Kafka 常见问题 | Apache Kafka 官方学习文档
Kafka 常见问题 | Apache Kafka 官方学习文档
本文基于 Confluent 官方 Kafka 常见问题解答文档(https://docs.confluent.io/kafka/faq.html#how-do-i-get-started-with-ak)整理,涵盖Kafka核心定义、工作原理、核心概念、优势及快速上手方式,是Kafka入门的核心参考内容。
一、什么是Apache Kafka?
Apache Kafka® 是一款分布式事件流处理平台,专为处理高吞吐、实时的数据流设计。你可以将Kafka作为数据基础设施的核心中枢,构建可扩展、容错的实时事件流处理应用。
Kafka 提供持久化存储、高性能、水平扩展能力,是实时分析、事件驱动架构等场景的理想选择,其核心定位是打通各类系统的实时数据流转,成为企业数据生态的核心链路。
二、Kafka 的典型应用场景
Kafka 可跨行业应用于各类实时数据处理场景,核心使用场景包括:
- 实时数据管道:构建在系统间实时传输数据的管道,实现数据的高效流转
- 事件驱动架构:创建能对事件进行实时响应的应用,适配微服务架构的异步交互需求
- 流处理:对数据流进行实时的处理和转换,挖掘数据实时价值
- 行为追踪:跟踪用户行为、系统指标及应用日志,实现全链路监控
- 消息通信:作为微服务架构的高吞吐消息系统,实现服务间解耦
- 数据集成:整合多源数据,并向多个消费者提供统一的数据访问能力
- 日志聚合:收集并聚合多个服务的日志数据,实现日志的集中管理与分析
三、Kafka 工作原理
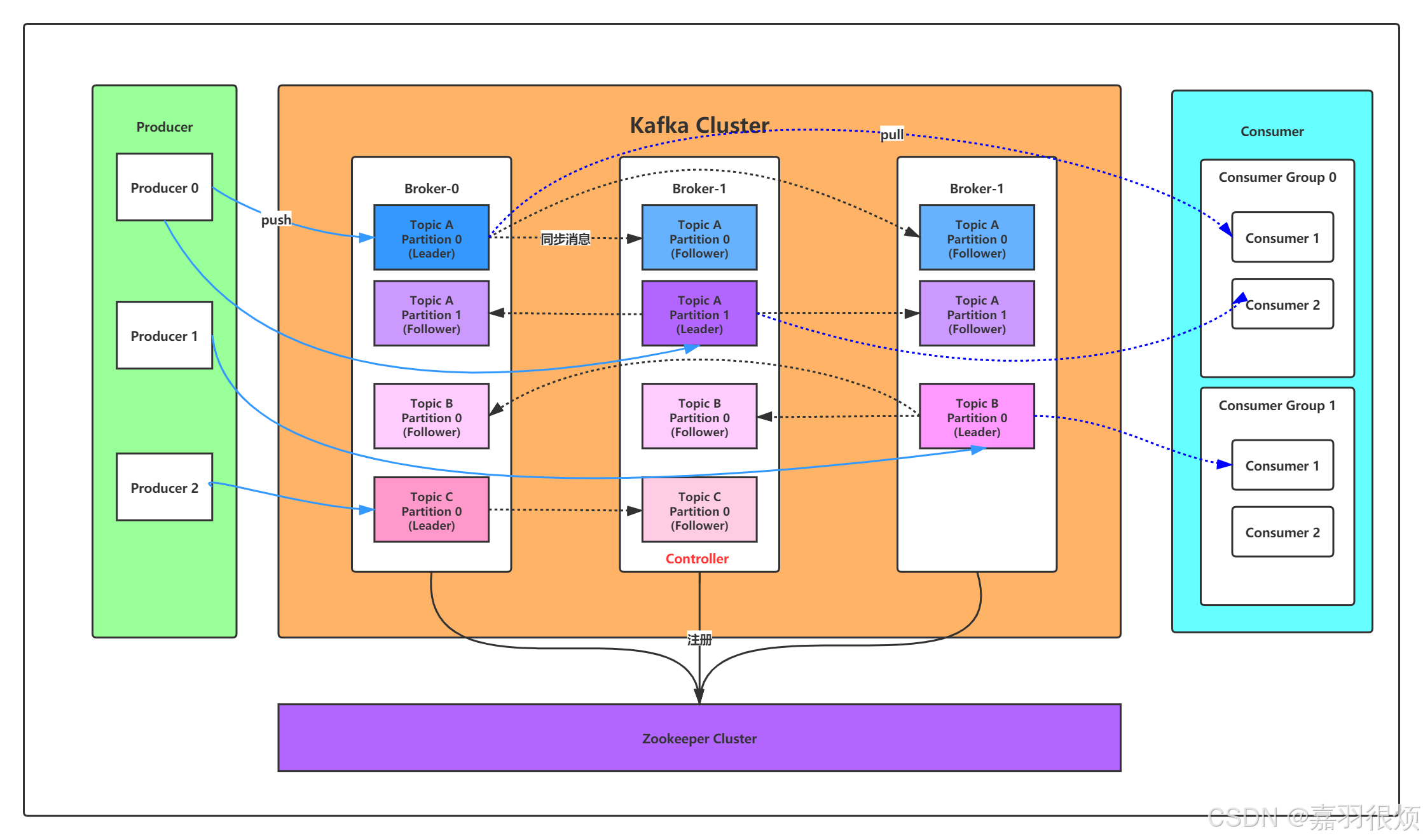
Kafka 以Broker分布式集群为核心,将事件流存储在主题(Topic)中,整体工作流程遵循发布-订阅模型,核心逻辑如下:
- 生产者(Producer)将事件写入指定的主题;
- 主题按类别组织事件,并可拆分为多个分区(Partition)实现并行处理;
- Broker 负责数据的存储和分发,并通过副本机制实现容错;
- 消费者(Consumer)从主题中读取事件,并自主维护在每个分区中的消费位置(偏移量/Offset)。
Kafka 采用基于日志的存储模型,事件以追加的方式写入主题,且可被多次读取。这种设计赋予了Kafka高吞吐、高持久化的特性,同时支持历史数据的重放处理。
四、使用Kafka 的核心优势
Kafka 相比传统数据传输工具,具备八大核心优势,也是其成为主流分布式事件流平台的关键:
- 高吞吐:每秒可处理数百万条事件,轻松支撑海量实时数据场景
- 可扩展性:通过新增Broker节点实现水平扩展,无需中断服务
- 持久化:对事件进行持久化存储,并可长期保留历史数据
- 容错性:副本机制确保即使Broker节点故障,数据依然可用
- 低延迟:专为实时处理设计,数据传输延迟极小
- 解耦性:实现系统间的无依赖通信,降低服务耦合度
- 可重放:消费者可通过重置偏移量,重新处理历史数据
- 多生产多消费:支持多个应用同时向同一主题生产、消费数据
五、Kafka 与传统消息系统的区别
Kafka 在设计上与传统消息系统有本质区别,核心差异体现在以下六点:
| 特性 | Kafka | 传统消息系统 |
|---|---|---|
| 持久化 | 持久化存储事件,消费后不删除 | 多为临时存储,消费后通常删除消息 |
| 可重放 | 支持重置偏移量,多次读取同一事件 | 无重放能力,消息消费后不可再读 |
| 吞吐能力 | 专为高吞吐设计,百万级消息/秒 | 吞吐能力有限,适用于低流量场景 |
| 分区机制 | 支持跨Broker的主题分区,实现并行处理 | 无分区设计,串行处理消息 |
| 存储模型 | 基于追加写的日志模型 | 基于队列的存储模型 |
| 扩展性 | 新增Broker实现水平扩展 | 扩展能力有限,多为垂直扩展 |
六、Kafka 核心概念详解
6.1 主题(Topic)与分区(Partition)
主题是事件发布的类别或源名称,是Kafka最基础的组织单元;分区是对主题的拆分,是Kafka实现并行处理和水平扩展的核心。
核心特性
- 一个主题可包含一个或多个分区;
- 每个分区是有序、不可变的事件序列;
- 分区支持多个消费者的并行处理,提升消费效率;
- 相同键(Key) 的事件会被写入同一个分区,保证事件的顺序性。
6.2 Broker(代理节点)
Broker 是Kafka集群中存储事件流的服务器,一个Kafka集群由多个协同工作的Broker组成,核心特性:
- 单个Broker每秒可处理数十万次读写请求,性能强悍;
- Broker 负责存储主题及其对应的分区;
- 集群中的每个Broker同时也是引导服务器(bootstrap server) ,连接任意一个Broker即可访问整个集群;
- Broker 之间通过数据复制,实现集群的容错能力。
6.3 生产者(Producer)与消费者(Consumer)
生产者和消费者是Kafka的客户端应用,分别负责事件的写入和读取,核心特性:
生产者
- 控制事件的分区分配策略,如按键(Key)哈希或轮询(round-robin)分配;
- 可向同一主题并行写入数据,支持多生产者协同工作。
消费者
- 自主维护在每个读取分区中的偏移量(Offset) ,即消费位置;
- 可同时从多个分区和主题中读取数据;
- 支持多消费者同时处理同一主题的事件,实现并行消费。
6.4 副本机制(Replication)
复制是指在Kafka集群的不同Broker间维护多份数据副本的过程,是Kafka实现高可用和容错的核心机制,核心价值:
- 容错性:若某个Broker故障,可从副本中获取数据,不影响服务;
- 高可用性:即使Broker故障,集群仍可继续对外提供服务;
- 数据持久性:多份数据副本确保数据不会因节点故障丢失。
生产环境最佳实践:将副本因子(replication factor)设置为3,即每份数据在不同Broker上保留3个副本,兼顾容错性和资源利用率。
6.5 Kafka Connect 与 Kafka Streams
除核心的生产消费能力外,Kafka 还提供两大核心组件,完善实时数据处理生态:
Kafka Connect
是Kafka与外部系统(数据库、键值存储、文件系统等)对接的数据集成框架,核心能力:
- 提供适用于常见系统的预制连接器,开箱即用;
- 提供自定义连接器开发框架,适配个性化集成需求;
- 包含两类核心连接器:源连接器(将外部数据导入Kafka)、下沉连接器(将Kafka数据导出到外部系统)。
Kafka Streams
是用于构建实时流处理应用的客户端库,核心能力:
- 对数据流进行实时的处理和转换;
- 支持聚合、关联、窗口计算等复杂操作;
- 可构建跨事件维护状态的有状态应用,满足复杂业务处理需求。
七、如何快速上手Kafka?
Kafka 提供三种上手方式,适配开发学习、本地部署、生产环境等不同场景,可按需选择:
7.1 Confluent Cloud(全托管服务)
- 无需管理基础设施,开箱即用;
- 注册即可获得400美元免费额度,可免费体验;
- 参考「Confluent Cloud Quick Start」获取分步操作指南,适合快速体验和生产环境轻量使用。
7.2 Confluent Platform(自托管)
- 可下载用于本地开发或生产部署;
- 包含Kafka及各类附加工具和功能,生态完善;
- 参考「Installation Overview」获取安装指南,适合企业级自托管部署。
7.3 开源Apache Kafka
- 从kafka.apache.org下载官方开源版本;
- 轻量简洁,适合开发学习和定制化二次开发;
- 配套教程和示例代码可参考Confluent文档的「Clients」章节。
八、后续学习建议
- 夯实基础:参考「Get Started with Kafka」完成实操教程,掌握Kafka基本使用;
- 探索客户端库:在「Clients」章节中,查找多语言的Kafka生产者/消费者客户端文档、教程及示例代码;
- 入门学习:观看「Kafka 101」系列视频,系统学习Kafka核心概念;
- 深度进阶:参考「Kafka Design Overview」,深入理解Kafka的设计理念和核心特性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)