微软开源语音识别模型——VibeVoice-ASR
VibeVoice-ASR是微软推出的统一语音转文本模型,具备多项创新功能:支持60分钟长音频单次处理,保持说话人追踪与语义连贯性;提供自定义热词功能提升专业术语识别;可生成包含说话人、时间戳和内容的结构化转录;支持50多种语言及语码转换。该模型采用MIT许可证开源,性能表现优异,适用于会议记录、访谈转录等场景。项目团队欢迎用户反馈与合作,致力于持续优化模型表现。
VibeVoice-ASR



VibeVoice-ASR 是一款统一的语音转文本模型,专为处理60分钟长音频而设计,可一次性生成包含说话人(Who)、时间戳(When)和内容(What)的结构化转录,并支持自定义热词及50多种语言。
➡️ 代码库: microsoft/VibeVoice
➡️ 演示: VibeVoice-ASR 演示
➡️ 技术报告: VibeVoice-ASR 技术报告
➡️ 微调指南: 微调
➡️ vLLM 支持: vLLM-VibeVoice-ASR
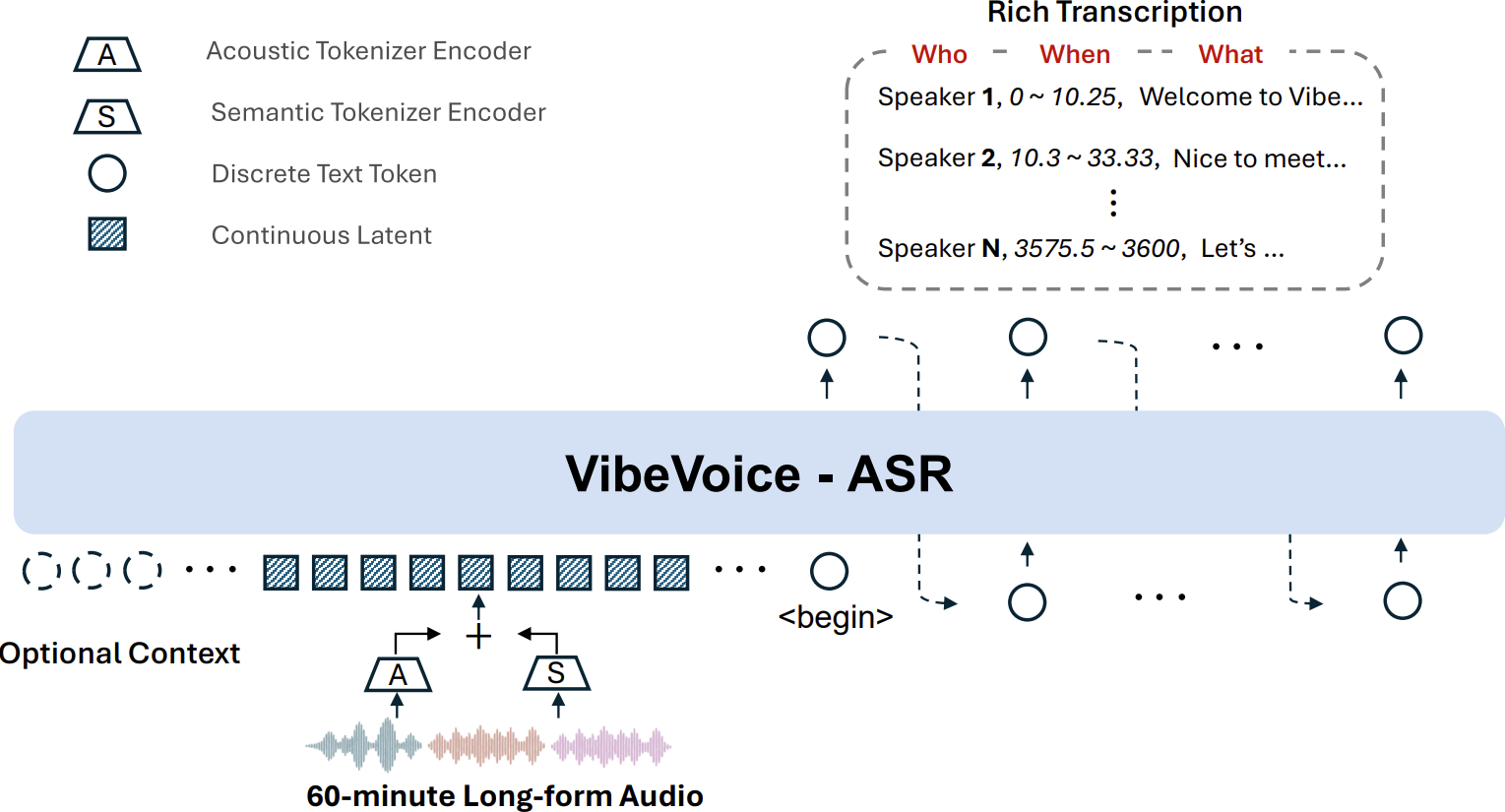
🔥 核心功能
-
🕒 60分钟单次处理:
与传统ASR模型将音频切割为短片段(常丢失全局上下文)不同,VibeVoice ASR可接受长达60分钟的连续音频输入(64K token长度内),确保整小时内的说话人追踪与语义连贯性。 -
👤 自定义热词:
用户可提供定制热词(如特定人名、专业术语或背景信息)引导识别过程,显著提升专业领域内容的准确率。 -
📝 富文本转录(人·时·事):
模型同步完成语音识别、说话人分离和时间戳标注,输出结构化结果,明确标注谁在何时说了什么。 -
🌍 多语言&语码转换支持:
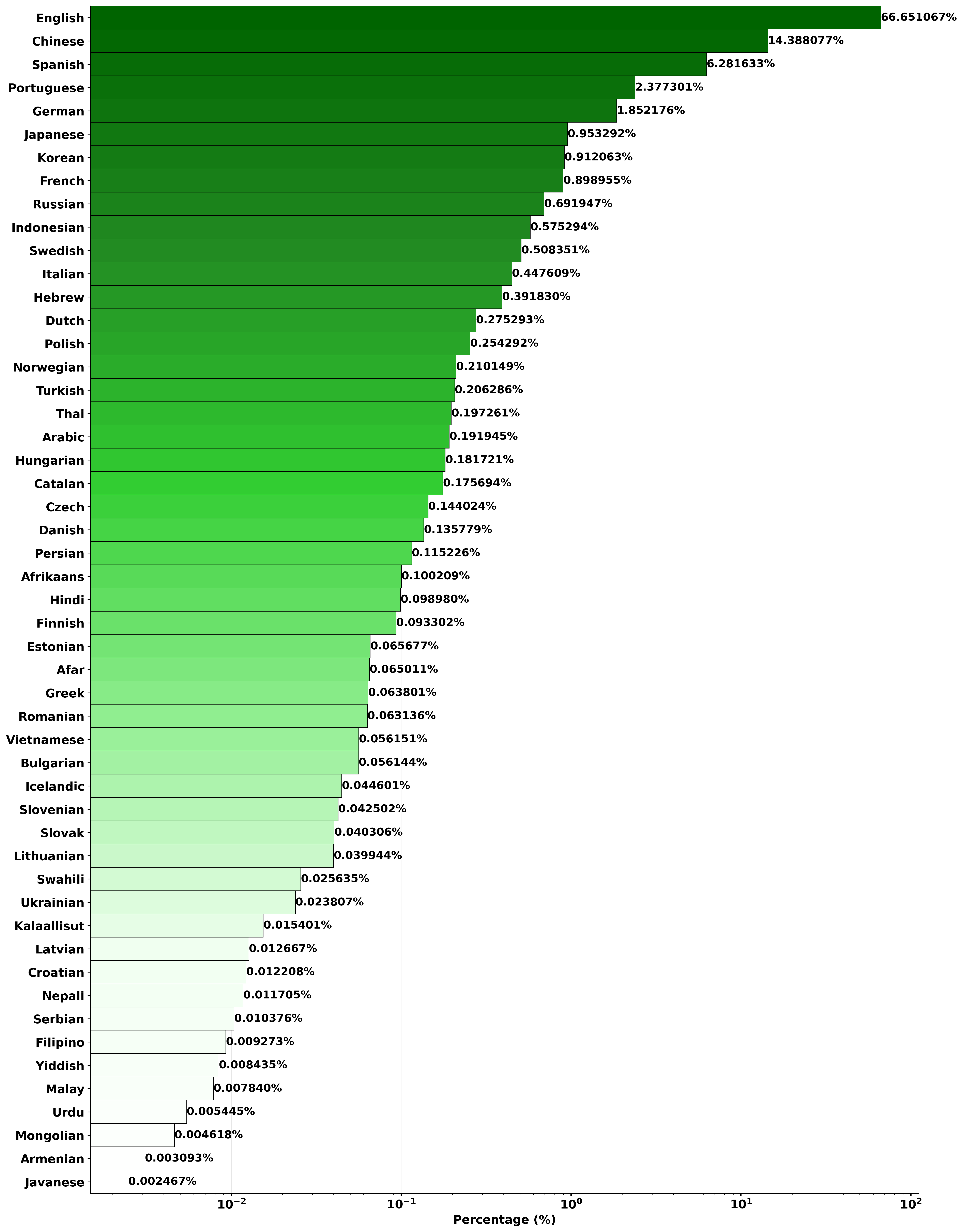
支持50余种语言,无需显式设置语言,原生支持语句内/间的语码转换。语言分布详见此处。
性能评估
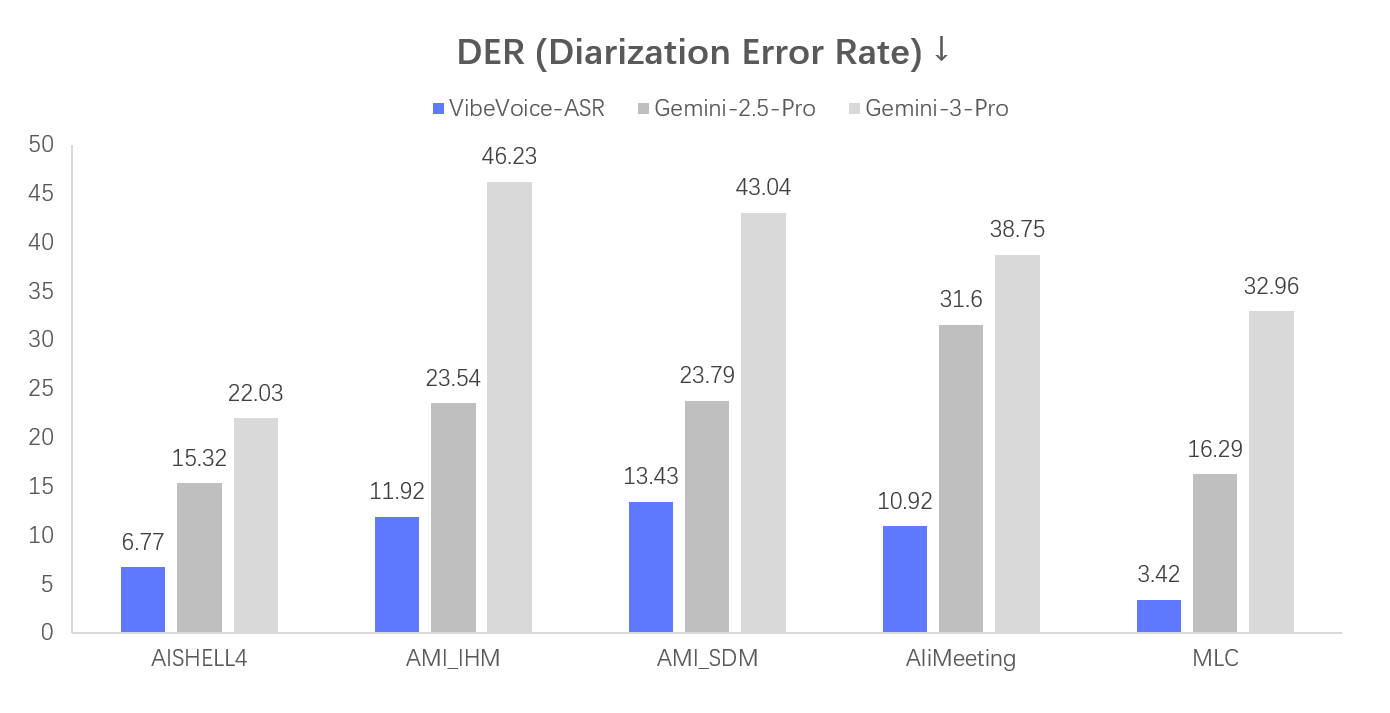
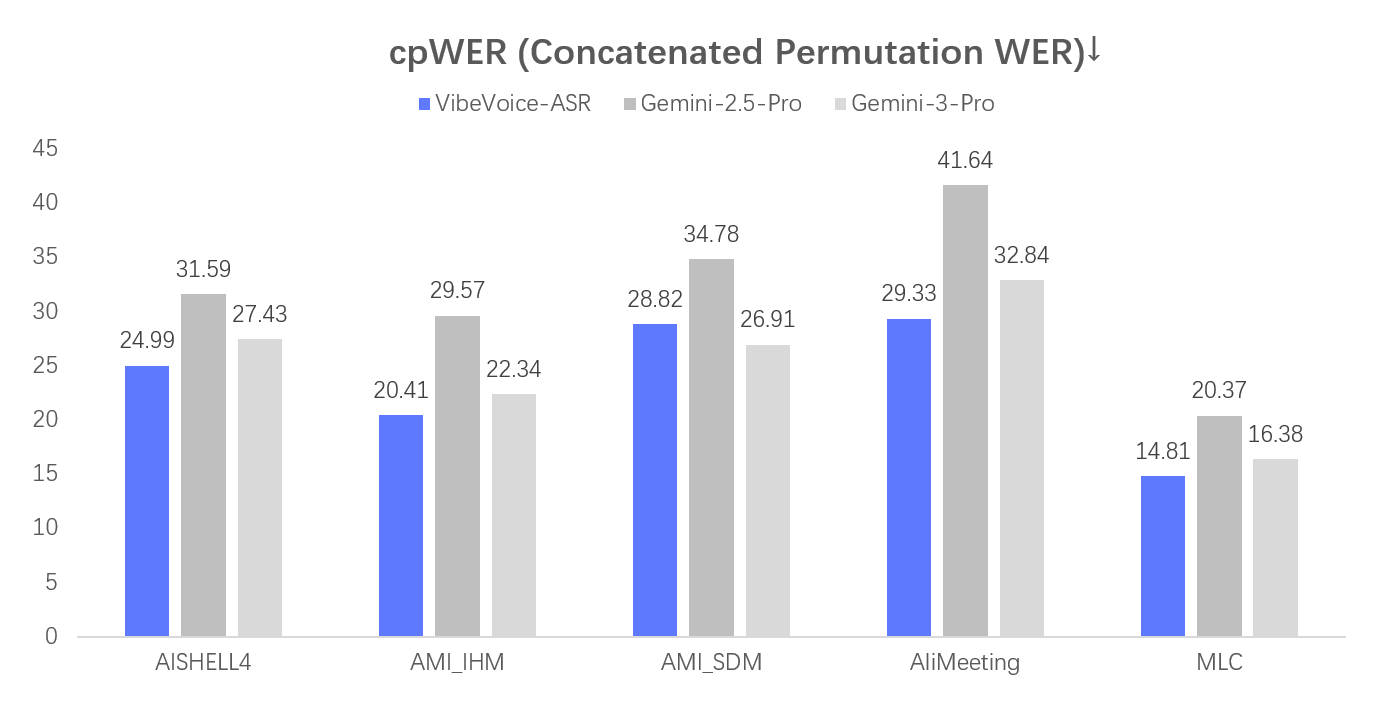
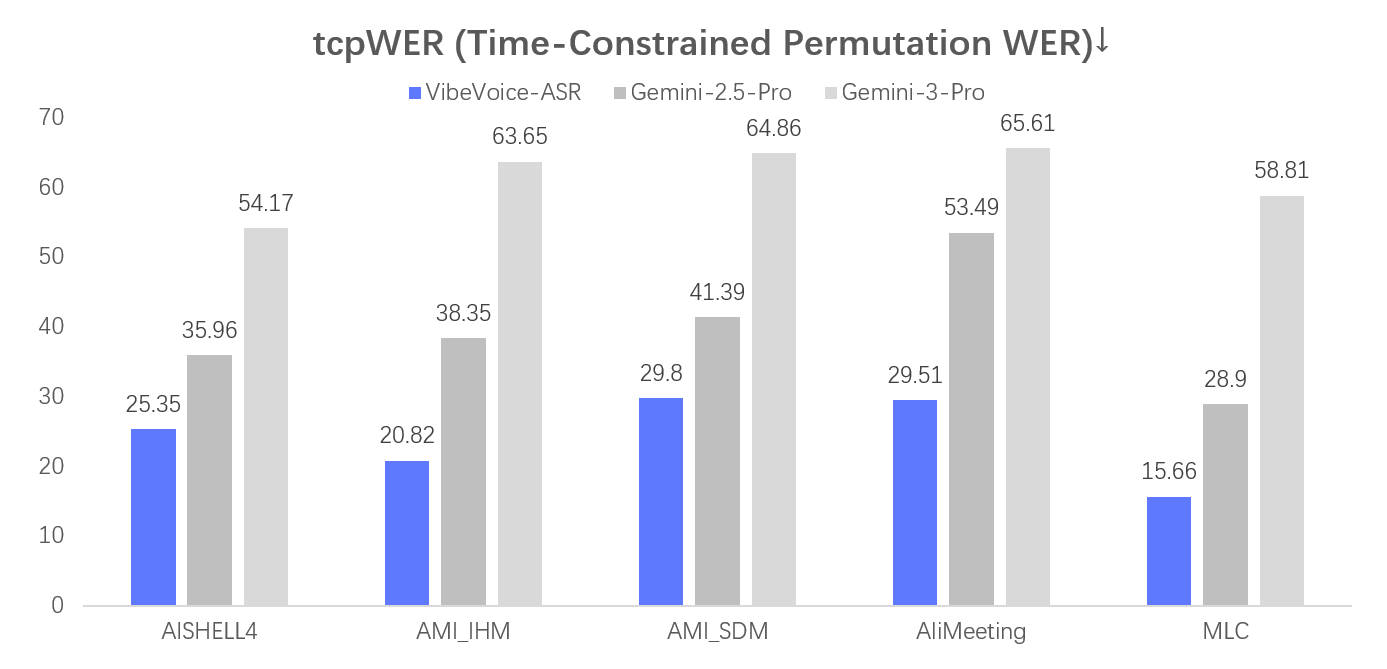
安装与使用
请参阅 GitHub README。
语言分布
许可证
本项目采用MIT许可证授权。
联系方式
本项目由微软研究院成员开展。我们欢迎来自用户的反馈与合作。如果您有任何建议、疑问,或发现我们的技术存在意外/冒犯性行为,请通过VibeVoice@microsoft.com联系我们。
若团队收到不良行为报告或自行发现问题,我们将在此代码库中更新适当的缓解措施。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)