语音识别准确性测试方法论
摘要:本文系统介绍了语音识别系统的测试方法论,涵盖核心测试维度、场景设计矩阵和自动化框架搭建。重点包括WER计算伪代码、致命缺陷识别清单(如静音误触发、数字误识别等)以及深度优化策略(声学模型对抗训练、领域术语校准)。报告关键指标要求WER≤8%、延迟<800ms,并提供测试工具链推荐(Python+Playwright+Pytest)。适用于AI测试工程师构建智能语音产品的质量保障体系。(
·
适用对象:AI测试工程师、质量保障专员、语音产品测试团队
一、核心测试维度
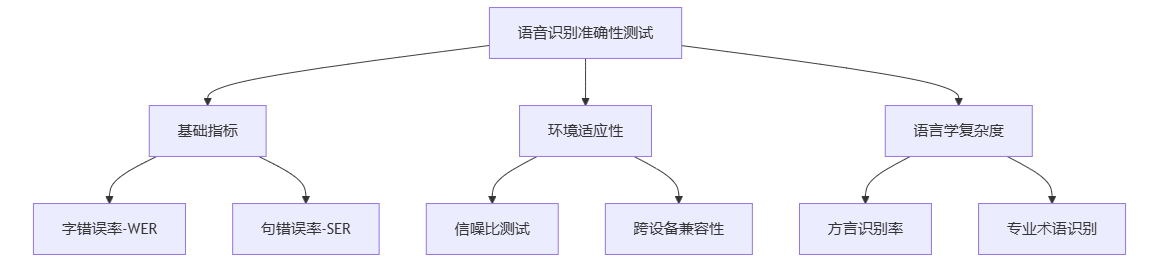
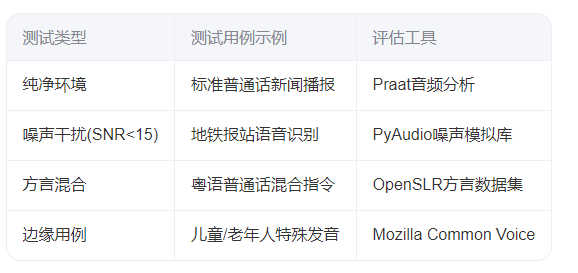
二、测试场景设计矩阵
三、自动化测试框架搭建
# 伪代码示例:WER自动化计算流程
def calculate_wer(reference, hypothesis):
# 使用动态规划计算编辑距离
d = levenshtein_distance(ref_words, hyp_words)
return d / len(ref_words)
# 多场景批量测试
for test_case in test_suite:
audio = load_audio(test_case.path)
result = asr_engine.transcribe(audio)
wer = calculate_wer(test_case.transcript, result.text)
log_metrics(test_case.id, wer, result.latency)
四、致命缺陷识别清单
-
静音误触发:无声输入产生虚报文本
-
数字误识别:”12306“ → ”一二三零六“
-
同音字混淆:”登录“ vs ”登陆“
-
分词错误:”北京地铁“ → ”北京 铁 皮“
五、深度优化策略
-
声学模型强化:采用对抗样本训练(如增加白噪声扰动)
-
语言模型校准:注入垂直领域术语库(教育场景需加入课件术语)
-
端到端测试方案:
音频输入 → VAD端点检测 → 特征提取 → 声学评分 → 语义解码 → 输出验证
六、测试报告关键指标
{
"accuracy_metrics": {
"WER": "≤8%(纯净环境)",
"SER": "≤15%",
"hotword_recall": "≥95%"
},
"performance": {
"latency": "<800ms(实时场景)",
"throughput": "≥50并发流"
}
}
精选文章:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)