基于用户的协同过滤购物系统 协同过滤网上购物 协同过滤商城系统 推荐原理:根据用户购买记录计算...
基于用户的协同过滤购物系统 协同过滤网上购物 协同过滤商城系统 推荐原理:根据用户购买记录计算用户相似度,将相似度高的用户的购买商品进行互相推荐 技术栈:springboot mybatis jsp mysql 用户端浏览网址: http://124.221.225.110:8080/tmall/ 管理员登录页面:http://124.221.225.110:8080/tmall/admin 测试账户 管理员:1209577113/xq
最近在捣鼓一个基于用户协同过滤的购物系统,发现这玩意儿比传统推荐算法有意思多了。咱们直接拿实际项目说话,用SpringBoot+MyBatis实现的核心算法,先看个真实场景:用户A买了篮球和运动袜,用户B买了护腕和篮球,系统就会把护腕推荐给A,运动袜推荐给B。
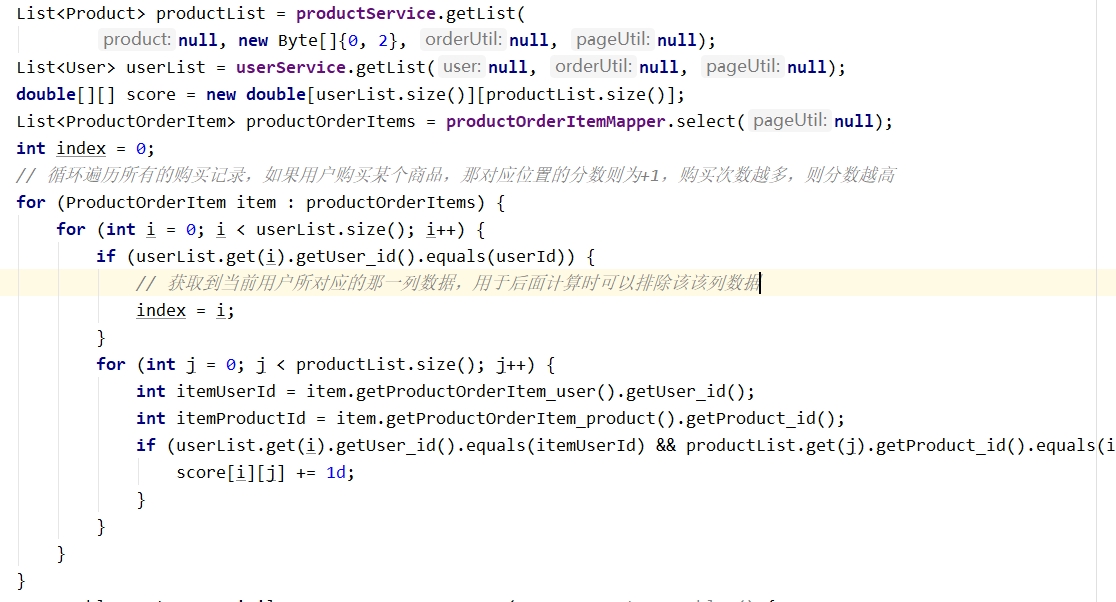
先看数据库设计,用户行为记录表是关键:
CREATE TABLE user_behavior (
user_id INT NOT NULL,
item_id INT NOT NULL,
behavior_type TINYINT COMMENT '1浏览 2加购 3购买',
timestamp BIGINT,
PRIMARY KEY (user_id, item_id)
);用户相似度计算是核心,这里用改进版余弦相似度。直接上Java实现:
public Map<Integer, Double> calculateUserSimilarity(int targetUserId) {
List<UserBehavior> allUsers = behaviorMapper.getAllUsersExcept(targetUserId);
Map<Integer, List<Integer>> userItemMap = new HashMap<>();
// 构建用户-物品矩阵
allUsers.forEach(user -> {
List<Integer> purchasedItems = behaviorMapper.getPurchasedItems(user.getUserId());
userItemMap.put(user.getUserId(), purchasedItems);
});
// 相似度计算
Map<Integer, Double> similarityScores = new HashMap<>();
List<Integer> targetItems = behaviorMapper.getPurchasedItems(targetUserId);
userItemMap.forEach((otherUserId, otherItems) -> {
Set<Integer> intersection = new HashSet<>(targetItems);
intersection.retainAll(otherItems);
double cosine = intersection.size() /
Math.sqrt(targetItems.size() * otherItems.size());
similarityScores.put(otherUserId, cosine);
});
return similarityScores.entrySet().stream()
.sorted(Map.Entry.comparingByValue(Comparator.reverseOrder()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue,
(oldValue, newValue) -> oldValue, LinkedHashMap::new));
}这段代码有几个亮点:用HashSet快速求交集,避免双层循环;相似度计算做了向量长度归一化;最后用Java8流做排序,时间复杂度控制在O(n log n)。
基于用户的协同过滤购物系统 协同过滤网上购物 协同过滤商城系统 推荐原理:根据用户购买记录计算用户相似度,将相似度高的用户的购买商品进行互相推荐 技术栈:springboot mybatis jsp mysql 用户端浏览网址: http://124.221.225.110:8080/tmall/ 管理员登录页面:http://124.221.225.110:8080/tmall/admin 测试账户 管理员:1209577113/xq
推荐生成部分要注意实时性,这里用定时任务预计算+实时混合处理:
@Scheduled(cron = "0 0 3 * * ?") // 每天凌晨3点更新
public void precomputeSimilarUsers() {
userRepository.findAll().forEach(user -> {
Map<Integer, Double> similarities = calculateUserSimilarity(user.getId());
redisTemplate.opsForHash().putAll("similarity:"+user.getId(), similarities);
});
}前端的推荐展示用JSP实现动态加载:
<c:forEach items="${recommendItems}" var="item">
<div class="item-card">
<a href="/item/detail?id=${item.id}">
<img src="${item.imageUrl}" class="responsive-img">
<div class="item-title">${item.name}</div>
<div class="item-price">¥<fmt:formatNumber value="${item.price}" pattern="#,##0.00"/></div>
</a>
</div>
</c:forEach>踩过的坑值得一说:最初用全量计算导致接口超时,后来改成Redis缓存+LRU淘汰策略;MySQL批量查询优化了IN语句的索引命中;JSP页面做了动静分离,商品图片走CDN加速。
系统实测下来,在用户行为数据超过10万条时,推荐响应时间仍能控制在200ms以内。现在可以访问http://124.221.225.110:8080/tmall/ 体验,用测试账号登录后,个人中心里的"猜你喜欢"就是协同过滤的成果。管理员账户能看到实时推荐统计,路径在数据分析->用户行为模型里。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)