沐曦GPU安装大模型
本文介绍了在沐曦GPU上部署AI模型的关键步骤:1.通过mx-smi命令检查GPU驱动版本,建议选择与驱动版本匹配的沐曦官方镜像;2.从沐曦官网获取最新Docker镜像并部署;3.参考官方教程启动容器和模型。模型兼容性需满足三个条件:沐曦适配模型(可通过魔塔社区查询)、vllm版本支持的模型架构(需核对vllm官网文档)、以及bfloat16精度支持。特别提醒需注意maca版本与GPU驱动的匹配问
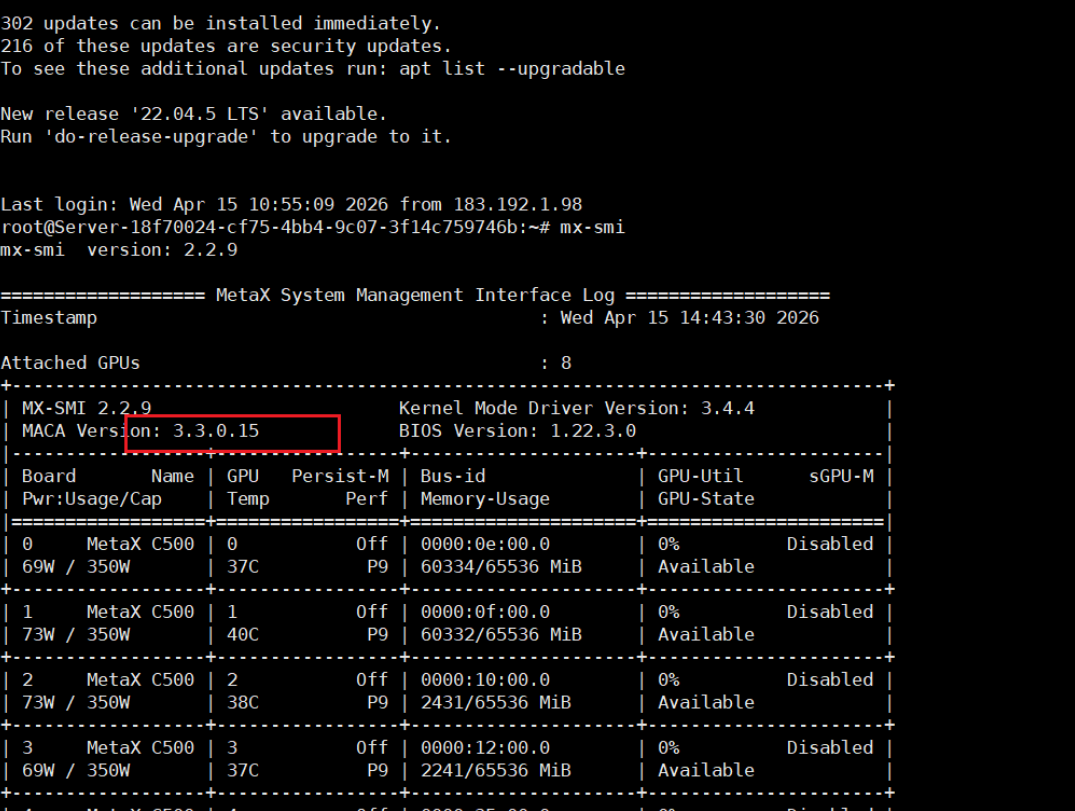
1.查看当前GPU对应的驱动版本号
命令为 mx-smi
2.去沐曦官方网站,找镜像
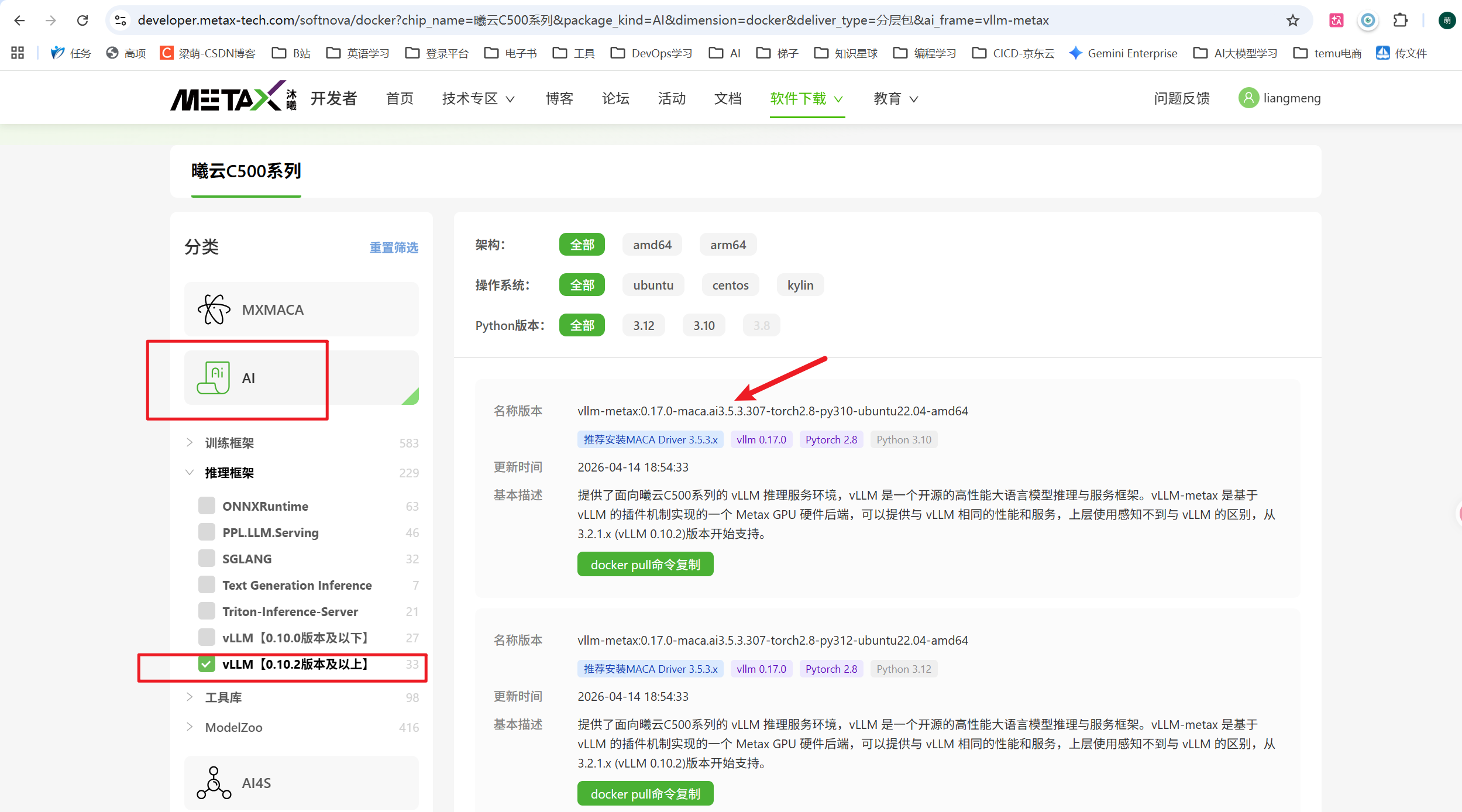
需要注意下镜像中的maca版本,跟服务器GPU的驱动版本尽量保持一致或相近。可以通过升级GPU驱动的方式,解决版本不一致问题。
3.一般情况,就找最新发布的镜像,点击 镜像复制命令
复制后,到自己服务器上执行,就会下载这个镜像。
4.下载和启动模型
参考沐曦提供的模型部署教程,启动容器,在容器内部下载和启动模型
https://developer.metax-tech.com/doc/242
哪些模型可以部署在沐曦GPU上?
1.魔塔社区中,沐曦做了适配的模型
https://www.modelscope.cn/organization/metax-tech?tab=model
2.vllm版本支持的模型架构
根据下载的镜像的vllm版本,在vllm官方网站中,看该模型的架构是否支持。
先看镜像的vllm版本
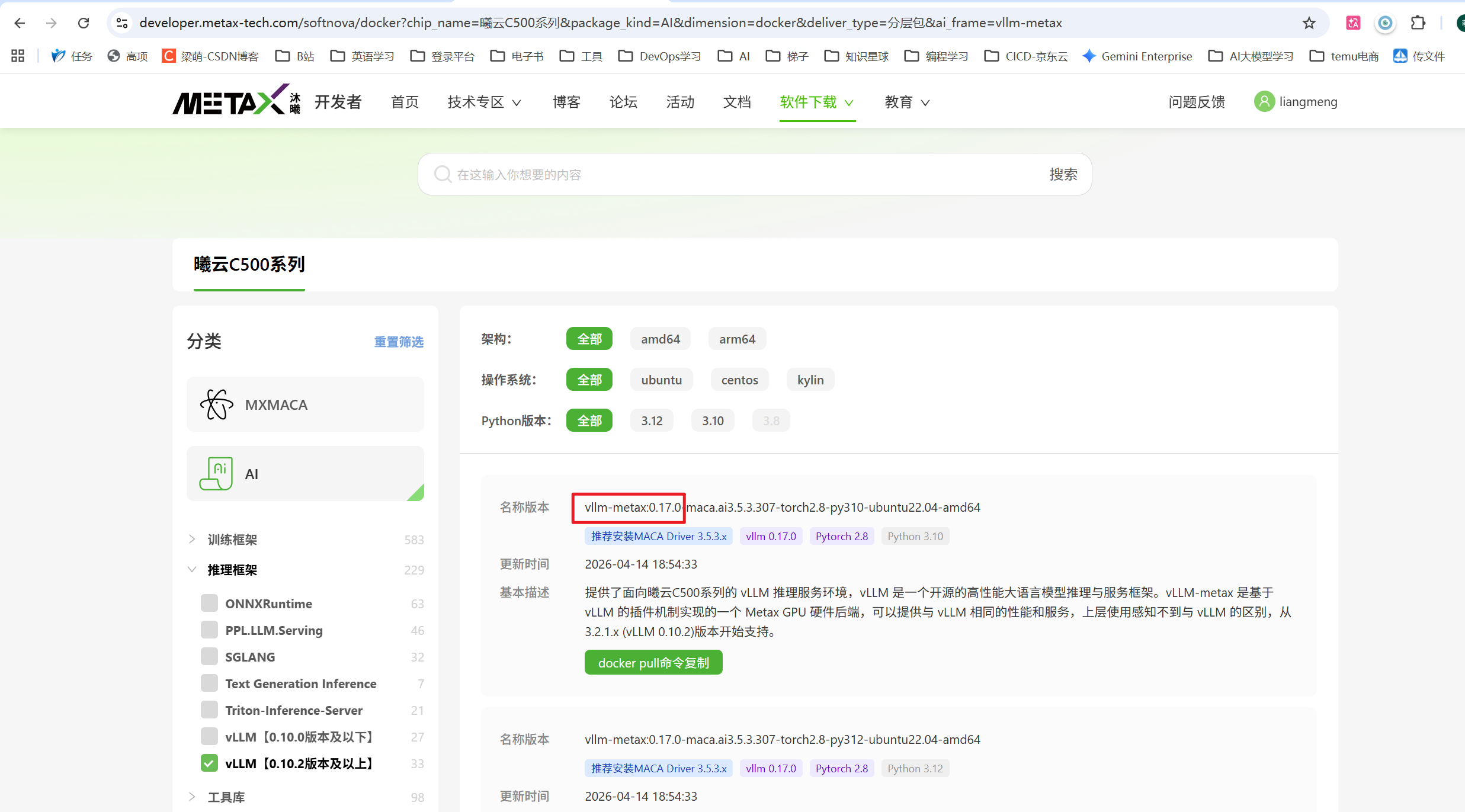
如上图,镜像的vllm版本是0.17
然后去vllm官网,看0.17版本支持哪些模型架构
https://docs.vllm.ai/en/v0.17.0/models/supported_models/#pooling-models
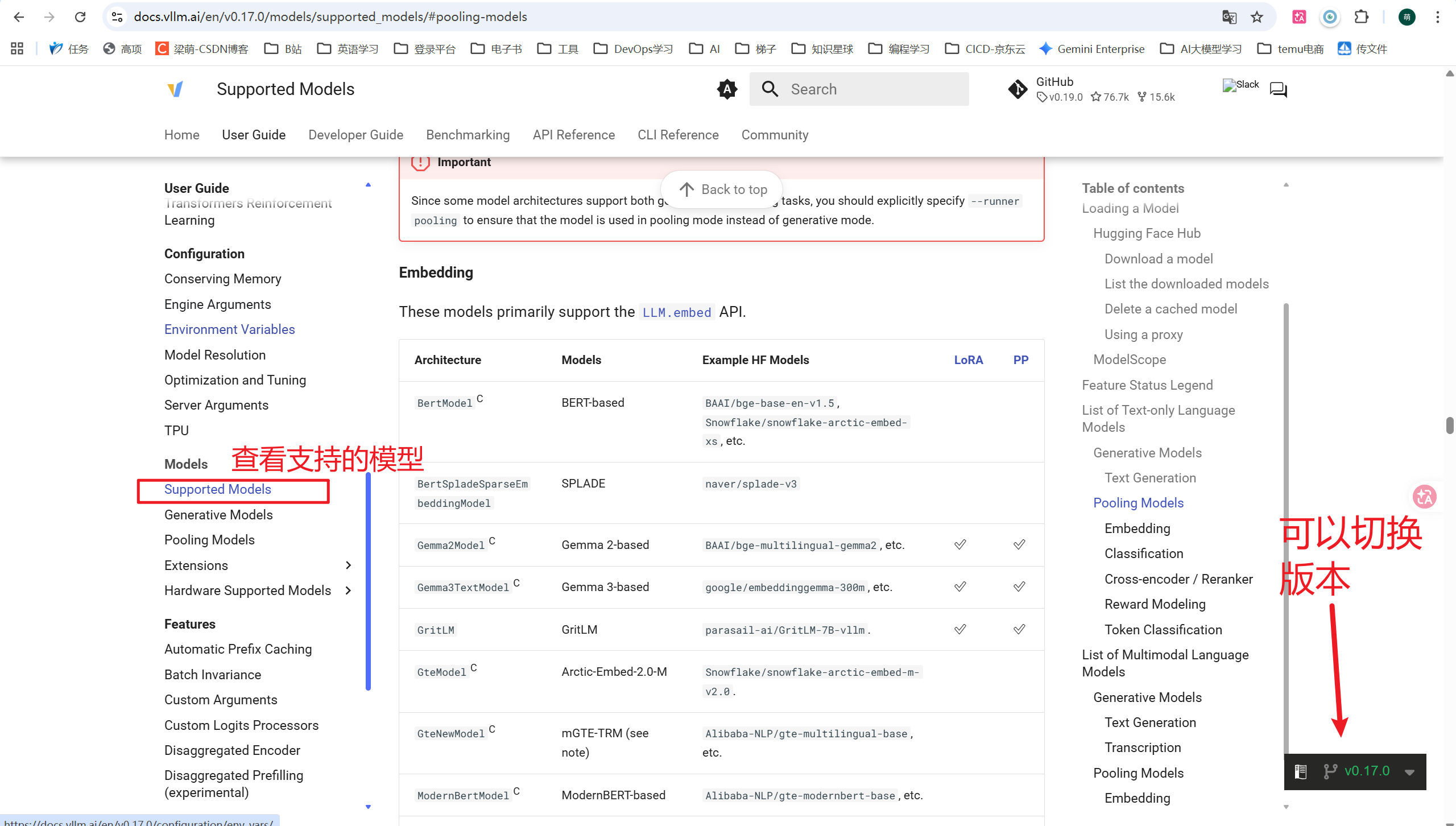
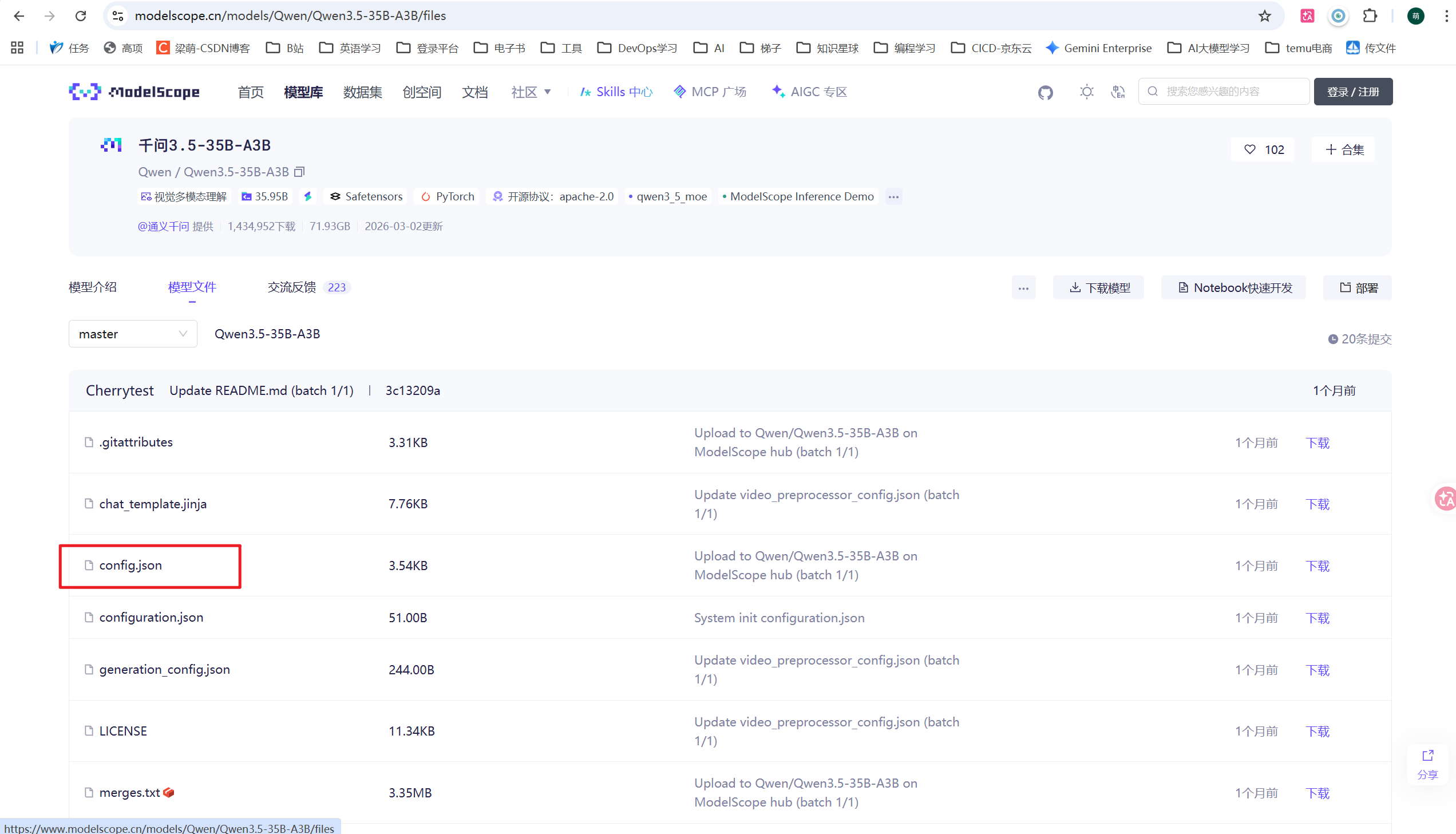
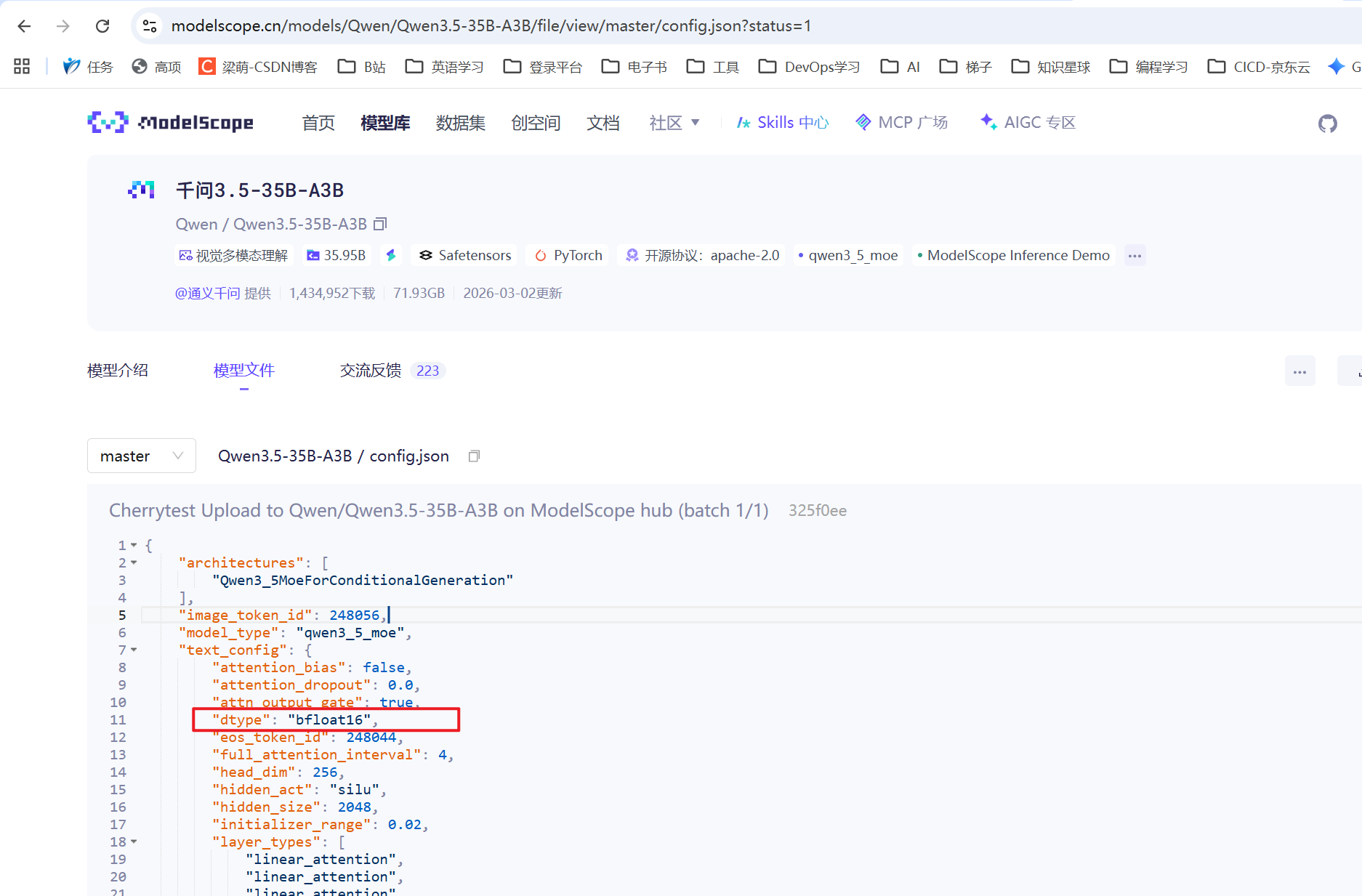
假如想安装某个模型,打开这个模型的配置文件,找到模型架构
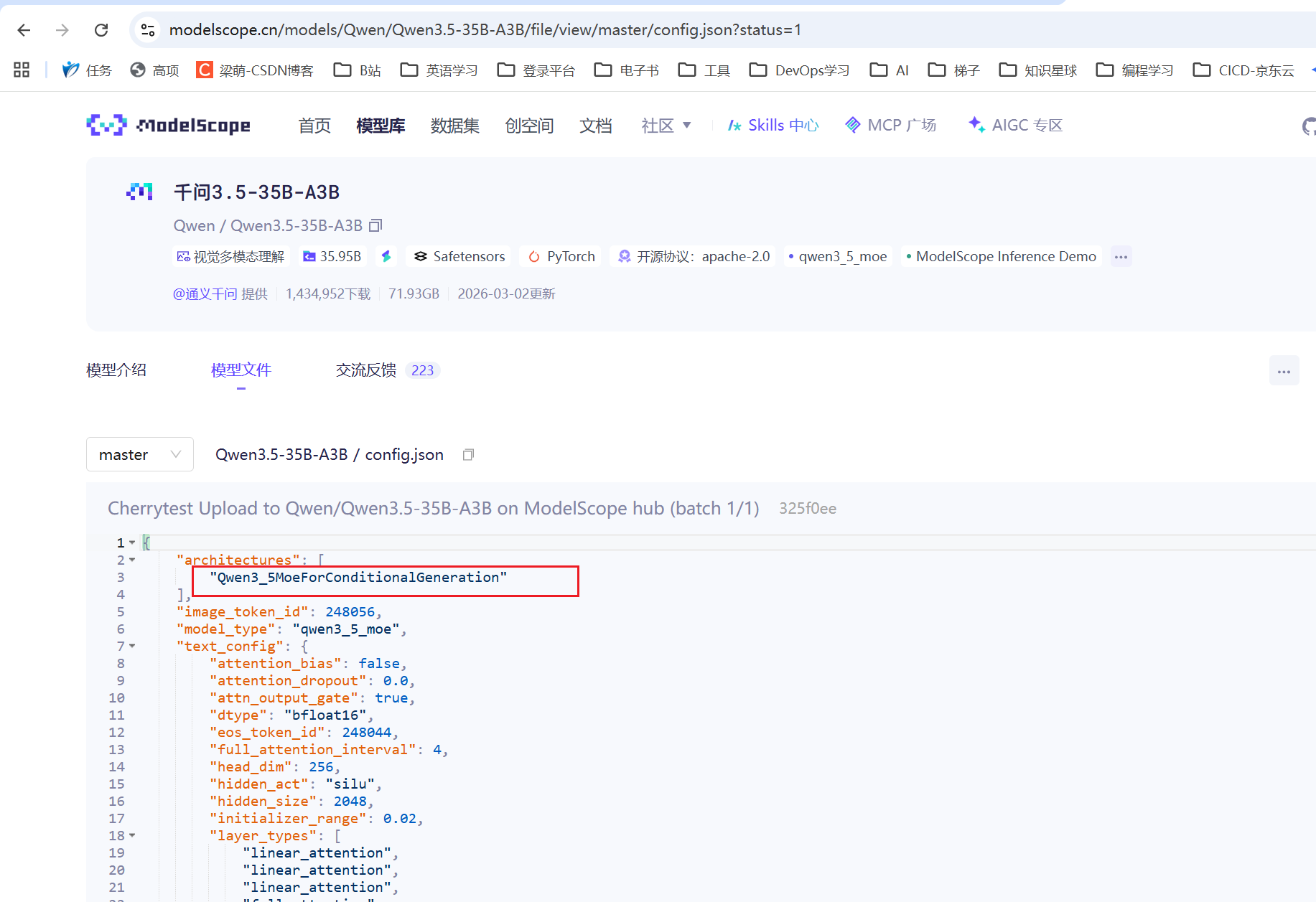
在vllm官网中,搜索该模型架构
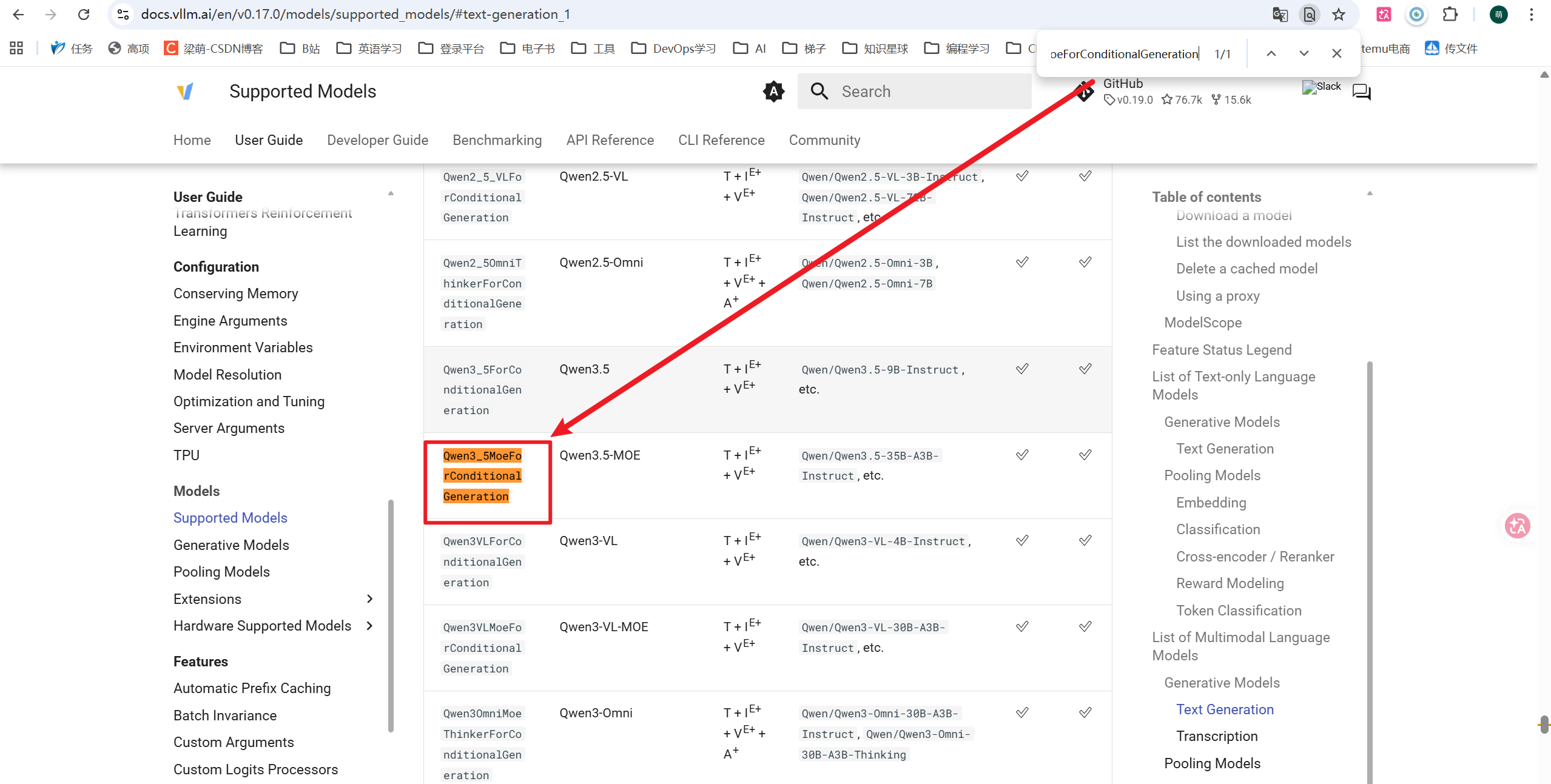
这就说明vllm 0.17版本,支持该模型架构,是可以安装的。
3.看模型精度是否支持bfloat16

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)