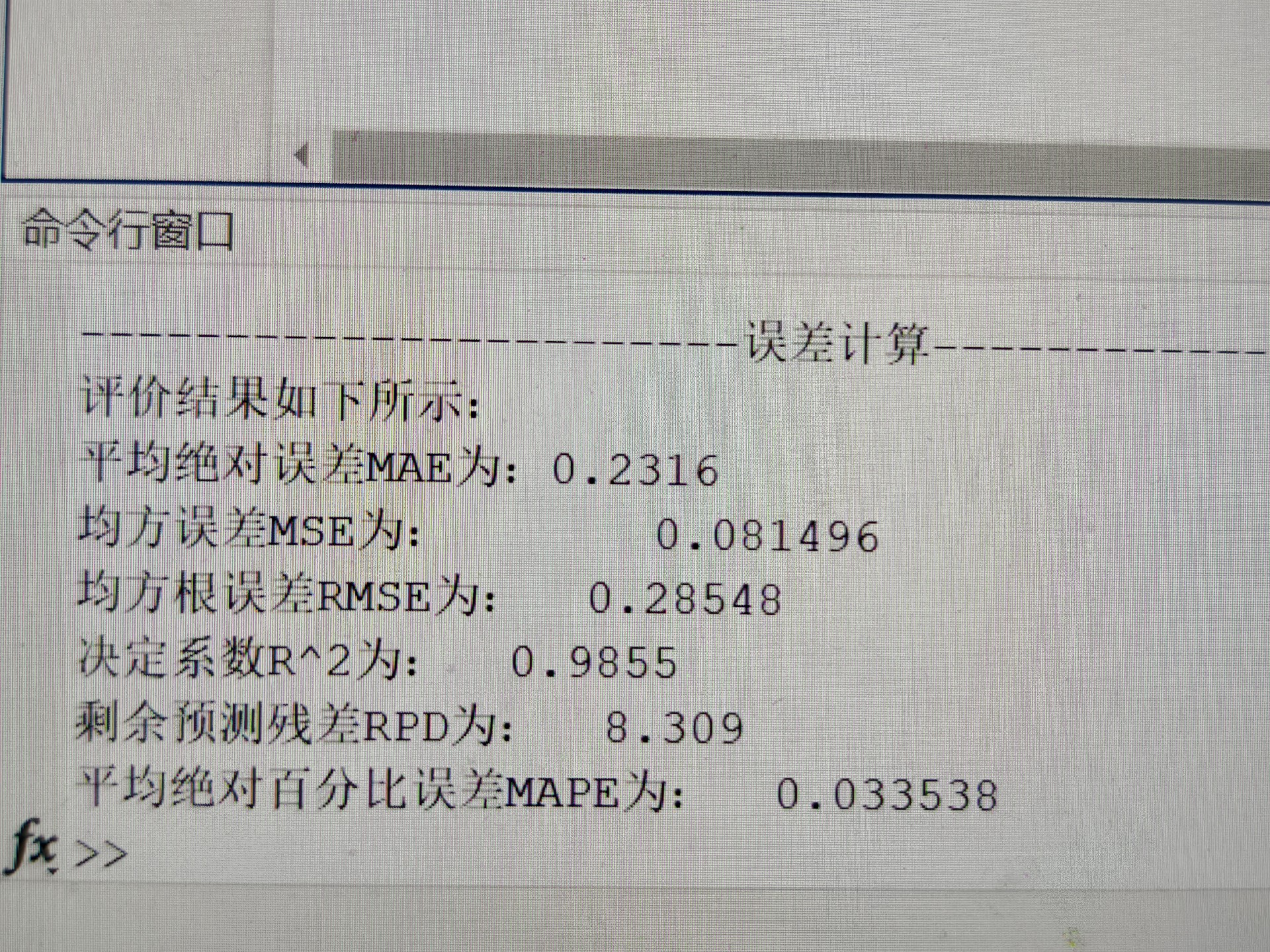
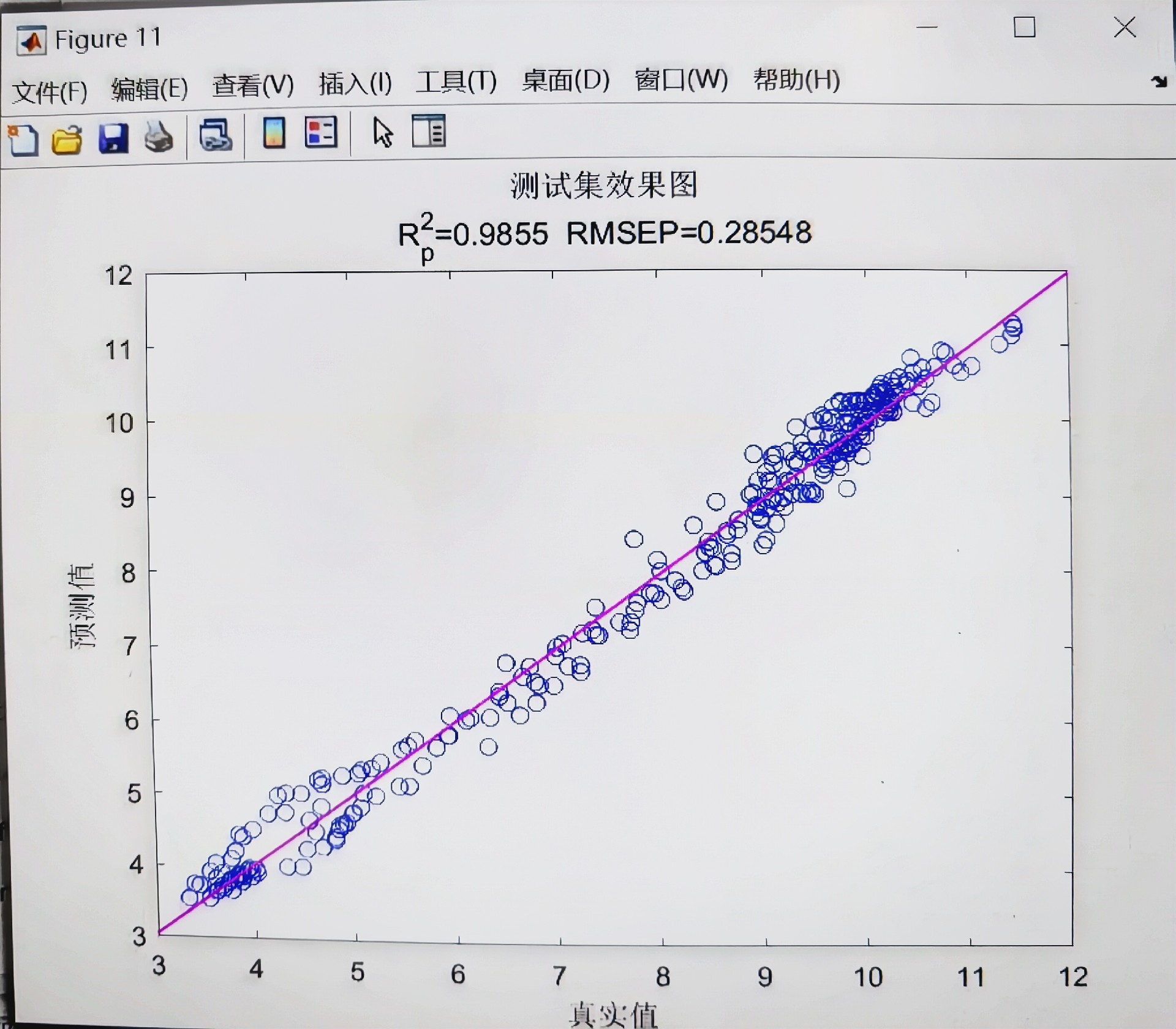
探索基于BKA - Transformer - LSTM的数据回归预测
基于BKA-Transformer-LSTM的数据回归预测 模型结合Transformer的全局注意力机制和LSTM的短期记忆及序列处理能力 首先,采用Transformer自注意力机制捕捉数据的全局依赖性,并输出一个经过全局上下文编码的表示;然后,采用2024年最新优化算法黑翅鸢优化算法BKA优化长短时记忆网络LSTM的隐含层神经元数目等,以避免模型陷入局部最优,提高模型泛化能力;最后,采用优化的LSTM内部的记忆单元和门控机制捕捉数据中的短期依赖关系,进一步处理这个表示,捕捉其中的短期依赖关系,并输出最终的预测结果
在数据预测领域,如何巧妙融合不同模型的优势来提升预测精度一直是研究热点。今天咱们聊聊基于BKA - Transformer - LSTM的数据回归预测模型,这个模型可是把Transformer的全局注意力机制与LSTM的短期记忆及序列处理能力完美结合了起来。
Transformer自注意力机制捕捉全局依赖性
Transformer的自注意力机制就像是拥有上帝视角,能捕捉数据间的全局依赖性。它通过计算输入序列中每个位置与其他位置的关联程度,生成一个经过全局上下文编码的表示。以下是一个简化的自注意力机制代码示例(使用Python和PyTorch):
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super(SelfAttention, self).__init__()
self.embed_dim = embed_dim
self.query_proj = nn.Linear(embed_dim, embed_dim)
self.key_proj = nn.Linear(embed_dim, embed_dim)
self.value_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
query = self.query_proj(x)
key = self.key_proj(x)
value = self.value_proj(x)
attention_scores = torch.matmul(query, key.transpose(-2, -1)) / (self.embed_dim ** 0.5)
attention_weights = nn.functional.softmax(attention_scores, dim=-1)
output = torch.matmul(attention_weights, value)
return output这里,SelfAttention类实现了自注意力机制。在forward函数中,首先通过线性变换得到query、key和value,然后计算注意力分数attentionscores,并通过softmax得到注意力权重attentionweights,最后将注意力权重与value相乘得到输出。这一过程让模型能够在全局范围内捕捉数据的相关性。
黑翅鸢优化算法BKA优化LSTM
2024年最新的黑翅鸢优化算法BKA闪亮登场,它主要用于优化长短时记忆网络LSTM的隐含层神经元数目等参数。LSTM虽然强大,但容易陷入局部最优,而BKA就像是给LSTM装上了智能导航,避免它在优化过程中迷路。
基于BKA-Transformer-LSTM的数据回归预测 模型结合Transformer的全局注意力机制和LSTM的短期记忆及序列处理能力 首先,采用Transformer自注意力机制捕捉数据的全局依赖性,并输出一个经过全局上下文编码的表示;然后,采用2024年最新优化算法黑翅鸢优化算法BKA优化长短时记忆网络LSTM的隐含层神经元数目等,以避免模型陷入局部最优,提高模型泛化能力;最后,采用优化的LSTM内部的记忆单元和门控机制捕捉数据中的短期依赖关系,进一步处理这个表示,捕捉其中的短期依赖关系,并输出最终的预测结果
假设我们使用BKA优化LSTM的隐含层神经元数目hidden_size,虽然没有现成的BKA算法库直接调用,这里我们用伪代码来大概示意下这个优化过程:
# 假设我们有一个训练好的LSTM模型
class SimpleLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(SimpleLSTM, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
# 初始化一些参数
input_size = 10
num_layers = 2
# 假设BKA算法返回一个优化后的hidden_size
optimized_hidden_size = bka_optimize()
# 使用优化后的参数构建LSTM模型
model = SimpleLSTM(input_size, optimized_hidden_size, num_layers)上述伪代码中,SimpleLSTM是一个简单的LSTM模型,bkaoptimize函数代表使用BKA算法来优化hiddensize,最后使用优化后的hidden_size构建模型,以此提高模型的泛化能力。
LSTM捕捉短期依赖关系
经过Transformer自注意力机制处理的数据,再交给优化后的LSTM。LSTM内部的记忆单元和门控机制能够很好地捕捉数据中的短期依赖关系。下面是一个简单的LSTM代码示例(同样基于PyTorch):
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out在这个LSTMModel类中,lstm层处理输入序列,通过记忆单元和门控机制捕捉短期依赖关系,fc层将LSTM的输出映射到最终的预测结果。
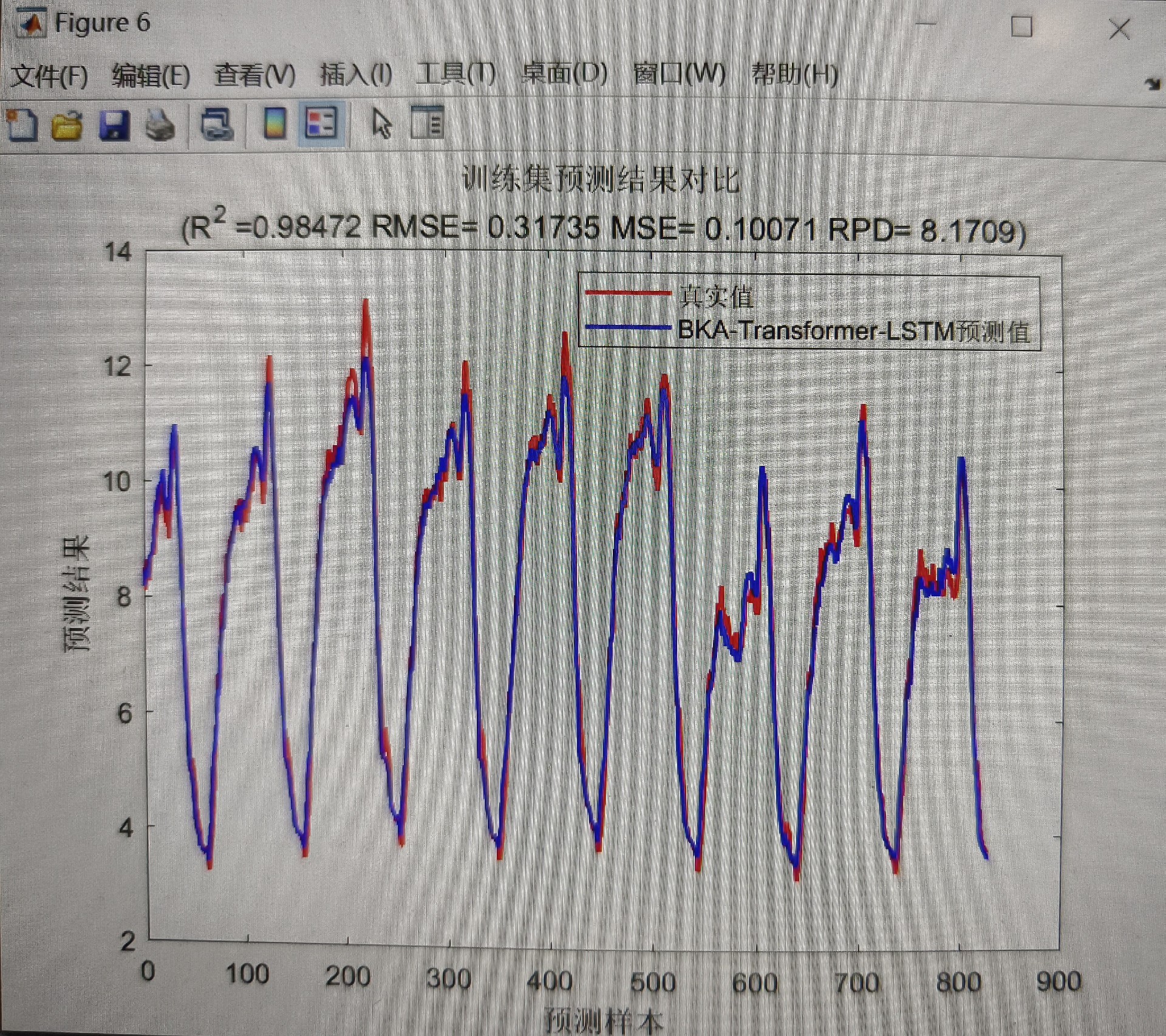
综上所述,基于BKA - Transformer - LSTM的数据回归预测模型通过这样三步走,充分利用了Transformer的全局视野和LSTM的短期记忆能力,再加上BKA算法的优化加持,在数据回归预测任务中有望取得出色的效果。当然,实际应用中还需要根据具体数据和任务进行进一步的调优和验证。
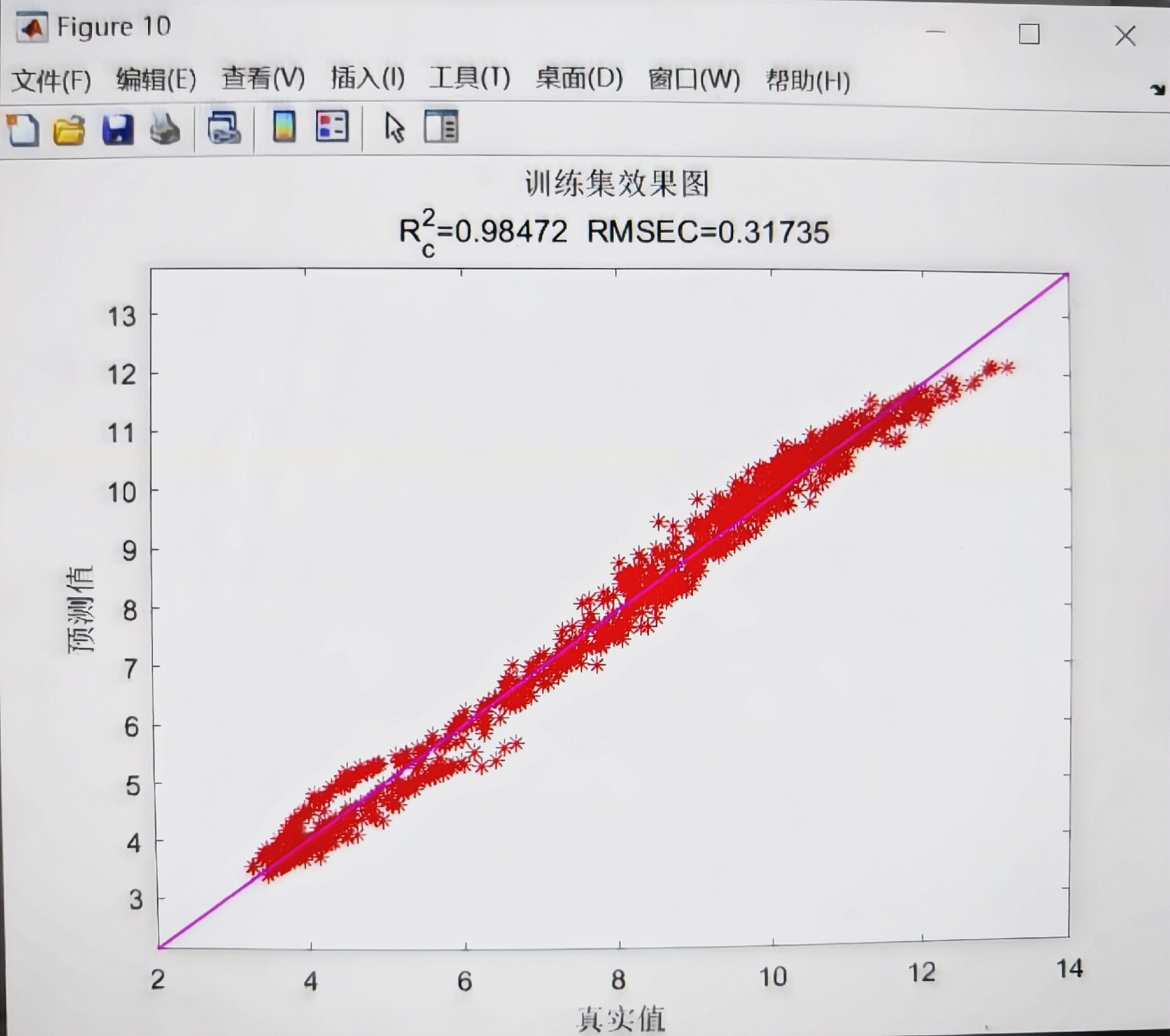
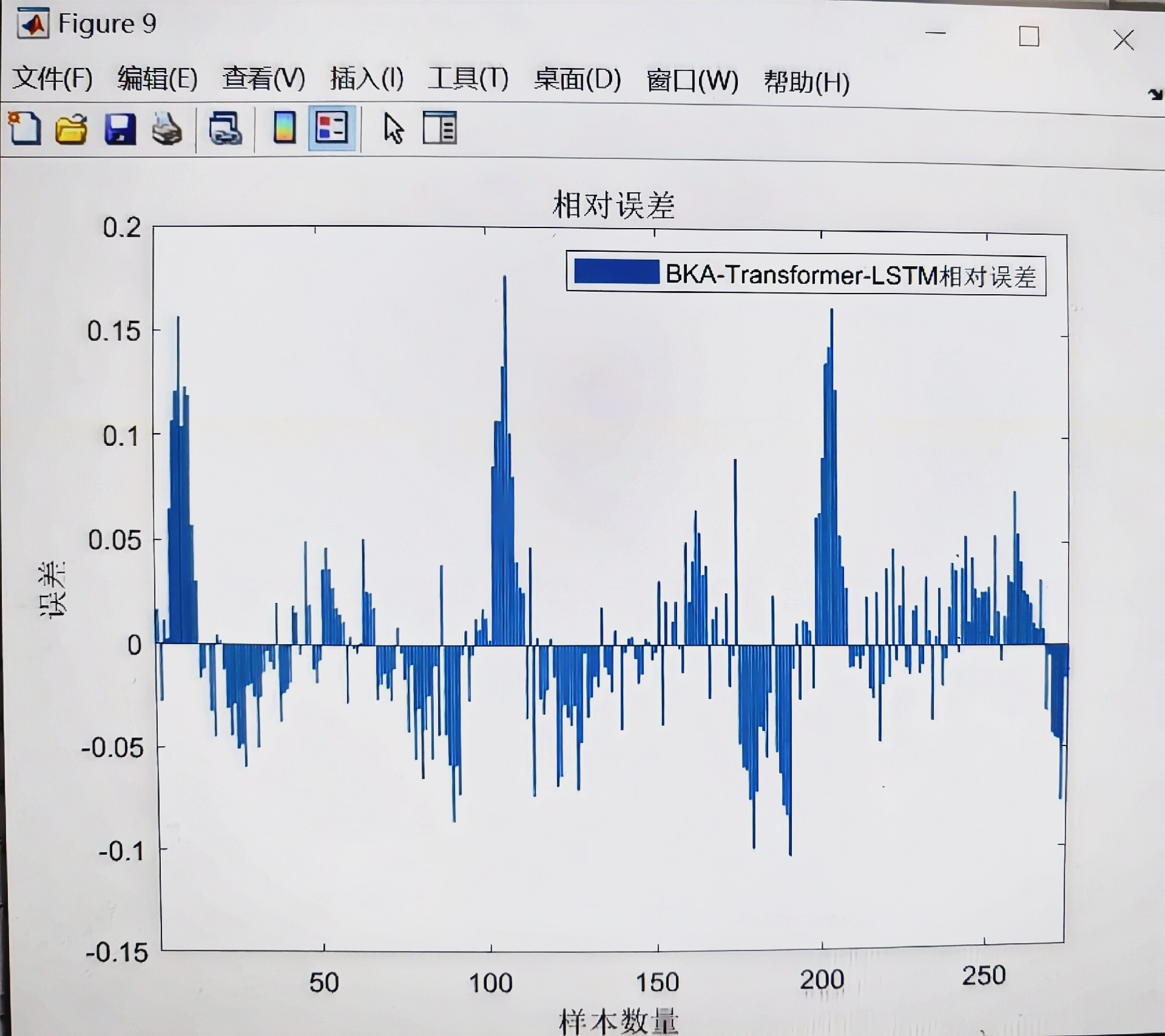
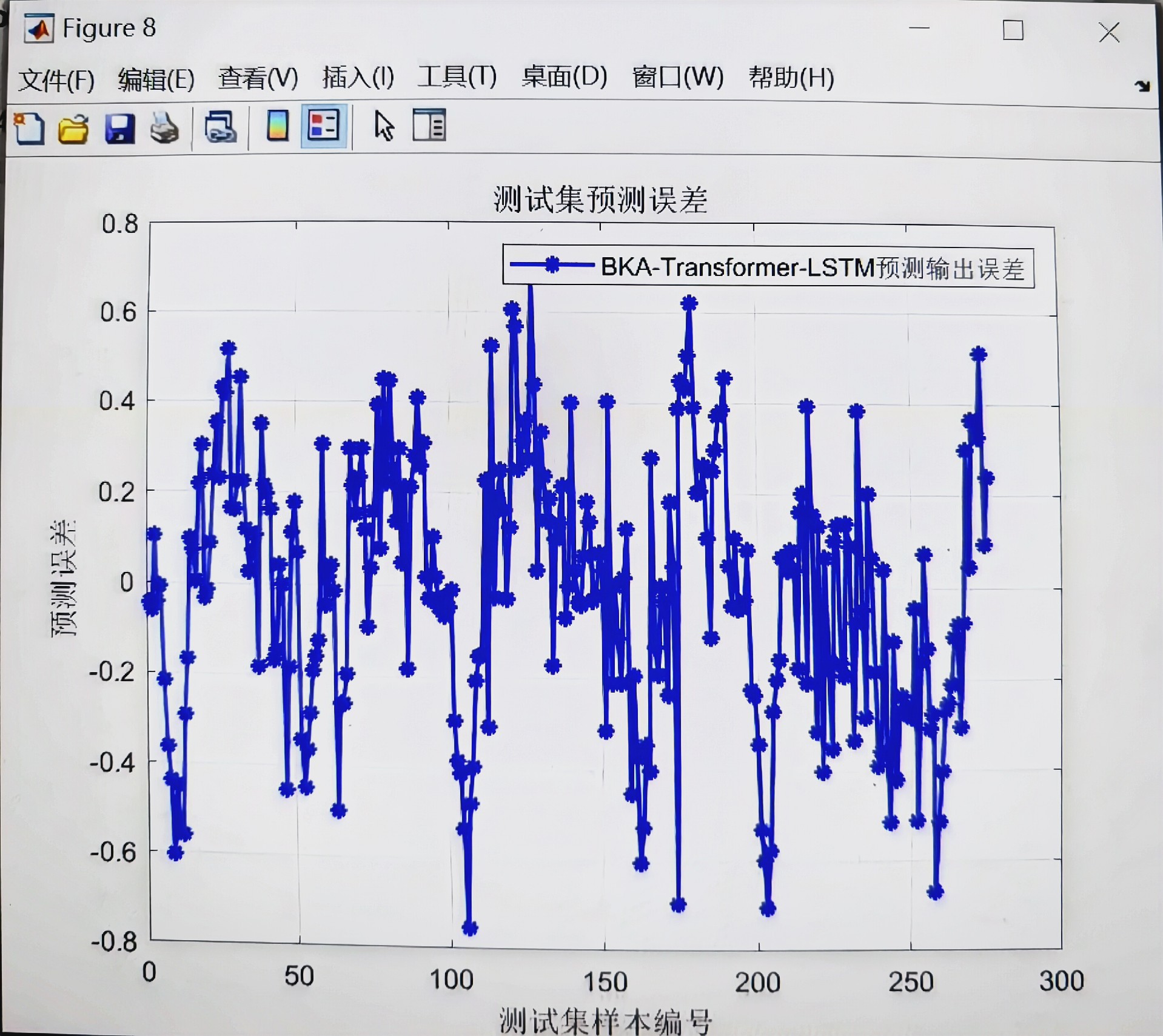
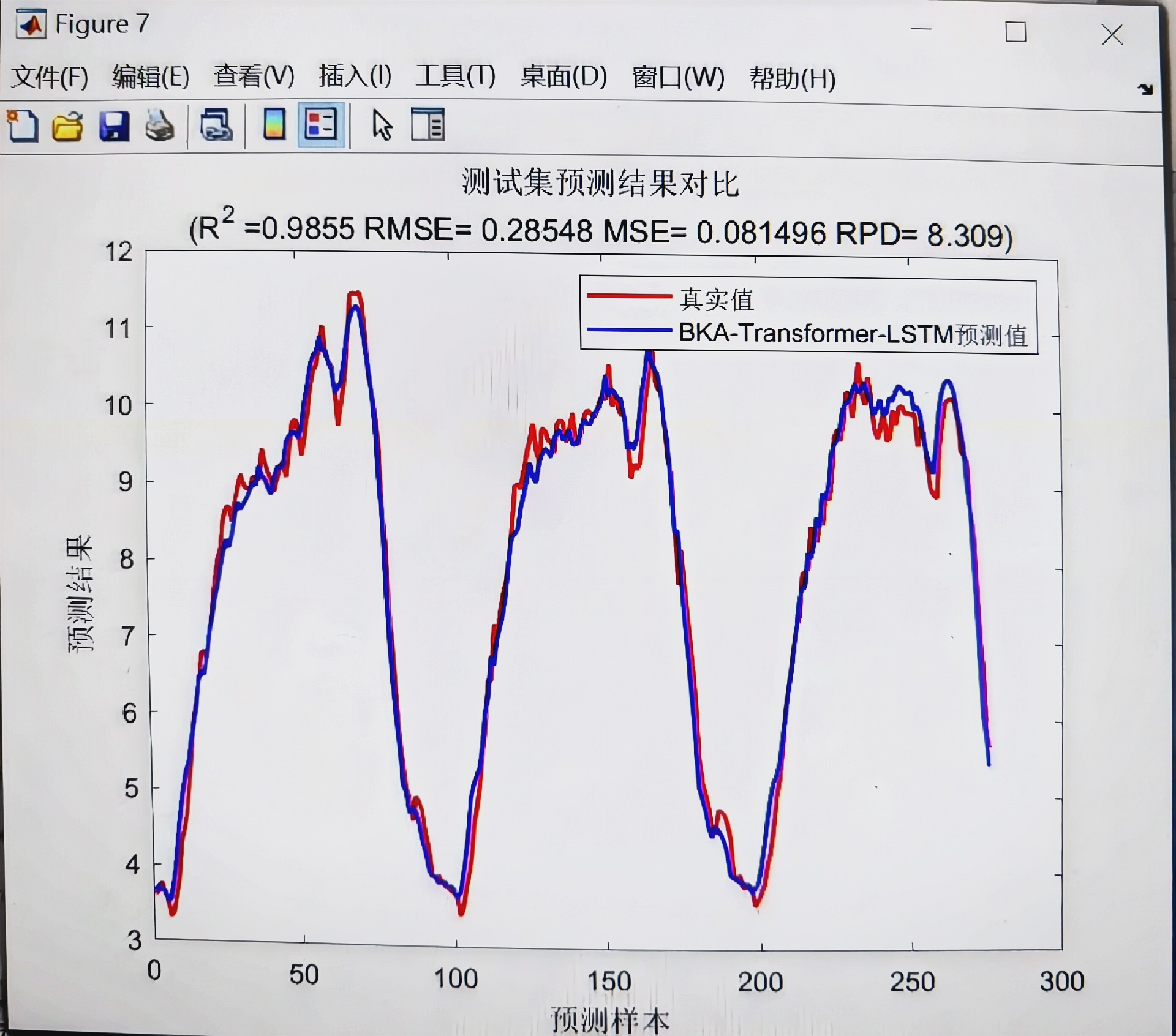

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)