(2026|ICLR|中科院自动化所,CLIP,特征记忆库/检索,使用动态提示扩展 CLIP 提示)MRAD:基于记忆驱动检索的零样本异常检测
本文探索替代主流参数化拟合的异常检测方法,即直接利用辅助数据的经验分布。基于这一思想,本文提出了 MRAD,一个统一的记忆驱动的检索框架。基础模型 MRAD-TF 在冻结的视觉骨干网络上构建两级记忆库,并通过相似度检索解决分类和分割问题。
MRAD: Zero-Shot Anomaly Detection with Memory-Driven Retrieval

论文地址:https://arxiv.org/abs/2602.00522
项目页面:https://github.com/CROVO1026/MRAD
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
在跨数据集的分析表明,与正常和异常特征集合的相似度能够可靠地反映正常程度,同时保留微妙的内部变化。
受此观察启发,本文提出了一个新的零样本异常检测(zero-shot anomaly detection,ZSAD)框架 MRAD(Memory-Retrieval Anomaly Detection,记忆检索异常检测),用直接的特征-标签检索范式替代参数化拟合。
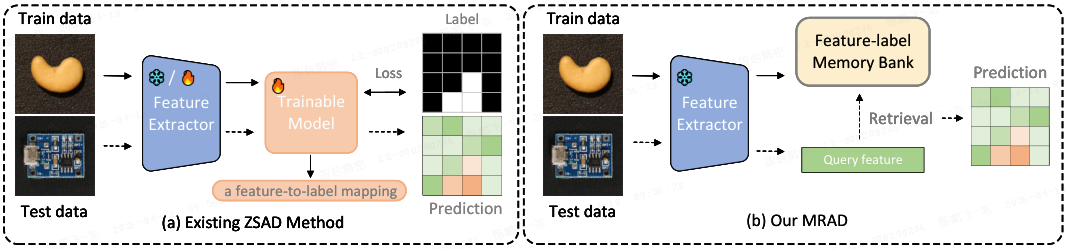
具体地,如上图所示,
- 本文构建了一个两级记忆库,显式存储特征-标签对作为键(key)和值(value)。
- 推理时,通过相似度检索获得异常得分,从而降低训练成本、过拟合和信息损失。
基于这个无训练的 MRAD 模型(MRAD-TF),本文提出了两个轻量级增强:
- (i)MRAD-FT,仅添加两个线性层来微调检索度量,以较低的训练成本同时提升分类和分割性能;
- (ii)MRAD-CLIP,将 MRAD-FT 的区域先验作为动态偏置注入可学习的 CLIP 文本提示中,增强定位能力和对未见类别的泛化能力。该变体改进了传统的动态提示学习方法,后者在未见类别上效果不足。
3. MRAD:基于记忆检索的异常检测
3.1 概述
3.1.1 动机
基于冻结的 CLIP 图像编码器的相似度分布,本文进行了一项跨数据集研究:
- 将来自数据集 A 的 patch 特征作为查询,数据集 B 的 patch 特征作为键。
- 设 K 为异常和正常键的集合;设 V 为与键对齐的 one-hot 标签矩阵。
对于查询特征 q,本文定义其基于检索的异常和正常相似度得分为:
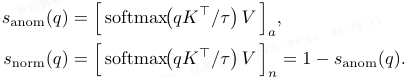
其中 τ 是温度参数,[⋅]_a 选择 “异常” 通道。换言之,s_anom(q) 是查询 q 分配给异常键的 softmax 相似度得分,而 s_norm(q) 是分配给正常键的得分。
接着令 Ω_A 和 Ω_N 分别表示异常和正常查询的索引集,本文聚合了四个数据集级别的统计量:
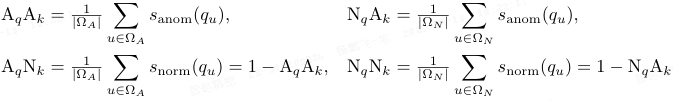
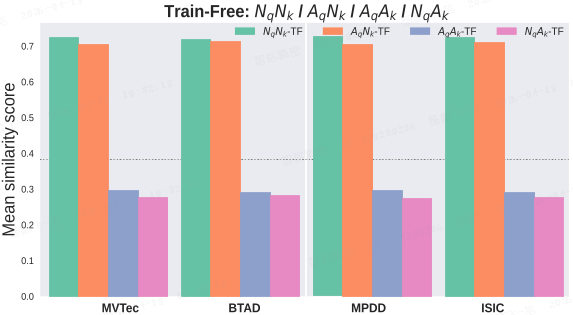
在各个数据集上,一致观察到 NqNk > AqNk 和 AqAk > NqAk(如上图所示),这表明相似度得分 s_anom(q) 是一个稳定的异常判别信号。
受此观察启发,本文用相似度检索替代参数化拟合。
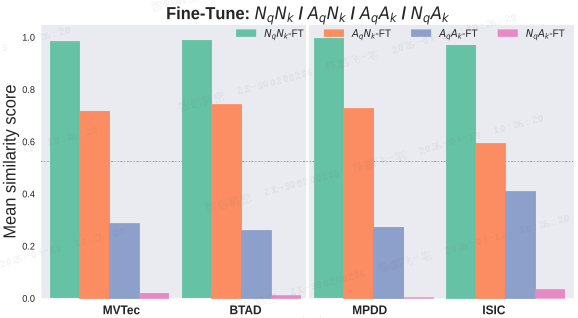
此外,本文引入了一种轻量级微调策略,进一步扩大 AqAk 与 NqAk 的差距(如下图所示)。
【注:这里可以观察到的额外的一个现象是:NqNk >> AqAk
论文中未给出说明,我的猜想是:不同数据集的异常是不同的,
- 使用数据集 A 的异常,在数据集 B 的异常中检索,相似度分数较低
- 使用数据集 A 的正常,在数据集 B 的异常中检索,只会得到更低的相似度,所以,1 - 这个相似度,就会得到一个较大的结果
一个更合理的对比方法是,不使用 “1 - NqAk” 间接得到 NqNk,而是使用数据集 A 的正常,在数据集 B 的正常中检索,从而直接得到 NqNk
】
3.1.2 方法概述
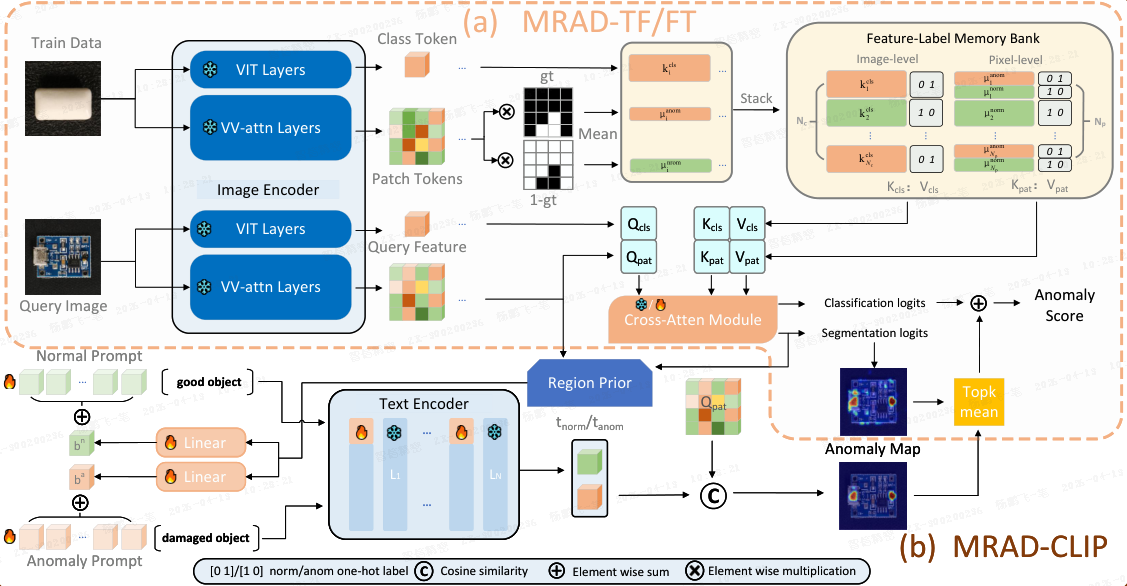
如上图所示,给定一个辅助数据集,MRAD-TF 冻结 CLIP 图像编码器,从辅助数据集中提取类别 token 和 patch token,构建一个两级特征-标签记忆库。在推理时,使用查询图像在记忆库检索,产生图像级别的异常得分和像素级别的异常图。
为了以很小的代价进一步提升判别能力,MRAD-FT 在交叉注意力模块中添加了两个线性层来微调检索度量,同时保持骨干网络冻结。
基于 MRAD-FT,本文提出了 MRAD-CLIP,它将区域先验注入可学习的 CLIP 提示中,从而在传统的提示学习方法基础上提升泛化能力和异常定位精度。
3.2 MRAD:从无训练到微调
3.2.1 特征-标签记忆库
观察到针对正常/异常特征的检索具有很强的判别性,本文用两级特征-标签记忆库替代了可训练的显式分类器。
本文将冻结的 CLIP 图像编码器拆分为全局分支 ϕ_cls(输出类别 token)和局部分支 ϕ_vv(V-V 注意力,输出 patch token),两者共享相同的预训练权重。对于第 i 张图像 I_i,全局特征和第 u 个 patch 特征为:
![]()
其中特征经过 ℓ2 归一化以实现稳定的检索。给定一个二值掩码标签,将其下采样到 ϕ_vv 的 patch 网格,并用 ~M_{i,u} 表示第 u 个 patch 的标签。
对于异常图像,分别对标注异常区域内部和外部的 patch 特征取平均,得到两个区域原型。分别记这些 patch 级别的原型为 μ^anom_i(仅 ~M_{i,u} = 1 的 patch)和 μ^norm_i(仅 ~M_{i,u} = 0 的 patch)。
对于正常标注的图像,仅计算正常原型 μ^norm_i(等价于 ~M_{i,u} ≡ 0)。
令 e_norm = [1,0]^⊤ 和 e_anom = [0,1]^⊤ 表示 one-hot 标签。记忆库因此包含两个级别:
- (i) 一个图像级记忆库,存储每个全局特征 k^cls_i 及其正常/异常标签 e_norm 和 e_anom。
- (ii) 一个 patch 级记忆库,存储区域原型 μ^norm_i 和 μ^anom_i 及其对应的标签 e_norm 和 e_anom。
最后,堆叠键和值得到矩阵形式:
![]()
其中 N_c 是图像级条目数,N_p > N_c 是 patch 级条目数。
3.2.2 MRAD-TF:无训练基础模型
对于查询图像 I,得到全局和 patch 查询 Q_cls,Q_pat = ϕ(I)
交叉注意力模块中基于检索的检测过程定义为:
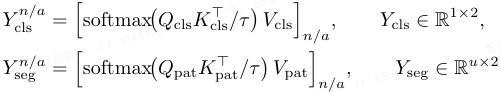
其中 [⋅]^{n/a} 选择正常/异常通道,Y_seg 表示分割 logits,表示每个 patch 的正常/异常得分。
对于像素级分割,将 Y^a_seg 上采样形成异常图 ~M。
对于图像级分类,最终异常得分计算为:
![]()
本文将 TopKMean(~M) 定义为上采样异常图 ~M 中最大的 k 个值的平均值,这能够突出高置信度的异常区域,同时抑制背景噪声。
3.2.3 MRAD-FT:轻量级微调
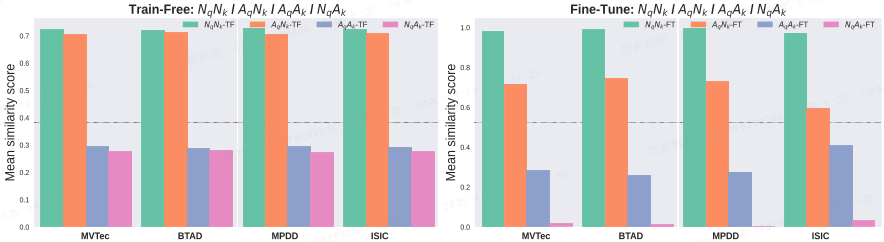
如上图所示,在无训练设置下,正常与异常相似度之间的判别边际有限。因此,本文采用一种轻量级微调方法,校准检索度量以更好地对齐正常和异常语义。其结果是,数据集级别的统计量(例如 AqAk−NqAk)表现出更大的分离度,从而得到更可靠的异常决策。
具体来说,对于查询-键对,本文插入两个线性映射 Wq,Wk
微调后的检索过程定义为:
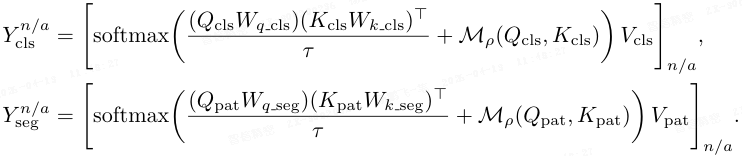
为了稳定训练,本文应用一个相似度 dropout 算子 M_ρ(⋅,⋅),该算子对每个查询在 QK^⊤ 矩阵中 mask 掉相似度最高的前 ρ%,在训练期间将其 logits 设为 −∞(推理时保留所有匹配)。这可以防止单数据集设置中的琐碎自匹配,并鼓励对相似度较低的特征进行鲁棒的判别。
给定分类标签 y 和分割掩码 M,目标函数结合了分类损失和分割损失:
![]()
其中 BCE(⋅,⋅) 表示二值交叉熵损失,Dice(⋅,⋅) 表示 Dice 损失,Focal(⋅,⋅) 表示 Focal 损失。
3.3 MRAD-CLIP:动态提示学习扩展
为了在保持视觉分支冻结的同时利用语言先验,本文用可学习的上下文 token 扩充 CLIP 提示,并注入来自 MRAD-FT 的图像特定先验。
静态、对象无关的提示。 本文将 E 个可学习的上下文 token 预置到文本模板 “good object” 和 “damaged object” 之前,形成类别无关的提示:
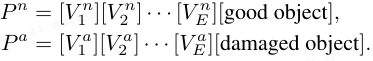
先验引导的动态偏置。 给定一张查询图像,本文对 MRAD-FT 的异常图进行阈值分割,分离出异常区域和正常区域,并对每个区域内的 patch 特征取平均得到原型(prototypes)。这些原型通过轻量级线性层投影为偏置向量 b^{n/a},然后添加到 E 个上下文 token 上,形成图像特定的动态提示:
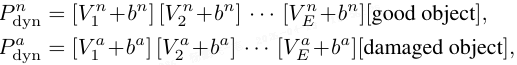
提示条件的余弦分类器。 给定 CLIP 文本编码器 T(⋅)(遵循与 AnomalyCLIP 相同的设置)和 ℓ2 归一化 Norm(⋅),本文从 CLIP 文本编码器获得归一化的文本
![]()
然后使用余弦分类器进行预测:
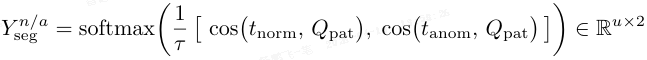
其中,cos(t,Q_pat) 返回 t 与所有 patch 特征之间的余弦相似度向量。通过将 Y^a_seg 上采样到原始图像分辨率得到精炼的异常图。
![]()
仅训练文本侧参数,视觉编码器和 MRAD 记忆库保持冻结。本文使用如上的分类和分割损失,从而得到一个提示条件的精炼模块,以极少的额外参数改善局部对齐并减少背景假阳性。
4. 实验
4.1 实验设置
数据集。 本文在 16 个公开数据集上评估 ZSAD 性能,涵盖工业和医疗领域。
- 遵循 ZSAD 设置,本文使用单个工业数据集作为辅助训练源,直接测试其余工业数据集和所有医疗数据集。
- 默认情况下,本文采用 VisA 作为辅助数据集构建记忆库,因为其类别与其他数据集不重叠;当评估 VisA 自身时,本文改用 MVTec-AD 作为辅助数据集。
评估指标。
- 对于图像级分类任务,本文报告 ROC 曲线下面积(AUROC)和平均精度(AP)。
- 对于分割任务,本文采用像素级 AUROC 和区域重叠度(PRO)指标来评估定位性能。
实现细节。
- 遵循先前工作,使用公开可用的 CLIP(ViT-L/14-336)预训练权重,输入分辨率统一为 518×518。
- 从图像编码器的最后一层提取类别 token 和 patch token 来构建记忆库:当使用 MVTec-AD 作为辅助数据集时,记忆库包含 1725/2976(类别/patch)条目;当使用 VisA 时,包含 2162/3093 条目。
- 对于 MRAD-CLIP,将可学习提示长度设为 12。
- 使用 Adam 优化器,学习率为 5×10−4,批量大小为 8。
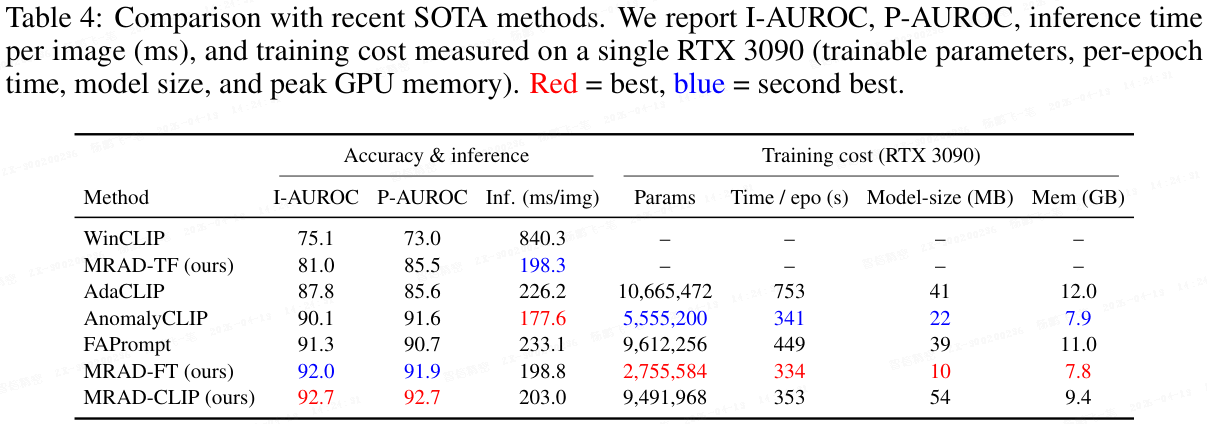
4.2 与最先进方法的比较
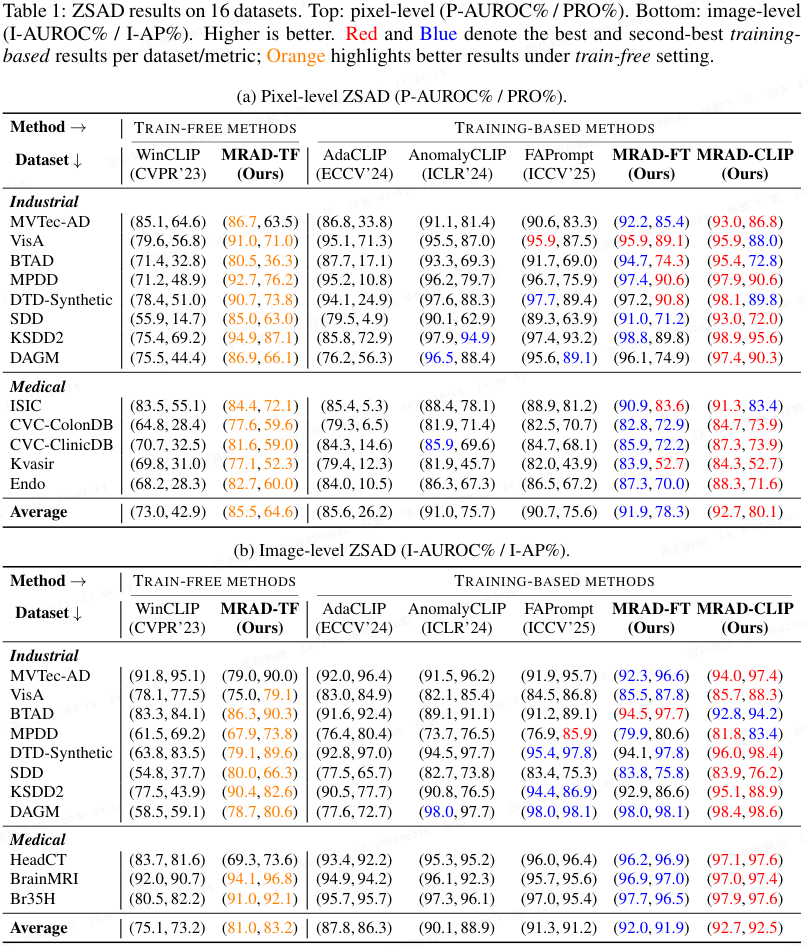
定量比较。 如上表所示,报告了涵盖工业和医疗领域的 16 个数据集上的结果。
- MRAD-TF 已经超越了先前的无训练基线(如 WinCLIP),表明直接访问经验特征-标签分布非常有效。
- 在此无训练模型基础上,MRAD-FT 在像素级和图像级指标上进一步超越了基于训练的方法(如 FAPrompt、AnomalyCLIP)。
- 此外,MRAD-CLIP 在 ZSAD 中取得了最先进的结果,与最强的前期工作(包括本文的 MRAD-FT)相比具有一致的性能优势,表明以区域先验为条件的动态提示增强了跨域泛化能力并锐化了定位精度。
综合来看,这些结果表明本文的 MRAD 是一个强大的 ZSAD 方法,并且可以以原则性的方式轻松扩展以达到最先进的性能,彰显了该框架的有效性和灵活性。

定性比较。
- 在工业数据集(多样化的材料、纹理和成像条件)上,MRAD-TF 和 MRAD-CLIP 在图像级和像素级指标上名列前茅。它们还表现出较低的跨数据集方差和最小的排名波动,表明对背景杂波和细粒度缺陷具有鲁棒性。
- 在医疗数据集(较大的形态变异和强烈的领域偏移)上,同样的模式成立:轻量级度量校准和先验引导的提示在跨域迁移下保持了决策边界和定位质量。
定性来看,生成的 heatmap 具有更少的背景假阳性、更紧致的异常边界以及跨域大范围缺陷区域的更平滑定位。这些观察与定量提升相一致,进一步支持了本文方法的稳定性和泛化能力。
4.3 消融实验
本文进行了广泛的消融实验,以检验 MRAD 框架中不同组件的贡献。所有结果均在代表性的工业或医疗数据集上报告。
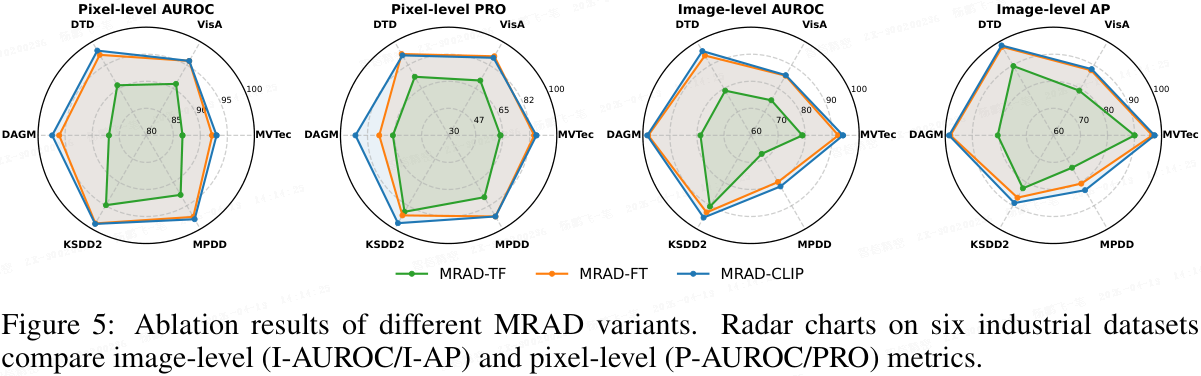
关于 TF/FT/CLIP 的消融。 在六个工业数据集上,如图 5 所示,雷达图揭示了清晰的单调趋势。
- MRAD-TF 建立了有竞争力的性能,而在 MRAD-FT 中添加两个线性层在图像级(I-AUROC/I-AP)和像素级(P-AUROC/PRO)指标上均带来了一致的提升。这表明轻量级微调有效地增强了分类和分割的判别能力。
- 在此基础上,MRAD-CLIP 通过结合区域先验的动态提示学习进一步提升了性能,尤其是在像素级指标上,同时在图像级得分上也产生了微小但一致的增益。
- 曲线在所有轴上的向外扩展证实了每个组件贡献了互补的收益,提供了稳定的改进而非数据集特定的尖峰。
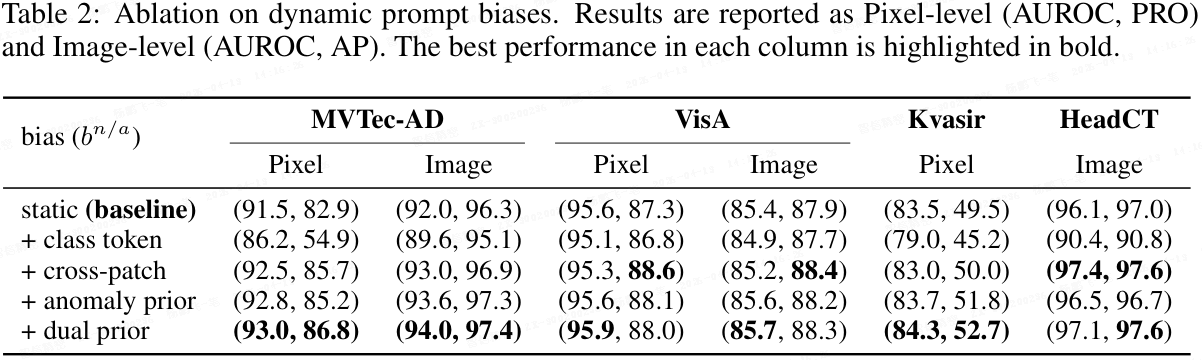
关于动态提示偏置的消融。 本文仅改变 MRAD-CLIP 动态提示中加性偏置的来源,保持其他所有组件固定。表格 2 报告了四个数据集上的像素级(AUROC/PRO)和图像级(AUROC/AP)结果。
- 静态变体(无偏置;等价于 AnomalyCLIP)作为基线。
- 来自类别 token 的偏置(类似于 CoCoOp)降低了分割和跨域鲁棒性,表明仅靠全局特征是不够的。
- 引入跨 patch 注意力(两个可学习查询关注 patch 特征)改善了 ZSAD 性能,表明以区域级上下文为条件的提示有助于对未见类别的泛化。
- 受此观察指导,以 MRAD-FT 异常先验为条件产生了一致的图像级和像素级增益。
- 此外,同时注入正常和异常先验(双先验)在多个数据集上实现了几乎最佳且最鲁棒的性能。
这些结果表明,具有显式先验的局部区域感知偏置对 ZSAD 至关重要,而仅使用全局特征往往会削弱性能。
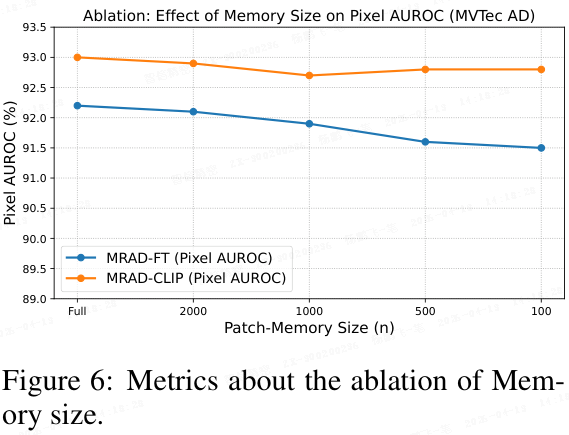
记忆库大小消融。 本文通过随机下采样对 patch 级记忆库进行消融,取 n∈ {Full, 2000, 1000, 500, 100}。对于每个 n,本文在多个随机子样本上取平均,并在 MVTec-AD 上报告 MRAD-FT 和 MRAD-CLIP 的像素 AUROC(如图 6 所示)。
- 随着 n 减小,由于记忆库中原型覆盖范围的减少,两种方法都表现出平缓但微小的下降。然而,下降幅度仅在千分之几以内,证明了 MRAD 框架的强大鲁棒性。
- 相对而言,MRAD-CLIP 在小记忆库大小下更加鲁棒,表现出更小的下降和更低的方差,这主要因为它不依赖于提示的精确动态偏置,并且已经可以从粗略的区域先验中受益。
在实践中,本文认为即使在典型预算下使用小规模记忆库(n≥100),具有多样性感知的记忆库也能接近完整性能。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)