排索引) | 极慢 (纯暴力扫描,易超时) | 极快 (依赖布隆过滤器剪枝) |
| 查询语言 | Lucene Query / ES DSL | LogQL | LogsQL (管道式,易上手) |
采集器
- logstash 超大规模日志时,日志先存到kafka,再通过logstash同步到elasticsearch
对于日志规模不大时,不需要用到logstash。由于Elasticsearch具有解析的能力(如Logstash过滤器)— Ingest,这意味着可以将数据直接用Filebeat推送到Elasticsearch,并让Elasticsearch既做解析的事情,又做存储的事情
- filebeat ,轻量级解决方案
filebeat读日志文件,elasticsearch处理并存储。能满足绝大部分需求了。而且filebeat是所有采集方案中,最轻量级的 - fluent,插件比Filebeat更多,功能更加丰富,资源占用只是稍微比filebeat多一点
有结构化数据结构需求时,filebeat有点力不从心。例如:
(1)使用spring框架,日志直接通过tcp发送到fluent,不用输出到文件
(2)对于超大规模日志时,直接传输到elasticsearch,elasticsearch通过ingest处理,再存储。这时,elasticsearch处理不过来。可以通过fluent传到kafka,再通过logstash同步到elasticsearch
| 采集器 | 开发语言 | 资源消耗 | 核心生态/阵营 | 核心优势与特点 | 典型应用场景 |
| Logstash | Java (JRuby) | 极高 (JVM) | Elastic Stack (ELK) | 插件极其丰富,数据清洗、转换(Grok)能力最强。 | 集中式的日志处理中心、复杂日志清洗。 |
| Filebeat | Go | 较低 | Elastic Stack (EFK) | 轻量级,无依赖,通常作为 Logstash 的前置采集器部署在节点上。 | 边缘节点文件日志采集、轻量级转发。 |
| Fluentd | Ruby + C | 中等 | CNCF (云原生) | 统一的日志层,支持数百个插件,路由和过滤能力强大。 | K8s 集群级的集中式日志聚合与路由。 |
| Fluent Bit | C | 极低 | CNCF (云原生) | 专为云端和边缘计算设计,内存占用通常在 MB 级别,内置 K8s 过滤器。 | 云原生环境、K8s DaemonSet 节点级采集。 |
| Promtail | Go | 较低 | Grafana Labs (Loki) | 与 Loki 深度绑定,强项在于提取日志标签(Labels)以对齐 Prometheus。 | 纯 Loki 架构下的日志采集。 |
| Grafana Alloy | Go | 中等 | Grafana Labs (OTel) | 兼容 OpenTelemetry,统一采集日志、指标(Metrics)和链路追踪(Traces)。 | 现代高阶可观测性平台、多信号统一采集。 |
| Vector | Rust | 极低 | Datadog | 性能怪兽,极高的吞吐量和极低的延迟,支持极其复杂的路由拓扑。 | 超大规模日志流处理、高性能网关。 |
面试核心考点:它们之间的本质区别
在面试中,不要只是背诵它们的特点,要能够讲出它们在实际架构中的定位差异:
1. “重型处理” vs “轻量级采集”
-
Logstash / Fluentd (重型): 它们通常不直接部署在业务的每一个 Pod 或节点里,因为太吃内存了。它们一般作为聚合层(Aggregator),接收来自轻量级采集器的数据,进行复杂的正则匹配、脱敏、多行拼接后,再发给存储端。
-
Fluent Bit / Filebeat / Promtail (轻量级): 它们是纯粹的 Agent(代理)。以 Fluent Bit 为例,因为它完全用 C 语言编写,可以直接以 DaemonSet 的形式部署在 K8s 的每个 Node 上,对宿主机 CPU 和内存的侵入性降到了最低。
2. “单一职责” vs “统一可观测性 (Alloy)”
-
传统的 Filebeat 或 Promtail 通常只负责“收日志”。
-
Grafana Alloy 代表了目前的最新趋势。它是 Grafana 整合了原有的 Grafana Agent 后推出的新一代采集器。它的最大区别在于原生支持 OpenTelemetry (OTel) 协议。这意味着你不需要在服务器上同时跑 Node Exporter(收指标)、Fluent Bit(收日志)和 Jaeger Agent(收链路),只需要一个 Alloy 就能搞定所有可观测性数据的采集与路由,大大降低了运维成本。
3. 云原生的适配度
在 K8s 环境下,采集器不仅要收集 /var/log/containers/ 下的日志文件,还要能把日志和 K8s 的元数据(比如这段日志属于哪个 Namespace、哪个 Pod、哪个 Label)结合起来。
-
Fluent Bit 凭借其轻量的特性和优秀的
kubernetesfilter 插件,成为了 K8s 环境下最主流的日志采集标准之一。 -
Promtail 的区别在于它会像 Prometheus 抓取指标一样去“发现”日志目标(Service Discovery),并严格要求给日志打上 Label,这对于后续在 Grafana 中联动 Metrics 和 Logs 非常方便。
Logstash
1. 核心架构:三段式流水线 (Pipeline)
Logstash 的内部运行机制是一个非常经典的事件驱动模型。
-
Inputs(输入源): 负责采集数据。它可以同时接收多种协议和来源的数据,比如 Beats(如 Filebeat 发来的日志)、Kafka(消息队列)、TCP/UDP 端口、甚至直接去拉取关系型数据库的数据。
-
Filters(过滤器/转换器):这是 Logstash 最强大、也是最消耗资源的核心大脑。 当日志事件穿过 Filter 时,Logstash 会对它们进行解析、丰富、脱敏和修改。
-
Outputs(输出目标): 将处理好的标准 JSON 数据发送到下游。最典型的下游是 Elasticsearch,但它也能输出到文件、Kafka、或者通过 Webhook 发给告警系统。
2. 为什么说它“重”?(底层运行环境)
在面试中,如果你能点出 Logstash 的底层机制,面试官一定会对你刮目相看。
-
JRuby 与 JVM 引擎: 与 C 语言编写的 Fluent Bit(几十 KB 内存)不同,Logstash 是用 JRuby 编写的,运行在 Java 虚拟机 (JVM) 上。
-
资源消耗怪兽: 启动一个闲置的 Logstash 进程,通常就需要占用 1GB 左右的堆内存(Heap Size)。如果在高吞吐量下进行复杂的正则匹配,它不仅极其吃内存,还会消耗大量的 CPU 资源。
-
背压机制(Backpressure): Logstash 内部有一个基于内存或磁盘的持久化队列(Persistent Queues, PQ)。当 Output 端(如 ES)写入变慢时,Logstash 的队列会积压,进而拒绝接收 Input 端的新数据,以此来保护自身不被 OOM 撑爆。
3. Logstash 的“杀手锏”:Grok 解析
在没有大模型的时代,把杂乱无章的文本日志变成 Elasticsearch 能够建立倒排索引的结构化 JSON,全靠 Logstash 的 Grok 插件。这也是日常运维中最常打交道的地方。
Grok 的本质: 预定义了一大堆宏的正则表达式(Regex)。
举个最直观的例子,一段原始的 Nginx 访问日志: 192.168.1.10 - - [10/Oct/2023:13:55:36 -0700] "GET /api/v1/users HTTP/1.1" 200 4321
通过 Logstash 的 Grok 匹配规则: %{IPORHOST:client_ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:http_version}" %{NUMBER:response_code} %{NUMBER:bytes}
它瞬间就能被切分成完美的 JSON 字段,这样 Elasticsearch 才能针对 response_code: 200 或者 client_ip 进行高效的快速聚合查询。除了 Grok,它还常搭配 mutate(字段增删改)和 geoip(将 IP 转换为地理位置经纬度)一起使用。
4. 经典企业级架构:缓冲层的引入
由于 Logstash 太重,直接把它部署在业务节点上采集日志是不现实的。在真实的工业界,经典的重型架构通常是这样的:
-
采集层 (Shipper): 在每台机器/Pod 上部署轻量级的 Filebeat。
-
缓冲层 (Buffer): Filebeat 不直接发给 Logstash,而是发给 Kafka 集群削峰填谷。
-
处理层 (Aggregator): 几台高配的独立服务器专门运行 Logstash 集群,作为“消费者”从 Kafka 拉取日志,疯狂进行 Grok 正则解析。
-
存储层 (Storage): 结构化后的数据最终写入 Elasticsearch。
Filebeat工作原理
- 1、Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
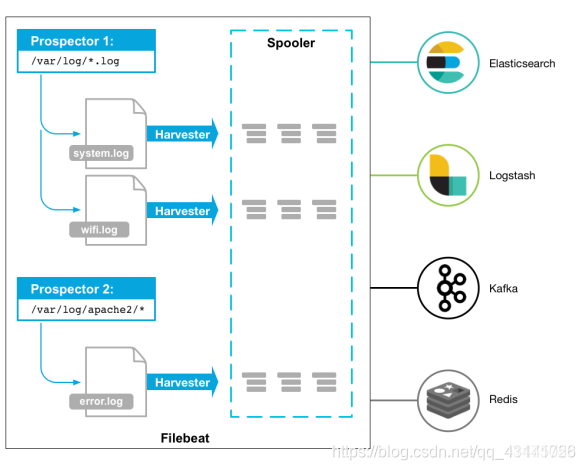
2、Harvester(收割机):负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
3、Prospector(勘测者):负责管理Harvester并找到所有读取源。
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
filebeat.prospectors:
- input_type: log
paths:
- /apps/logs/*/info.log
4、Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
5、Filebeat如何保证事件至少被输出一次:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
遥测数据处理往往非常复杂,尤其是在大规模高并发场景下。正因如此,Fluentd 应运而生。它不仅是一个基础的采集工具,更发展成为了一个完整的可观测性生态系统,包含了适用于不同语言的 SDK 以及重要的子项目——Fluent Bit。
核心共同点
这两个项目在底层理念上有很深的渊源,Fluent Bit 的设计和构建正是基于 Fluentd 架构的最佳实践。它们都具备以下特质:
-
开源开放:均基于 Apache License v2.0 条款开源。
-
权威认证:都是由云原生计算基金会 (CNCF) 托管的顶级毕业项目。
-
生产级验证:均为经过实战检验的生产级解决方案,其中 Fluent Bit 在全球部署量已超过 150 亿次。
-
厂商中立:秉持绝对的厂商中立与社区驱动原则。
-
大厂背书:被业界广泛采用,深受亚马逊、微软、谷歌等数百家头部科技公司的信赖。
Fluentd 与 Fluent Bit
核心差异对比表
具体选择哪一款工具,本质上取决于业务的具体需求和部署环境。以下是两者在技术规格上的详细横向对比:
| 对比维度 | Fluentd (聚合器首选) | Fluent Bit (边缘 Agent 首选) |
| 适用范围 | 容器 / 服务器 | 嵌入式 Linux / 容器 / 服务器 |
| 开发语言 | C 和 Ruby | C |
| 内存占用 | > 60 MB | 约 450 KB (极低侵入性) |
| 系统性能 | 中等 | 极高性能 / 高吞吐 |
| 依赖关系 | 作为 Ruby Gem 构建,依赖于其他底层 gem。 | 极度轻量,除非特定插件需要,否则无外部依赖。 |
| 插件生态 | 极其庞大,提供超过 1000 个外部插件。 | 精简高效,内置超过 100 个核心插件可供选择。 |
| 开源许可证 | Apache License v2.0 | Apache License v2.0 |
架构演进趋势
在实际的云原生架构中,Fluentd 和 Fluent Bit 既可以独立运行,也可以完美互补。传统的经典架构是:在边缘节点部署 Fluent Bit 进行轻量级采集,随后转发给中心的 Fluentd 集群进行复杂的集中式聚合与过滤。
但值得关注的行业趋势是:近年来,为了追求极致的性能表现、更优的服务器资源利用率以及更简化的运维链路,主流云服务提供商与企业级架构已逐渐将重心完全转向 Fluent Bit。凭借其不断完善的插件生态,Fluent Bit 现已被业界广泛视为下一代的高性能遥测数据解决方案。
Flentbit
1. 核心架构:Fluent Bit 的六步数据流水线
Fluent Bit 的设计哲学是“管道化”。一条日志从产生到存入后端(如 Loki 或 VictoriaLogs),会经历以下六个阶段:
-
Input(输入):负责收集数据。最常用的是
tail插件,也就是像tail -f命令一样去实时读取日志文件的追加内容。 -
Parser(解析):将非结构化的文本(如单纯的字符串)转换为结构化数据(如 JSON)。比如把一条 Nginx 的文本日志拆分成
IP、Status_Code、URL等字段。 -
Filter(过滤与清洗):这是面试最爱考的地方。 你可以在这里丢弃无用日志、修改日志内容、或者追加元数据(比如加上这台机器的 IP、或者 K8s 的 Pod 名称)。
-
Buffer(缓冲):日志在发往目的地之前,会先暂存在内存或磁盘中。这就像一个蓄水池,用来应对瞬时的日志洪峰。
-
Routing(路由):根据日志的
Tag(标签),决定这条日志该走哪条通道。比如业务日志发给 VictoriaLogs,安全审计日志发给 Elasticsearch。 -
Output(输出):将缓冲好的日志打包,通过网络请求发送给目标存储。
2. K8s 下的终极形态:DaemonSet 与元数据注入
在 Kubernetes 体系中,业务 Pod 会在各个 Node(节点)上动态漂移。因为日志通常存储在运行业务 Pod 的宿主机节点上,所以 Fluent Bit 需要具备节点本地的访问权限。
这正是为什么通常采用 DaemonSet 模式部署的原因:它确保在集群的每一个 Node 上都运行且只运行一个 Fluent Bit 实例,使其能够直接读取并推送节点本地磁盘上的日志到日志存储后端。
它的工作流是这样的:
-
业务 Pod 把日志打到标准输出(stdout)。K8s 会把这些日志截获,存入宿主机的
/var/log/containers/目录下。 -
Fluent Bit Pod 会把宿主机的这个目录**挂载(Volume Mount)**到自己的容器里,用
tail插件去读。 -
核心魔法(kubernetes filter 插件):Fluent Bit 拿到一条日志后,只知道它的文件名(比如
pod-a-xyz.log)。kubernetes插件会拿着这个名字去问 K8s API Server:“这个 Pod 属于哪个 Namespace?它身上有什么 Labels?”问到之后,将这些信息拼接到日志里。最终在查询面板上,你才能通过namespace=prod这样的条件搜到日志。
3. 进阶:缓冲(Buffer)与背压(Backpressure)
如果你在面试中提到自己维护过采集链路的稳定性,面试官极有可能问你:“如果目标存储宕机了,或者写入速度跟不上,Fluent Bit 会崩溃吗?”
这就是内存缓冲区溢出的经典问题。Fluent Bit 中内存缓冲区溢出的根本原因,通常是因为配置的缓冲区容量太小,无法承受涌入的庞大数据量。 为了解决这个问题,你需要掌握它的防崩溃机制:
-
Chunk(数据块):Fluent Bit 不会一条条发日志,而是把日志打包成 Chunk。
-
内存 vs 磁盘缓冲:默认情况下,Chunk 存在内存里。如果后端阻塞,内存会迅速被撑爆导致 OOM(Out of Memory)。生产环境中,SRE 必须配置
storage.type filesystem,开启磁盘缓冲(混合模式)。内存满了就写到磁盘里。 -
背压机制(Mem_Buf_Limit):你可以给 Input 插件设置一个
Mem_Buf_Limit(比如 10MB)。当内存中的未发送日志达到 10MB 时,Fluent Bit 会暂停读取新日志(暂停 tail),直到之前的日志成功发出去。这就叫背压。
Alloy
1. 核心定位:可观测性领域的“瑞士军刀”
在以前的架构中,为了全面监控一个 K8s 集群,你可能需要在节点上同时跑三个 Agent:
-
用 Fluent Bit 或 Promtail 收日志 (Logs)
-
用 Prometheus Node Exporter 收指标 (Metrics)
-
用 Jaeger Agent 收链路追踪 (Traces)
Alloy 的降维打击在于“大一统”。它是一个开源的 OpenTelemetry (OTel) Collector 发行版。这意味着你只需要在服务器上部署 一个 Alloy 二进制文件,就能同时收集指标、日志、链路追踪(Traces)甚至性能剖析(Profiles)数据。这种统一收集不仅降低了 CPU 和内存的开销,还极大地减轻了 SRE 的运维负担。
2. 颠覆性架构:从“线性流水线”到“有向无环图 (DAG)”
这是面试中最能体现你技术深度的部分。
-
传统流水线(如 Fluent Bit / 标准 OTel):通常是线性的
输入 (Receiver) -> 处理 (Processor) -> 输出 (Exporter)。 -
Alloy 的 DAG 架构:Alloy 采用了基于组件(Component)的有向无环图(DAG)模型。你可以把数据流想象成乐高积木,各个组件之间通过引用相互连接,可以实现极其复杂的网状路由策略。
-
Alloy 配置语法 (Alloy Syntax):它没有使用传统的 YAML,而是使用了一种高度可编程的、类似 Terraform (HCL) 的声明式配置语言(其前身称为 River)。你可以直接在配置文件里写逻辑表达式、连接组件。
一个典型的处理逻辑示例: 你可以配置一个 loki.source.api 组件通过 HTTP 接收日志,然后把输出直接“连”到 loki.process 组件进行过滤和标签提取,最后再“连”到 loki.write 发送到远端。
3. 为什么选 Alloy 而不是原生 OTel Collector?
“既然 Alloy 是基于 OpenTelemetry Collector 的,那我为什么不直接用原生的 OTel 呢?”
“原生 OTel Collector 追求的是绝对的厂商中立,配置相对底层。而 Alloy 是**‘开箱即用 (Batteries included)’**的。如果我们的技术栈深度绑定了 Grafana 生态(比如用了 Prometheus 看指标、Loki 查日志、Tempo 查链路),Alloy 内置了针对这些组件的原生优化管道,甚至不需要做格式转换。同时,它也完全兼容 OTLP 协议,保留了未来切换后端的灵活性。”

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)