这个组合模型挺有意思的,咱们拆开看看怎么玩。先说核心思路:用粒子群算法给BiLSTM找最佳参数,再让注意力机制帮模型抓住重点特征。下面这段是参数优化的核心代码
PSO-BiLSTM-Attention基于粒子群算法优化双向长短期记忆神经网络结合SE注意力机制的多变量回归组合预测模型 Matlab语言 可直接运行 1.多变量单输出,也可替换为时间序列单列预测,粒子群算法也可替换为其他优化算法(如灰狼、蜣螂)。 Matlab版本最好在2020B及以上。 使用粒子群优化的参数为:学习率,隐藏层节点数 ,正则化参数。 评价指标包括:R2、MAE、RMSE和MAPE等,出图效果如图1所示,可完全满足您的需求 2.直接替换Excel数据即可用,注释清晰,适合新手小白 3.附赠示例数据,输入格式如图3所示(不同特征数量均可)运行main文件一键出图
function [best_params, convergence_curve] = PSO(Data)
% 粒子群参数设置
n_particles = 20; % 小样本测试用,正式可以调大
max_iter = 50;
dim = 3; % 优化学习率、隐藏节点数、正则化参数
% 参数范围设定
bounds = [0.001, 0.1; % 学习率范围
50, 200; % 隐藏节点数
0.0001, 0.01]; % 正则化系数
% 初始化粒子群
particles = struct('position',[],'velocity',[],'cost',[],'best',[]);
for i=1:n_particles
particles(i).position = bounds(:,1) + (bounds(:,2)-bounds(:,1)).*rand(dim,1);
particles(i).velocity = zeros(dim,1);
particles(i).cost = cost_function(particles(i).position, Data);
particles(i).best.position = particles(i).position;
particles(i).best.cost = particles(i).cost;
end
% 迭代优化过程
for iter=1:max_iter
for i=1:n_particles
% 更新速度和位置(这里简化了邻域最优计算)
inertia = 0.6;
cognitive = 1.4 * rand();
social = 1.4 * rand();
particles(i).velocity = inertia * particles(i).velocity + ...
cognitive * rand(dim,1).*(particles(i).best.position - particles(i).position) + ...
social * rand(dim,1).*(global_best.position - particles(i).position);
particles(i).position = particles(i).position + particles(i).velocity;
% 边界处理
particles(i).position = max(particles(i).position, bounds(:,1));
particles(i).position = min(particles(i).position, bounds(:,2));
% 评估新位置
current_cost = cost_function(particles(i).position, Data);
if current_cost < particles(i).best.cost
particles(i).best.position = particles(i).position;
particles(i).best.cost = current_cost;
end
end
% 记录收敛曲线
convergence_curve(iter) = global_best.cost;
end
end这段代码有几个注意点:粒子速度更新公式里的系数设置比较讲究,正式用的时候建议加上自适应调整。边界处理用到了矩阵运算,比逐元素判断更高效。实际运行时可以加个并行计算,把每个粒子的cost评估放到parfor里加速。
接下来看模型结构的关键部分,这里用到了双向LSTM和SE注意力:
function net = create_model(inputSize, numHiddenUnits, learningRate, regParam)
layers = [
sequenceInputLayer(inputSize)
bilstmLayer(numHiddenUnits,'OutputMode','sequence')
squeezeLayer % 自定义层处理维度
% SE注意力模块
functionLayer(@(X) se_block(X), 'Formattable', true)
fullyConnectedLayer(64)
reluLayer
fullyConnectedLayer(1)
regressionLayer
];
options = trainingOptions('adam', ...
'LearnRate', learningRate, ...
'L2Regularization', regParam, ...
'MaxEpochs', 200, ...
'Plots', 'none');
net = trainNetwork(XTrain, YTrain, layers, options);
end
% SE注意力实现
function Y = se_block(X)
[h, w, c] = size(X);
squeeze = mean(X, [1 2]); % 全局平均池化
excitation = fullyconnect(squeeze, c/4, 'WeightsInitializer','he')...
relu...
fullyconnect(c, 'WeightsInitializer','he')...
sigmoid;
Y = X .* reshape(excitation,1,1,c);
end这个SE模块的实现用了函数层,好处是不用自定义层类。注意通道压缩比例设为4,这个参数对计算量影响挺大。双向LSTM的输出模式要用sequence才能保留时间维度信息,后面接的squeeze层是为了去掉多余的维度。
PSO-BiLSTM-Attention基于粒子群算法优化双向长短期记忆神经网络结合SE注意力机制的多变量回归组合预测模型 Matlab语言 可直接运行 1.多变量单输出,也可替换为时间序列单列预测,粒子群算法也可替换为其他优化算法(如灰狼、蜣螂)。 Matlab版本最好在2020B及以上。 使用粒子群优化的参数为:学习率,隐藏层节点数 ,正则化参数。 评价指标包括:R2、MAE、RMSE和MAPE等,出图效果如图1所示,可完全满足您的需求 2.直接替换Excel数据即可用,注释清晰,适合新手小白 3.附赠示例数据,输入格式如图3所示(不同特征数量均可)运行main文件一键出图
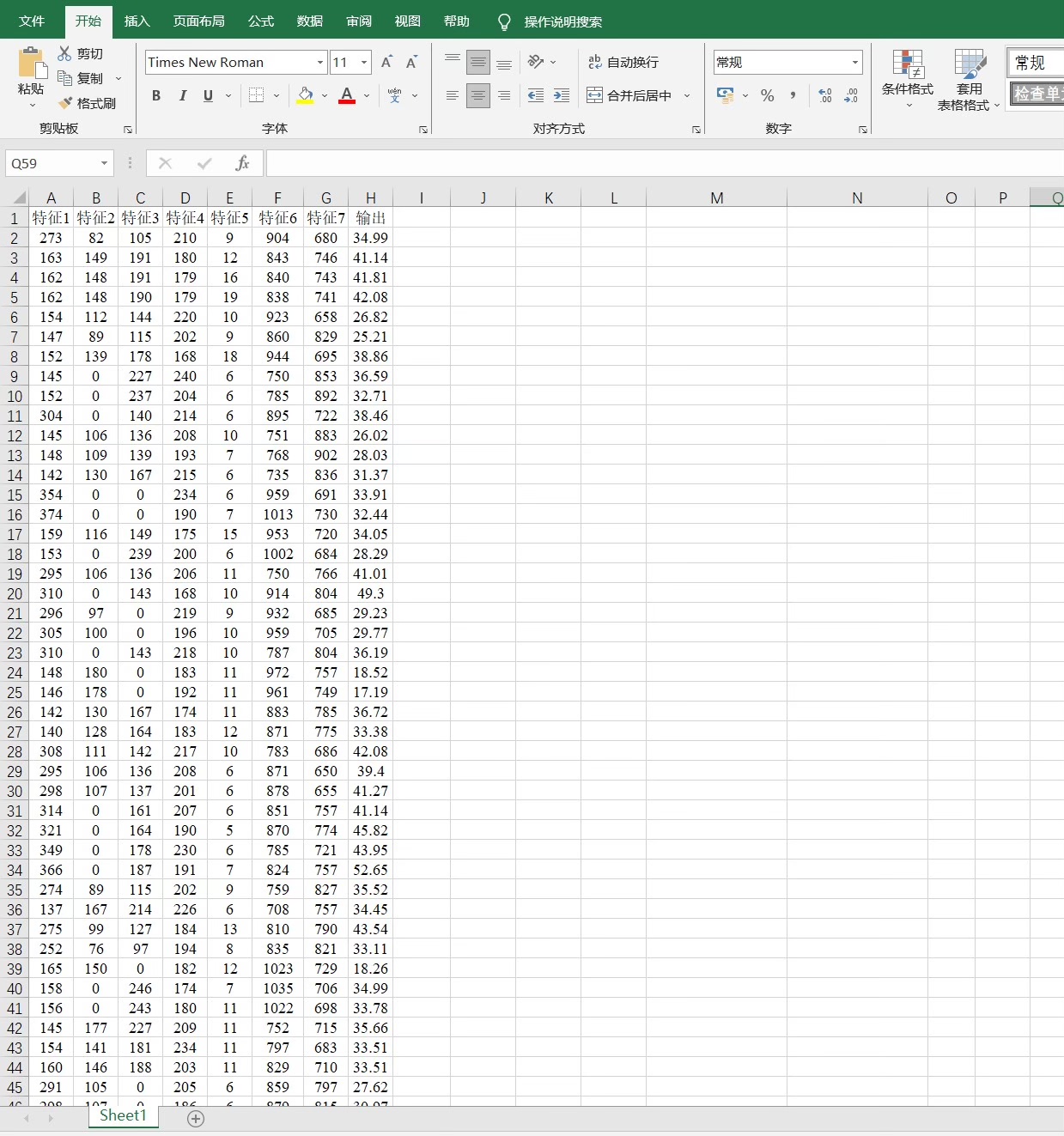
新手使用时最容易出错的地方是数据预处理,这里给出标准化的正确姿势:
% 数据预处理
data = readmatrix('your_data.xlsx');
[~, ~, data_norm] = normalize(data); % 2020b新增的语法
% 滑动窗口构造时序样本
lookback = 12; % 根据数据周期调整
[XTrain, YTrain] = create_dataset(data_norm, lookback);
% 数据集拆分
train_ratio = 0.8;
split_idx = floor(size(XTrain,1)*train_ratio);
XVal = XTrain(split_idx+1:end,:);
YVal = YTrain(split_idx+1:end);
XTrain = XTrain(1:split_idx,:);
YTrain = YTrain(1:split_idx);滑动窗口的实现要注意别把未来数据泄露到输入里。数据标准化一定要用训练集统计量来处理验证/测试集,这个坑很多人踩过。
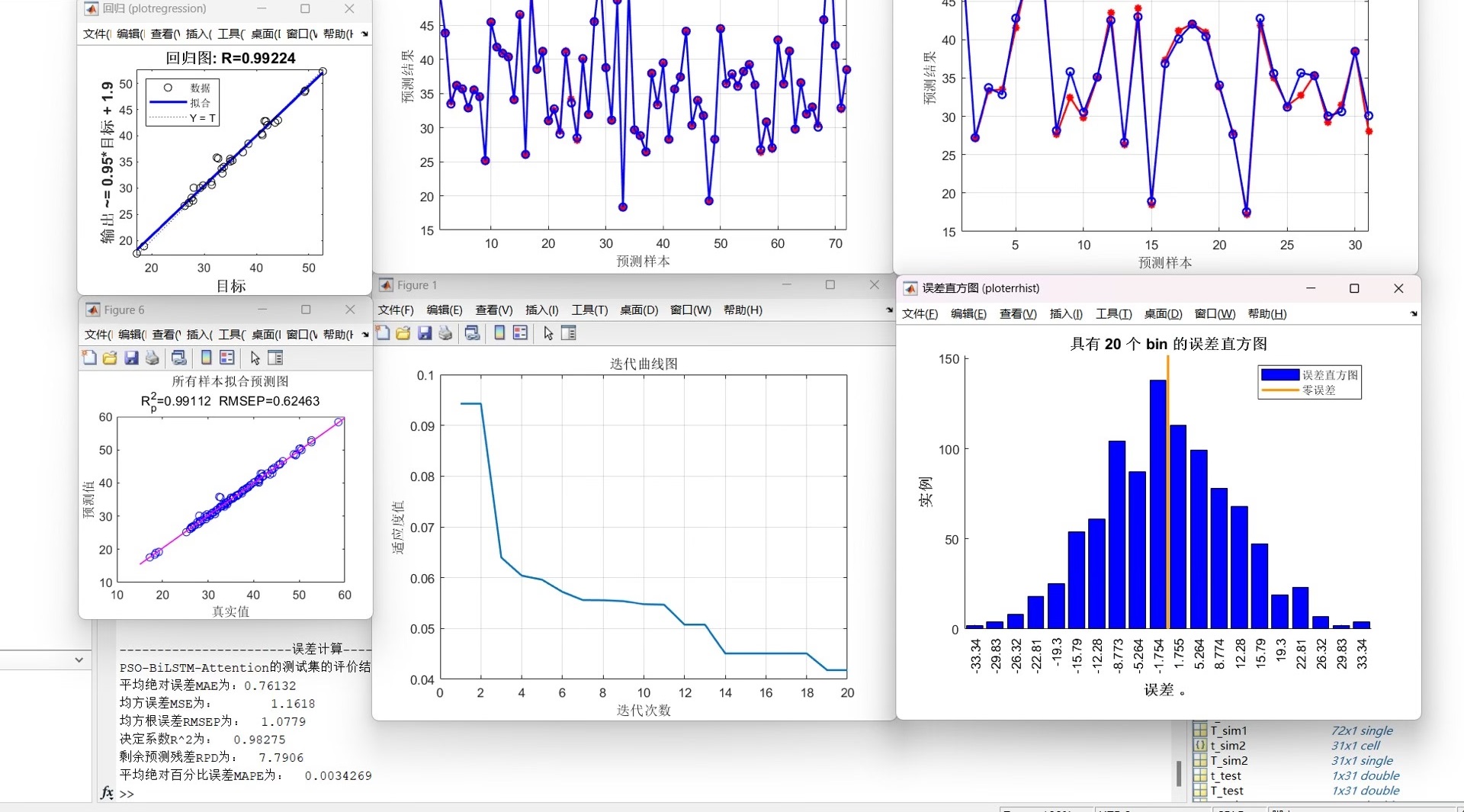
最后是结果可视化部分,可以这样展示预测效果:
% 预测结果反标准化
pred = predict(net, XTest);
pred = pred * data_std(end) + data_mean(end); % 假设目标在最后一列
% 绘制对比曲线
figure('Position',[200,200,800,400])
plot(YTest, 'LineWidth',1.5)
hold on
plot(pred, '--')
legend('真实值','预测值')
title(['R2=',num2str(r2_score),' MAPE=',num2str(mape_score)])
xlabel('时间步')
ylabel('目标值')
grid on
% 附加注意力权重可视化
attention_weights = get_attention_weights(net, XTest);
figure
imagesc(attention_weights)
title('特征注意力热力图')
xlabel('时间步')
ylabel('特征维度')
colorbar画图时建议用真实的日期标签代替时间步,如果数据有时间戳的话。注意力热力图的解读要注意,颜色深浅代表特征在不同时间步的重要性,可以辅助分析模型关注点。
整套代码跑起来大概需要5-15分钟(取决于数据量和粒子数),记得在运行前检查:
- Excel数据是否第一列是时间戳(可选)
- 特征列是否连续无缺失
- 输出目标是否在最后一列
- Matlab有没有安装Deep Learning Toolbox
遇到报错先看这几点,基本上新手都能跑起来。想替换其他优化算法的话,把PSO函数换成GWO或者蜣螂算法的实现就行,注意保持参数传递接口一致。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)