车牌检测还手动裁?基于 YOLOv8 的车牌位置检测与裁剪
车牌检测还手动裁?基于 YOLOv8 的车牌位置检测与裁剪
代码详见:https://github.com/xiaozhou-alt/Car_Plate_Recognition
一、项目介绍
本项目是一套 端到端的中国车牌识别解决方案,通过 “车牌位置检测 + 车牌内容识别” 两阶段流程,实现从原始车辆图片到车牌号码的自动化识别。
本文为项目介绍的第一篇文章,实现车牌位置检测和裁剪的算法说明。
核心功能:基于 YOLOv8 模型,实现复杂场景下的车牌定位,支持倾斜车牌矫正(通过顶点坐标透视变换 + 边界框旋转矫正)
如果您喜欢本文,有兴趣继续关注本项目,请查看第二篇文章:测测你的牌:基于 MobileNetV2 的车牌内容检测
二、文件夹结构
Car_Plate_Recognition/
├── README.md
├── demo.mp4 # 演示视频文件
├── demo.py # 主程序文件,包含GUI界面
├── predict.py # 车牌识别预测脚本
├── preprocess.py # 数据预处理脚本
├── requirements.txt
├── train_location.py # 车辆位置检测训练脚本
├── train_plate.py # 车牌识别训练脚本
├── data/
├── plate_data.yaml # 数据配置文件
├── plate_info.csv # 车牌信息表(含图片名、车牌号、顶点坐标)
├── images/
├── train/ # 训练集图片(.jpg/.jpeg/.png)
└── val/ # 验证集图片(.jpg/.jpeg/.png)
└── labels/ # YOLO格式标签文件(与图片同名,.txt格式)
├── train/
└── val/
├── log/ # 日志目录
├── output/
├── model/ # 模型文件目录
├── pic/ # 图片输出目录
├── recognition-output/ # 识别输出目录
└── training_history_mobilenet.json # MobileNet训练历史数据
└── yolo_train-output/ # YOLO训练输出目录
├── license_plate_detection/ # 车牌检测相关文件
├── runs/ # 训练运行记录
└── test_samples_output/ # 测试样本输出
└── test/ # 测试图片目录
三、数据集介绍
数据源于:CCPD2019|车牌识别数据集|计算机视觉数据集
数据集或可由:ccpd-preprocess
经我处理完毕的(使用ccpd原数据集中base下的 20 % 20\% 20% 部分,经过裁剪处理,可以直接训练识别):Plate_Recognition
1. 数据集结构
需按照以下目录结构组织数据集,核心包含图片文件、标签文件、配置文件、车牌信息表四部分:
data/
├── plate_data.yaml # 数据配置文件
├── plate_info.csv # 车牌信息表(含图片名、车牌号、顶点坐标)
├── images/
├── train/ # 训练集图片(.jpg/.jpeg/.png)
└── val/ # 验证集图片(.jpg/.jpeg/.png)
└── labels/ # YOLO格式标签文件(与图片同名,.txt格式)
├── train/
└── val/
2. 关键文件说明
(1)plate_data.yaml
用于配置数据集路径、类别信息,格式如下:
train: ./images/train # 训练集图片路径(相对/绝对路径均可)
val: ./images/val # 验证集图片路径
nc: 1 # 类别数量(仅车牌1类)
names: [license_plate] # 类别名称(需与代码中class_name一致)
(2)plate_info.csv
记录每张图片的车牌关键信息,字段说明:
| 字段名 | 类型 | 说明 |
|---|---|---|
| image_name | 字符串 | 图片文件名(需与 images 文件夹中文件完全一致,含后缀) |
| plate_number | 字符串 | 真实车牌号码(中国车牌 7 位,如 “京 A12345”) |
| vertices | 字符串 | 车牌四个顶点坐标(格式:[[x1,y1],[x2,y2],[x3,y3],[x4,y4]]),用于倾斜矫正 |
(3)YOLO 标签文件(labels 目录下)
每个图片对应一个.txt标签文件,格式遵循 YOLO 标准:
# 格式:[类别索引] [中心x/宽] [中心y/高] [宽/图宽] [高/图高]
0 0.523 0.345 0.120 0.085
-
类别索引:固定为 0(仅车牌一类)
-
坐标:归一化坐标(取值 0-1)
3. 数据要求
-
图片分辨率:建议不低于 640×480(与模型输入尺寸 640 适配)
-
车牌角度:支持 ±30° 倾斜(内置矫正逻辑)
训练完毕的模型下载:rexinshiminxiaozhou | Car_Plate_Recognition | Kaggle
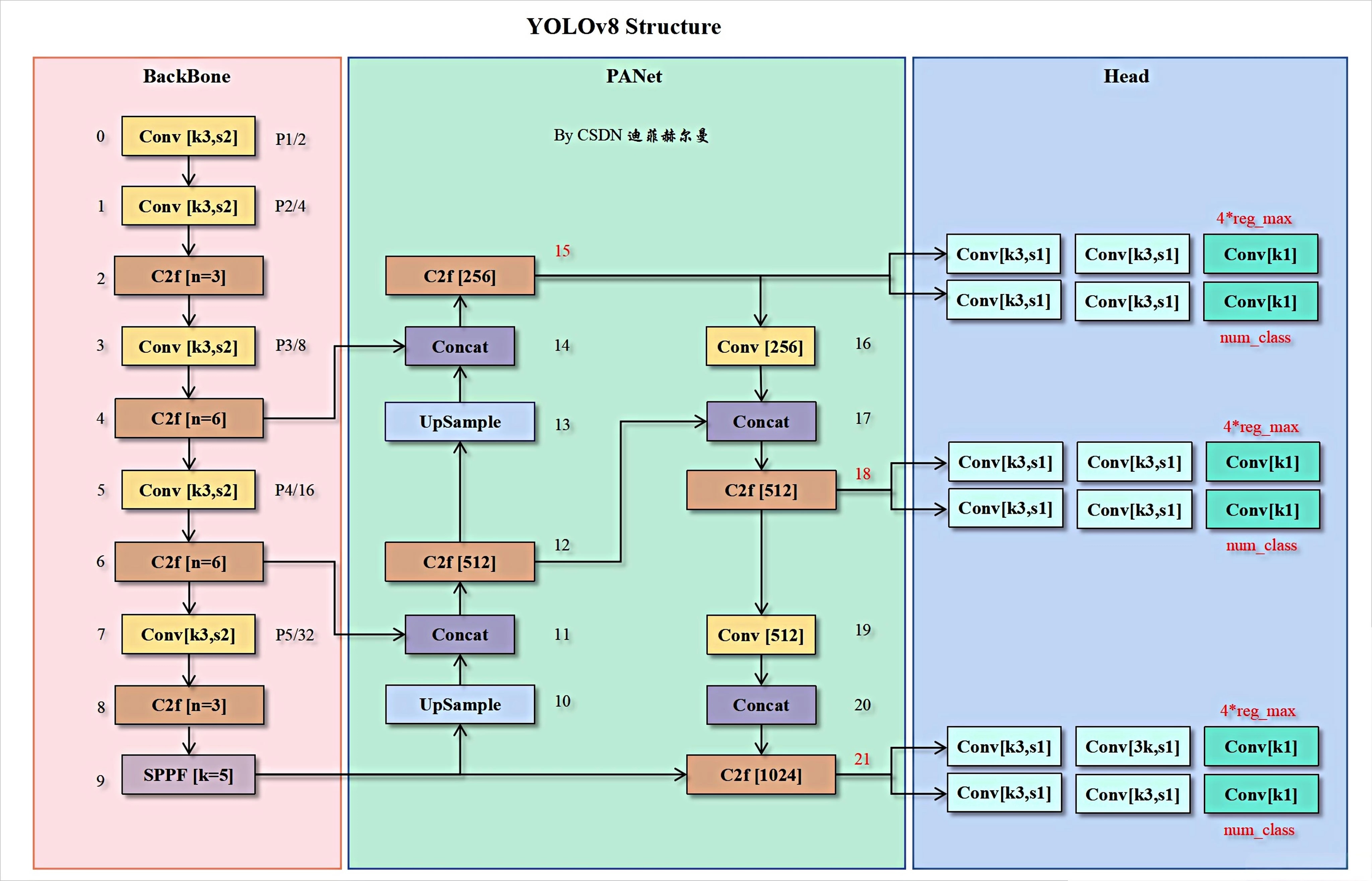
四、YOLOv8 算法介绍
YOLOv8 作为单阶段目标检测模型的主流方案,采用输入端-主干网络-颈部网络-检测头的端到端架构,核心优势在于兼顾检测速度与精度。
1. 输入端:自适应预处理与数据增强
YOLOv8 输入端核心优化在于自适应预处理与高效数据增强策略,降低人工配置成本的同时提升模型泛化能力。数据增强采用 Mosaic 增强(随机拼接 4 4 4 张图像),通过随机缩放、裁剪、翻转实现样本多样性扩充,其核心是图像像素的坐标映射变换,对于 任意输入图像 ∈ R H × W × 3 \in \mathbb{R}^{H \times W \times 3} ∈RH×W×3,拼接后的图像 I mosaic I_{\text{mosaic}} Imosaic 满足:
I mosaic ( x , y , c ) = { I 1 ( x , y , c ) ( x ∈ [ 0 , W 1 ) , y ∈ [ 0 , H 1 ) ) I 2 ( x − W 1 , y , c ) ( x ∈ [ W 1 , W 1 + W 2 ) , y ∈ [ 0 , H 2 ) ) I 3 ( x , y − H 1 , c ) ( x ∈ [ 0 , W 3 ) , y ∈ [ H 1 , H 1 + H 3 ) ) I 4 ( x − W 3 , y − H 1 , c ) ( x ∈ [ W 3 , W 3 + W 4 ) , y ∈ [ H 1 , H 1 + H 4 ) ) I_{\text{mosaic}}(x,y,c) = \begin{cases} I_1(x,y,c) & (x \in [0,W_1), y \in [0,H_1)) \\ I_2(x-W_1,y,c) & (x \in [W_1,W_1+W_2), y \in [0,H_2)) \\ I_3(x,y-H_1,c) & (x \in [0,W_3), y \in [H_1,H_1+H_3)) \\ I_4(x-W_3,y-H_1,c) & (x \in [W_3,W_3+W_4), y \in [H_1,H_1+H_4)) \end{cases} Imosaic(x,y,c)=⎩ ⎨ ⎧I1(x,y,c)I2(x−W1,y,c)I3(x,y−H1,c)I4(x−W3,y−H1,c)(x∈[0,W1),y∈[0,H1))(x∈[W1,W1+W2),y∈[0,H2))(x∈[0,W3),y∈[H1,H1+H3))(x∈[W3,W3+W4),y∈[H1,H1+H4))
其中 ( W i , H i ) (W_i,H_i) (Wi,Hi) 为第 i i i 张图像拼接后的宽高, c c c 为通道维度( R G B RGB RGB)。预处理阶段采用自适应锚框计算与自适应图片缩放:锚框通过 K − m e a n s K-means K−means 算法对训练集目标框聚类得到,满足 IOU ( a n c h o r , t a r g e t ) ≥ 0.5 \text{IOU}(anchor, target) \geq 0.5 IOU(anchor,target)≥0.5 的约束;图片缩放则根据目标尺寸自动调整为模型输入尺寸(本项目为 640 × 640 640×640 640×640),避免冗余黑边填充。
🤓🤓🤓小周有话说:
把输入端的工作想象成 “给模型准备多样化的训练素材并整理规整”。
比如在车牌检测项目中,Mosaic 增强 就像把 4 4 4 张不同场景(晴天、雨天、傍晚)、不同角度(正面、倾斜、侧方)的车牌图像随机“拼拼图”:可能左边是一张正面清晰的蓝牌,右上角是一张倾斜的黄牌,右下角是一张被遮挡一半的白牌。这样做能让模型见多识广,后续遇到复杂场景的车牌时不会“认不出”。
自适应锚框 就像给模型准备了几套 “定制尺寸的框子模板”,因为车牌尺寸相对固定(约 4 : 1 4:1 4:1 比例),模型不用再盲目尝试各种大小的框,直接用匹配车牌尺寸的模板去定位,效率和精度都更高;自适应缩放则是把不同大小的原始图像(比如有的图是 1080 × 1920 1080×1920 1080×1920,有的是 720 × 1280 720×1280 720×1280)统一调整成 640 × 640 640×640 640×640 的标准,让模型能稳定处理。
2. 主干网络:C2f 模块与特征提取
YOLOv8 主干网络以 C2f 模块为核心,替换了 YOLOv5 的 C3 模块,增强了特征融合能力。C2f 模块基于 Bottleneck 残差结构,通过分流操作将输入特征图分为两部分,一部分直接进行恒等映射,另一部分经过多层卷积与激活函数处理后与恒等映射部分拼接融合,其特征融合过程可表示为:
F out = Concat ( F direct , Bottleneck ( F split ) ) F_{\text{out}} = \text{Concat}(F_{\text{direct}}, \text{Bottleneck}(F_{\text{split}})) Fout=Concat(Fdirect,Bottleneck(Fsplit))
其中 F direct F_{\text{direct}} Fdirect 为直接分流的特征图, F split F_{\text{split}} Fsplit 为进入 Bottleneck 处理的特征图,$\text{Bottleneck}$ 包含 1 × 1 1×1 1×1 卷积(降维)、 3 × 3 3×3 3×3 卷积(特征提取)和 S i L U SiLU SiLU 激活函数 σ ( x ) = x ⋅ sigmoid ( x ) \sigma(x) = x \cdot \text{sigmoid}(x) σ(x)=x⋅sigmoid(x)。主干网络最后通过 S P P F SPPF SPPF(空间金字塔池化)模块,对输入特征图进行 1 × 1 1×1 1×1、 5 × 5 5×5 5×5、 9 × 9 9×9 9×9、 13 × 13 13×13 13×13 尺度的池化操作,再拼接融合,实现多尺度特征聚合,公式为:
F SPPF = Concat ( MaxPool ( F i n , k ) ∣ k ∈ { 1 , 5 , 9 , 13 } ) F_{\text{SPPF}} = \text{Concat}(\text{MaxPool}(F_{in}, k) \mid k \in \{1,5,9,13\}) FSPPF=Concat(MaxPool(Fin,k)∣k∈{1,5,9,13})
🤓🤓🤓小周有话说:
主干网络就像 “模型的眼睛和大脑初级处理中心”,负责从图像中提取关键特征。
在车牌检测中,当一张包含车牌的图像输入后,C2f 模块 先把图像特征分成两拨:一拨直接保留原始基础特征(比如图像的明暗、边缘轮廓),另一拨则进行“深度加工”——先压缩特征维度( 1 × 1 1×1 1×1 卷积)减少计算量,再细致提取车牌的纹理特征(比如车牌上的字符边缘、蓝底白字的颜色对比, 3 × 3 3×3 3×3 卷积),最后把两拨特征合并,既保留了基础信息,又强化了关键特征。
SPPF 模块 则像 “用不同倍数的放大镜看车牌”: 1 × 1 1×1 1×1 的放大镜看整体轮廓, 5 × 5 5×5 5×5 的看车牌区域细节, 9 × 9 9×9 9×9 和 13 × 13 13×13 13×13 的看更大范围的上下文(比如车牌周围的车身、背景),把这些不同角度看到的信息整合起来,让模型能更全面地认识“什么是车牌”。
3. 颈部网络:PAN-FPN 特征融合
YOLOv8 颈部网络采用 PAN-FPN 结构,实现上下采样与跨尺度特征融合,解决目标检测中 “小目标难检测” 的问题。FPN(特征金字塔网络)部分 采用自上而下的上采样,将主干网络输出的深层高语义特征(大尺度,低分辨率)通过 2 × 2 2×2 2×2 上采样与浅层低语义特征(小尺度,高分辨率)拼接融合;PAN(路径聚合网络)部分 则采用自下而上的下采样,将浅层高分辨率特征传递至深层,补充位置信息。特征融合过程中,对不同尺度的特征图先通过 1 × 1 1×1 1×1 卷积统一通道数,再进行逐元素相加或拼接,公式为:
F fusion = Concat ( Conv1×1 ( F deep ↑ 2 ) , Conv1×1 ( F shallow ) ) F_{\text{fusion}} = \text{Concat}(\text{Conv1×1}(F_{\text{deep}} \uparrow 2), \text{Conv1×1}(F_{\text{shallow}})) Ffusion=Concat(Conv1×1(Fdeep↑2),Conv1×1(Fshallow))
其中 F deep ↑ 2 F_{\text{deep}} \uparrow 2 Fdeep↑2 表示对深层特征进行 2 2 2 倍上采样。通过 P A N − F P N PAN-FPN PAN−FPN 融合后,颈部网络输出 3 3 3 个不同尺度的特征图(本项目为 80 × 80 80×80 80×80、 40 × 40 40×40 40×40、 20 × 20 20×20 20×20),分别对应检测小、中、大尺寸的目标。
🤓🤓🤓小周有话说:
颈部网络 就像 “模型的信息中转站”,负责把主干网络提取的不同层次特征整合优化,让模型能精准定位不同大小、不同位置的车牌。
比如在一张图像中,既有近距离拍摄的大尺寸车牌(占图像比例大),也有远距离拍摄的小尺寸车牌(占图像比例小):
FPN 部分 先把深层的 “车牌语义特征”(比如模型已经判断出“这是车牌”的抽象信息)放大,和浅层的“车牌位置特征”(比如车牌在图像左上角的具体坐标信息)结合,让模型知道“这个位置有个车牌”;
PAN 部分 则反过来,把浅层的精准位置信息传递到深层,帮模型修正大尺寸车牌的定位偏差。
最终输出的三个尺度特征图,就像三个“检测分工小组”:大尺度特征图(80×80)负责找小车牌,中尺度(40×40)找中等大小车牌,小尺度(20×20)找大车牌,确保不管车牌大小,都能被精准检测到。
4. 检测头:Decoupled Head 与 Anchor-Free 检测
YOLOv8 采用 Decoupled Head(解耦检测头)设计,将目标分类任务与边界框回归任务分离,避免两者相互干扰。检测头包含两个并行分支:分类分支输出目标属于各类别的概率,回归分支输出目标边界框的坐标偏移量与目标置信度。与 YOLOv5 的 Anchor-Based 不同,YOLOv8 采用 Anchor-Free 策略,直接预测目标中心坐标 ( x c , y c ) (x_c, y_c) (xc,yc)、宽高 ( w , h ) (w, h) (w,h) 以及偏移量,边界框预测公式为:
x c = ( x pred ⋅ 2 − 0.5 + x grid ) ⋅ s y c = ( y pred ⋅ 2 − 0.5 + y grid ) ⋅ s w = ( w pred ⋅ 2 ) 2 ⋅ w anchor h = ( h pred ⋅ 2 ) 2 ⋅ h anchor x_c = (x_{\text{pred}} \cdot 2 - 0.5 + x_{\text{grid}}) \cdot s \\ y_c = (y_{\text{pred}} \cdot 2 - 0.5 + y_{\text{grid}}) \cdot s \\ w = (w_{\text{pred}} \cdot 2)^2 \cdot w_{\text{anchor}} \\ h = (h_{\text{pred}} \cdot 2)^2 \cdot h_{\text{anchor}} xc=(xpred⋅2−0.5+xgrid)⋅syc=(ypred⋅2−0.5+ygrid)⋅sw=(wpred⋅2)2⋅wanchorh=(hpred⋅2)2⋅hanchor
其中 ( x pred , y pred , w pred , h pred ) (x_{\text{pred}}, y_{\text{pred}}, w_{\text{pred}}, h_{\text{pred}}) (xpred,ypred,wpred,hpred) 为模型预测值, ( x grid , y grid ) (x_{\text{grid}}, y_{\text{grid}}) (xgrid,ygrid) 为特征图网格坐标, s s s 为特征图下采样率, ( w anchor , h anchor ) (w_{\text{anchor}}, h_{\text{anchor}}) (wanchor,hanchor) 为预定义锚框尺寸。损失函数采用 C I o U CIoU CIoU 损失(Complete Intersection over Union),综合考虑边界框的重叠度、中心点距离和宽高比,公式为:
CIoU = 1 − IoU + ρ 2 ( b , b gt ) c 2 + α v \text{CIoU} = 1 - \text{IoU} + \frac{\rho^2(b, b_{\text{gt}})}{c^2} + \alpha v CIoU=1−IoU+c2ρ2(b,bgt)+αv
其中 IoU \text{IoU} IoU 为预测框与真实框的交并比, ρ ( b , b gt ) \rho(b, b_{\text{gt}}) ρ(b,bgt) 为两框中心点欧氏距离, c c c 为两框最小外接矩形对角线长度, α \alpha α 为权重系数, v v v 为宽高比一致性参数。
🤓🤓🤓小周有话说:
检测头 就像 “模型的最终判断终端”,负责给图像中的目标“下结论”:这是不是车牌,以及车牌在哪个位置。解耦检测头相当于安排了两个“专人”:
一个专人(分类分支)只负责判断 “这个区域是不是车牌”,给出确定度(比如99%是车牌,1%是其他);另一个专人(回归分支)只负责测量 “车牌的位置和大小”,比如车牌左上角在(100,200),右下角在(500,300)。
Anchor-Free 策略 就像 “不用固定模板找目标”:以前的 Anchor-Based 是拿着几套固定尺寸的框子去套,套中了才判断;现在则是直接“画框”,不管车牌大小形状,直接预测出最贴合车牌的框子,更灵活,尤其适合车牌可能存在轻微变形的场景(比如倾斜、轻微褶皱)。
CIoU 损失 则像“严格的评分老师”,不仅看模型画的框和真实车牌的重叠程度,还看框的中心点是不是对准了,宽高比例是不是符合车牌的 4 : 1 4:1 4:1 标准,只有这些都达标,才会给高分,督促模型不断优化框的精度。
五、项目实现
1.模块导入:依赖库加载
import os
import cv2
import time
import numpy as np
import pandas as pd
import random
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
from matplotlib.font_manager import FontProperties
import yaml
from ultralytics import YOLO
import torch
import matplotlib.font_manager as fm
import requests
from pathlib import Path
导入代码运行所需的全量依赖库,按功能可分为5类:
-
系统与路径操作:os、Path(用于创建目录、处理文件路径);
-
计算机视觉处理:cv2(图像读取、裁剪、矫正等核心视觉操作)、numpy(数值计算,支撑图像矩阵运算);
-
数据处理:pandas(读取车牌信息 CSV 文件)、yaml(解析数据配置文件);
-
深度学习框架:torch(设备调度,判断 CPU/GPU)、ultralytics.YOLO(加载 YOLOv8 模型,执行训练/检测);
-
可视化与辅助:matplotlib系列(绘制检测结果图)、time(生成时间戳)、random(随机选取测试样本)、requests(下载中文字体)。
2. 核心类定义:LicensePlateTrainer(车牌检测训练器)
该类封装了模型训练、加载、评估、检测裁剪、结果可视化的全流程,核心是通过YOLOv8实现车牌目标检测的端到端开发。
2.1 初始化方法:init
def __init__(self, data_config, model_name='yolov8m.pt', img_size=640, batch_size=16, epochs=50, class_name='license_plate'):
"""初始化训练器"""
self.data_config = data_config
self.img_size = img_size
self.batch_size = batch_size
self.epochs = epochs
self.class_name = class_name
# 保存中文字体属性
self.chinese_font = chinese_font
# 创建输出目录用于保存测试样本图片
self.output_dir = "test_samples_output"
os.makedirs(self.output_dir, exist_ok=True)
print(f"测试样本图片将保存至: {os.path.abspath(self.output_dir)}")
self.device = '0' if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {'GPU' if self.device == '0' else 'CPU'}")
self.model = YOLO(model_name)
with open(data_config, 'r') as f:
self.data_info = yaml.safe_load(f)
if 'names' not in self.data_info:
print(f"警告: 数据配置文件中未找到 'names' 定义")
else:
names = self.data_info['names']
if isinstance(names, list) and self.class_name not in names:
print(f"警告: 数据配置文件的names列表中未找到 {self.class_name} 类别")
elif isinstance(names, dict) and self.class_name not in names.values():
print(f"警告: 数据配置文件的names字典中未找到 {self.class_name} 类别")
elif not isinstance(names, (list, dict)):
print(f"警告: 数据配置文件的names类型不支持(应为list或dict)")
dataset_dir = os.path.dirname(data_config)
self.plate_info = pd.read_csv(os.path.join(dataset_dir, 'plate_info.csv'))
self.best_map = 0
self.patience = 5
self.no_improve_epochs = 0
self.best_model_path = None
初始化训练器的基础参数和资源,为后续训练、检测做准备,核心流程 6 6 6 步:
- 参数赋值:保存传入的数据集配置路径、模型名称、图像尺寸、批次大小、训练轮数、目标类别(车牌)等核心参数;
- 资源准备:保存中文字体属性(供可视化使用),创建测试结果输出目录(避免后续保存图片失败);
- 设备调度:通过torch判断当前环境是否支持 GPU,优先使用 GPU(设备标识 ‘0’),否则使用 CPU;
- 模型加载:加载预训练的 YOLOv8 模型(默认
yolov8m.pt,中型模型,兼顾精度和速度); - 数据校验:读取数据集配置文件(
yaml格式),校验配置中是否包含类别名称(names),且目标类别(license_plate)是否存在,避免训练时类别不匹配; - 数据加载:读取车牌信息 CSV 文件(含图像名称、车牌号码、顶点坐标等),初始化训练监控参数(最佳mAP、早停耐心值等)。
2.2 开始训练!
def train(self):
"""训练模型"""
names = self.data_info['names']
if isinstance(names, list):
class_idx = names.index(self.class_name)
elif isinstance(names, dict):
class_idx = list(names.values()).index(self.class_name)
else:
raise ValueError(f"不支持的names类型: {type(names)}")
results = self.model.train(
data=self.data_config,
epochs=self.epochs,
imgsz=self.img_size,
batch=self.batch_size,
device=self.device,
patience=self.patience,
save=True,
verbose=True,
project='license_plate_detection',
name='exp',
classes=[class_idx]
)
self.best_model_path = os.path.join(
'license_plate_detection',
'exp',
'weights',
'best.pt'
)
print(f"最佳模型已保存至: {self.best_model_path}")
return results
调用 YOLOv8 的训练接口,实现车牌类别的针对性训练,核心流程 3 3 3 步:
- 类别索引转换:将目标类别名称(
license_plate)转换为配置文件中对应的索引(因为 YOLO 训练需要通过索引指定训练类别),兼容names为列表或字典的两种配置格式; - 模型训练:传入训练参数(数据集配置、轮数、图像尺寸、批次大小、设备等),开启早停(
patience=5, 5 5 5 轮无提升则停止),训练结果保存至指定目录(license_plate_detection/exp),且仅训练车牌这一个类别(classes=[class_idx]),提升训练效率; - 结果记录:记录训练过程中生成的最佳模型路径(基于 mAP 指标筛选),并返回训练结果(含损失曲线、评估指标等)。
2.3 模型评估
def evaluate(self):
"""在验证集上评估模型"""
metrics = self.model.val(
data=self.data_config,
imgsz=self.img_size,
device=self.device,
verbose=True
)
mAP50 = metrics.box.map50
mAP50_95 = metrics.box.map
print(f"验证集评估结果:")
print(f"mAP@0.5: {mAP50:.4f}")
print(f"mAP@0.5:0.95: {mAP50_95:.4f}")
if hasattr(metrics.box, 'classes'):
for i, c in enumerate(metrics.box.classes):
print(f"类别 {c} - 精确率: {metrics.box.p[i]:.4f}, 召回率: {metrics.box.r[i]:.4f}, mAP50: {metrics.box.map50[i]:.4f}")
return {
'mAP50': mAP50,
'mAP50_95': mAP50_95
}
调用 YOLOv8 的验证接口,在验证集上评估模型性能,核心流程 3 3 3 步:
- 执行评估:传入数据集配置、图像尺寸、设备等参数,在验证集上计算模型的检测指标;
- 指标提取:提取核心评估指标—— m A P @ 0.5 mAP@0.5 mAP@0.5( I O U IOU IOU阈值 0.5 0.5 0.5 时的平均精度,目标检测核心指标)和 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95( I O U IOU IOU 阈值 0.5 0.5 0.5 到 0.95 0.95 0.95 的平均精度,更全面评估模型鲁棒性);
- 结果输出:打印评估结果(含类别级别的精确率、召回率),并返回核心指标字典供后续分析。
2.4 检测与裁剪矫正
def detect_and_crop(self, image_path):
"""检测车牌并裁剪矫正"""
image = cv2.imread(image_path)
if image is None:
return None, None
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = self.model(image_rgb, imgsz=self.img_size)
boxes = results[0].boxes
if len(boxes) == 0:
return None, None
best_idx = boxes.conf.argmax().item()
box = boxes.xyxy[best_idx].cpu().numpy()
conf = boxes.conf[best_idx].item()
x1, y1, x2, y2 = map(int, box)
plate_region = image[y1:y2, x1:x2]
image_name = os.path.basename(image_path)
plate_row = self.plate_info[self.plate_info['image_name'] == image_name]
if not plate_row.empty:
try:
vertices_str = plate_row['vertices'].values[0]
vertices = eval(vertices_str)
vertices_np = np.array(vertices, dtype=np.float32)
corrected_plate = correct_skew(image, vertices_np)
return corrected_plate, conf
except Exception as e:
print(f"使用顶点信息矫正失败: {e}")
try:
gray = cv2.cvtColor(plate_region, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
lines = cv2.HoughLinesP(edges, 1, np.pi/180, 30, minLineLength=30, maxLineGap=10)
if lines is not None:
angles = []
for line in lines:
x1_line, y1_line, x2_line, y2_line = line[0]
angle = np.arctan2(y2_line - y1_line, x2_line - x1_line) * 180.0 / np.pi
angles.append(angle)
median_angle = np.median(angles)
if abs(median_angle) > 5:
rows, cols = plate_region.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), median_angle, 1)
plate_region = cv2.warpAffine(plate_region, M, (cols, rows), borderMode=cv2.BORDER_REPLICATE)
except Exception as e:
print(f"基于边界框的矫正失败: {e}")
corrected_plate = cv2.resize(plate_region, (400, 100))
return corrected_plate, conf
实现车牌的检测、裁剪与倾斜矫正,确保输出规整的车牌图像,核心流程 5 5 5 步:
- 图像读取与检测:读取输入图像,转换为 R G B RGB RGB 格式( Y O L O YOLO YOLO 模型输入要求),调用模型检测车牌,若未检测到车牌则返回 N o n e None None;
- 最优检测框筛选:从检测结果中选取置信度最高的边界框(
best_idx=conf.argmax()),提取边界框坐标和置信度,裁剪出车牌区域; - 优先顶点矫正:查询车牌信息 C S V CSV CSV,若当前图像有车牌顶点坐标(标注的精准位置),则调用
correct_skew函数进行透视变换矫正(最精准的矫正方式); - 降级边界框矫正:若顶点矫正失败,通过 C a n n y Canny Canny 边缘检测 + 霍夫直线检测提取车牌区域的直线角度,计算中位角度,当倾斜角度> 5 ° 5° 5° 时进行旋转矫正,避免小角度过度矫正;
- 统一尺寸:将矫正后的车牌图像 resize 到固定尺寸( 400 × 100 400×100 400×100,符合中国车牌的宽高比),返回规整的车牌图像和置信度。
3. 辅助函数:correct_skew(车牌倾斜矫正)
def correct_skew(image, vertices):
"""改进的车牌倾斜矫正算法"""
if len(vertices) != 4:
rect = cv2.minAreaRect(vertices)
vertices = cv2.boxPoints(rect)
center = np.mean(vertices, axis=0)
def get_angle(point):
return np.arctan2(point[1] - center[1], point[0] - center[0]) * 180 / np.pi
vertices = sorted(vertices, key=get_angle)
width_top = np.linalg.norm(vertices[0] - vertices[1])
width_bottom = np.linalg.norm(vertices[2] - vertices[3])
width = int((width_top + width_bottom) / 2)
height_left = np.linalg.norm(vertices[0] - vertices[3])
height_right = np.linalg.norm(vertices[1] - vertices[2])
height = int((height_left + height_right) / 2)
# 确保宽大于高(车牌特征)
if width < height:
width, height = height, width
vertices = [vertices[1], vertices[2], vertices[3], vertices[0]]
# 强制设置宽高比为4:1(中国车牌标准)
if width / height < 3.5:
width = int(height * 4)
dst = np.array([
[0, 0],
[width - 1, 0],
[width - 1, height - 1],
[0, height - 1]], dtype=np.float32)
M = cv2.getPerspectiveTransform(np.array(vertices, dtype=np.float32), dst)
warped = cv2.warpPerspective(image, M, (width, height))
# 通过HSV颜色空间检测蓝色区域判断是否需要翻转
if height > 0 and width > 0:
hsv = cv2.cvtColor(warped, cv2.COLOR_BGR2HSV)
lower_blue = np.array([100, 50, 50])
upper_blue = np.array([130, 255, 255])
blue_mask = cv2.inRange(hsv, lower_blue, upper_blue)
blue_area = cv2.countNonZero(blue_mask)
flipped = cv2.flip(warped, 0)
flipped_hsv = cv2.cvtColor(flipped, cv2.COLOR_BGR2HSV)
flipped_blue_mask = cv2.inRange(flipped_hsv, lower_blue, upper_blue)
flipped_blue_area = cv2.countNonZero(flipped_blue_mask)
if flipped_blue_area > blue_area * 1.2:
warped = flipped
# 统一调整为目标尺寸
target_size = (400, 100)
resized = cv2.resize(warped, target_size)
return resized
基于透视变换实现车牌的精准倾斜矫正,同时优化车牌方向和尺寸,核心流程 6 6 6 步:
- 顶点预处理:若输入顶点数不是 4 4 4(非四边形),则通过最小外接矩形拟合生成 4 4 4 个顶点,确保符合透视变换要求;
- 顶点排序:以车牌中心为基准,按顶点与中心的夹角排序,确保顶点按 左上→右上→右下→左下 的顺序排列;
- 尺寸计算:计算车牌上下边的平均宽度和左右边的平均高度,确保宽>高(符合中国车牌横版特征),若不符合则交换宽高并重新排序顶点;
- 宽高比校正:强制将宽高比调整为 4 : 1 4:1 4:1(中国标准车牌宽高比),避免标注误差导致的尺寸异常;
- 透视变换:定义目标矩形(规整的矩形),计算透视变换矩阵,将倾斜的车牌映射为规整的矩形;
- 方向优化:通过 H S V HSV HSV 颜色空间检测蓝色区域(中国民用车牌多为蓝底),判断车牌是否倒置,若倒置则翻转调整;最后统一 resize 到固定尺寸( 400 × 100 400×100 400×100)并返回。
六、结果展示
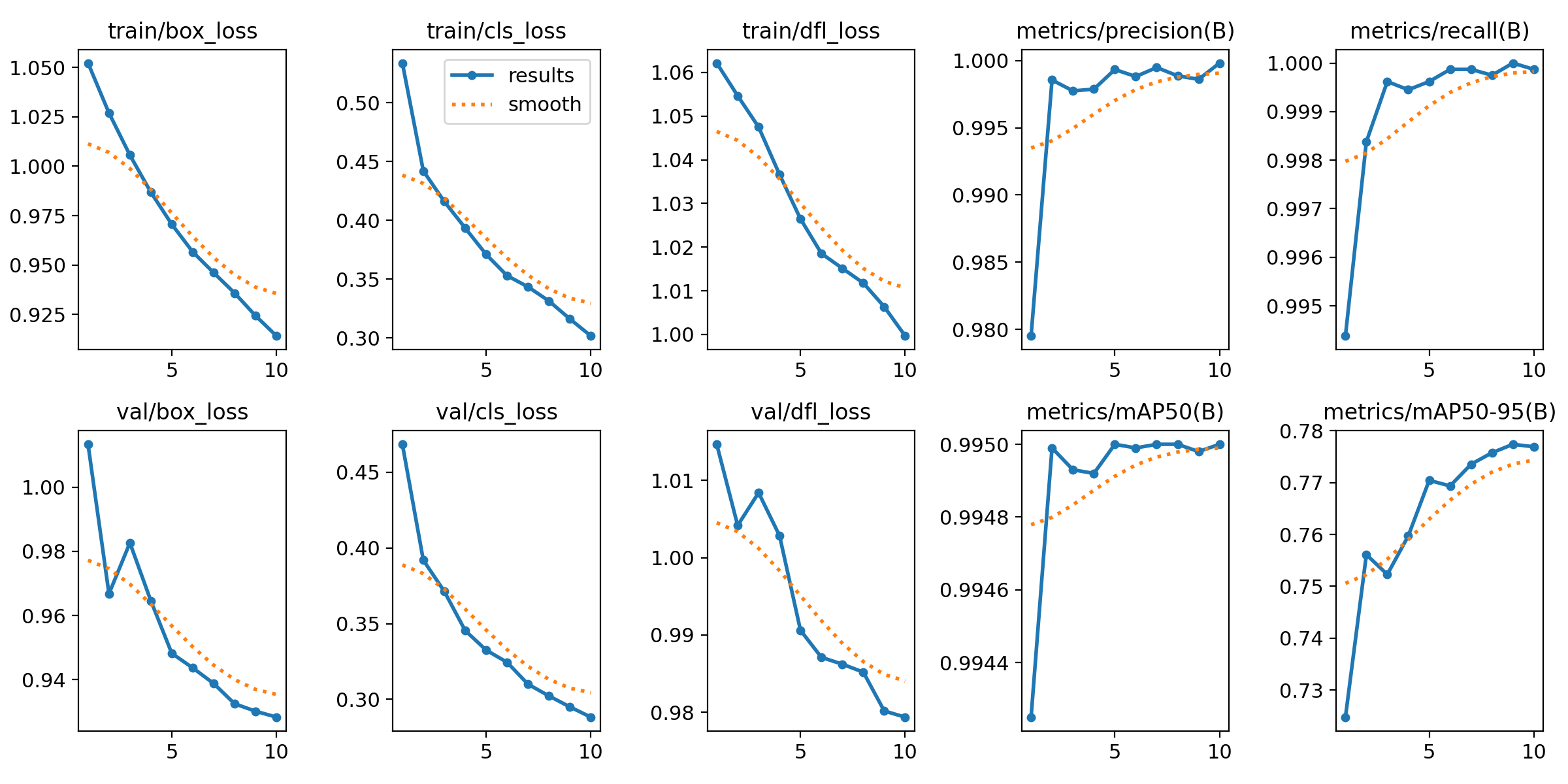
1. 模型评估结果
车牌检测模型(YOLOv8)
| 评估指标 | 数值示例 | 说明 |
|---|---|---|
| mAP@0.5 | 0.9950 | IoU=0.5 时的平均精度 |
| mAP@0.5:0.95 | 0.777 | IoU 0.5-0.95 的平均精度 |
| 精确率(Precision) | 0.999 | 检测为车牌的样本中实际为车牌的比例 |
| 召回率(Recall) | 1.000 | 实际为车牌的样本中被检测到的比例 |
2. 可视化结果
车牌位置检测
训练历史曲线:
-
损失曲线:训练损失与验证损失随轮次下降,最终趋于平稳(无明显过拟合)
-
准确率曲线:训练准确率与验证准确率同步上升,最佳验证准确率稳定在 92% 以上
训练过程中得到的训练检测:

验证检测:

初步使用YOLOv8定位并进行矫正裁剪的车牌测试结果如下:

如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)