YOLOv8n-CCNet:一种具有渐进式卷积的轻量级人群计数网络
导读:
人群计数技术在公共安全、智慧城市和交通管理等领域具有重要应用价值。然而,现实场景中的群体图像存在尺度剧烈变化、遮挡严重以及背景复杂等挑战,导致现有方法难以兼顾准确性与效率。为应对这些问题,本文基于改进的YOLOv8n架构,提出一种人群计数网络YOLOv8n-CCNet。该网络通过三项核心创新实现性能提升:首先,在骨干网络中引入渐进式GhostConv替换策略,并设计轻量化特征提取模块,在保持多尺度感知能力的同时减少27.3%的参数数量;其次,在特征融合层加入通道与位置注意力机制,通过局部跨通道交互和方向感知的位置编码,增强对密集小目标的定位能力;最后,采用WIoUv3边界框回归损失函数,通过动态非单调聚焦机制优化梯度特性,提升遮挡场景下的回归稳定性。为验证所提方法的有效性,在包含1500张图像的高密度、多尺度人群自制数据集上进行了实验。结果表明,YOLOv8n-CCNet的mAP50达到65.3%,mAP50:95为35.6%,召回率为56.4%。相比基线模型,在计数精度和推理速度方面均有显著提升,证明了其在复杂现实场景中的有效性。
作者信息:
田雪晴, 张东明*, 郭亦涵, 赵文会, 陈立家:河南大学物理与电子学院,河南 开封
论文详情
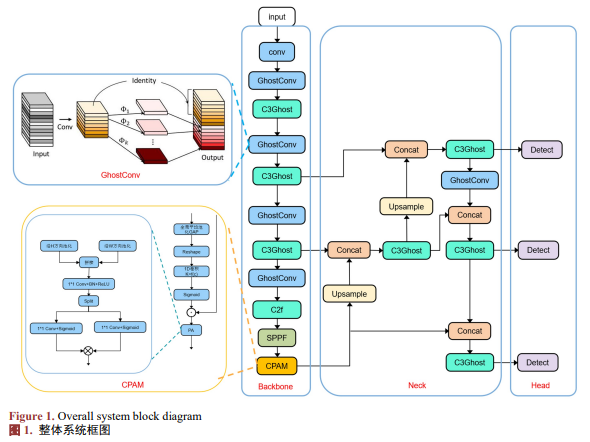
本文提出YOLOv8n‑CCNet模型。该模型设计基于三大核心准则:轻量化架构、精准定位与精细聚焦,依次引入轻量级GhostConv模块与高精度WIoU损失函数,并结合通道与位置注意力机制,构建了一套面向密集多尺度人群场景的优化检测体系。整体框架如图1所示。
训练采用AdamW优化器,初始学习率为1e−3,权重衰减系数为0.05。学习率调度采用带热启动的余弦退火策略。数据增强方法包括马赛克增强、随机裁剪与色彩空间扰动。训练共进行300轮,批次大小为16,并采用混合精度训练以加速收敛。所有实验均在配备NVIDIA RTX 3060 GPU的工作站上完成。输入图像尺寸根据数据集进行调整,训练时使用预训练权重进行初始化。
数据来源包括:(1) 从符合CC0协议的公开视频平台(如Pexels、Pixabay)采集的监控场景图像,筛选时遵循场景多样性、人群密度梯度、光照与遮挡条件及分辨率四项标准;(2) 融合多个广泛使用的人群计数公开数据集,包括ShanghaiTech、UCF-QNR、NWPU-Crowd,均已遵循相应许可协议。经去重与清洗后,数据集共包含1500张图像,标注人头实例超过15万个。所有标注均由专业标注人员进行边界框标注,并经过三轮交叉验证以确保标注质量。最后,将数据集按照8:2比例随机划分为训练集(1200张图像)与验证集(300张图像),划分过程中保持不同来源与场景的分布均衡。
我们选择使用召回率(Recall)和平均精度均值(Mean Average Precision, mAP)作为我们的指标来衡量计数精度和稳健性。其计算公式如下所示:
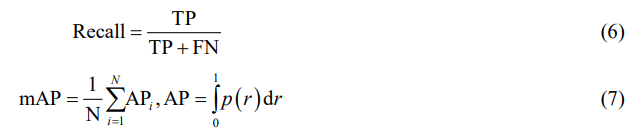
其中平均精度AP是通过量化精确率–召回率曲线(P-R曲线)下的面积;TP,FN是混淆矩阵中的指标。
混淆矩阵通过对比实际标签与预测标签,将结果分为四类:真正例(TP,预测正确且为正类)、假正例(FP,预测错误且为正类)、真反例(TN,预测正确且为负类)、假反例(FN,预测错误且为负类)。
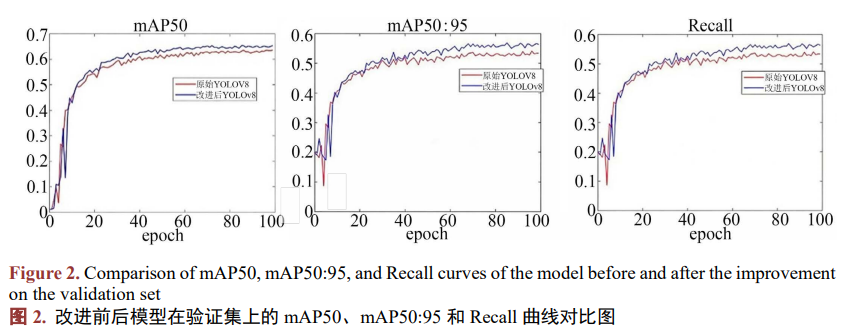
为直观对比模型性能,我们将改进前后的YOLOv8n在验证集上的mAP50、mAP50:95和Recall随训练轮次的变化曲线进行对比,结果如图2所示。
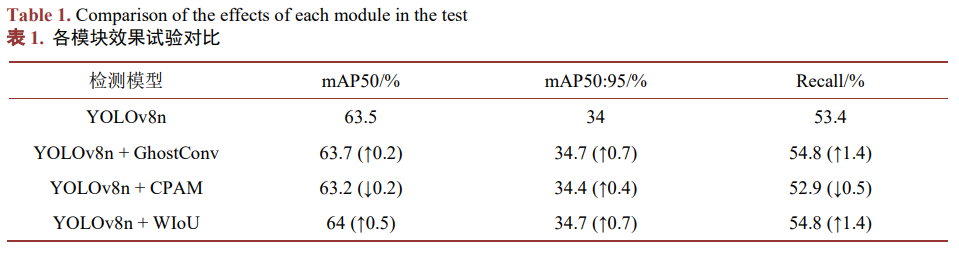
对于加入各模块之后的效果进行对比,并且分析各改进模块的贡献,包括GhostConv模块、CPAM模块以及WIoU损失函数等。具体结果如表1所示。
消融实验通过逐步验证各模块对模型性能的贡献,结合本文对比实验,量化不同改进策略对检测精度的影响。本次消融实验的设计如表2所示,其中“√”表示使用了该模块,空白则表示未使用。消融实验结果如表3所示。其中“↑”表示性能增加量,“↓”表示性能减少量。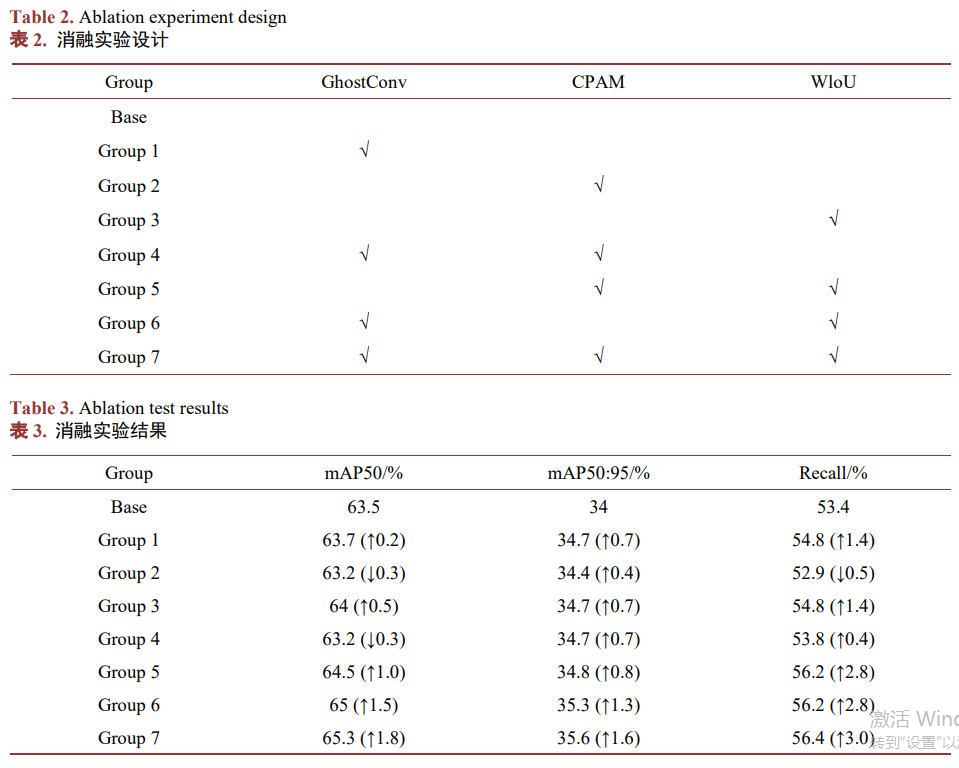
由表3所示,Group 7检测精度全面优于其他Group,所以我们选择Group 7为最终模型。
本文提出一种面向密集人群计数的高效检测网络YOLOv8n-CCNet。通过渐进式轻量化设计,在显著降低参数量的同时保留了模型对多尺度人头的检测能力;定制化的通道与位置注意力模块有效增强了网络在复杂背景下对密集小目标的聚焦与定位能力;配合动态优化的WIoUv3损失函数,大幅提升了遮挡场景下边界框回归的稳定性。实验全面验证了各模块的有效性与协同作用。
本研究为在资源受限的边缘设备上实现高精度、实时的人群计数提供了可行方案。未来工作将着重在极微小目标检测、无需密集标注的弱监督学习方法以及视频时序信息建模等方面展开探索,如近期研究所示,以提升动态场景下的计数性能,进一步推动该技术在智慧城市管理与公共安全监测中的应用。
基金项目:
河南省科技攻关项目(232102211037),河南大学科研实验室开放项目(20252304056)。
原文链接:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)